Map 、Set 、weakMap 、weakSet
垃圾回收、栈内存、堆内存、原始值、引用值
分析下面的例子,说出{ a: 1 }这个对象被引用的次数?可能有人说是1次,也可能有人说2次。那么{ a:1 }对象到底被引用几次呢?这个引用到底指代的是什么意思呢?
实际上{ a: 1 }这个对象被引用3次。至于是什么原因,我们在这里先不直接说明,我们一点点的从基础开始说起。
const obj = { a:1 };
const obj2 = obj;
const map = new Map();
map.set(obj, {a: 3});
javaScript 栈内存、堆内存
如果const a = 1这行代码出现在你的面前,你会如何看待它呢?肯定有人要说,这太简单了!!!不就是声明一个变量a,然后将1赋值给a嘛。
其实这种理解的并不是很透彻,我们要从栈内存和堆内存中理解,这样有助于之后我们理解引用的问题。首先有些人会错误的认为变量a就是数值1,而数值1就是变量a。这种想法是错误的,首先我们要明确HJavaScript中的基本数据值有哪些?基本数据值:number、string、boolean、undefined、null、Symbol、bigInt。既然明确了JavaScript中的基本数据值有哪些,你为什么会认为变量a是1呢?
为了让我们能够理解const a = 1代码,我们从内存中下手。在内存中分为堆内存、栈内存,堆内存中一般存储基本数据值,而栈内存中一般存储引用数据值。因为在堆内存中一般是以空间的形式存在的,而栈内存更改数据一般只能开辟空间,所以将引用数据值只能存储到堆内存中。在MDN文档中指出:In JavaScript, primitive values are immutable-once a primitive value is create, it cannot be change, although the variable that holds it may be reassigned another value. By contrast.objects and arrays are mutable by default - their properties and elements can be changedwithout reassigning a new value.
MDN指出的是什么意思呢?它说:在JavaScript中,原始数值(基本数据值)是不可变的,被创建一次后就不能够变化,尽管保存它的变量可以重新分配一个值。相比之下默认情况,对象和数组是可变的,可以更改它的属性和元素,而无需重新分配新值。其实MDN文档已经说的很明白了,也就是基本数据类型创建后不能够发生变化,而对象和数组是可以发生变化的。
const a = 1该如何理解这行代码呢?首先a是我们声明的一个变量,什么是变量呢?你可以将变量理解为一个盒子,变量的特性就是它们能够存储任何东西–不只是字符串和数字。变量可以存储更复杂的数据,甚至是函数。我们说,变量是用来储存数值的,那么就有一个重要的概念区分。变量不是数值本身,它们仅仅是一个用于存储数值的容器。
那么也就是说,此时数值1和变量a是不同的两个东西,变量a是存储数值1的“纸箱子”,而数值1是JavaScript中的基本数据值。

如果是在内存中,那么const a = 1的过程又是什么样子的呢?我们说过栈内存中存储的是基本数据值,整体的存储效果类似我们下面的效果示意图。此时我们能够看到其实在栈内存中存储的是数值1,而并不是变量a,此时的变量a成为了数值1的标识。也就是在栈内存中,通过变量a能够获取到数值1。
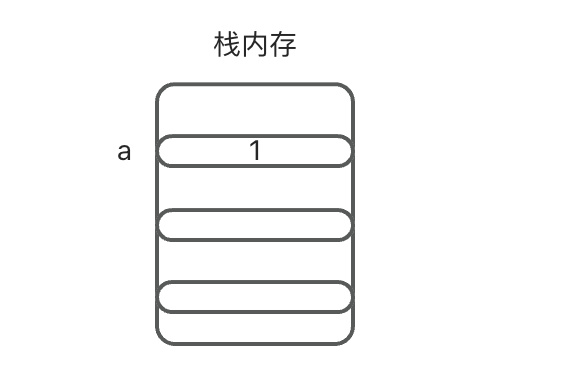
那么MDN上指出的:原始数值是不可变的,被创建一次后就不能够变化,尽管保存它的变量可以重新分配一个值。这又是什么意思呢?比如说,下面的图就是let a = 1; a = 3,变量a重新赋值的栈内存过程。此时我们发现数值1并没有被直接覆盖,而是重新在栈内存中开辟了另一个空间。只是将变量a这个标识移动到了3上,但是数值1在内存中并没有发生变化,数值1之后会被垃圾回收机制清理掉。
所以到这里,我们在脑子里就要清楚一个概念:变量并不是数值的本身,而是存储数值的一个容器而已
那如果是引用值的话,又是什么样子的过程呢?其实MDN上也指出:相比之下默认情况,对象和数组是可变的,可以更改它的属性和元素,而无需重新分配新值。也就是说,对象和数组是可以改变自身的属性与元素,而不像基本数值一样,一旦创建之后就不可更改。
通过下面的示意图,我们也不难看出引用数据类型在内存中存储的特点。首先我们发现栈内存中存储的不再是数值,而是类似一个地址的数值0x666。通过这个地址就可以通过指针找到堆内存中的数据。而此时变量obj、arr保存的就不再是一个单纯的数值,而是一个地址,你也可以认为是一个指针,指向堆内存中的引用数据值。相比基本数值的话,此时堆内存中的对象{ a:1 }的属性a是可以修改的。但是我们还是要注意,此时{ a: 1 }对象中的a也只是标识,标识着对象的a属性是数值1。但是你要注意,堆内存中对象属性是可以更改的。

垃圾回收机制、强引用、弱引用
上面中的栈内存、堆内存概念,只是想让我自己了解基本数值与引用数值在内存中的存储方式,只是参考的作用。但是还是想再一次告诉自己,变量与数值并不是同一个东西,一定要注意变量与数值是不同的两个东西,变量是装数值的容器。
在之前学习垃圾回收机制的时候,了解过垃圾回收机制的引用计数法,但是没有真正的学习到精髓。现在我们就结合垃圾回收机制来看一下什么是强引用?什么是弱引用?
先分析下面的例子,首先声明obj变量,其次将{ a: 1 }对象的堆内存地址交给obj变量进行储存。然后重新给变量obj赋值null数值。此时有人会认为obj = null的作用是触发垃圾回收机制、或者是删除了{ a: 1 }对象,所以变量obj结果打印的是null。
let obj = { a: 1 };
obj = null;
console.log(obj); // null
实际上这些想法都是错误的,我们来做一个实验:通过实验,我们发现,虽然执行了obj = null语句,但是{ a: 1 }对象依旧存在,因为obj2依旧是{ a: 1 }对象。所以说明obj = null语句的作用并不是删除{ a: 1 }对象。而且obj = null语句并不能够触发垃圾回收机制。
let obj = { a: 1 };
let obj2 = obj;
obj = null;
console.log(obj); // null
console.log(obj2); // { a: 1 }
强引用
既然obj = null语句并不是删除{ a: 1 }对象,也不能够触发垃圾回收机制。那么上面的例子到底是一个什么样子的过程呢?
这里面牵扯着强引用的问题:
ES2015规范之前,是没有区分引用的强弱。
ES2015规范以后,强弱引用。
我们针对下面的例子,来看一下什么是强引用。
- 代码执行
const obj = { a: 1 }时,此时栈内存中的标识obj存储的是堆内存中{ a: 1 }对象地址。所以此时{ a: 1 }对象被引用次数为1次。 - 代码执行
const obj2 = obj时,此时栈内存中的标识obj2储存的地址与obj标识存储的地址一致,存储的都是{ a: 1 }对象的地址,所以此时{ a: 1 }对象引用次数+1,引用次数为2次。 - 代码执行
obj = null,此时obj = null会栈堆内存中开辟另一个空间,将null数值存储到该空间内,并且将obj标识与新开辟的空间对应。那么之前的空间由于没有标识进行引用,所以栈内存与堆内存之前的指针发生断裂,也就是说{ a: 1 }对象的引用次数-1,现在{a: 1}对象的引用次数为1次。

let obj = { a: 1 };
let obj2 = obj;
obj = null;
console.log(obj); // null
console.log(obj2); // { a: 1 }
我们在上面例子中说的引用次数是什么意思呢?其实这个引用次数是针对垃圾回收机制说的。上面例子中的所有代码执行完成之后,由于obj2变量保存着{ a: 1 }对象的地址,所以{ a: 1 }对象的引用次数为1次。如果我们也将obj2变量与{ a: 1 }对象之间的指针也断开,此时会发生什么情况呢?
