延时队列的设计:定时任务轮询、DelayQueue、时间轮算法、消息中间件、Redis
一、基本概念
什么是延时队列?首先它要具有队列的特性,再给它附加一个延迟消费队列消息的功能,延迟队列相对比普通队列,区别就在延时的特性上,普通队列先进先出,按入队顺序进行处理,而延时队列中的元素在入队时会指定一个延时时间,希望能够在指定时间到了以后处理。
二、使用场景
业务类场景:
1、支付订单成功后,指定时间以后将支付结果通知给接入方。
2、淘宝订单业务:下单之后如果三十分钟之内没有付款就自动取消订单。
3、美团或饿了吧订餐通知:下单成功后60s之后给用户发送短信通知。
4、会议预定系统,在预定会议开始前半小时通知所有预定该会议的用户。
5、IT问题工单超过24小时未处理,则自动拉企微群提醒相关责任人。
6、用户下单外卖以后,距离超时时间还有10分钟时提醒外卖小哥即将超时。
技术框架场景∶
1、关闭空闲连接。服务器中,有很多客户端的连接,空闲一段时间之后需要关闭之。
2、缓存。缓存中的对象,超过了空闲时间,需要从缓存中移出。
3、任务超时处理。在网络协议滑动窗口请求应答式交互时,处理超时未响应的请求等。
上面的这些场景都可以通过延时队列解决。
三、实现方案
1、定时任务轮询数据库
2、Java提供的DelayQueue
3、netty提供的时间轮算法实现类HashedWheelTimer
4、消息中间件(rabbitmq、rocketmq.kafka)延迟消息
5、redis的sorted set或redis key过期回调
四、实现落地
1)、定时任务轮询数据库
采用定时任务实现延迟,对业务表进行轮询判断,订单到点执行,有一点点误差。实现如下:1)使用单机版的spring sceduled+分布式锁,代码如下:
@Slf4j
@Configuration
@EnableScheduling
public class OrderAutoCancelSpringJob {
@Resource
private DistributeLockHelper distributeLockHelper;
private static final String ORDER_AUTO_CANCEL_LOCK = "orderAutoCancelLocScheduled(cron = "0/60 * * ** ?")
public void cancelOrder() {
if(!distributeLockHelper.tryLock(ORDER_AUTO_CANCEL_LOCK,TimeUnit.MINUTES,1)){
return;
}
try{
//执行业务逻辑
}finally{
distributeLockHelper.unlock(ORDER_AUTO_CANCEL_LOCK);
}
}
}
2)使用分布式调度框架,常见的有xxl-job、Elastic-Job、Quartz、Saturn,配置频率为每几秒一次的定时任务,如果处理的数据量比较大,可以利用分布式调度框架的分片功能并行处理,大大提升数据处理的能力,加快处理速度。
3)优缺点
优点:
实现简单,不用引入任何中间件,各个业务模块可以自行定义延迟执行规则。
缺点∶
完全由业务代码控制,重复代码多,不论是否有待执行的数据,都要空轮询且需要频繁访问数据库,另外由于是定时轮询的,会有一点点误差。
- 适用场景
该方案在互联网应用还是比较广泛的,适合定实时性要求没那么精确,允许有一点误差的场景。
5)使用示例及代码演示
以订单为例,超过指定时间后,订单自动取消




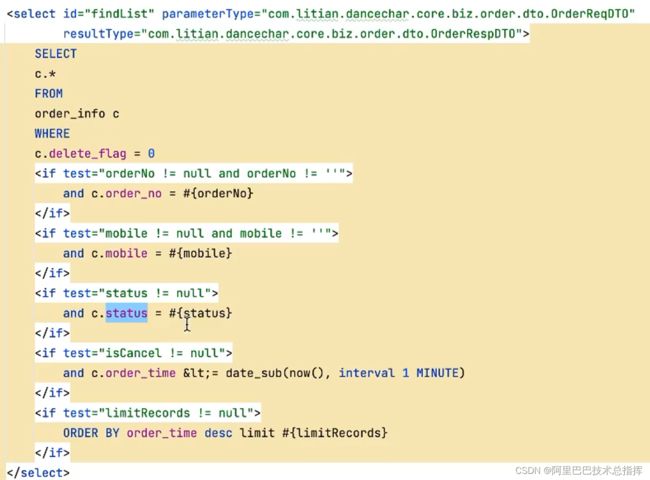

基于XXL-JOB:

2、DelayQueue延迟队列
1)什么是DelayQueue?
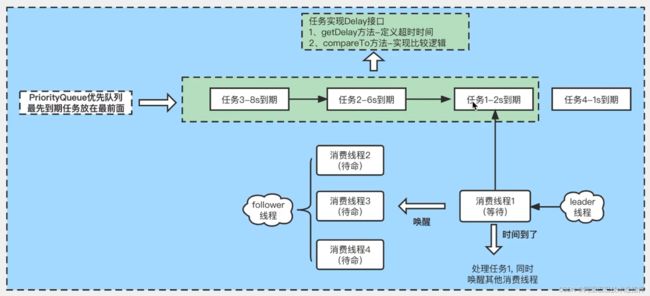
DelayQueve是一个无界的BlockingQueve,用于放置实现了Delayed接口的对象,其中的对象只能在其到期时才能从队列中取走。这种队列是有序的,即队头对象的延迟到期时间最长。注意︰不能将null元素放置到这种队列中。
2)实现注意事项
队列元素需要实现Delayed接口,getDelay方法用于设置延迟时间,compareTo方法用于对队列中的元素进行排序。入队:
put()、offer(),线程安全。
出队:
poll(),非阻塞方式获取,没有到期的元素直接返回null。
take(),阻塞方式获取,没有到期的元素线程将会等待。
3)优缺点
优点:
JDK自带的,不用引入其他框架或中间件,使用简单方便。
缺点∶
不支持分布式或持久化,重启后会丢失,如果订单并发量非常大,因为DelayQueve是无界的,订单量越大,队列内的对象就越多,可能造成0OM的风险。所以使用DelayQueue实现延时任务,只适用于任务量较小的情况。
4)适用场景
适用于不需要持久化任务量少的单机任务,能容忍丢失。
- 代码演示




3、时间轮算法延迟队列
1)时间轮算法是什么及实现原理?
时间轮算法,参考的时钟,从时钟中得到的一些启发设计出来的,简单的讲它是一个存储定时任务的环形队列,底层采用数组实现,数组中的每个元素可以存放一个延时任务列表。延时任务列表是一个双向链表,链表中的每一项表示的都是一个延时任务。
2)常见实现方案
以netty的HashedWheelTimer为例,算法规则如下:假设共有八个槽0~7,槽的时间单位为1秒
现在要加入一个延时5秒的任务,计算方式就是5%8+ 1 = 6,即放在槽位为6,下标为5的那个槽中。
假如要加入一个延时50s的任务,计算方式就是50% 8+1= 3,即应该放在槽位是3,下标是2的位置。但是记住这里有轮次的概念,轮次=(50 - 1)/8 = 6,即轮数记为6。也就是说当循环6轮之后扫到下标的2的这个槽位会触发这个任务。
对于延迟超过时间轮所能表示的范围有两种处理方式:
一是通过增加一个字段-轮数,Netty就是这样实现的。
二是多层次时间轮,Kafka是这样实现的,跟我们的手表非常像,像我们秒针走一圈,分针走一格,分针走一圈,时针走一格。相比而言Netty的实现会有空推进的问题,而Kafka采用DelayQueve以槽为单位,利用空间换时间的思想解决了空推进的问题。它们的任务插入和删除时间复杂度都为0(1)
3)优缺点
优点:只需要一个线程推进时间轮,查询效率高,性能相对好一些。
缺点:内存占用高,任务有较大的耗时会影响时间轮的正确性,不支持分布式运行和持久化运行。)适用场景
适用于对时效性不高的,可快速执行的小任务,能够做到高性能,低消耗,应用的场景:心跳检测(客户端探活)
会话、请求是否超时消息延迟推送
5)使用示例及代码演示
public final static Timer HASHED_WHEEL_TINER = new HashedWheelTimer(new DefaultThreadFactory(" nettylelaylsg"),18L,TimeUnit.MILLISECONDS,512,true);


4、消息中间件延时队列
1)常见的实现方案. rocketmq
rocketmq先把消息按照延时时间段发到指定的队列中,然后通过一个定时器轮询这些队列,查看消息是否到期,如果到期就把这个消息发到指定的topic队列,流程图如下所示︰基于rocketmq实现延时队列原理
注意点:
RocketMQ延时消息的延迟时长不支持随意时长的延迟,是通过特定的延迟等级来指定的。默认支持18个等级的延迟消息,延时等级定义在RocketMQ服务端的MessageStoreConfig类中的如下变量中:
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m ?m 8m 9m 10m 28m 30m 1h 2h";
发消息时,设置delayLevel等级即可:msg.setDelayLevel(level)。level有以下三种情况:
level == 0,消息为非延迟消息
1<=level<=maxLevel,消息延迟特定时间,
例如level1,延迟1slevel > maxLevel,则level maxLevel
例如level==20,延迟2h注意∶如果希望支持超过2h的延时消息,需要修改时间配置和对应的level
kafkal
不支持延时消息的能力,实现方案可参考rocketmq
2)优缺点
优点∶基于消息中间件可以快速实现延时队列,而且天然支持消息消费的有序性、消息持久化、ACK机制等。缺点∶没有接入上面中间件的团队,需要额外引入、增加了部署和运维成本。
3)适用场景
一般大厂的方案,适用于大量延时任务的场景。
5、基于redis延时队列
1)常见的实现方案
.基于redis sortedset实现.
基于redisson提供的api实现.
基于redis过期回调实现
将延时任务添加到redis,通过监听redis过期回调事件,对到期的任务进行处理。
2)优缺点
优点:基于redis完成了任务持久化,且支持分布式运行。
缺点∶缺乏队列顺序消息特性,相同score的任务无法顺序执行,缺乏ack特性,若任务执行失败,而队列的任务被删除了,就丢失了。
3)适用场景
适用于对顺序要求不高、允许任务丢失的场景,比如延时通知场景