Elasticsearch聚合查询
ElasticSearch聚合查询
文章目录
-
- ElasticSearch聚合查询
-
- 一、聚合概念
-
- 1、ES 聚合分析是什么?
- 2、ES 聚合查询语法格式
- 3、指标(metric)和桶(bucket)
- 二、指标(metric)详解
-
- 1、Max Min Sum Avg
- 2、值统计
- 3、distinct 聚合
- 4、统计聚合
- 5、拓展的统计聚合
- 6、百分比统计
- 7、百分比排名聚合
- Top Hits
- 三、桶(bucket)详解
-
- 1、Terms Aggregation
- 2、Filter Aggregation
- 3、Filters Aggregation
- 4、范围聚合
- 5、时间范围聚合
- 6、Histogram 直方图聚合
- 7、Date_Histogram 直方图聚合
- 四、管道聚合
- 五、矩阵聚合
说明:该文章的ES版本为7.6.1
官方对聚合有四个关键字: Metric(指标)、Bucketing(桶)、Matrix(矩阵)、Pipeline(管道)。
创建索引,插入数据
PUT /t_shirt/
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"sold_date": {
"type": "date"
},
"remark": {
"type": "text"
}
}
}
}
批量插入数据
@Test
void bulkTest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
List<Shirt> list = new ArrayList<>();
list.add(new Shirt(150,"red","lining", LocalDateTime.parse("2007-12-03T10:15:30"),"备注"));
list.add(new Shirt(299.99,"yellow","adidas", LocalDateTime.parse("2020-05-03T10:20:30"),"备注"));
list.add(new Shirt(200.88,"blue","lining", LocalDateTime.parse("2007-12-10T12:15:30"),"备注"));
list.add(new Shirt(566,"red","nike", LocalDateTime.parse("2010-01-03T18:25:30"),"备注"));
for (int i = 0; i < list.size(); i++) {
bulkRequest.add(new IndexRequest("t_shirt").source(JSON.toJSONString(list.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(!bulk.hasFailures());
}
一、聚合概念
1、ES 聚合分析是什么?
概念: Elasticsearch除全文检索功能外提供的针对Elasticsearch数据做统计分析的功能。它的实时性高,所有的计算结果都是即时返回。
Elasticsearch将聚合分析主要分为如下4类:
Metric (指标):指标分析类型,如计算最大值、最小值、平均值等等。(对桶内的文档进行聚合分析的操作)
Bucket (通):分桶类型,类似于Mysql中的Group By 语法。 (满足特定条件的文档集合)
Pipeline (管道):管道分析类型,基于上一级的聚合分析结果进行在分析
Matrix (矩阵):矩阵分析类型(聚合是一种面向数值型的聚合,用于计算一组文档字段中的统计信息)
2、ES 聚合查询语法格式
"aggs" : {
"" : { <!--聚合的名字 -->
"" : { <!--聚合的类型 -->
<aggregation_body> <!--聚合体:对哪些字段进行聚合 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!--元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!--在聚合里面在定义子聚合 -->
}
[,"" : { ... } ]* <!--聚合的名字 -->
}
3、指标(metric)和桶(bucket)
这两种也是最常用的使用方式
- 桶(bucket)
- 简单来说,桶就是满足特定条件的文档的集合。
- 当聚合开始被执行,每个文档里面的值通过计算来决定符合那个桶的条件,如果匹配到,文档将放入响应的桶并接着开始聚合操作。