实际上如果我们将obj2变量与{ a: 1 }对象之间的指针断开的话,此时{ a: 1 }对象的引用次数为0次,那么垃圾回收机制会试图在某一不可预测的时刻回收这个对象。注意垃圾回收机制执行的时机是不可预测的。
let obj = { a: 1 };
let obj2 = obj;
obj = null;
obj2 = null;
console.log(obj); // null
console.log(obj2); // null
强引用在理论上会出现内存溢出的问题,为什么强引用会出现内存溢出的现象呢?为什么在JavaScript中不容易体现出内存溢出的问题呢?
对于强引用来说,如果说引用次数不为0的话,那么垃圾回收机制是不会进行清除的。所以遇到下面的情况时,理论上就会出现内存溢出的现象。
当fn函数执行完成的时候,理论上fn函数是要回到被声明时的状态,也就是说fn函数执行时产生的AO执行期上下文环境要被清除。而由于闭包函数function(){}的存在,导致fn函数执行完成后不能够清除AO环境,所以就会一直占用内存。当这种行为多了以后,理论上是会产生内存溢出的问题。如果说想释放内存的话,那么我们可以手动的清除引用。
为什么JavaScript中不容易出现内存溢出呢?因为JavaScript是建立于浏览器的基础上执行,所以有些内存问题会由浏览器的方面去解决。
function fn() {
let a = 1;
return function() {
console.log(a);
}
}
var demo = fn();
demo();
// 手动清除引用
demo = null;
弱引用
上面我们说过在ES2015之前是不区分强弱引用的,但是在ES2015之后是区分强弱引用的。那么强引用与弱引用有什么区别呢?
先说结论:本质上强弱引用是针对垃圾回收机制来讲的,我们说强引用的话,垃圾回收机制会在引用次数上增加1。而如果是弱引用的话,那么垃圾回收机制不会针对引用计数。
在ES6中哪些API存在弱引用的性质呢?首先是WeakMap的键名,其次是WeakSet集合中的元素。
WeakMap对象是一组键/值对的集合,其中的键是弱引用的。其键必须是对象,而值是任意的。
如何证明WeakMap对象中的键是弱引用呢?我们一起来看下面的例子:
首先Map对象的键名是强引用,这一点要明确。也就是说,目前除了WeakMap/WeakSet存在弱引用,其它的都可以认为是强引用。
- 代码执行
const obj = { a: 1 },此时{ a : 1 }对象被引用的次数为1。 - 代码执行
const obj2 = obj,此时{ a: 1 }对象被引用的次数为2。 - 代码执行
map.set(obj, 'obj'),注意此时map对象中的键名引用着{ a: 1 }对象,所以{ a: 1 }被引用的次数为3。 - 如果我现在断开
obj/obj2对{ a: 1 }对象的引用,此时map对象中还存在{a:1}的键名吗?换句话说,{ a: 1 }对象是否被垃圾回收机制清除了吗?
