openswan中的in_struct和out_struct函数
openswan中的in_struct和out_struct函数
文章目录
-
- openswan中的in_struct和out_struct函数
-
- 1. 花絮
- 2. in_struct代码实现分析
- 3. 它到底几个意思?
-
- 3.1 为什么这么做?
- 3.2 它的实现原理
-
- 3.2.1 sakmp头部描述说明
- 3.2.2 sakmp头部载荷取值范围
- 3.2.3 isakmp头部中标记位处理
- 3.2.4 参数obj_pbs干什么的?
1. 花絮
有什么比openswan中的in_struct和out_struct更让人难以理解的呢??? 如果存在的话,那就是:女朋友为啥又生气了?

算了,不管了,今天我是找不到她生气的原因了;还是把openswan中的in_struct()函数整理下吧,感觉这个更容易些

在学习openswan源码的过程中,有两个函数是想逃不能逃的,但是有很难看懂它是怎么个原理,它的功能很明确,但是就算如此,还是看不懂它的原理。我看这个接口花了很长的时间。哎,没办法,基础有点菜。下面就把个人的心得分享下:
2. in_struct代码实现分析
在源代码中in_struct和out_struct都有一段较为详细的注释:
/* "parse" a network struct into a host struct.
*
* This code assumes that the network and host structure
* members have the same alignment and size! This requires
* that all padding be explicit.
*
* If obj_pbs is supplied, a new pb_stream is created for the
* variable part of the structure (this depends on their
* being one length field in the structure). The cursor of this
* new PBS is set to after the parsed part of the struct.
*
* This routine returns TRUE iff it succeeds.
*/
这里对in_struct进行描述:它的功能也比较明确:
将网络字节序结构体转换为主机字节序结构体
这里假设网络结构体和主机结构体拥有相同的对齐方式和大小, 这要求他们所有的填充字节都是明确的。
如果参数obj_pbs是非空,则会创建一个新的pb_stream结构。它用来描述ins中sd的部分,但是cur指针是指向已经解析完毕的数据后后一个字节。
操作成功返回TRUE
是的,它转换的是结构体,而不是单个的short类型或者int类型。这样处理更加方便,模块化。简单的说:
htonl(), htons()分别转换的为四个字节,两个字节类型的变量,而in_struct(), out_struct()一次性转换一个结构体。只要你传入的结构体描述信息(struct_desc)正确就可以
也许我们对这个种方式不习惯,但是它的好处大大滴。既然使用了人家代码,那就接收人家的规则。
很多刚开始看的人不明白为什么要使用“obj_pbs”形参,既然解析完毕了为什么还要保存该信息呢???

实际上这个操作在变长的载荷中是必须的,因为变长部分数据并没有被转换到struct_ptr中。下面慢慢说明:
我是直接在源码上进行的注释:
/****************************************************
* 功能: 将网络字节序结构体转化为主机字节序结构体
* struct_ptr: 解析后的输出数据
* sd : 描述信息
* ins : 输入的网络字节序数据流
* obj_pbs : 指向该结构后面尚未解析的ins数据部分
*****************************************************/
bool
in_struct(void *struct_ptr, struct_desc *sd
, pb_stream *ins, pb_stream *obj_pbs)
{
err_t ugh = NULL;
u_int8_t *cur = ins->cur;/*待解析数据开始*/
/*确保有待解析的数据大小足够,否则无法成功解析为sd描述的大小*/
if (ins->roof - cur < (ptrdiff_t)sd->size)
{
ugh = builddiag("not enough room in input packet for %s"
" (remain=%li, sd->size=%zu)"
, sd->name, (long int)(ins->roof - cur), sd->size);
}
else
{
/*root指向待解析数据的末尾*/
u_int8_t *roof = cur + sd->size; /* may be changed by a length field *//*未考虑变长属性*/
u_int8_t *outp = struct_ptr;/*outp指向输出结构体*/
bool immediate = FALSE;
field_desc *fp;
for (fp = sd->fields; ugh == NULL; fp++)
{
size_t i = fp->size;
