分布式文件存储数据库:MongoDB 快速入门
文章目录
- 一、MongoDB 简介
-
- 1.1 MongoDB 与 MySQL 比较
- 1.2 应用场景
- 二、Ubuntu20.04 下安装和卸载 MongoDB 5.0
-
- 2.1 安装
- 2.2 运行
- 2.3 卸载
- 三、数据库操作
- 四、集合操作
- 五、文档操作
-
- 5.1 插入文档
- 5.2 删除文档
- 5.3 更新文档
- 5.4 查询文档
- 5.5 排序
- 5.6 分页
- 5.7 计算文档数
- 5.8 去重
- 5.9 $type 操作符
- 5.10 聚合查询
- 六、索引
-
- 6.1 原理
- 6.2 操作
- 6.3 复合索引
- 七、副本集(Replica Set)
-
- 7.1 主从复制
- 7.2 副本集搭建
- 八、Python 与 MongoDB 交互
-
- 8.1 安装 PyMongo
- 8.2 快速入门
- 8.3 字符串 id 转换为 ObjectId
一、MongoDB 简介
MongoDB 是由 C++ 语言编写的一个开源的文档型数据库,旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系型数据库和非关系型数据库之间的产品,是非关系型数据库当中功能最丰富,最接近于关系型数据库的。
它支持的数据结构十分松散、是一种类似于 JSON 的 BSON 格式(JSON 的超集),可以存储比较复杂的数据类型。
MongoDB 将数据存储在硬盘上,并将需要经常读取的数据会被缓存在内存中,以提高查询效率。
1.1 MongoDB 与 MySQL 比较
| MongoDB | MySQL | 补充说明 |
|---|---|---|
| database 数据库 | database 数据库 | MongoDB 的默认数据库为 test,数据库存储在指定的 data 目录中,不同的库放在不同的文件中,且每个库有各自的集合和权限。 |
| collection 集合 | table 表 | MongoDB 的集合不像 MySQL 的表那样,必须按照字段的类型严格地插入数据,而是可以插入不同格式和类型地数据。 |
| document 文档 | row 记录/行 | 文档是一组键值对(即 BSON),字段值可以包含其他文档,数组及文档数组。同一个集合中的文档不需要设置相同的字段,并且在同一集合中的不同文档中,字段的数据类型也可以不同。 |
| field 字段 | column 字段/列 | |
| index 索引 | index 索引 | |
| table joins 表连接 | MongoDB 不支持表连接 | |
| primary key 主键 | primary key 主键 | MongoDB 自动将 _id 字段设置为主键 |
1.2 应用场景
- 游戏应用:玩家的装备、积分等直接以内嵌文档的形式存储,易于查询与更新。
- 物流应用:订单信息、状态等会在运送过程中不断更新,使用 MongoDB 内嵌数组的形式存储,可以一次将所有状态信息读出,方便快捷。
- 社交应用:用户的朋友圈信息、聊天记录等都很适合用 MongoDB 存储,并且通过地理位置索引实现附近的人、地点等功能也极为方便。
- 视频直播:存储用户信息、礼物信息等。
- 大数据应用:随时提取数据进行分析。
二、Ubuntu20.04 下安装和卸载 MongoDB 5.0
2.1 安装
-
导入包管理系统使用的公钥:
wget -qO - https://www.mongodb.org/static/pgp/server-5.0.asc | sudo apt-key add -如果失败,尝试安装 gnupg 库后重新导入公钥:
sudo apt-get install gnupg -
创建
/etc/apt/sources.list.d/mongodb-org-4.4.list软件源列表文件:echo "deb [ arch=amd64,arm64 ] https://repo.mongodb.org/apt/ubuntu focal/mongodb-org/5.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-5.0.list -
更新源数据库:
sudo apt-get update -
安装 MongoDB:
sudo apt-get install -y mongodb-org -
固定版本,防止意外升级(可选):
echo "mongodb-org hold" | sudo dpkg --set-selections echo "mongodb-org-server hold" | sudo dpkg --set-selections echo "mongodb-org-shell hold" | sudo dpkg --set-selections echo "mongodb-org-mongos hold" | sudo dpkg --set-selections echo "mongodb-org-tools hold" | sudo dpkg --set-selections
2.2 运行
-
启动 MongoDB 服务器:
sudo systemctl start mongod -
设置开机自启动(可选):
sudo systemctl enable mongod -