实际上map中还是存在{ a: 1 }对象的键名,因为Map的键名是强引用,虽然你接触了obj/obj2变量对{a:1}的引用。但是map的键名依旧引用着{a:1}对象,所以此时{a:1}对象被引用次数依旧是1,{a:1}对象并不会被垃圾回收机制清除。特别注意:这也是强引用的特点,待会和弱引用的特点做对比。
// map
let obj = { a: 1 };
let obj2 = obj;
const map = new Map();
map.set(obj, 'obj');
obj = null;
obj2 = null;
console.log(map);
好了,我们现在再看弱引用的特点:
- 代码执行
const obj = { a: 1 },此时{ a: 1 }对象被引用的次数为1。 - 代码执行
const obj2 = obj,此时{ a: 1 }对象被引用的次数为2。 - 代码执行
wm.set(obj, 'obj'),特别注意:由于weakMap对象的键名是弱引用,所以垃圾回收机制不会对其计数,所以现在{ a: 1 }对象被引用的次数依旧是2。 - 如果我现在断开
obj/obj2对{ a: 1 }对象的引用,此时weakMap中还存在{a:1}的键名吗?换句话说,{a:1}对象是否被垃圾回收机制清除了吗? - 由于
weakMap的键名是弱引用,所以理论上weakMap中应该不存在以{a:1}对象形式的键名了。因为我手动解除了变量obj/obj2对{a:1}的引用,此时{a:1}对象被引用的次数为0次。所以垃圾回收机制会清除{a:1}对象,一旦{a:1}对象被清除掉,那么weakMap中也就不存在{a:1}对象。 - 实际上我们从控制台的表现来看,与我们预期的结果并不相符。这是为什么呢?这是因为我们说过垃圾回收机制的时机是不可预测的。我们手动解除引用并不能够触发垃圾回收机制,垃圾回收机制是不可预测的。所以,你还是能够看到
weakMap中存在{a:1}对象。
// WeakMap
let obj = { a: 1 };
let obj2 = obj;
const wm = new WeakMap();
wm.set(obj, 'obj');
obj = null;
obj2 = null;
console.log(wm);

那么如何能够测试垃圾回收机制是否真的清除了{a:1}对象呢?其实也很简单,虽然垃圾回收机制的执行时机不可预测,但是我们可以延迟一段时间再去打印weakMap。例如:
延时10s之后,我们发现weakMap中并不存在任何键值对了。这说明什么问题?这说明了weakMap的键名的的确确是弱引用,垃圾回收机制对weakMap键名的引用并不会计数。当外界的引用都清除完后,垃圾回收机制在不可预测的时刻将{a:1}对象进行清除。因为垃圾回收机制是不可预测的,所以你测试的时候,会发现weakMap中有时候存在键值对,有时候又不存在任何键值对的情况。
let obj = { a: 1 };
let obj2 = obj;
let wm = new WeakMap();
wm.set(obj, 'obj');
obj = null;
obj2 = null;
setTimeout(() => {
console.log(wm);
}, 10000);
console.log(wm);

特别重要:
可能你没有注意到一个问题。为什么Map中存在keys、entries、values、forEach、clear、size这些属性和方法,而WeakMap中却不存在这些方法和属性呢?
因为WeakMap的键名是弱引用,所以对于WeakMap来说,它内部的数据结构是不稳定的。weakMap内部的键名受到外界的影响,如果外界的引用发生断裂,那么WeakMap内部的数据将会随之发生变化,而对于这些需要依赖数据的方法和属性来说,数据的不稳定性导致它们没有存在的意思。所以你会发现WeakMap中并没有以上的方法和属性。
特别重要:
在WeakMap中我们讨论的是键名的弱引用特点,并没有讨论键值的问题。其实讨论键值的引用性并不没有什么意思。比如说下面例子中的两种方式,一种是wm.set(obj, obj3)的方式,另一种是wm.set(obj, {a:3})。当手动解除obj/obj2引用的时候,两种方式中的{a:3}对象会不会被垃圾回收机制清除呢?
首先第一种方式,虽然解除了obj/obj2的引用,垃圾回收机制会回收{a:1}对象,但是对于键值中的{a:3}对象并不会受到影响,因为此时外界let obj3 = {a:3}中的obj3变量还引用着{a:3}对象,{a:3}对象的引用次数是1。
其次是第二种方式,当解除了obj/obj2的引用,垃圾回收机制会回收{a:1}对象。因为weakMap中的{a:1}键名被清除,所以随之{a:3}的键值失去引用,{a:3}的引用次数为0次。所以{a:3}对象会被垃圾回收机制回收。
let obj = { a: 1 };
let obj2 = obj;
let obj3 = { a: 3 };
let wm = new WeakMap();
// 不会清除{a:3}
wm.set(obj, obj3);
// 会清除{a:3}
wm.set(obj, {a:3});
obj = null;
obj2 = null;
Map 与普通对象的区别
Map 存在的意义
首先我们要弄清楚为什么存在Map,Map存在的意义是什么呢?可能普遍的人都认为Map存在的原因是因为:普通对象Object的键名只能是string、Symbol类型,而Map的键名是任意类型。如果想要存储键名是对象类型的数据,那么就要用到Map对象去处理。
显然理解到这里是不够的,还是不能够表明Map存在的意义。Map其实与面向对象的关系比较紧密,比如说我现在有两个类Person、Grade,然后通过这两个类创建实例化对象,我现在想将这两个类实例化出来的对象进行对应的存储起来。例如:Person1 => Grade; Person2 => Grade2,此时Map的功能就体现出来了,Person1 => Grade是紧密相关的两个对象,我们要对应的去保存,所以现在只有通过Map的方式进行存储比较合理。
当我们知道Map实际上是与面向对象息息相关的时候。我们回头再看下面的两种数据结构,你觉得是第一种数据结构好呢?还是第二种数据结构好呢?那自然是第一种数据结构好。
// 数据结构一
{
{ a: 1 }: '[\'a\', 1]'
}
// 数据结构二
{
a: {
value:1,
expression: '[\'a\', 1]'
}
}
Map 与 Object 对比
object和Map类似的是,它们都允许你按键存取一个值、删除键、检测一个键是否绑定了值。因此我们过去一直都把对象当成Map使用。
不过Map和object有一些重要的区别,在下列情况中使用Map会是更好的选择:
- 意外的键
什么叫意外的键呢?我们分别针对Map和object来分析什么是意外的键?