/*passert条件成立,继续执行;不成立,直接退出*/
passert(ins->roof - cur >= (ptrdiff_t)i);
passert(cur - ins->cur <= (ptrdiff_t)(sd->size - i));
passert(outp - (cur - ins->cur) == struct_ptr);/*解析长度相同*/
switch (fp->field_type)
{
case ft_mbz: /* must be zero *//*全零域,*/
for (; i != 0; i--)
{
if (*cur++ != 0)
{
ugh = builddiag("byte %d of %s must be zero, but is not"
, (int) (cur - ins->cur), sd->name);
break;
}
*outp++ = '\0'; /* probably redundant */
}
break;
case ft_zig: /* should be zero, ignore if not *//*全零域,如果不是可以忽略其数值*/
for (; i != 0; i--)
{
if (*cur++ != 0)
{
openswan_log("byte %d of %s should have been zero, but was not"
, (int) (cur - ins->cur), sd->name);
/*
* We cannot zeroize it, it would break our hash calculation
* *cur = '\0';
*/
}
*outp++ = '\0'; /* probably redundant */
}
break;
case ft_nat: /* natural number (may be 0) */
case ft_len: /* length of this struct and any following crud */
case ft_lv: /* length/value field of attribute */
case ft_enum: /* value from an enumeration */
case ft_np: /* value from an enumeration */
case ft_np_in: /* value from an enumeration */
case ft_loose_enum: /* value from an enumeration with only some names known */
case ft_af_enum: /* Attribute Format + value from an enumeration */
case ft_af_loose_enum: /* Attribute Format + value from an enumeration */
case ft_set: /* bits representing set */
{
u_int32_t n = 0;
/* Reportedly fails on arm, see bug #775 */
for (; i != 0; i--)
n = (n << BITS_PER_BYTE) | *cur++;/*根据该属性的长度来获取值: 单字节、双字节、四字节*/
/*此处已经实现了字节序的转换(ntohl, ntohs)*/
switch (fp->field_type)/*ikev2_trans_attr_fields*/
{
case ft_len: /* length of this struct and any following crud *//*通用载荷头部*/
case ft_lv: /* length/value field of attribute *//*属性载荷头部*/
{/*载荷长度字段,此处是长度可变载荷,无法预定义长度,因此需要更新长度信息*/
u_int32_t len = fp->field_type == ft_len? n
: immediate? sd->size : n + sd->size;
if (len < sd->size)
{
ugh = builddiag("%s of %s is smaller than minimum"
, fp->name, sd->name);
}
else if (pbs_left(ins) < len)
{
ugh = builddiag("%s of %s is larger than can fit"
, fp->name, sd->name);
}
else
{
roof = ins->cur + len;/*根据报文中实际的长度定位数据末尾*/
}
break;
}
case ft_af_loose_enum: /* Attribute Format + value from an enumeration */
if ((n & ISAKMP_ATTR_AF_MASK) == ISAKMP_ATTR_AF_TV)/*通过最高位判断该载荷类型,0:变长,1:定长*/
immediate = TRUE;
break;
case ft_af_enum: /* Attribute Format + value from an enumeration */
if ((n & ISAKMP_ATTR_AF_MASK) == ISAKMP_ATTR_AF_TV)
immediate = TRUE;
