百度C++基础容器(5)
C++基础容器(5)
问题推动学习:
- 什么是序列容器和关联性容器?
- 什么是缓冲区溢出?
- 为什么缓冲区溢出那么严重?
- 数组在增删改查上的时间复杂度效率分析?
- 什么是差一错误?以及如何避免?(数组越界问题)
- 二维数组在C++中的访问效率问题?
- vector的特点是什么,为什么要使用vector?
- 字符串常量和字符串变量如何区分?
- unicode的编码有几种主要类型?
- 字符串的基本操作函数有哪些?为什么这些函数是危险的,以及如何规避这些危险的操作?
容器
什么是序列容器和关联性容器?
其实这两种容器从根本上来说:是因为有着不同的数据结构(设计者在设计的思维模式上不同)
因为不同的容器的发明,是为了解决不同场景下的问题,没有什么容器是最好的,只有什么容器是最合适的。
关联性容器就比如说:map,set等
数据结构上就比如二叉树这种
数组:
数组的基本使用就不多说了
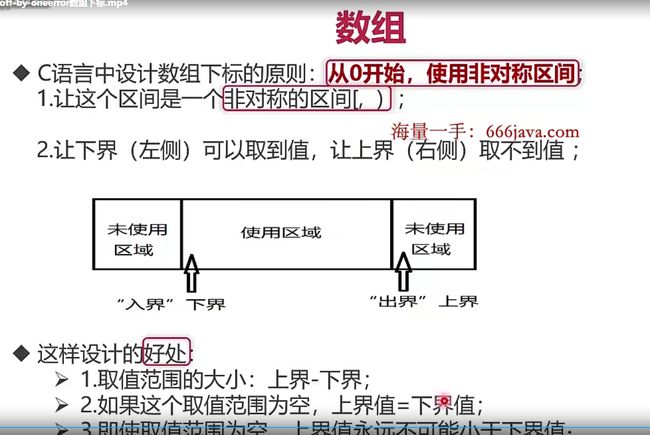
这里讲一个:差一错误
什么是差一错误:
就是对数组的长度判断出现了错误!比如下面的代码所示
在for循环中不要采用左闭右闭的区间形式,采用左闭右开的区间模式是C++设计者们的设计思路
比如说在vector.end()他并不是数组的最后一个元素,而是数组的最后一个元素的下一个位置!
这样的设计符合了:左闭右开的设计思想
//int arr[10] = ......;
for(int i = 0; i <= 10; i++){
std::cout << arr[i] << std::endl;
}
这是数组越界产生的错误,这里有几个要点:
- 在for循环中对于终止的条件不要使用数字来表示终止条件!在企业的开发中,别人根本不知道这是什么意思
- 在容器中使用容器的函数
- 判断的条件不要出现等于的情况 =

二维数组
在征服C指针这本书里也看到过,其实二维数组的本质上也还是一维数组
二维数组的话,就是了解一下怎么遍历就OK了,然后有一个cache命中率的问题:
就是行遍历和列遍历的问题,for循环内外条件的不同,会让遍历的效率不同。
在PPT中有解释
二维数组在C++中的访问效率问题?
下面的PPT回答了整个问题(内外for循环遍历的对象不同,会让其复杂度不同)

什么是缓冲区溢出?
为什么缓冲区溢出那么严重?
这是百度的解释:
缓冲区溢出是一种非常普遍、非常危险的漏洞,在各种操作系统、应用软件中广泛存在。利用缓冲区溢出攻击,可以导致程序运行失败、系统宕机、重新启动等后果。更为严重的是,可以利用它执行非授权指令,甚至可以取得系统特权,进而进行各种非法操作。
缓冲区溢出(buffer overflow),是针对程序设计缺陷,向程序输入缓冲区写入使之溢出的内容(通常是超过缓冲区能保存的最大数据量的数据),从而破坏程序运行、趁著中断之际并获取程序乃至系统的控制权。
在数组中缓冲区溢出就是对数组进行了越界操作
在字符串中缓冲区溢出比如说字符串在拼接时,会在原来的字符串内存末尾追加新加入的字符串,可能会覆盖掉某块内存上以及存在有的数据。
因此缓冲区溢出是非常严重可怕的后果,一些黑客也可以利用缓冲区溢出来攻击别人的程序。
如何避免缓冲区的溢出?