- 桶也可以嵌套在其他桶里面。
- 指标(metric)
- 桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档进行一些指标的计算。分桶就是一种达到目的地的手段:他提供了一种给文档分组的方法来让我们可以计算感兴趣的指标。
- 大多数的指标都是简单的数学运算(最大值、最小值、汇总、平均值),这些都是通过文档的直来计算的。
二、指标(metric)详解
Mertic 聚合分析分为单值分析、多值分析两类。
单值分析:
min、max、sum、avg、cardinality
多值分析:输出多个分析结果
status、extended_status、percentile、percentile_rank、top_hits
1、Max Min Sum Avg
计算文档中价格的最大值、最小值、平均值、总和
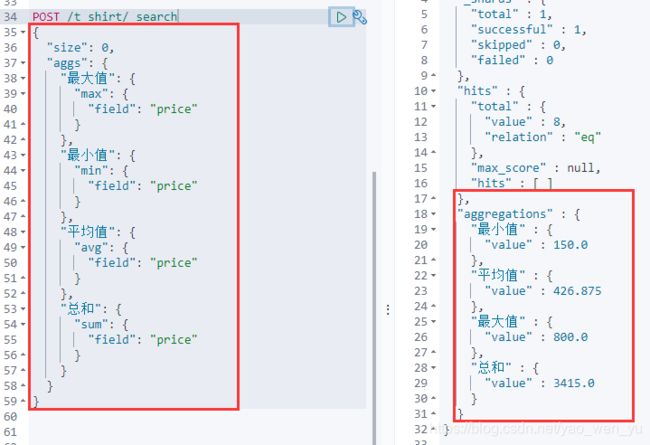
java Api 实现
@Test
void metric1() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
MaxAggregationBuilder maxAggregationBuilder = AggregationBuilders.max("最高价格").field("price");
MinAggregationBuilder minAggregationBuilder = AggregationBuilders.min("最低价格").field("price");
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("平均值").field("price");
SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("总和").field("price");
searchRequest.source(new SearchSourceBuilder()
.aggregation(maxAggregationBuilder)
.aggregation(minAggregationBuilder)
.aggregation(avgAggregationBuilder)
.aggregation(sumAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
Max max = search.getAggregations().get("最高价格");
Min min = search.getAggregations().get("最低价格");
Avg avg = search.getAggregations().get("平均值");
Sum sum = search.getAggregations().get("总和");
System.out.println("最高价格:"+max.getValue()+
"\n最低价格:"+min.getValue()+
"\n平均值:"+avg.getValue()+
"\n总和:"+sum.getValue());
}
2、值统计
计算聚合文档中某个值(可以是特定的数值型字段,也可以通过脚本计算而来)的个数。该聚合一般域其它 single-value 聚合联合使用,比如在计算一个字段的平均值的时候,可能还会关注这个平均值是由多少个值计算而来。
统计价格个数
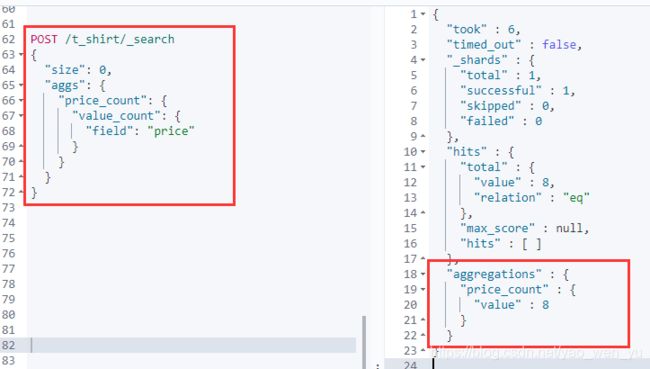
java Api 实现
@Test
void metric2() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
ValueCountAggregationBuilder countAggregationBuilder = AggregationBuilders.count("价格").field("price");
searchRequest.source(new SearchSourceBuilder().aggregation(countAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ValueCount valueCount = search.getAggregations().get("价格");
System.out.println("个数:"+valueCount.getValue());
}
3、distinct 聚合