使用 mongo Shell 连接本地 MongoDB 服务器:
# 默认连接到本地的 27017 端口,这是 MongoDB 的默认端口 mongo # 指定本地端口号 mongo --port 端口号 # 指定远程地址和端口号 mongo "mongodb://mongodb0.example.com:28015" mongo --host mongodb0.example.com:28015 mongo --host mongodb0.example.com --port 28015 # 指定用户名和密码 mongo --username 用户名 --password --authenticationDatabase admin # 会提示输入密码
-
退出 mongo Shell:
exit
2.3 卸载
-
停止 MongoDB:
sudo systemctl stop mongod -
删除包:
sudo apt-get purge mongodb-org* -
删除数据目录:
sudo rm -r /var/log/mongodb sudo rm -r /var/lib/mongodb
三、数据库操作
MongoDB 有一些名称上的限制,比如:
- 不要有特殊符号:/\. "$
- 名称区分大小写
- 但是两个名称之间只有大小写的区别是不行的
- ……
限制比较多,具体参考官方文档:传送门。
-
查看当前所在数据库:
db -
查看所有数据库:
show dbs没有数据的库,即便存在,也不会被展示,比如默认的 test 库。
MongoDB 的自带库,了解一下即可,尽量不要去操作:
- admin:主要是一些权限相关的东西,要是将一个用户添加到这个数据库,这个用户会自动继承所有数据库的权限。并且,一些特定的命令也只能从这个数据库运行。
- local:MongoDB 是可以搭建副本集(类似于 MySQL 的主从)的,而这个数据库中的数据永远不会被复制到其他机器上。所以,该库用来存储仅限于本地使用的一些数据。
- config:用来保存分片相关的信息。
-
切换数据库:
use 数据库名称切换数据库前,不需要创建数据库,MongoDB 会自动创建。
-
创建数据库:
切换到不存在的数据库,MongoDB 会自动创建。
-
删除数据库:
先切换到要删除的数据库,然后执行以下命令:
db.dropDatabase()注意:删除后,使用
db查看当前库,可以发现我们当前还在被删除的库中。
四、集合操作
-
查看库中的所有集合:
show collections show tables -
创建集合:
如果集合不存在,MongoDB 会在第一次向集合插入文档时,自动创建该集合。
-
显式创建集合:
db.createCollection( "集合名称", // 选项都是可选的 { capped: <boolean>, autoIndexId: <boolean>, size: <number>, max: <number>, storageEngine: <document>, validator: <document>, validationLevel: <string>, validationAction: <string>, indexOptionDefaults: <document>, viewOn: <string>, // Added in MongoDB 3.4 pipeline: <pipeline>, // Added in MongoDB 3.4 collation: <document>, // Added in MongoDB 3.4 writeConcern: <document> } )选项(都是可选的):
- capped:要创建有上限的集合,请指定 true。如果指定为 true,则必须在 size 选项中设置最大大小。
- autoIndexId:指定为 false 则会禁用在 _id字段自动创建索引。
- size:设置了 capped 选项时必填。为有上限的集合指定最大大小(单位为字节)。一旦有上限的集合达到其最大大小,MongoDB就会删除旧文档,为新文档腾出空间。
- max:限制集合中的最大文档数量。
详细的选项限制参考官方文档:传送门
-
删除集合:
db.集合名称.drop()
五、文档操作
在 MongoDB 中,每个文档都会有一个_id字段作为唯一标识,该字段是自动生成的,也可以手动指定该字段的值。
5.1 插入文档
-
插入单条:
db.集合名称.insert({ "键":"值", "键":"值", …… }) -
插入多条:
db.集合名称.insertMany( [ {"键":"值","键":"值",……}, {"键":"值","键":"值",……}, …… ], { writeConcern: 1, // 写入策略,默认为1,即要求确认写操作,0 是不要求 ordered: true // 是否按照顺序写入,默认为 true } ) db.集合名称.insert([ {"键":"值","键":"值",……}, {"键":"值","键":"值",……}, …… ])还可以使用脚本方式插入多条:
for(let i=0; i<9; i++){ // 比如,插入10条 db.集合名称.insert({"键":"值","键":"值",……}) }
5.2 删除文档
-
删除符合条件的文档:
db.集合名称.remove( // 条件部分 { // 如,删除_id 为ObjectId("61bff1fd")的文档 "_id":ObjectId("61bff1fd"), // 如,删除 age 为999的文档 "age":999 }, // 选项部分 { justOne:布尔值, // (可选)如果为 true,表示只删除一个文档,否则就表示删除所有符合条件的文档 } ) -
删除所有文档:
db.集合名称.remove({}) // 条件留空即可
5.3 更新文档
-
更新文档:
db.集合名称.update( // 条件部分 { "age":25 }, // 更新部分 { "age":17 }, // 选项部分 { upsert:布尔值, // (可选)如果要更新的文档不存在,是否插入新文档,默认为 false,不插入 multi:布尔值, // (可选)是否更新所有符合条件的文档,默认为 false,只更新第一条 } )上面直接写键值对的更新方法会将原有的文档删除后,插入新的文档。即 age 为25的文档被更新后,就只剩下 age 为17的一个字段了,其他字段都被删除了。
所以,要想保留没被更新的部分,得用
$set更新:db.集合名称.update( { "age":25 }, { $set: { "age":17 } }
5.4 查询文档
-
查询一个集合中的所有文档:
db.集合名称.find() // find 内不传入任何条件要格式化结果,就将
.pretty()附加到命令中:db.集合名称.find().pretty() -
比较查询:
格式 说明 {key:value}匹配等于指定值的值 {key: {$lt:value}}匹配小于指定值的值 {key: {$lte:value}}匹配小于或等于指定值的值 {key: {$gt:value}}匹配大于指定值的值 {key: {$gte:value}}匹配大于或等于指定值的值 {key: {$ne:value}}匹配所有不等于指定值的值 {key: {$in:[value1,value2……]}}匹配数组中指定的任何值 {key: {$nin:[value1,value2……]}}匹配不在数组中的值 在
find()内指定字段和值就能查出匹配的文档。// 查询 age 等于17的男同学 db.student.find( {"age": 17, "gender": "male"} ) // 查询 age 大于17的男同学 db.student.find( {"age": {$gt:17}, "gender": "male"} )内嵌文档上的相等匹配是精确匹配,多出一个值或少一个值都不行,包括字段顺序:
db.集合名称.find( {字段: {内嵌字段1: 值1, 内嵌字段2: 值2}} ) -
数组查询:
假设字段的值是数组:
-
如果向
find()传入的是数组中的某一个值,那么会匹配字段包含该值的文档。 -
如果向
find()传入的也是一个数组,那么就会精确匹配,包括顺序。
比如:
db.inventory.find({tags:"red"}) // 会匹配 tags 包含 red 的文档 db.inventory.find({tags: ["red", "blank"]}) // 精确匹配 tags 为 red 和 blank 的文档,且顺序不能错 -
-
逻辑连接查询:
格式 说明 {$and:[{条件1}, {条件2}……]}返回与所有条件匹配的所有文档 {$not:{条件1}}返回与条件不匹配的文档 {$nor:[{条件1}, {条件2}……]}返回所有与所有条件都不匹配的文档 {$or:[{条件1}, {条件2}……]}返回与任意一个条件匹配的所有文档 比如:查询年龄大于17或者性别为男的所有同学
db.student.find( $or:[ {"age": {$gt:17}, {"gender": "male"} ] ) -
模糊查询:
在 MongoDB 中,使用正则表达式,近似的实现模糊查询:
db.集合名称.find({"字段":/正则表达式/}) // 表达式用 / 包裹,不要加引号 -
指定要返回的字段:
<字段>: 1:包含该字段。<字段>: 0:排除该字段。
比如,返回 item 和 status 字段,并将默认返回的 _id 字段排除:
db.inventory.find({}, { _id: 0, item: 1, status: 1 });
5.5 排序
db.集合名称.find().sort({字段A:1, 字段B:-1})
说明:1代表升序,-1则是降序。
5.6 分页
db.集合名称.find().sort(排序方式).skip(起始位置).limit(每页条数)
5.7 计算文档数
db.集合名称.find().count()
5.8 去重
db.集合名称.find().distinct("字段") // 会按照给定字段的值判断是否重复
5.9 $type 操作符
$type 用于按照类型操作文档,详细的类型如下:
| 类型 | 数字简写 | 别名 | 注释 |
|---|---|---|---|
| Double | 1 | “double” | |
| String | 2 | “string” | |
| Object | 3 | “object” | |
| Array | 4 | “array” | |
| Binary data | 5 | “binData” | |
| Undefined | 6 | “undefined” | 已经弃用 |
| ObjectId | 7 | “objectId” | |
| Boolean | 8 | “bool” | |
| Date | 9 | “date” | |
| Null | 10 | “null” | |
| Regular Expression | 11 | “regex” | |
| DBPointer | 12 | “dbPointer” | 已经弃用 |
| JavaScript | 13 | “javascript” | |
| Symbol | 14 | “symbol” | 已经弃用 |
| JavaScript code with scope | 15 | “javascriptWithScope” | 在 4.4 版本已经弃用 |
| 32-bit integer | 16 | “int” | |
| Timestamp | 17 | “timestamp” | |
| 64-bit integer | 18 | “long” | |
| Decimal128 | 19 | “decimal” | 3.4 版本新增 |
| Min key | -1 | “minKey” | |
| Max key | 127 | “maxKey” |
使用方法:
// 查询指定字段类型为 string 的文档
db.集合名称.find({"字段":{$type:2}})
db.集合名称.find({"字段":{$type:String}})
db.集合名称.find({"字段":{$type:"string"}})
5.10 聚合查询
聚合查询主要用于处理数据(比如计算平均值、求和等),并返回计算后的数据结果。
db.集合名称.aggregate(
[
{
$match:{条件} // 匹配到的结果,会传递给$group
},
{
$group:
{
_id:"$分组依据字段",
"保存聚合结果的名称":{$聚合表达式:"$字段"}
}
}
]
)
// 比如,按照作者名字分组,求每个作者的点赞数 likes 的总和
db.集合名称.aggregate(
[
{
$match:{}
},
{
$group:
{
_id:"$author_name",
"sum_article":{$sum:"$likes"}
}
}
]
)
常用聚合表达式:
| 达式 | 描述 |
|---|---|
| $sum | 计算总和。 |
| $avg | 计算平均值 |
| $min | 获取集合中所有文档对应值得最小值。 |
| $max | 获取集合中所有文档对应值得最大值。 |
| $push | 将值加入一个数组中,不会判断是否有重复的值。 |
| $addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 |
| $first | 根据资源文档的排序获取第一个文档数据。 |
| $last | 根据资源文档的排序获取最后一个文档数据 |
六、索引
索引表现为一种特殊的数据结构,是对集合中的一列或多列的值进行排序的一种结构。它存储在一个易于遍历读取的数据集合中,可以极大的提高查询的效率。
6.1 原理
索引存储一个或一组特定字段的值,按该字段的值排序。索引条目的排序支持基于范围的查询和等值匹配操作。此外,MongoDB可以通过索引中的排序返回排序后的结果。
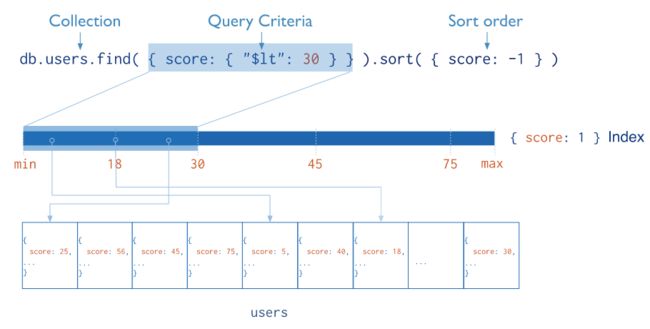
从根本上说,MongoDB 中的索引类似于其他数据库系统中的索引。MongoDB 在集合级别定义索引,并支持 MongoDB 集合中文档的任何字段或子字段的索引。
6.2 操作
-
创建索引:
db.集合名称.createIndex( { "字段1":升序为1,降序为-1, "字段2":升序为1,降序为-1, …… }, { background:布尔值, // 设置为 true,表示在后台创建,不阻塞当前进程,默认为 false unique:布尔值, // 设置为 true,表示建立唯一的索引,默认值为 false name:字符串, // 给索引设置名称,默认为:字段名_排序顺序 } ) -
查看索引:
db.集合名称.getIndexes() -
查看集合索引大小:
db.集合名称.totalIndexsize() -
删除集合的所有索引:
db.集合名称.dropIndexes() -
删除集合指定索引:
db.集合名称.dropIndex("索引名称")
6.3 复合索引
由多个字段维护的索引,有个专门的名称,叫做复合索引。创建方法还是使用上面的createIndex,只不过要传入多个字段。
注意:MongoDB 中复合索引和关系型数据库一样,建立时都要遵循最左前缀原则。
七、副本集(Replica Set)
MongoDB 中的副本集是一组 Mongod 维护的相同数据集的进程。这些进程通常分布在不同的机器上,由一个 Primary 主节点和若干 Secondary 从节点组成。副本集没有固定的主节点,当一个主节点故障时,副本集会从从节点中选举一个新的主节点,以此保证系统的高可用。
副本集的目的是解决系统的可用性,保障数据安全,并不能改善系统的性能或并发量。
7.1 主从复制
主节点负责处理所有读写请求,并记录操作日志(Oplog)。这些日志会被从节点复制过去,并应用所记录的操作,从而实现主从的数据复制或者说同步。

7.2 副本集搭建
-
