微信小程序+中草药分类+爬虫+torch
1 介绍
本项目提供中草药数据集,使用gpu、cpu版本的torch版本进行训练,将模型部署到后端flask,最后使用微信小程序进行展示出来。
数据爬虫可以参考:http://t.csdnimg.cn/7Olus 项目中的爬虫代码,并且本项目提供相同的爬虫代码。
2 数据处理,随机打乱训练集和测试集
因为我们的原始图片是在一个文件夹下,需要划分训练集和 测试集,这步也可以手工操作,总之,我们要将目录结构变为:

if os.path.isdir(category_path):
# 获取该种类下的所有图片文件
image_files = [f for f in os.listdir(category_path) if f.endswith(".jpg")]
# 随机打乱图片顺序
random.shuffle(image_files)
# 计算切割点
split_point = int(len(image_files) * split_ratio)
# 将图片分配给训练集
train_images = image_files[:split_point]
for image in train_images:
src = os.path.join(category_path, image)
dst = os.path.join(train_folder, category_folder, image)
os.makedirs(os.path.dirname(dst), exist_ok=True)
shutil.move(src, dst)
3 模型训练和验证
from torchvision import transforms as T # 导入torchvision库中的transforms模块,并将其重命名为T。
from torchvision.datasets import ImageFolder # 从torchvision.datasets模块中导入ImageFolder类,用于加载图像数据集。
from torch.utils.data.dataloader import DataLoader # 从torch.utils.data.dataloader模块中导入DataLoader类,用于创建数据加载器。
import torch # 导入PyTorch库。
from PIL import ImageFile
from sklearn.metrics import classification_report, accuracy_score
import warnings # 导入warnings库,用于忽略警告信息。
warnings.filterwarnings("ignore")
# 检查cpu是否可用,将结果存储在变量device中
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
# 数据预处理,归一化
transform = T.Compose([
T.Resize(256),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 导入训练集和测试机,并且同时对图片进行预处理
train = ImageFolder('data/train', transform=transform) # 从指定路径加载训练集,并应用之前定义的数据预处理管道。
test = ImageFolder('data/val', transform=transform) # 从指定路径加载测试集,并应用之前定义的数据预处理管道。
print('Size of raw dataset :', len(train)) # 打印训练集的大小。
print('Size of test dataset :', len(test)) # 打印测试集的大小。
from torchvision import models
model = models.resnet50(pretrained=True) # 导入resnet50网络
# 修改最后一层,最后一层的神经元数目=类别数目,所以设置为100个
model.fc = torch.nn.Linear(in_features=2048, out_features=5)
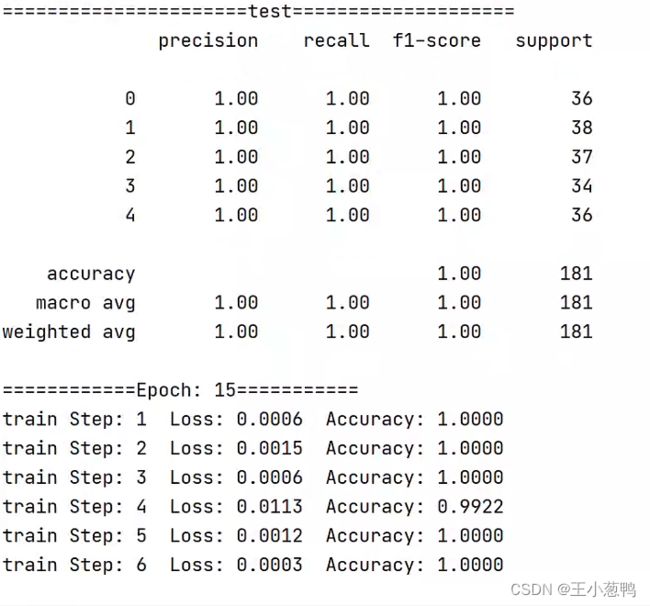
最后的结果展示:

4 模型部署到flask端
无论我们训练使用的是gpu还是cpu,我们在部署时都尽可能的转换为cpu端,引入图片输入是cpu端
def prepare_image(image):
transform = T.Compose([
T.Resize(256),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 对图像进行预处理
input_tensor = transform(image)
input_batch = input_tensor.unsqueeze(0) # 添加批次维度
return input_batch
预测的核心代码块,主要是传入字节文件,转换为图片,然后预测,最后获取结果,并将结果保存在data中
img_bytes = flask.request.form.get('picture') # 获取值
image = base64.b64decode(img_bytes)# 编码转换
image = Image.open(io.BytesIO(image))
input_batch = prepare_image(image) # 预处理图像
output = model(input_batch) # 预测
output = torch.softmax(output, dim=-1) # 得到预测值
score, predicted_idx = torch.max(output, 1) # 得分和标签
score = score.detach().numpy()[0]
predicted_idx = predicted_idx.detach().numpy()[0]
label_name = idx2class[predicted_idx]# 写入到字典中
label_info = idx2info[predicted_idx]
data = {"class_name": label_name, "prob": float(score),"info":label_info}
5 微信小程序
详细参考http://t.csdnimg.cn/7Olus中微信小程序页面,本项目包含微信小程序,可以放心使用。
详细咨询完整代码:https://docs.qq.com/doc/DWEtRempVZ1NSZHdQ