它属于multi-value,基于文档的某个值(可以是特定的字段,也可以通过脚本计算而来),计算文档非重复的个数(去重计数),相当于sql中的distinct。
统计颜色个数(去重)
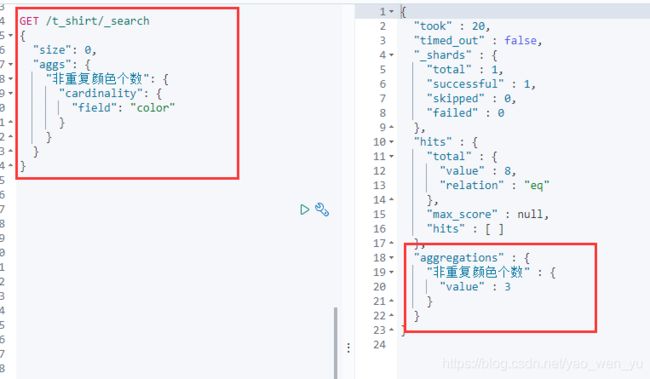
java Api 实现
@Test
void metric3() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
CardinalityAggregationBuilder cardinalityAggregationBuilder = AggregationBuilders.cardinality("颜色种类").field("color");
searchRequest.source(new SearchSourceBuilder().aggregation(cardinalityAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
Cardinality cardinality = search.getAggregations().get("颜色种类");
System.out.println("颜色种类:"+cardinality.getValue());
}
4、统计聚合
它属于multi-value,基于文档的某个值(可以是特定的数值型字段,也可以通过脚本计算而来),计算出一些统计信息(min、max、sum、count、avg5个值)。
计算价格的统计
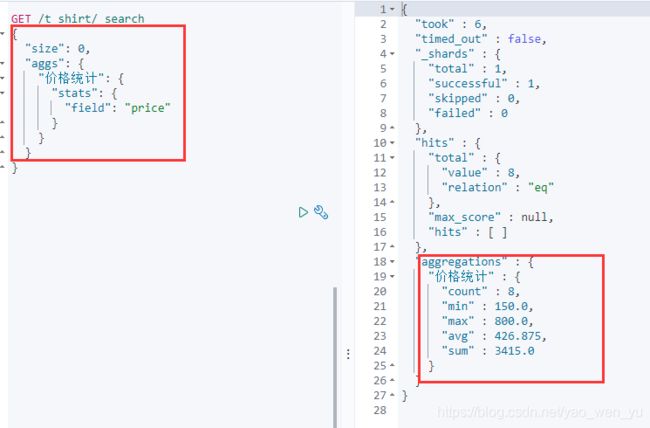
java Api 实现
@Test
void metric4() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
StatsAggregationBuilder statsAggregationBuilder = AggregationBuilders.stats("价格统计").field("price");
searchRequest.source(new SearchSourceBuilder().aggregation(statsAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
Stats stats = search.getAggregations().get("价格统计");
System.out.println("价格统计:\n最高价格:"+stats.getMaxAsString()+
"\n最低价格:"+stats.getMinAsString()+
"\n平均价格:"+stats.getAvgAsString()+
"\n价格总和:"+stats.getSumAsString());
}
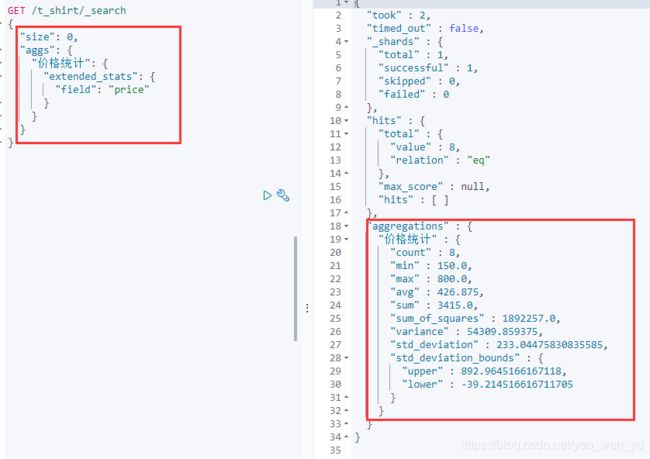
5、拓展的统计聚合
它属于multi-value,比stats多4个统计结果: 平方和、方差、标准差、平均值加/减两个标准差的区间
价格扩展统计
java Api 实现
@Test
void metric5() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
ExtendedStatsAggregationBuilder statsAggregationBuilder = AggregationBuilders.extendedStats("价格统计").field("price");
searchRequest.source(new SearchSourceBuilder().aggregation(statsAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
ExtendedStats stats = search.getAggregations().get("价格统计");
System.out.println("价格统计:\n最高价格:"+stats.getMaxAsString()+
"\n最低价格:"+stats.getMinAsString()+
"\n平均价格:"+stats.getAvgAsString()+
"\n价格总和:"+stats.getSumAsString()+
"\n平方和:"+stats.getSumOfSquaresAsString()+
"\n方差:"+stats.getVarianceAsString()+
"\n标准差:"+stats.getStdDeviationAsString());
}
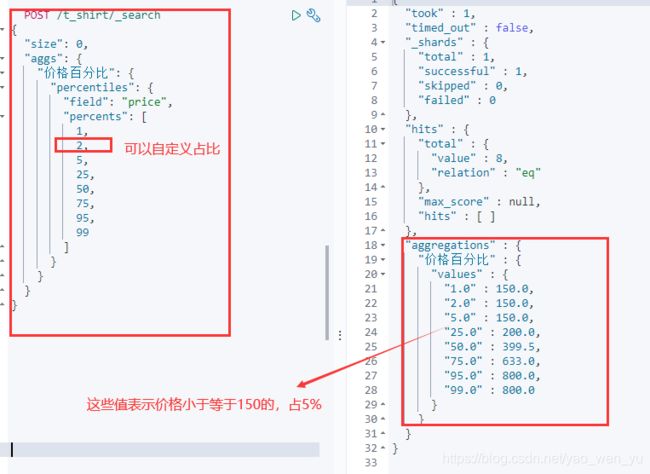