/* FALL THROUGH */
case ft_enum: /* value from an enumeration */
if (enum_name(fp->desc, n) == NULL)/*判断报文中枚举类型的值是否合法*/
{
ugh = builddiag("%s of %s has an unknown value: %lu"
, fp->name, sd->name, (unsigned long)n);
}
/* FALL THROUGH */
case ft_loose_enum: /* value from an enumeration with only some names known */
break;
case ft_set: /* bits representing set */
if (!testset(fp->desc, n))/*判断报文中某些bit标志位是否合法*/
{
ugh = builddiag("bitset %s of %s has unknown member(s): %s"
, fp->name, sd->name, bitnamesof(fp->desc, n));
}
break;
default:
break;
}
i = fp->size;
switch (i) /*将转后字节序后的报文中的数据存储到输出结构struct_ptr中*/
{
case 8/BITS_PER_BYTE:
*(u_int8_t *)outp = n;
break;
case 16/BITS_PER_BYTE:
*(u_int16_t *)outp = n;
break;
case 32/BITS_PER_BYTE:
*(u_int32_t *)outp = n;
break;
default:
bad_case(i);
}
outp += i;
break;
}
case ft_raw: /* bytes to be left in network-order *//*原始类型报文直接赋值即可,不用区分大小端、不同判断数据是否合法*/
for (; i != 0; i--)
{
*outp++ = *cur++;
}
break;
case ft_end: /* end of field list *//*解析到结构体的末尾*/
passert(cur == ins->cur + sd->size);/*检查解析的长度是否正确*/
if (obj_pbs != NULL)/*如果传入该参数*/
{
/******************************************************************************
*通过init_pbs()将obj_pbs指向ins数据的开始和结束位置,
*然后更新obj_pbs中cur指针为已经解析的位置(确切的说是已经成功解析部分的下一个字节)
*但是如果有变长部分,则cur指向的为变长部分第一个字节;它没有拷贝到传入的struct_ptr中
******************************************************************************/
init_pbs(obj_pbs, ins->cur, roof - ins->cur, sd->name);
obj_pbs->container = ins;
obj_pbs->desc = sd;
obj_pbs->cur = cur;
}
ins->cur = roof;/*更新cur指针到数据的sd结构之后,如果不存在变长载荷应该与cur指的位置相同;存在的话不相同*/
/*注意: 变长载荷数据部分没有继续解析且不能通过ins来获取,但是可以通过obj_pbs来获取变长载荷的数据部分*/
DBG(DBG_PARSING
, DBG_prefix_print_struct(ins, "parse ", struct_ptr, sd, TRUE));
return TRUE;
default:
bad_case(fp->field_type);
}
}
}
/* some failure got us here: report it */
openswan_loglog(RC_LOG_SERIOUS, "%s", ugh);
return FALSE;
}
3. 它到底几个意思?
其实就算看懂了我上面的注释,也许还有有很多疑问:
- 它为什么这么实现?向通常的处理方式那样不行吗?它的目的是什么
- 它这样实现的原理是什么?
要理解几个问题,还真的花费点时间。如果说你对ISAKMP报文格式比较熟悉的话,那么看起来会容易很多;相反如果还不是那么清楚,就有点吃力。而我属于后者,花费了很长时间才略有眉目,因此抓紧记录下来:
3.1 为什么这么做?
它最大的优点我认为是模块化处理,方便维护、扩展。举个例子:
我想在ISAKMP载荷中添加一种新的载荷类型(这是平常的需求),如果我们采用常用的那种网络数据包的解析方式:解析二层头–>解析三层头–>解析四层头—>解析四层数据。这并没有问题,但是如果我要添加一个四层协议呢,是不是需要在所有的四层处理流程中进行修改、添加参数是否合法的判断、解析报文等等。
而采用in_struct这种方式就不需要,只需要按格式添加相应的协议结构体描述信息(该信息中包括了参数取值范围,字段长度,类型等等),它会自动完成参数合法性检验、字节序转换等等(当然正常报文的处理都需要添加)。而不需要像普通的那样每次都得判断参数是否合法、逐个进行字节序转换,极大的提高了代码的利用率。
当然代价也很明显:我等菜鸡们看不懂!!!