创建数据存放目录:
mkdir 数据存放目录路径每台机器都要创建。
-
启动进程:
mongod --port 端口号 --dbpath 数据存放目录路径 --bind_ip 0.0.0.0 --replSet 副本集名称/[其他主机的ip:端口号,其他主机的ip:端口号,……]每台机器都要执行以上命令。
-
配置副本集:
在 MongoDB Shell 中执行:
use admin var config = { _id:"副本集名称", members:[ {_id:0,host:"主机ip:端口号"}, {_id:1,host:"主机ip:端口号"}, {_id:2,host:"主机ip:端口号"}, …… ] } rs.initiate(config)MongoDB 会自动选举出主节点。
八、Python 与 MongoDB 交互
PyMongo 是 MongoDB 官方提供的 python 驱动,用于python 程序和 MongoDB 之间的交互。
PyMongo 是同步的,MongoDB 还推出了一个 异步的驱动Motor ,感兴趣的可以自行学习。
8.1 安装 PyMongo
python3 -m pip install pymongo
8.2 快速入门
from pymongo import MongoClient
# 创建客户端连接
client = MongoClient("IP地址", 端口号) # 默认为本地的27017
# 获取数据库
db = client.test_database
# 或者数据库名称为 test-database 时
db = client['test-database']
# 获取集合
collection = db.test_collection
# 或者
collection = db['test-collection']
# 构建文档
"""
文档内部的 python 实例(如:datetime 对象)会被自动转换为 BSON 类型
"""
import datetime
post = {"author": "Mike",
"text": "My first blog post!",
"tags": ["mongodb", "python", "pymongo"],
"date": datetime.datetime.utcnow()}
# 插入单个文档
posts = db.posts # 隐式创建集合
post_id = posts.insert_one(post).inserted_id # insert_one 返回文档对象
# 列出所有集合
db.list_collection_names()
# 返回:['posts']
# 获取单个文档
posts.find_one({"author": "Mike"}) # 返回匹配的第一个文档
# 批量插入,将多个文档放入一个列表中
new_posts = [{"author": "Mike",
"text": "Another post!",
"tags": ["bulk", "insert"],
"date": datetime.datetime(2009, 11, 12, 11, 14)},
{"author": "Eliot",
"title": "MongoDB is fun",
"text": "and pretty easy too!",
"date": datetime.datetime(2009, 11, 10, 10, 45)}]
result = posts.insert_many(new_posts)
result.inserted_ids
# 返回:[ObjectId('...'), ObjectId('...')]
# 获取多个文档
for post in posts.find({"author": "Mike"}): # 不加条件就是获取全部
print(post)
# 获取匹配条件的文档数量
posts.count_documents({"author": "Mike"}) # 不写条件就是获取集合中的文档总数
# 范围查询,如:查询 2009年11月12号12点之前的所有文章
d = datetime.datetime(2009, 11, 12, 12)
for post in posts.find({"date": {"$lt": d}}).sort("author"): # 按照 author 排序
pprint.pprint(post)
8.3 字符串 id 转换为 ObjectId
由于 ObjectId 和它的字符串形式不同,所以,通过 ObjectId 的字符串形式是找不到文档的:
post_id_as_str = str(post_id) # post_id 是一个 ObjectId
posts.find_one({"_id": post_id_as_str}) # 找不到任何文档
但是,web 应用经常会有通过 URL 中的 id 查找数据的场景,我们知道, URL 中的 Id 是字符串,不能直接用来查找文档。所以,需要转换一下:
from bson.objectid import ObjectId
def get(post_id): # 此处的 post_id 是一个字符串
#从字符串转换到 ObjectId:
document = client.db.collection.find_one({'_id': ObjectId(post_id)})