6、百分比统计
它属于multi-value,对指定字段(脚本)的值按从小到大累计每个值对应的文档数的占比(占所有命中文档数的百分比),返回指定占比比例对应的值。默认返回[ 1, 5, 25, 50, 75, 95, 99 ]分位上的值。
统计价格的百分比
java Api 实现
@Test
void metric6() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
PercentilesAggregationBuilder statsAggregationBuilder = AggregationBuilders.percentiles("价格统计").field("price");
searchRequest.source(new SearchSourceBuilder().aggregation(statsAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
Percentiles percentiles = search.getAggregations().get("价格统计");
System.out.println("价格统计:"+percentiles.percentileAsString(50)); //参数 50:就是50%
}
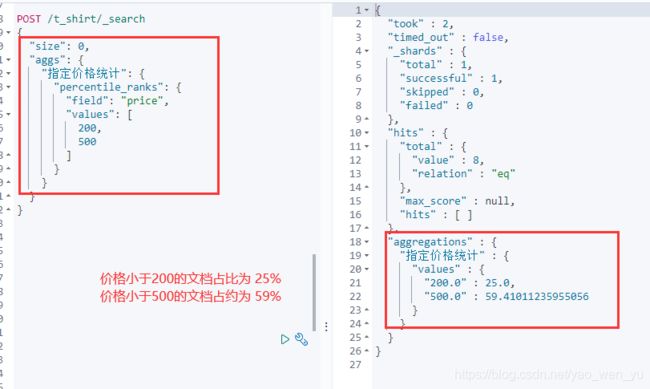
7、百分比排名聚合
统计价格小于 200 和 小于500 的文档占比
java Api 实现
@Test
void metric7() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
double [] doubles = new double[]{200,500};
PercentileRanksAggregationBuilder percentileRanksAggregationBuilder = AggregationBuilders.percentileRanks("价格统计",doubles).field("price");
searchRequest.source(new SearchSourceBuilder().aggregation(percentileRanksAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析结果
PercentileRanks percentileRanks = search.getAggregations().get("价格统计");
System.out.println("价格统计:"+percentileRanks.percentAsString(1)); //参数 50:就是50%
}
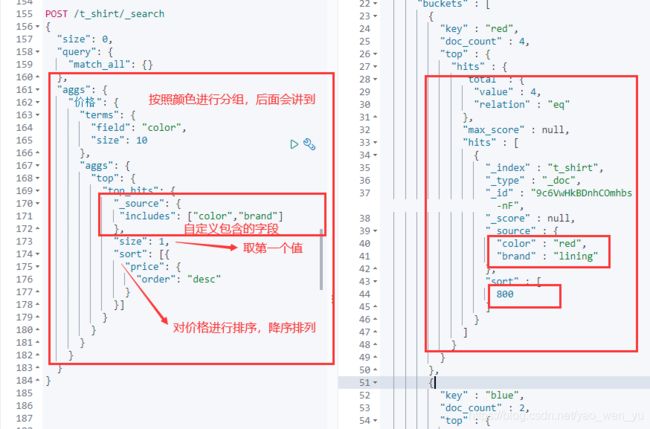
Top Hits
最高匹配权值聚合,获取到每组前n条数据,相当于sql 中Top(group by 后取出前n条)。它跟踪聚合中相关性最高的文档,该聚合一般用做 sub-aggregation,以此来聚合每个桶中的最高匹配的文档,较为常用的统计。
对颜色进行分组,查询每个分组中价格最高的商品
java Api 实现
@Test
void metric8() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
String[] includes = new String[]{"price","color"};
String[] excludes = new String[]{"brand","sold_date","remark"};
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("颜色分组").field("color");
TopHitsAggregationBuilder topHitsAggregationBuilder = AggregationBuilders.topHits("价格最高的颜色").size(1).sort("price", SortOrder.DESC).fetchSource(includes, excludes);
termsAggregationBuilder.subAggregation(topHitsAggregationBuilder);
searchRequest.source(new SearchSourceBuilder().aggregation(termsAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(search);