**object**:一个object有一个原型,也就是[[prototype]]属性,在object上设置的键名可能与[[prototype]]属性上的键名产生冲突。比如说下面的例子:
我们可以看到object对象自身的属性键名a与[[prototype]]上的属性键名a产生冲突。虽然你可以通过Object.create(null)去创建一个不存在[[prototype]]属性的对象,但是这种方式是不太常见的。
const obj = {
a:1
}
Object.prototype.a = 100;

**map**:Map默认情况不包含任意键。只包含显式插入的键。首先我们创建了一个map,我们发现map本身存在[[Entries]]属性,这个[[Entries]]属性表示的是什么呢?[[Entries]]属性其实表示Map中的键值对形式。此时很显然Map对象中是不存在任何键值对形式,但是Map对象上还存在size属性。这就有点与普通的object类似了,难道我们也能直接通过map.xxx的方式去在map对象上添加属性吗?

实际上通过map.xxx的形式给map对象添加属性是可以的,比如说我通过map.a = 100的方式给map添加了a属性。此时map对象的形式是什么样子的呢?很显然我们能够看到map对象自身存在了a属性,但是我们发现[[Entries]]属性里依旧是不存在任何键值对。这说明什么问题呢?这说明Map对象的键值对是存储在[[Entries]]属性内部,并不受外界的影响。map默认情况下是不包含任何键值对的,只包含显式插入的值。所以,为什么Map读取存储键值对是通过get、set函数,而不是像对象通过. or []的方式去存储属性,因为Map的键值对是存储在[[Entries]]属性中的,而不是Map对象自身。

- 键值的类型
**object**:一个object的键必须是一个string或者是Symbol类型。
**Map**:一个Map的键可以是任意值,包括函数、对象或任意基本类型。
- 键的顺序
**object**:我们说过object本质上是无序的。虽然object的键目前是有序的,但并不总是这样,而且这个顺序是复杂的。因此,最好不要依赖属性的顺序。
自ECMAScript 2015规范以来,对象的属性被定义为是有序的;ECMAScript 2020则额外定义了继承属性的顺序。虽然我们看到对象属性被定义有序的,但是对象依旧是无序的,是不可迭代的。for...in仅包含了以字符串为键的属性;Object.keys仅包含了对象自身的、可枚举的、以字符串为键的属性。Object.getOwnPropertyNames包含了所有以字符串为键的属性,即使是不可枚举的。Object.getOwnPropertySymbols与前者类似,但是包含的是symbol为键的属性。
**Map**:Map对象中的键是有序的,是可以进行迭代的。当迭代的时候,一个Map对象以set插入的顺序返回键值。
- size属性
**object**:object的键值对个数只能动手计算,但是我们可以通过Object.keys()方法来获取对象自身可枚举属性的个数。
**Map**:Map的键值对个数可以轻易地通过Size属性获取。
- 迭代
**object**:object因为是无序的,所以不可以被迭代,所以使用JavaScript中的for...of表达式并不能够直接迭代对象。
- 当然你可以手动实现迭代协议,或者你可以使用
Object.keys()或者Object.entries()方法。 for...in表达式允许你迭代一个对象的可枚举属性。
可能有人会问,不是说obj不可迭代吗?为什么你直接用for...of去迭代obj呢?注意看清楚吖,我迭代的是什么东西,我迭代的对象是Object.entries(obj)方法返回的二维键值对数组,数组是有序的,当然可以被迭代,而且还可以通过解构的方式获取到键值对。
const obj = {
a:1,
b:2
};
for (let [key, value] of Object.entries(obj)) {
console.log(key, value);
}
**Map**:Map是有序的,是可以被迭代的。为什么Map是可以迭代的呢?因为Map.prototype实现了迭代接口Symbol.iterator,所以Map可以直接通过for...of进行迭代。
const map = new Map();
map.set({a:1}, 'a:1');
map.set({a:2}, 'a:2');
for (let [key, value] of map) {
console.log(key, value); // {a:1}, 'a:1' {a:2} 'a:2'
}
- 性能
**object**:在频繁添加和删除键值对的场景下未作出优化。
**Map**:在频繁增删键值对的场景下表现更好。
- 序列化和解析
**object**:原生的由object到JSON的序列化支持,使用JSON.stringify()。原生的由JSON到object的解析支持,使用JSON.parse()。
**Map**:没有元素的序列化和解析支持,但是你可以使用携带的replacer参数的JSON.stringify创建一个自己的对Map的序列化和解析支持。
const map = new Map();
map.set({a:1}, 'a:1');
map.set({a:2}, 'a:2');
// 字符串序列化
const str = JSON.stringify(map, function(key, value) {
if (value instanceof Map) {
return {
key: 'Map',
value:[...value.entries()]
};
}
return value;
});
// 对象序列化
const parseMap = JSON.parse(str, function(key, value) {
if (value !== null && typeof value === 'object') {
if (value.key === 'Map') {
return new Map(value.value);
}
}
return value;
});
console.log(parseMap);
Map、Set、weakMap、WeakSet 的使用
Map 对象
Map对象保存键值对,并且能够记住键的原始插入顺序。任何值(对象或者基本类型)都可以作为一个键或者一个值。
Map对象是键值对的集合。Map中的一个键只能出现一次;它在Map的集合中是独一无二的。Map对象按键值对迭代——一个for...of循环在每次迭代后会返回一个形式为[key, value]的数组。迭代按照插入顺序进行,即键值对按set()方法首次插入到集合中的顺序(也就是说,当调用set时,map中没有具有相同值的键)进行迭代。
我们通常见到的键值对只是a:1的这种形式,实际上[a, 1] { a => 1 }这种形式都是键值对的形式。
键的相等性
Map键的比较基于零值相等算法。(它曾经使用同值相等,将0和-0视为不同。检查浏览器兼容性。)这意味着NaN是与NaN相等的,虽然NaN !== NaN,剩下所有的其它的值是根据===运算符的结果判断是否相等。
**Map**构造函数中的参数
Map构造函数中的参数接收二维数组,数组内部是以键值对的形式存在的,例如:
const map = new Map([
[{}, '1'],
['too', 'bar'],
[true, 'false'],
]);
**Map**实例属性、实例方法
Map实例属性size:返回Map对象中的键值对数量,注意是[[Entries]]属性内部的键值对数量,并不是Map对象自身上的属性数量。
Map实例方法:
clear:移除Map对象中所有的键值对。delete:移除Map对象中指定的键值对,如果键值对存在并成功被移除,返回true,否则返回false。调用delete后再调用map.has(key)将返回false。has:返回一个布尔值,用来表明Map对象中是否存在与指定的键key关联的值。get:返回与指定的键key关联的值,若不存在关联的值,则返回undefined。set:在Map对象中设置与指定的键key关联的值,并返回Map对象。keys:返回一个新的迭代对象,其中包含map对象中所有的键,并以插入Map对象的顺序排列。values:返回一个新的迭代对象,其中包含map对象中所有的值,并以插入Map对象的顺序排列。entries:返回一个新的迭代对象,其为一个包含map对象中所有键值对的[key, value]数组,并以插入Map对象的顺序排列。forEach:以插入的顺序对Map对象中存在的键值对分别调用一次callbackFn。如果给定了thisArg参数,这个参数将会是回调函数中的this值。
const map = new Map();
map.set({a:1}, 'a:1');
map.set({a:2}, 'a:2');
map.forEach((key, value)=>{
console.log(key, value); // a:1 {a:1}
});
Set 对象
set对象允许你储存任何类型的唯一值,无论是原始值或者是对象引用。
set对象是值的集合,所以set是不存在键的。你会发现set对象中并不存在get、set方法,只是存在add、has方法。
set对象是值的集合,你可以按照插入的顺序迭代它的元素。Set中的元素只会出现一次,即Set中的元素是唯一的。
值的相等
因为Set中的值总是唯一的,所以需要判断两个值是否相等。在ECMAScript规范的早期版本中,这不是基于和===操作符中使用的算法相同的算法。具体来说,对于Set,+0(+0严格相等于-0)和-0是不同的值。然而,在ECMAScript 2015规范中这点已被更改。换句话说,现在的浏览器在Set中认为+0 0 -0都是相同的。
另外,NaN和undefined都可以被存储在Set中,NaN之间被视为相同的值NaN被认为是相同的,尽管NaN !== NaN
**set**构造函数参数
set构造函数接收一个可迭代对象,可迭代对象内部的元素将成为Set对象的元素。
set对象中是不存在键的,虽然你在浏览器中会发现[[Entries]]属性中会存在0,1,2,3这种类似键名的东西。这只是浏览器给你展示出键值对的效果而已,实际上Set对象并不存在键。
const set = new Set(1); // 报错
const set = new Set([1, 2, 3, undefined, NaN, {}]);
console.log(set);

**Set**实例属性、实例方法
Set实例属性size:返回Set对象中值的个数。注意是[[Entries]]属性内部值的个数,并不是Set对象自身的属性个数。
Set实例方法:
add:在Set对象尾部添加一个元素。返回该set对象。clear:移除set对象内部的所有元素。delete:移除值为value的元素,并返回一个布尔值来表示是否移除成功。Set.prototype.has(value)会在此之后返回false。has:返回一个布尔值,表示该值在Set中存在与否。keys:与values()方法相同,返回一个新的迭代器对象,该对象包含set对象中的按插入顺序排列的所有元素的值。values:返回一个新的迭代对象,该对象包含set对象中的按插入顺序排列的所有元素的值。entries:返回一个新的迭代对象,该对象包含Set对象中的按插入顺序排列的所有元素的值的[value, value]数组。为了使这个方法和Map对象保持相似,每个值的键和值相同。因为set对象是不存在键的。forEach:按照插入的顺序,为Set对象中的每一个值调用一次callbackFn。如果提供了thisArg参数,回调中的this会是这个参数。
const set = new Set([1, 2, false, 'true', 'str']);
set.forEach((key, value) => {
console.log(key, value); // 1, 1 2, 2 false, false
});
weakMap / weakSet
weakMap/weakSet我们在弱引用知识中已经介绍过它们的特点了。
所以我们在这里只是总结一下实例方法:
weakMap:
delete:删除weakMap中与key相关联的值。删除之后,weakMap.prototype.has(key)将会返回false。get:返回weakMap中与key相关联的值,如果key不存在则返回undefined。has:返回一个布尔值,断言一个值是否已经与weakMap对象中的key关联。set:给weakMap中的key设置一个value。该方法返回一个weakMap对象。
至于为什么WeakMap对象不存在forEach、clear、keys、values、entries方法,我们在弱引用知识中已经介绍过了。
weakSet:
weakSet对象是一些对象值的集合。且其与set类似,WeakSet中每个对象值都只能出现一次。在WeakSet的集合中,所有对象都是唯一的。
它和set对象的主要区别在于:
WeakSet只能是对象的集合,而不像Set那样,可以是任何类型的任意值。WeakSet持弱引用:集合中的对象的引用为弱引用。如果没有其它的对WeakSet中对象的引用,那么这些对象将会被垃圾回收机制回收掉。所以WeakSet也不存在keys、entries、values、forEach、size属性或者方法。
weakSet实例方法:
add:将value添加到WeakSet对象最后一个元素的后面。delete:从weakSet中移除value。此后调用has方法,将返回false。has:返回一个布尔值,表示value是否存在于weakSet对象中。