图神经网络的介绍
- 图神经网络概念
https://cloud.tencent.com/developer/article/2334518?areaId=106001
https://blog.csdn.net/qq_44689178?type=blog; 先参考阅读这篇博主;
该文献中,介绍了 多视图 的 图神经网络的学习;
以及多视图 图神经网络的 对比学习,
需要阅读;
Deep multi-view learning methods: A review
Xiaoqiang Yan a, Shizhe Hu a, Yiqiao Mao a, Yangdong Ye a,⇑, HuiYu b,⇑
a School of Information Engineering, Zhengzhou University, Zhengzhou 450052, China
b School of Creative Technologies, University of Portsmouth, PO1 2DJ, United Kingdom
1.1 基本概念
图神经网络(Graph neural networks, GNN)[73]在学习表示方面协调了图在建模交互中与深度模型的表达能力,并因其对图结构数据的建模能力而受到越来越多的关注。他们处理变大小的置换不变图,并通过从拓扑邻居传递、转换和聚合表示的迭代过程来学习低维表示。近年来,GNN在图结构数据分析方面表现突出,如社会网络[74]和知识图[75]。首先,我们简要回顾了GNN的基本背景知识。设G¼fV;Eg表示图形,表示GNN的输入数据,变量V¼fvig和E¼feijg表示节点和边的集合。每条边eij¼ðvi;VjÞ连接vi和vj,每个节点vi包含一个表示其属性的特性xi。GNN的聚合过程可以表示为:
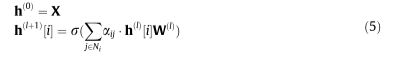
其中,变量X表示图G中所有节点的输入特征;r为类似Relu的非线性函数,hðlÞ½i表示节点i在第l层的隐藏特征,a为邻接矩阵的变体,WðlÞ为可学习线性转移矩阵。
近年来,GNN在MVL场景中也取得了很好的性能,如多图聚类和多视图图传统网络。我们以图的多视图表示学习为例。Hassani等人[76]提出了一种基于图的对比性多视图特征学习方法,该方法表明将视图数量增加到2个以上并不能提高性能。
在图神经网络学习中, 将视图的数量提高两个以上, 使用对比学习时,并不能提高更好的性能。
如图8所示,本文模型在节点和图的两个层次上进行。首先,采用图扩散方法创建目标视图的附加图视图,并将其馈送给两个gnn,随后使用共享多层感知器(MLP)学习节点表示。然后,学习到的特征表示被输入到一个图池中,后面跟着一个共享的MLP来学习图表示

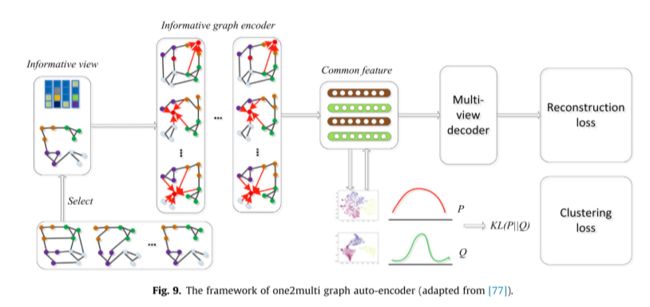
基于GNN的多图聚类是一个活跃的研究方向,近年来得到了广泛的关注。如Fan等[77]设计了一种one2multi图自动编码器,该编码器能够利用内容信息从多个视图重构图结构,学习节点嵌入。该模型由两个主要部分组成:多图自动编码器和图的自监督聚类机制。
如图9所示,one2multi由一个基于图的编码器体系结构和一个基于图的多视图解码器体系结构组成,其中信息最丰富的视图通过启发式度量模块来选择。