3.2 它的实现原理
这个目前我只能把自己的理解分享出来,也许比较浅,但是可以节省点时间。
首先说struct_desc这个结构体,它是解析的关键:

| 序号 | 结构体名称 | 作用 |
|---|---|---|
| 1 | struct desc | 用来描述一个载荷信息:如isakmp头部、sa载荷等等 |
| 2 | field_desc | 用来描述载荷中的一个成员信息(某一个自字段) |
| 3 | field_type | 用来描述载荷中某个成员的类型(与实际的字段类型有关) |
| 4 | enum_names | 该字段的取值范围以及说明(用来判断该成员取值是否合法) |
| 序号 | 枚举类型 | 说明 |
|---|---|---|
| 1 | ft_mbz | 全0类型,比如某一保留位添加0 |
| 2 | ft_nat | 自然数 |
| 3 | ft_len | 长度字段 |
| 4 | ft_lv | 长度/值字段(主要用于变长载荷), 这个处理又有点特殊 |
| 5 | ft_raw | 原始报文,例如cookie,没有字节序问题,直接拷贝即可 |
| 6 | ft_np | 下一个载荷 |
| 7 | ft_end | 结构体描述结束标记 |
| 8 | … | … |
3.2.1 sakmp头部描述说明
ISAKMP头部格式如下:
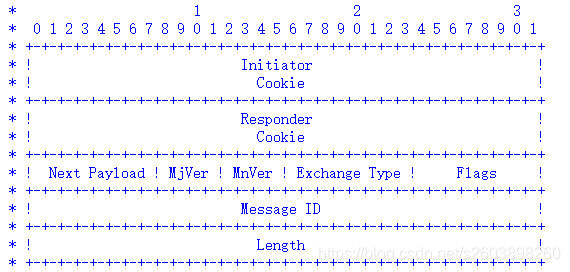
它的结构体描述信息如下:
static field_desc isa_fields[] = {
{ ft_raw, COOKIE_SIZE, "initiator cookie", NULL },/*无字节序取值范围问题,可以直接拷贝*/
{ ft_raw, COOKIE_SIZE, "responder cookie", NULL },/*无字节序取值范围问题,可以直接拷贝*/
{ ft_np_in,8/BITS_PER_BYTE, "next payload type", &payload_names },
{ ft_enum, 8/BITS_PER_BYTE, "ISAKMP version", &version_names },
{ ft_enum, 8/BITS_PER_BYTE, "exchange type", &exchange_names },
{ ft_set, 8/BITS_PER_BYTE, "flags", flag_bit_names },
{ ft_raw, 32/BITS_PER_BYTE, "message ID", NULL },
{ ft_len, 32/BITS_PER_BYTE, "length", NULL },
{ ft_end, 0, NULL, NULL }
};
struct_desc isakmp_hdr_desc = { "ISAKMP Message", isa_fields, sizeof(struct isakmp_hdr) };
说明:
可以看出isa_fields中的每一个成员都对应ISAKMP头部中的一个成员
- Initiator cookie : 无字节序问题、没有取值范围的要求, 类型为ft_raw, 长度为8 (COOKIE_SIZE);
- Responder cookie : 无字节序问题、没有取值范围的要求, 类型为ft_raw, 长度为8 (COOKIE_SIZE);
- Next Payload: 下一载荷,有取值范围要求,因此使用payload_names来说明取值范围
- 版本号:ISAKMP的主次版本号也有要求,因此使用version_names来说明取值范围
- flags: 标记位:加密、认证、提交。有比特位的要求,因此使用flag_bit_names来说明bit位是否使用
- MessageID: 一串字符串,无字节序和取值问题,类型为ft_raw
- Length: 报文长度,为正整数,有字节序问题,因此需要进行字节序转换
3.2.2 sakmp头部载荷取值范围
在上面我们可以知道,ISAKMP头部载荷使用payload_names结构体来说明,下面我们先找出
ISAKMP头部载荷都包括哪些,然后再分析payload_names。
- ISAKMP头部载荷

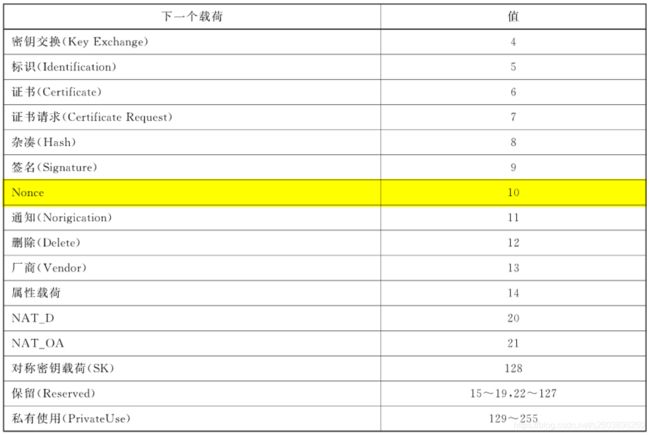
- payload_names结构体
enum_names payload_names =
{ ISAKMP_NEXT_NONE, ISAKMP_NEXT_NATOA_RFC, payload_name, &payload_names_ikev2_main};
static enum_names payload_names_ikev2_main =
{ ISAKMP_NEXT_v2SA, ISAKMP_NEXT_v2EAP, payload_name_ikev2_main, &payload_names_nat_d};
static enum_names payload_names_nat_d =
{ ISAKMP_NEXT_NATD_DRAFTS, ISAKMP_NEXT_NATOA_DRAFTS, payload_name_nat_d, NULL};