- 使用更加安全的API,减少使用底层API
- 对数组的边界一定要检查
- 额…然后我也不知道了,没有开发经验
数组在增删改查上的时间复杂度效率分析?
这个内容其实是数据结构和算法分析里面的问题,能够口述表达清楚就可以。
同时也能够将数组和链表的两种数据结构的不同点和各自的优点缺点都表达清楚就OK
数组:
优点:
- 支持随机访问,访问的效率很高,因此数组在内存中连续存储的,知道起始地址后可以很快定位要访问的下标对应的内容。
- 占用的空间内存相比链表小,对内存的消耗相对不高
缺点
- 在中间的插入需要移动后面的所有元素,时间复杂度为O(n)
- 拓展性不强(动态数组除外)
链表
优点:
- 插入和删除的效率很高,数据结构决定的
- 拓展性比较好(同上)
缺点:
- 不支持随机访问,因为在内存中的布局不是连续的,需要从头开始遍历
- 占用的内存相比于数组而言较大,这是数据的结构决定的
vector的特点是什么,为什么要使用vector?
这种问题主要是为了巩固自己的知识,虽然他没有什么难度,但是这是属于考察基本功的问题。
vector属于动态数组,他解决了普通数组所带来的一些问题,比如拓展性不好,同时也提供了一系列的API让数组的使用大大的便捷了。
使用vector让程序的编写更加快捷,对数组元素的操作更加安全。
但是缺点:
- vector容器的本质就是将数组的包装,加入了C++中面向对象的特性,因此他的效率是不如纯数组的。百度C++课程里面说了,在一些对性能追求非常高的地方,仍然会使用纯数组,而不是STL中的容器,比如输入法
- 在很多开发的企业公司里,他们认为STL库中的容器不安全,他们会选择自己去开发一套容器来做项目。
字符串
字符串常量和字符串变量如何区分?
同时整个知识点也可以回想一下:指针常量和常量指针的内容
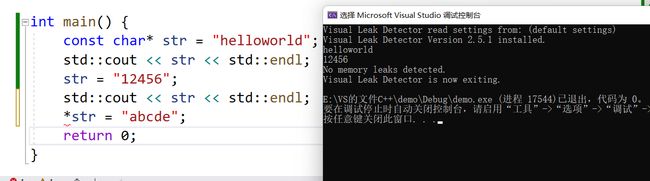
int main() {
//这里定义一个helloworld的字符常量,str是一个字符类型的指针
//同时这里有一个知识点,是指针常量和常量指针的内容
//const在前是对指针解引用后的内容不能做修改,指针所指向的地址是可以修改的
const char* str = "helloworld";
std::cout << str << std::endl;
//这里是可以改变的,改变的不是字符常量helloworld,而是让str指向了一个新的字符常量
str = "12456";
std::cout << str << std::endl;
//这里报错了!const在前,字符常量是不能被修改的哦baby
*str = "abcde";
return 0;
}
//其实在C++中没有绝对的字符串变量,虽然这个话有点怪怪的,但是大概意思就是说,变量就是拿一个数组来存放字符串常量的,操作的时候仍然要小心
int main() {
char str[11] = { "helloworld" };
for (int i = 0; i < 11; i++) {
std::cout << str[i] << std::endl;
}
return 0;
}
int main() {
char str[11] = { "helloworld" };
for (int i = 0; ; i++) {
//字符串变量的末尾会默认加上一个'\0'可以通过这样的遍历方式,打印数组
if (str[i] != '\0') {
std::cout << str[i] << std::endl;
}
else {
break;
}
}
return 0;
}
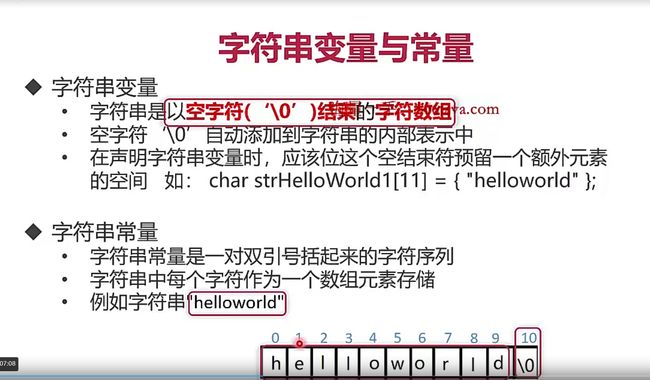
unicode的编码有几种主要类型?