以全球贫困分析、分子性质预测、多视角相机再定位和压缩伪影抑制为例,对多视角GNN的应用进行了综述。Khan等[78]提出了一种卷积算法基于图结构的网络分析全球贫困状况。这种方法被应用于三项任务:(1)预测金融包容性的采用;(2) 预测一个人是否生活在贫困线以下;(3) 预测手机用户的性别。对于分子性质预测,Ma等人[79]根据以下观察结果提出了一个多视图图神经网络:原子和键都会显著影响分子的化学性质,因此明智的做法是同时利用节点(原子)和边(键)信息来建立表达模型。薛等人[80]重新设计GNN,与CNN合作指导特征提取和信息传播过程,以获得多视点图像的特征表示。
1.2 图神经网络与因果学习的结合
https://cloud.tencent.com/developer/article/1887977
https://hub.baai.ac.cn/view/17067
1.3 图神经网络与 大语言模型的结合
原文链接

图在表示和分析诸如引文网络、社交网络和生物数据等实际应用中的复杂关系方面扮演着重要角色。最近,大型语言模型(LLMs),它们在各个领域取得了巨大成功,也被用于图相关任务,超越了传统的基于图神经网络(GNNs)的方法,实现了最先进的性能。在这篇综述中,我们首先全面回顾和分析了结合LLMs和图的现有方法。首先,我们提出了一个新的分类法,根据LLMs在图相关任务中扮演的角色(即增强器、预测器和对齐组件)将现有方法分为三类。然后,我们系统地调查了沿着分类法的三个类别的代表性方法。最后,我们讨论了现有研究的剩余局限性,并强调了未来研究的有希望的途径。相关论文已总结,并将在以下网址持续更新:https://github.com/yhLeeee/Awesome-LLMs-in-Graph-tasks。
图论,在现代世界的许多领域,特别是在技术、科学和物流领域,扮演着基础性的角色[Ji et al., 2021]。图数据代表了节点之间的结构特性,从而阐明了图组件内的关系。许多实际世界的数据集,如引文网络[Sen et al., 2008]、社交网络[Hamilton et al., 2017]和分子数据[Wu et al., 2018],本质上都是以图的形式表示的。为了处理图相关任务,图神经网络(GNNs)[Kipf and Welling, 2016; Velickovic et al., 2018]已经成为处理和分析图数据的最受欢迎的选择之一。GNNs的主要目标是通过在节点之间的递归信息传递和聚合机制,获取在节点、边或图层面上的表达性表示,用于不同种类的下游任务。
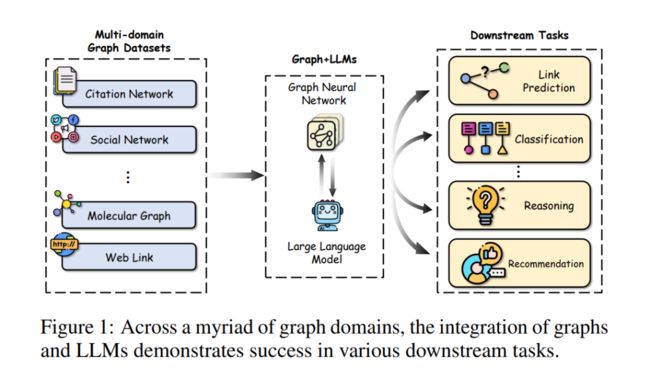
近年来,如Transformer [Vaswani et al., 2017]、BERT [Kenton and Toutanova, 2019]、GPT [Brown et al., 2020] 及其变体等大型语言模型(LLMs)在多个领域取得了重大进展。这些LLMs可轻易地应用于各种下游任务,几乎无需调整,就在多种自然语言处理任务中展现了卓越性能,例如情感分析、机器翻译和文本分类 [Zhao et al., 2023d]。虽然它们主要聚焦于文本序列,但目前越来越多的研究开始关注于增强LLMs的多模态能力,使其能够处理包括图形 [Chai et al., 2023]、图像 [Zhang et al., 2023b] 和视频 [Zhang et al., 2023a] 在内的多种数据类型。
LLMs在图相关任务中的应用已显著改变了我们与图的交互方式,特别是那些含有与文本属性相关联的节点的图。将LLMs与传统GNNs(图神经网络)的结合可以带来互利共赢,增强图学习。尽管GNNs擅长捕捉结构信息,但它们主要依赖语义上受限的嵌入作为节点特征,这限制了它们表达节点完整复杂性的能力。通过整合LLMs,GNNs可以得到更强大的节点特征,有效捕捉结构和语境方面的信息。另一方面,LLMs擅长编码文本,但通常难以捕捉图数据中的结构信息。结合GNNs和LLMs可以利用LLMs强大的文本理解能力,同时发挥GNNs捕捉结构关系的能力,从而实现更全面、强大的图学习。例如,TAPE [He et al., 2023] 利用与节点(如论文)相关的语义知识,这些知识由LLMs生成,来提高GNNs中初始节点嵌入的质量。此外,InstructGLM [Ye et al., 2023] 用LLMs替换了GNNs中的预测器,通过平铺图形和设计提示(提示)等技术,利用自然语言的表现力。MoleculeSTM [Liu et al., 2022] 将GNNs和LLMs对齐到同一向量空间,将文本知识引入图形(如分子)中,从而提高推理能力。
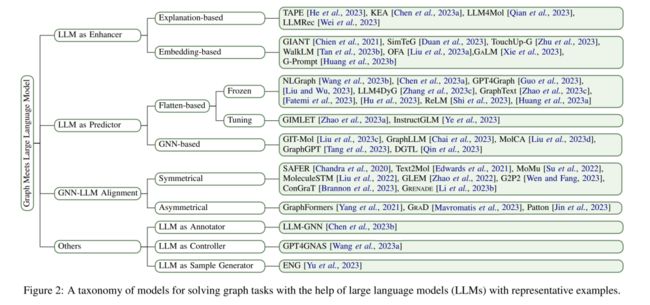
显然,LLMs从不同角度对图相关任务产生了重要影响。为了更好地系统概览,如图2所示,我们遵循Chen et al. [2023a]的方法,组织我们的一级分类法,基于LLMs在整个模型管道中扮演的角色(即增强器、预测器和对齐组件)进行分类。我们进一步细化我们的分类法,并为初始类别引入更多细粒度。
动机。尽管LLMs在图相关任务中的应用越来越广泛,但这个迅速发展的领域仍然缺乏系统的综述。张等人[Zhang et al., 2023d]进行了一项前瞻性综述,提出了一篇讨论图与LLMs整合所面临挑战和机遇的观点文章。刘等人[Liu et al., 2023b]提供了另一项相关综述,总结了现有的图基础模型,并概述了预训练和适应策略。然而,这两篇文章都在全面覆盖和缺乏专门关注LLMs如何增强图的分类法方面存在局限性。相比之下,我们专注于图和文本模态共存的场景,并提出了一个更细粒度的分类法,以系统地回顾和总结LLMs技术在图相关任务中的当前状态。
贡献。这项工作的贡献可以从以下三个方面总结:
(1)结构化分类法。通过结构化分类法,对该领域进行了广泛概览,将现有工作分为四类(图2)。
(2)全面综述。基于提出的分类法,系统地描述了LLMs在图相关任务中的当前研究进展。
(3)一些未来方向。我们讨论了现有工作的剩余局限性,并指出了可能的未来发展方向。
LLM作为增强器
图神经网络(GNNs)已成为分析图结构数据的强大工具。然而,最主流的基准数据集(例如,Cora [Yang et al., 2016] 和 Ogbn-Arxiv [Hu et al., 2020])采用了朴素的方法来编码TAGs中的文本信息,使用的是浅层嵌入,如词袋法、跳跃模型 [Mikolov et al., 2013] 或 TF-IDF [Salton and Buckley, 1988]。这不可避免地限制了GNNs在TAGs上的性能。LLM作为增强器的方法对应于利用强大的LLMs来提升节点嵌入的质量。衍生的嵌入被附加到图结构上,可以被任何GNNs利用,或直接输入到下游分类器中,用于各种任务。我们自然地将这些方法分为两个分支:基于解释和基于嵌入,这取决于它们是否使用LLMs产生额外的文本信息。

LLM作为预测器
这一类别的核心思想是利用LLMs来对广泛的图相关任务进行预测,例如在统一的生成范式下的分类和推理。然而,将LLMs应用于图模态提出了独特的挑战,主要是因为图数据往往缺乏直接转换成序列文本的方式,不同的图以不同的方式定义结构和特征。在这一部分,我们根据模型是否使用GNNs来提取结构特征供LLMs使用,将模型大致分为基于平铺和基于GNN的预测两类。

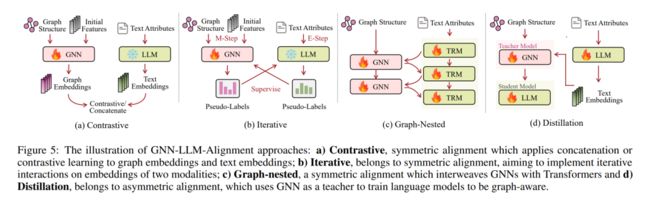
GNN-LLM 对齐
对GNNs和LLMs的嵌入空间进行对齐是整合图模态与文本模态的有效方式。GNN-LLM对齐确保在特定阶段协调它们的嵌入空间时,每个编码器的独特功能得以保留。在这一部分,我们总结了对齐GNNs和LLMs的技术,这些技术可以根据是否对GNNs和LLMs都给予同等重视,或是否优先考虑一种模态而另一种模态则不那么重视,被分类为对称或非对称。
结论
近年来,将大型语言模型(LLMs)应用于与图相关的任务已成为研究的一个突出领域。在这篇综述中,我们旨在提供对适应图的LLMs的现有策略的深入概述。首先,我们介绍了一个新的分类法,根据LLMs所扮演的不同角色(即增强器、预测器和对齐组件),将涉及图和文本模态的技术分为三类。其次,我们根据这种分类系统地回顾了代表性的研究。最后,我们讨论了一些限制,并强调了几个未来的研究方向。通过这篇全面的综述,我们希望能够揭示LLMs在图学习领域的进步和挑战,从而鼓励在这一领域进一步的提升。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
- 后台回复或发消息“GMLM” 就可以获取《大模型和图如何结合?最新《图遇见大型语言模型》综述,详述最新进展**》专知下载链接**
1.4 图神经网络与对比学习
https://mp.weixin.qq.com/s?__biz=Mzg4MzUwNzc5OQ==&mid=2247515476&idx=2&sn=2de2d687375043bc2191d116cd5e9d30&chksm=cf44aa6cf833237a23afb8b845a893881f10067aa23b85cc1f0e30cabb8c4f2312d984eaa695&mpshare=1&scene=23&srcid=1128dCfYZCJ7xvo7nA7DO5pz&sharer_shareinfo=5d9c7f606bc76afb5010e250fc31160e&sharer_shareinfo_first=5d9c7f606bc76afb5010e250fc31160e#rd
Neighbor Contrastive Learning on Learnable Graph Augmentation
论文摘要
近年来,旨在从未标记的图中学习表示的图对比学习(GCL)取得了很大的进展。然而,现有的GCL方法大多采用人为设计的图增强,对各种图数据集很敏感。此外,最初在计算机视觉中开发的对比损失已经直接应用于图数据,其中相邻节点被视为负节点,因此被推离锚点很远。然而,这与网络的同质性假设是矛盾的,即连接的节点通常属于同一类,并且应该彼此接近。在这项工作中,本文提出了一种端到端的自动GCL方法,称为NCLA,将邻居对比学习应用于可学习图增强。通过多头图注意力机制自动学习具有自适应拓扑结构的多个图增强视图,可以在不需要先验领域知识的情况下兼容各种图数据集。此外,通过将网络拓扑作为监督信号,设计了一种允许每个锚点有多个正信号的邻居对比损失。在提出的NCLA中,增强和嵌入都是端到端学习的。在基准数据集上的大量实验表明,当标签非常有限时,NCLA在自监督GCL上产生了最先进的节点分类性能,甚至超过了监督GCL。
图片

2. 实践
https://www.pytorchtutorial.com/pytorch-geometric-for-gnn/;
https://zhuanlan.zhihu.com/p/94491664