实际上这三个变量定义了一个有三个节点的链表,头节点为payload_names:第一个节点是payload_names,第二根节点为payload_names_ikev2_main, 第三个节点为payload_name_nat_d。他们是按功能将上述ISAKMP头部载荷区分划分成三类的。
enum next_payload_types {
ISAKMP_NEXT_NONE = 0, /* No other payload following */
ISAKMP_NEXT_SA = 1, /* Security Association */
ISAKMP_NEXT_P = 2, /* Proposal */
ISAKMP_NEXT_T = 3, /* Transform */
ISAKMP_NEXT_KE = 4, /* Key Exchange */
ISAKMP_NEXT_ID = 5, /* Identification */
ISAKMP_NEXT_CERT = 6, /* Certificate */
ISAKMP_NEXT_CR = 7, /* Certificate Request */
ISAKMP_NEXT_HASH = 8, /* Hash */
ISAKMP_NEXT_SIG = 9, /* Signature */
ISAKMP_NEXT_NONCE = 10, /* Nonce */
ISAKMP_NEXT_N = 11, /* Notification */
ISAKMP_NEXT_D = 12, /* Delete */
ISAKMP_NEXT_VID = 13, /* Vendor ID */
ISAKMP_NEXT_ATTR = 14, /* Mode config Attribute */
ISAKMP_NEXT_NATD_BADDRAFTS =15, /* NAT-Traversal: NAT-D (bad drafts) */
/* !!! Conflicts with RFC 3547 */
ISAKMP_NEXT_NATD_RFC = 20, /* NAT-Traversal: NAT-D (rfc) */
ISAKMP_NEXT_NATOA_RFC = 21, /* NAT-Traversal: NAT-OA (rfc) */
-----------------------------------------------------------------------------
ISAKMP_NEXT_v2SA = 33, /* security association */
ISAKMP_NEXT_v2KE = 34, /* key exchange payload */
ISAKMP_NEXT_v2IDi = 35, /* Initiator ID payload */
ISAKMP_NEXT_v2IDr = 36, /* Responder ID payload */
ISAKMP_NEXT_v2CERT= 37, /* Certificate */
ISAKMP_NEXT_v2CERTREQ= 38, /* Certificate Request */
ISAKMP_NEXT_v2AUTH= 39, /* Authentication */
ISAKMP_NEXT_v2Ni = 40, /* Nonce - initiator */
ISAKMP_NEXT_v2Nr = 40, /* Nonce - responder */
ISAKMP_NEXT_v2N = 41, /* Notify */
ISAKMP_NEXT_v2D = 42, /* Delete */
ISAKMP_NEXT_v2V = 43, /* Vendor ID */
ISAKMP_NEXT_v2TSi = 44, /* Traffic Selector, initiator */
ISAKMP_NEXT_v2TSr = 45, /* Traffic Selector, responder */
ISAKMP_NEXT_v2E = 46, /* Encrypted payload */
ISAKMP_NEXT_v2CP = 47, /* Configuration payload (MODECFG) */
ISAKMP_NEXT_v2EAP = 48, /* Extensible authentication*/
----------------------------------------------------------------------------
/* SPECIAL CASES */
ISAKMP_NEXT_NATD_DRAFTS = 130, /* NAT-Traversal: NAT-D (drafts) */
ISAKMP_NEXT_NATOA_DRAFTS = 131 /* NAT-Traversal: NAT-OA (drafts) */
};
在代码中检验枚举类型是否有效的接口为:enum_name():
const char *
enum_name_default(enum_names *ed, unsigned long val, const char *def)
{
enum_names *p;