//解析结果
Terms terms = search.getAggregations().get("颜色分组");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println("颜色分组:"+bucket.getKey());
TopHits topHits = bucket.getAggregations().get("价格最高的颜色");
for (SearchHit hit : topHits.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
for (Map.Entry<String, Object> stringObjectEntry : sourceAsMap.entrySet()) {
System.out.println(stringObjectEntry.getKey()+":"+stringObjectEntry.getValue());
}
}
}
}
三、桶(bucket)详解
它执行的是对文档分组的操作(与sql中的group by类似),把满足相关特性的文档分到一个桶里,即桶分,输出结果往往是一个个包含多个文档的桶(一个桶就是一个group)。
它有一个关键字(field、script),以及一些桶分(分组)的判断条件。执行聚合操作时候,文档会判断每一个分组条件,如果满足某个,该文档就会被分为该组(fall in)。
它不进行权值的计算,他们对文档根据聚合请求中提供的判断条件(比如:{“from”:0, “to”:100})来进行分组(桶分)。桶聚合还会额外返回每一个桶内文档的个数。
它可以包含子聚合——sub-aggregations(权值聚合不能包含子聚合,可以作为子聚合),子聚合操作将会应用到由父聚合产生的每一个桶上。
它根据聚合条件,可以只定义输出一个桶;也可以输出多个(multi-bucket);还可以在根据聚合条件动态确定桶个数(比如:terms aggregation)。
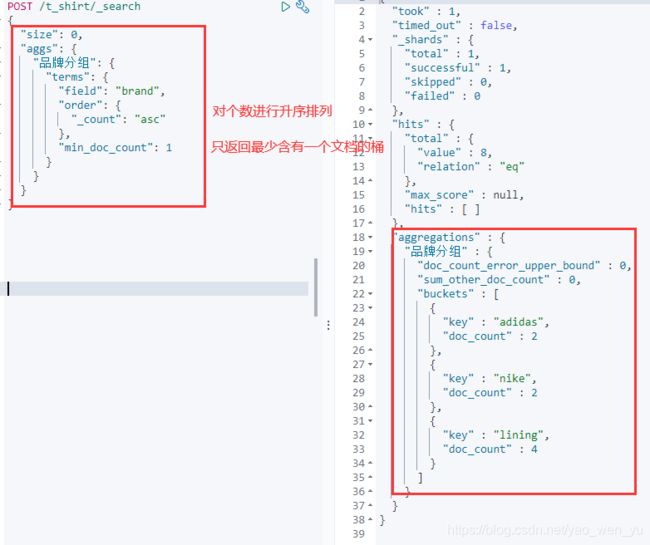
1、Terms Aggregation
词聚合。基于某个field,该 field 内的每一个【唯一词元】为一个桶,并计算每个桶内文档个数。默认返回顺序是按照文档个数多少排序。它属于multi-bucket。当不返回所有 buckets 的情况(它size控制),文档个数可能不准确。
根据品牌进行分组
java Api 实现
@Test
void metric9() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("品牌分组")
.field("brand")
.order(BucketOrder.count(true))
.minDocCount(1);
searchRequest.source(new SearchSourceBuilder().aggregation(termsAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(search);
//解析结果
Terms terms = search.getAggregations().get("品牌分组");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString()+"::::"+bucket.getDocCount());
}
}
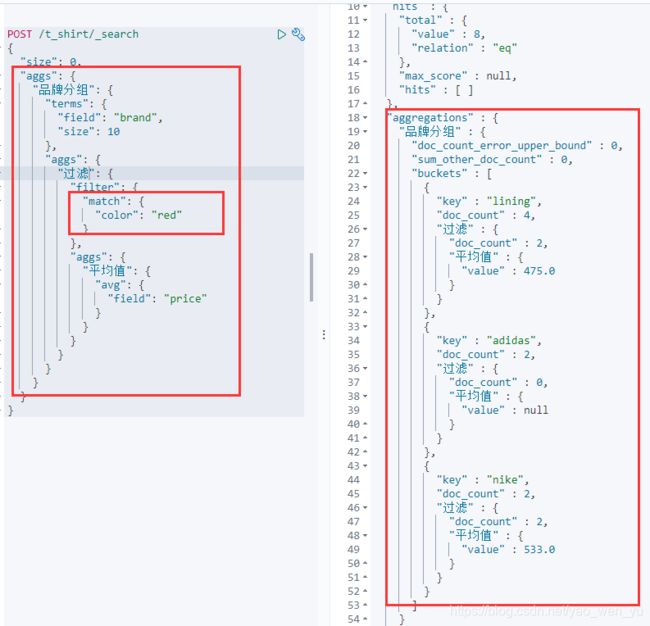
2、Filter Aggregation
过滤聚合。基于一个条件,来对当前的文档进行过滤的聚合。
按照品牌进行分组,对分组中的除红色以外的颜色进行过滤,最后再求出过滤之后价格的平均值
java Api 实现
@Test
void metric10() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
TermsAggregationBuilder termsAggregationBuilder = AggregationBuilders.terms("品牌分组")
.field("brand")
.order(BucketOrder.count(true))
.minDocCount(1);
FilterAggregationBuilder filterAggregationBuilder = AggregationBuilders.filter("过滤", QueryBuilders.matchQuery("color", "red"));