下面的PPT讲解的比较清楚了,有些点要注意:
比如 char c1 = 0;
char c2 = ‘\0’;
他们在计算机中的机器码表示是相同的,先记住就OK,我暂时也不太清楚为什么,但是如果你定义一个字符串数组,在内存的末尾会有0x00,因为整个表示数组的结束。

编码错误的根本原因:编码方式和解码方式不同!
字符串指针
这个部分的内容,上面的代码给了,回头可以自己去看一下baby

下面的代码可以看一下
int main() {
char str[11] = { "helloworld" };
const char* pStr = "helloworld";
char* pStr2 = str;
//这里是对原来str的遍历
for (int i = 0; i < 11; i++) {
std::cout << str[i];
}
std::cout<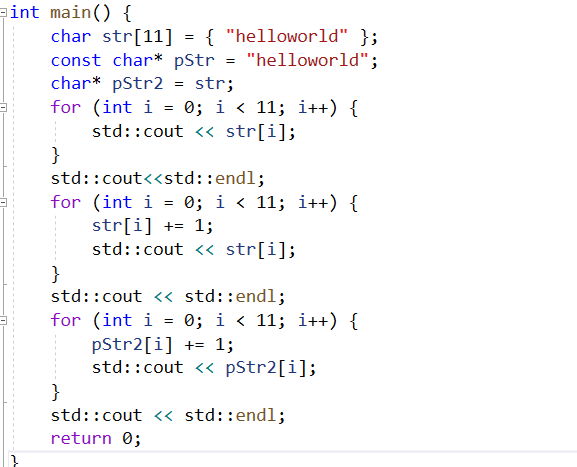
字符串函数的使用
字符串的基本操作函数有哪些?为什么这些函数是危险的,以及如何规避这些危险的操作?
strcat这类API都是比较偏向与底层的API,不推荐使用这样的API,如果要使用在后面加上_s
为什么是危险的?因为你在使用的时候可能会造成缓冲区的溢出
把这一段代码复制到自己的VS上运行时,程序会崩溃
因为strcat_s(strHelloWorld2, STR_LEN_NUM, "Welcome to C++");会检测缓冲区溢出的问题,你传入了最大的缓冲区大小为STR_LEN_NUM,如果长度大于这个,程序运行就会报错
当然也可以尝试一下,如果不使用strcat_s,程序都不会提示你报错,这是非常危险的事情
因为在大型的项目中: 你很难定位到底哪里出现了问题!
下面的代码还是比较好理解的,自己认真阅读一下,就能理解了
#include //使用C库的头文件
#include
using namespace std;
const unsigned int MAX_LEN_NUM = 16;
const unsigned int STR_LEN_NUM = 7;
const unsigned int NUM_TO_COPY = 2;
int main()
{
char strHelloWorld1[ ] = { "hello" };
char strHelloWorld2[STR_LEN_NUM] = { "world1" };
char strHelloWorld3[MAX_LEN_NUM] = {0};
//strcpy(strHelloWorld3, strHelloWorld1); // hello
strcpy_s(strHelloWorld3, MAX_LEN_NUM, strHelloWorld1);
//strncpy(strHelloWorld3, strHelloWorld2, NUM_TO_COPY); // wollo
strncpy_s(strHelloWorld3, MAX_LEN_NUM, strHelloWorld2, NUM_TO_COPY);
//strcat(strHelloWorld3, strHelloWorld2); // wolloworld1
strcat_s(strHelloWorld3, MAX_LEN_NUM, strHelloWorld2);
//unsigned int len = strlen(strHelloWorld3);
unsigned int len = strnlen_s(strHelloWorld3, MAX_LEN_NUM);
for (unsigned int index = 0; index < len; ++index)
{
cout << strHelloWorld3[index] << " ";
}
cout << endl;
// 小心缓冲区溢出
//strcat(strHelloWorld2, "Welcome to C++");
strcat_s(strHelloWorld2, STR_LEN_NUM, "Welcome to C++");
return 0;
}