for (p = ed; p != NULL; p = p->en_next_range)/*通过en_next_range访问下一个节点*/
if (p->en_first <= val && val <= p->en_last)/*取值在正常范围内,则返回name信息*/
return p->en_names[val - p->en_first];
return def;/*否则返回NULL*/
}
const char *
enum_name(enum_names *ed, unsigned long val)
{
return enum_name_default(ed, val, NULL);
}
3.2.3 isakmp头部中标记位处理
ISAKMP头部Flags标志位中,正常只有低三位是有效的(代码中实现了6位),其他bit位如果被设置那么就是错误的报文。
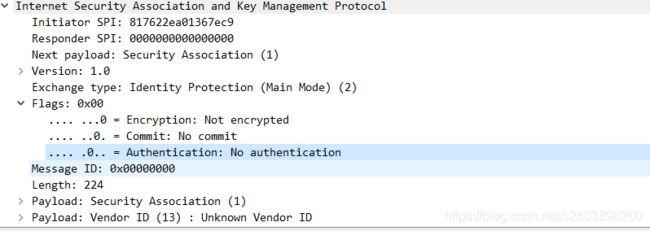
在in_struct中使用了testset()接口在判断是否有其他无效的bit位被设置,如果被设置则反会对应的错误信息。只是他的处理方式风格依然比较奇特:
Flags是否有效是通过flag_bit_names来描述的:
const char *const flag_bit_names[] = {
"ISAKMP_FLAG_ENCRYPTION", /* bit 0 */
"ISAKMP_FLAG_COMMIT", /* bit 1 */
"bit 2", /* bit 2 */
"ISAKMP_FLAG_INIT", /* bit 3 */
"ISAKMP_FLAG_VERSION", /* bit 4 */
"ISAKMP_FLAG_RESPONSE", /* bit 5 */
NULL
};
好吧,这段代码有点费解,看了很久。。。
也没有那么难,就是通过n是否为NULL,来判断有效的bit位是否已经结束。如果n已经为NULL,但是val却是非零,那么肯定的是val的bit位已经超出,此时返回FALSE; 如果val为0后,n依然不为NULL,则说明val的bit位是合法的。
bool
testset(const char *const table[], lset_t val)
{
lset_t bit;
const char *const *tp;
for (tp = table, bit = 01; val != 0; bit <<= 1, tp++)
{
const char *n = *tp;
if (n == NULL || ((val & bit) && *n == '\0'))/*n指向table成员的第一个字符*/
return FALSE;
val &= ~bit;/*已检测的位清零*/
}
return TRUE;
}
自己写了个例子测试了下:(只能说他们的想法很别致,只要别乱写描述信息就行)
#include
void testset(int value)
{
char *table[]={
"AAAAAAAAAAAAAAAA",
"BBBBBBBBBBBBBBBB",
"CCCCCCCCCCCCCCCC",
"DDDDDDDDDDDDDDDD",
NULL,
};
printf("value = %d\n", value);
int bit = 1;
char **tp = table;
for(bit=1; value !=0; tp++, bit<<=1){
char *n = *tp;
if( n == NULL || (value & bit) && *n=='0'){
printf("bit out of range!!!\n");
return;
}
printf("%c---%d\n", *n, *n);
value &= ~bit;
}
printf("value's bit is valid\n\n\n\n");
}
3.2.4 参数obj_pbs干什么的?
obj_pbs如果我没有理解错,是为了保留当前结构体的信息(未转换时的指针,大小信息), 同时将cur指针更新到已经解析完毕的位置;这个主要是为了处理有变长载荷的情形,由于变长载荷数据信息没有解析,因此将obj_pbs->cur指向变长载荷数据部分。

代码中ft_af_loose_enum和ft_af_enum的处理便是来源于此。

最高位AF如果为1,则是定长;如果AF为0,则为变长,此时需要在ft_lv时更新长度信息。
case ft_af_loose_enum: /* Attribute Format + value from an enumeration */
if ((n & ISAKMP_ATTR_AF_MASK) == ISAKMP_ATTR_AF_TV)
immediate = TRUE;
break;
case ft_af_enum: /* Attribute Format + value from an enumeration */
if ((n & ISAKMP_ATTR_AF_MASK) == ISAKMP_ATTR_AF_TV)
immediate = TRUE;
/* FALL THROUGH */
注意: 这里并没有将变长信息解析拷贝,而是将其头部指针保留下来,供后续再次解析处理。
用一张图片结束吧:
