redis实现主从复制的解析介绍
前面说到了redis在单机的模式下是可以数据持久化的,但是不可以解决单点失败的问题,当单台redis服务器出现问题时,就可能会造成数据的丢失;想要解决这个问题的话我们可以使用Redis的主从模式这也是Redis集群最简单的实现方式,这篇文章我就来简单部署一个Redis主从架构,我准备了3台ubuntu1804的主机,IP地址分别为10.0.0.{101,102,103},主机名分别为master,slave1,slave2。
目录
1、脚本安装redis
2、Redis主从复制
2.1、默认redis状态
2.2、实现Redis主从复制
2.2.1客户端命令行配置
2.2.2修改配置文件
3、主从复制故障与恢复
3.1、从节点故障与恢复
3.2、主节点故障与恢复
4、主从复制的优化
4.1、主从复制过程
4.1.1、全量复制的过程
4.1.2、增量复制的过程
4.1.3、主从同步完整过程
4.2、主从复制的主要事项
4.2.1、避免全量复制
4.2.2、避免复制的风暴
4.3、主从复制优化配置
5、常见主从复制故障
5.1、master密码不对
5.2、redis版本不一致
5.3、无法远程连接
5.4、配置不一致
1、脚本安装redis
#!/bin/bash
#REDIS_VERSION=redis-7.0.5
#REDIS_VERSION=redis-7.0.3
#REDIS_VERSION=redis-6.2.6
REDIS_VERSION=redis-5.0.14
#REDIS_VERSION=redis-4.0.14
REDIS_URL=http://download.redis.io/releases
PASSWORD=123456
INSTALL_DIR=/apps/redis
CPUS=`lscpu |awk '/^CPU\(s\)/{print $2}'`
. /etc/os-release
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$1" && $MOVE_TO_COL
echo -n "["
if [ $2 = "success" -o $2 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $2 = "failure" -o $2 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
prepare(){
if [ $ID = "centos" -o $ID = "rocky" ];then
yum -y install gcc make jemalloc-devel systemd-devel
else
apt update
apt -y install gcc make libjemalloc-dev libsystemd-dev
fi
if [ $? -eq 0 ];then
color "安装软件包成功" 0
else
color "安装软件包失败,请检查网络配置" 1
exit
fi
}
install() {
if [ ! -f ${REDIS_VERSION}.tar.gz ];then
wget ${REDIS_URL}/${REDIS_VERSION}.tar.gz || { color "Redis 源码下载失败" 1 ; exit; }
fi
tar xf ${REDIS_VERSION}.tar.gz -C /usr/local/src
cd /usr/local/src/${REDIS_VERSION}
make -j $CUPS USE_SYSTEMD=yes PREFIX=${INSTALL_DIR} install && color "Redis 编译安装完成" 0 || { color "Redis 编译安装失败" 1 ;exit ; }
ln -s ${INSTALL_DIR}/bin/redis-* /usr/bin/
mkdir -p ${INSTALL_DIR}/{etc,log,data,run}
cp redis.conf ${INSTALL_DIR}/etc/
sed -i -e 's/bind 127.0.0.1/bind 0.0.0.0/' -e "/# requirepass/a requirepass $PASSWORD" -e "/^dir .*/c dir ${INSTALL_DIR}/data/" -e "/logfile .*/c logfile ${INSTALL_DIR}/log/redis-6379.log" -e "/^pidfile .*/c pidfile ${INSTALL_DIR}/run/redis_6379.pid" ${INSTALL_DIR}/etc/redis.conf
if id redis &> /dev/null ;then
color "Redis 用户已存在" 1
else
useradd -r -s /sbin/nologin redis
color "Redis 用户创建成功" 0
fi
chown -R redis.redis ${INSTALL_DIR}
cat >> /etc/sysctl.conf < /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.d/rc.local
chmod +x /etc/rc.d/rc.local
/etc/rc.d/rc.local
else
echo -e '#!/bin/bash\necho never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
chmod +x /etc/rc.local
/etc/rc.local
fi
cat > /lib/systemd/system/redis.service < /dev/null
if [ $? -eq 0 ];then
color "Redis 服务启动成功,Redis信息如下:" 0
else
color "Redis 启动失败" 1
exit
fi
sleep 2
redis-cli -a $PASSWORD INFO Server 2> /dev/null
}
prepare
install#查看redis是否启用
[root@slave2 ~]#systemctl status redis.service● redis.service - Redis persistent key-value database Loaded: loaded (/lib/systemd/system/redis.service; enabled; vendor preset: enabled) Active: active (running) since Wed 2022-11-02 15:14:08 CST; 10min ago Main PID: 12529 (redis-server) Tasks: 4 (limit: 2236) Memory: 1.7M CGroup: /system.slice/redis.service └─12529 /apps/redis/bin/redis-server 0.0.0.0:6379
11月 02 15:14:08 ubuntu2004 systemd[1]: Starting Redis persistent key-value database...11月 02 15:14:08 ubuntu2004 systemd[1]: Started Redis persistent key-value database. 2、Redis主从复制
Redis的主从模式是可以实现Redis的数据跨主机备份,在配置主从的时候,从节点是需要开启数据持久化并设置和主节点同样的连接密码。

2.1、默认redis状态
刚安装好后的redis三台机器都是master状态,可以进到客户端查询一下

2.2、实现Redis主从复制
实现Redis的主从复制是有两种方式的,一种你可以通过命令行来配置,这样配置的话是临时生效,命令行配置的话重启Redis服务就没有用了,但是同步过来的数据还是会保留的;另一种就是修改redis的配置文件来使其生效,这样的话即使重启redis服务主从的关系还在的。
2.2.1客户端命令行配置
准备点数据
[root@master ~]#redis-cli -a 123456
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
127.0.0.1:6379> mset k1 v1 k2 v1 k3 v3
OK
127.0.0.1:6379> dbsize
(integer) 3使用命令行启用主从
127.0.0.1:6379> replicaof 10.0.0.101 6379
OK
127.0.0.1:6379> INFO replication
# Replication
role:slave #角色已经变成了slave,但是状态还是down,这时需要设置下主节点的连接密码才能变成up
master_host:10.0.0.101
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:1
master_link_down_since_seconds:1667376380
slave_priority:100
slave_read_only:1
connected_slaves:0
slave2节点同样操作

在master节点查看主从状态

查看连接状态

复制测试,发现之前的数据已经同步过来了


取消主从同步
我们是可以通过从节点执行replicaof no one命令即可取消主从复制,修改完后角色会变成master,并且之前同步的数据是不会丢的。

2.2.2修改配置文件
我们在前面使用了命令行实现了主从复制,命令行配置是有缺陷的,当从节点的redis服务重启后就失效了;为了解决这个缺陷我们可以将命令行配置的内容加到配置文件中,在重启一下redis服务让其读取配置文件。
[root@slave2 ~]#echo -e "replicaof 10.0.0.101 6379\nmasterauth 123456" >> /apps/redis/etc/redis.conf
[root@slave2 ~]#tail -2 /apps/redis/etc/redis.conf
replicaof 10.0.0.101 6379
masterauth 123456
[root@slave2 ~]#systemctl restart redis.service登录上去查看主从关系

3、主从复制故障与恢复
3.1、从节点故障与恢复
当从节点出现故障时,只需将Redis客户端指向其他的从节点就可以了,并不会对整体的架构的读操作进行太大的影响,即使所有的从节点出现故障,也可以直接访问主节点进行读的操作;不过一般从节点出现故障后,除了一些特殊情况一般都会尽快的修复好,从而减轻其他节点的工作负载。

3.2、主节点故障与恢复
当我们的主节点故障时,我们可以将一个从节点提升为新的主节点,在将另一个从节点指向到新的主节点,当原来的主节点修复好了后,把Redis服务起来后会发现恢复到了单机的状态,并且只有之前的数据。过程和之前一样我就不做演示了。
如果现在想要将原的主节点变成现有的主从架构的从节点,这样的话就可以将新的主节点(slave1)的数据同步过来了;但是想要保持之前的原节点不变的话,就需要将现在的主从架构中的节点都指向原节点,并且刚刚新增的key也就会丢失;这里我们可以保持原先的master节点为主节点为例,这里可以把slave2设置成原master节点的从节点,我们也是可以直接把现在新主节点(slave1)设置成原master节点的从节点,这样的话就形成了级联复制,这样的话slave可以不用修改配置,这样的话slave2是从slave1来同步数据,而slave1从master节点同步数据。
4、主从复制的优化
4.1、主从复制过程
Redis主从复制可以分为全量同步和增量同步。
4.1.1、全量复制的过程

第一次都是需要主从同步是全量同步的,主从同步可以让从节点到主节点进行同步数据,而且从节点也可以有从节点,也就是前面演示的级联复制的架构;
Redis的主从同步是非阻塞的,master节点收到从服务器的psync(在2.8版本之前是SYNC)命令,会fork一个子进程在后台执行bgsave命令,并将新写入的数据先写入到一个缓冲区中,bgsave执行完成之后,再将生成的RDB文件发送给slave节点,然后master节点再将缓冲区的内容以redis协议格式再全部发送给slave节点,slave节点先删除旧数据,slave节点将收到后的RDB文件载入自己的内存,再加载所有收到缓冲区的内容,从而这样一次完整的数据同步。
Redis全量复制一般发生在Slave首次初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
4.1.2、增量复制的过程
在全量同步之后再次需要同步时,从服务器只要发送当前的offset位置(等同于MySQL的binlog的位置)给主服务器,然后主服务器根据相应的位置将之后的数据(包括写在缓冲区的积压数据)发送给从服务器,再次将其保存到从节点内存即可。
4.1.3、主从同步完整过程
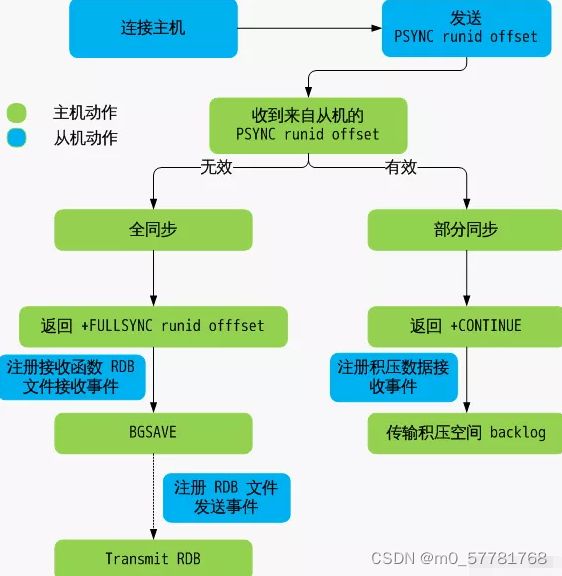
- 从服务器连接主服务器,发送PSYNC命令。
- 当主服务器接收到PSYNC命令后,开始执行BGSAVE命令生成RDB快照文件并使用缓冲区记录此后执行的所有写命令。
- 当主服务器BGSAVE执行完后,向所有从服务器发送RDB快照文件,并在发送期间继续记录被执行的写命令。
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照至内存。
- 主服务器快照发送完毕后,开始向从服务器发送缓冲区中的写命令。
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令。
- 后期同步会先发送自己slave_repl_offset位置,只同步新增加的数据,不再全量同步。
4.2、主从复制的主要事项
4.2.1、避免全量复制
- 第一次的全量复制是没法避免的,后续的全量复制是可以利用小主节点(内存小),尽量在业务低峰时进行全量复制;
- 在主节点重启后会发现运行的ID发生了变化,可能会触发全量复制,可以利用故障转移,例如哨兵或者集群的方式,而从节点重启的话是不会导致全量复制的;
- 当复制积压缓冲区不足时,主节点生成的新数据大与缓冲区的大小,从节点恢复和主节点连接后,这样会导致全量复制,这个是可以修改repl-backlog-size的值来解决,将其值调大。
4.2.2、避免复制的风暴
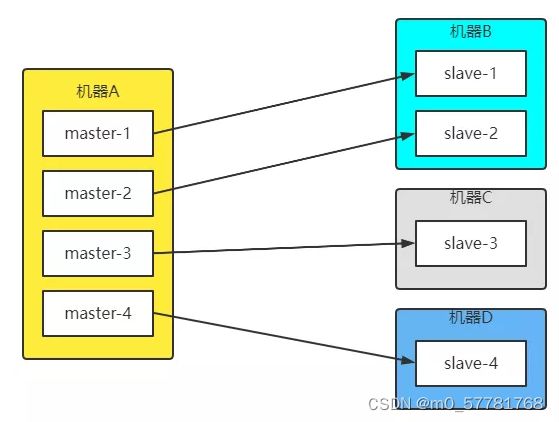
单主节点复制的风暴:当主节点重启后,多个从节点会同时从主节点复制数据,这样的话是会带来复制风暴,解决方式可以更换复制的架构,比如可以使用级联复制的架构。