filterAggregationBuilder.subAggregation(AggregationBuilders.avg("平均值").field("price"));
searchRequest.source(new SearchSourceBuilder().aggregation(termsAggregationBuilder.subAggregation(filterAggregationBuilder)));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(search);
//解析结果
Terms terms = search.getAggregations().get("品牌分组");
List<? extends Terms.Bucket> buckets = terms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString()+"===>"+bucket.getDocCount());
Filter filter = bucket.getAggregations().get("过滤");
System.out.println("\n数量"+filter.getDocCount());
Avg avg = filter.getAggregations().get("平均值");
System.out.println("\n平均值:"+avg.getValue());
}
}
3、Filters Aggregation
多过滤聚合。基于多个过滤条件,来对当前文档进行【过滤】的聚合,每个过滤都包含所有满足它的文档(多个bucket中可能重复),先过滤再聚合。它属于multi-bucket。

4、范围聚合
范围分组聚合。基于某个值(可以是 field 或 script),以【字段范围】来桶分聚合。范围聚合包括 from 值,不包括 to 值(区间前闭后开)。它属于multi-bucket。

java Api 实现
@Test
void metric12() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
RangeAggregationBuilder rangeAggregationBuilder = AggregationBuilders.range("价格区间").field("price");
rangeAggregationBuilder.addRange(0,100)
.addRange(101,300)
.addRange(301,600)
.addRange(601,900)
.subAggregation(AggregationBuilders.max("最大值").field("price"));
searchRequest.source(new SearchSourceBuilder().aggregation(rangeAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Range range = search.getAggregations().get("价格区间");
List<? extends Range.Bucket> buckets = range.getBuckets();
for (Range.Bucket bucket : buckets) {
System.out.print(bucket.getKeyAsString()+"===>"+bucket.getDocCount());
Max max = bucket.getAggregations().get("最大值");
System.out.println("\n最大值:"+max.getValue());
}
}
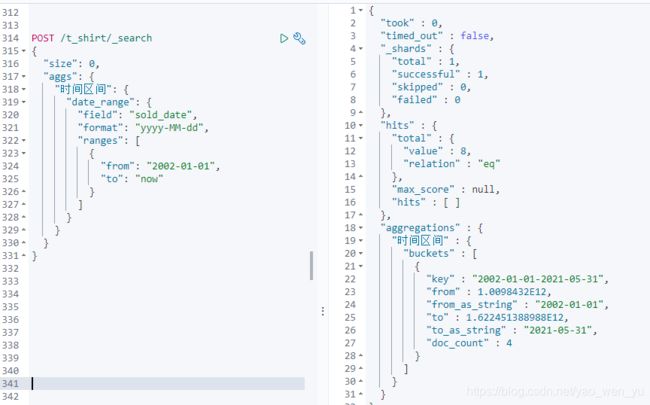
5、时间范围聚合
日期范围聚合。基于日期类型的值,以【日期范围】来桶分聚合。期范围可以用各种Date Math 表达式。同样的,包括 from 的值,不包括 to 的值。它属于multi-bucket。
java Api 实现
@Test
void metric13() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
DateRangeAggregationBuilder rangeAggregationBuilder = AggregationBuilders.dateRange("时间区间").field("sold_date");
rangeAggregationBuilder.
format("yyyy-MM-dd").
addRange("2002-01-01","2022-01-01");
searchRequest.source(new SearchSourceBuilder().aggregation(rangeAggregationBuilder));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Range range = search.getAggregations().get("时间区间");
List<? extends Range.Bucket> buckets = range.getBuckets();
for (Range.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString()+"===>"+bucket.getDocCount());
}
}
6、Histogram 直方图聚合

java Api 实现
@Test
void histogramPrices() throws IOException {
//构建查询请求
SearchRequest searchRequest = new SearchRequest().indices("t_shirt");
// 200 区间值
HistogramAggregationBuilder histogramAggregationBuilder = AggregationBuilders.histogram("价格区间").field("prices").interval(200);
AvgAggregationBuilder avgAggregationBuilder = AggregationBuilders.avg("平均值").field("prices");
searchRequest.source(new SearchSourceBuilder().aggregation(histogramAggregationBuilder.subAggregation(avgAggregationBuilder)));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(search);
}
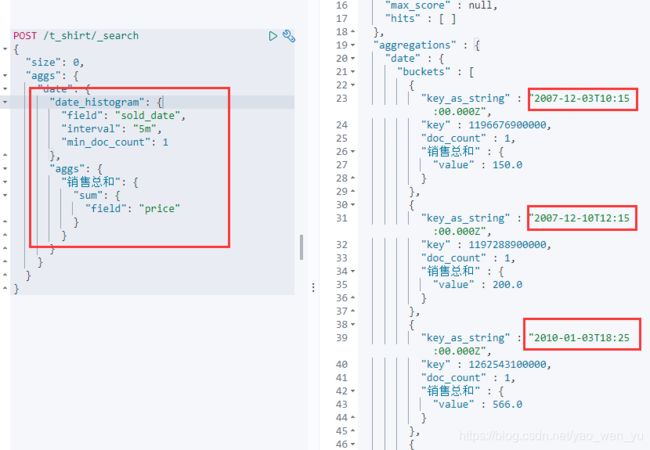
7、Date_Histogram 直方图聚合
统计每5分钟的销售数量及销售总金额
java Api 实现
@Test
void dateHistogram() throws IOException {
DateHistogramAggregationBuilder dateHistogramAggregationBuilder = AggregationBuilders.dateHistogram("5分钟时间间隔")
.field("sold_date");
// dateHistogramInterval(),这个方法已经过时,推荐使用
// dateHistogramAggregationBuilder.fixedInterval(DateHistogramInterval.minutes(5))
dateHistogramAggregationBuilder.fixedInterval(DateHistogramInterval.minutes(5))
.minDocCount(1);
SumAggregationBuilder sumAggregationBuilder = AggregationBuilders.sum("每月销售总和").field("price");
searchRequest.source(new SearchSourceBuilder()
.aggregation(dateHistogramAggregationBuilder.subAggregation(sumAggregationBuilder)));
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(search);
Histogram histogram = search.getAggregations().get("5分钟时间间隔");
List<? extends Histogram.Bucket> buckets = histogram.getBuckets();
for (Histogram.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString());
Sum sum = bucket.getAggregations().get("每月销售总和");
System.out.println("\n总和:"+sum.getValue());
}
}
四、管道聚合
管道聚合。它对其它聚合操作的输出(桶或者桶的某些权值)及其关联指标进行聚合,而不是文档,是一种后期对每个分桶的一些计算操作。管道聚合的作用是为输出增加一些有用信息。
管道聚合不能包含子聚合,但是某些类型的管道聚合可以链式使用(比如计算导数的导数)。
管道聚合大致分为两类:
parent,它输入是其【父聚合】的输出,并对其进行进一步处理。一般不生成新的桶,而是对父聚合桶信息的增强。
sibling,它输入是其【兄弟聚合】的输出。并能在同级上计算新的聚合。
五、矩阵聚合
矩阵聚合。此功能是实验性的,在将来的版本中可能会完全更改或删除。
它对多个字段进行操作并根据从请求的文档字段中提取的值生成矩阵结果的聚合系列。与度量聚合和桶聚合不同,此聚合系列尚不支持脚本编写。