单机器多实例的复制风暴:当服务器出现宕机时,后面有修复了,这样的话就会进行大量的全量复制,并引发复制风暴,解决的方法是主节点分散多机器。
4.3、主从复制优化配置
repl-diskless-sync no # 是否使用无盘同步RDB文件,默认为no,no为不使用无盘,需要将RDB文件保存到磁盘后再发送给slave,yes为支持无盘,支持无盘就是RDB文件不需要保存至本地磁盘,而且直接通过socket文件发送给slave
repl-diskless-sync-delay 5 #diskless时复制的服务器等待的延迟时间
repl-ping-slave-period 10 #slave端向server端发送ping的时间间隔,默认为10秒
repl-timeout 60 #设置主从ping连接超时时间,超过此值无法连接,master_link_status显示为down,并记录错误日志
repl-disable-tcp-nodelay no #是否启用TCP_NODELAY,如设置成yes,则redis会合并小的TCP包从而节省带宽, 但会增加同步延迟(40ms),造成master与slave数据不一致,假如设置成no,则redis master会立即发送同步数据,没有延迟,yes关注网络性能,no关注redis服务中的数据一致性
repl-backlog-size 1mb #master的写入数据缓冲区,用于记录自上一次同步后到下一次同步过程中间的写入命令,计算公式:repl-backlog-size = 允许从节点最大中断时长 * 主实例offset每秒写入量,比如master每秒最大写入64mb,最大允许60秒,那么就要设置为64mb*60秒=3840MB(3.8G),建议此值是设置的足够大
repl-backlog-ttl 3600 #如果一段时间后没有slave连接到master,则backlog size的内存将会被释放。如果值为0则 表示永远不释放这部份内存。
slave-priority 100 #slave端的优先级设置,值是一个整数,数字越小表示优先级越高。当master故障时将会按照优先级来选择slave端进行恢复,如果值设置为0,则表示该slave永远不会被选择。
min-replicas-to-write 1 #设置一个master的可用slave不能少于多少个,否则master无法执行写
min-slaves-max-lag 20 #设置至少有上面数量的slave延迟时间都大于多少秒时,master不接收写操作(拒绝写入)5、常见主从复制故障
5.1、master密码不对
即主节点在Redis配置文件中设置的requirepass部分,从节点在执行主从同步命令时或者修改配置文件时未添加正确,则会导致无法建立主从同步关系。
5.2、redis版本不一致
不同的redis大版本之间是会存在兼容性的问题的,例如大版本3和大版本4之间,大版本4和大版本5之间,因此各master节点和slave节点之间必须保持版本的一致。
5.3、无法远程连接
当在开启了安全模式的情况下,没有设置bind地址或者密码的话,外部是访问不了的,也就是没办法远程连接。
5.4、配置不一致
- 当主从节点的maxmemory不一致,主节点的内存大雨从节点的内存时,这样就可能会出现主从复制丢失数据的情况。
- 主从节点的rename-command命令不一致,例如在主节点定义了flushall,flushdb,而在从节点上没有定义,这样的话在主节点执行flushall或者flushdb的话,在从节点的数据是没有同步的。