Linux内核(2.6)进程调度算法
1.1 进程状态
在Sched.h(include\linux)中定义了进程的状态。
/*
*Task state bitmask. NOTE! These bits are also
*encoded in fs/proc/array.c: get_task_state().
*
* Wehave two separate sets of flags: task->state
* isabout runnability, while task->exit_state are
*about the task exiting. Confusing, but this way
*modifying one set can't modify the other one by
*mistake.
*/
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
#define TASK_WAKING 256
其实我们只要关心这几个就行了
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
1.1.1 TASK_RUNNING
运行态:或者是当前正在运行,或者是在一个等待运行的队列里。运行态的进程可以分为3种情况:内核运行态、用户运行态、就绪态。
当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。
内核态与用户态是操作系统的两种运行级别,跟intel cpu没有必然的联系, intel cpu提供Ring0-Ring3三种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为 内核态,没有使用Ring1和Ring2。Ring3状态不能访问Ring0的地址空间,包括代码和数据。Linux进程的4GB地址空间,3G-4G部 分大家是共享的,是内核态的地址空间,这里存放在整个内核的代码和所有的内核模块,以及内核所维护的数据。用户运行一个程序,该程序所创建的进程开始是运行在用户态的,如果要执行文件操作,网络数据发送等操作,必须通过write,send等系统调用,这些系统调用会调用内核中的代码来完成操作,这时,必须切换到Ring0,然后进入3GB-4GB中的内核地址空间去执行这些代码完成操作,完成后,切换回Ring3,回到用户态。这样,用户态的程序就不能 随意操作内核地址空间,具有一定的安全保护作用。
用户态切换到内核态的3种方式
A) 系统调用
这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作,比如前例中fork()实际上就是执行了一个创建新进程的系统调用。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断。
B) 异常
当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
C) 外围设备的中断
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
这3种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
1.1.2 TASK_INTERRUPTIBLE
可中断的睡眠态。进程被阻塞,它在等待某些条件来执行。
1.1.3 TASK_UNINTERRUPTIBLE
不可中断的睡眠态。这个状态只能被wake_up()唤醒。
1.1.4 TASK_STOPPED
停止态:这种情况发生在进程收到SIGSTOP, SIGTSTP, SIGTTIN或SIGTTOU信号,或者在它被调试的时候收到任何信号的时候。可向其发送SIGCONT信号让进程转换到可运行状态。
1.2 进程调度算法
1.2.1 抢占型多任务
调度器背后的思想是为了最好的利用处理器资源。假设系统中可运行的进程的数量大于系统处理器的数量,那么必须决定哪个进程需要优先运行,这其实是选出最优先的k个进程的问题,k就是处理器的数目。而调度器就是解决这个问题的。
世界上的多任务操作系统分为两种风格:合作型多任务和抢占型多任务。Linux,像所有Unix和大多数现代操作系统一样,提供抢占型多任务。调度器一旦决定运行一个进程,它就会毫无情面的挂起一个当前正在运行的进程。这样的动作称为抢占。一个进程在抢占之前运行的时间是预设好的,叫做时间片。管理时间片是调度算法的一部分。
而在合作型多任务中,任务切换只能依靠一个任务去主动放弃CPU。这种主动放弃叫做yield----就像pthread中的一样。目前的系统很少有采用这种调度策略的。
从kernel 2.5开始,调度器的算法做了很大的调整,时间复杂度降到了O(1)。下面我们来看它的设计和实现
1.2.2 时间片
时间片是决定了一个任务在没有被抢占的理想情况下可以运行多久。时间片的长度很难确定:时间片太长会导致系统交互性能不好,时间片太短会导致进程切换频繁,浪费系统资源。而且还需要考虑进程的目的,比如偏于IO交互的进程(比如响应触摸屏操作的进程)和偏于处理器运算的进程(比如视频解码进程)设计目的是不一样的,UNIX系统认为,偏于IO的进程需要快速响应,这种策略也影响了时间片的分配策略。
另外调度系统需要满足两个自相矛盾的目标:最小化的进程响应时间,最大化的系统工作效率。前者倾向于IO消耗型进程,后者倾向于CPU消耗型进程。
进程调度算法是基于优先级的,而优先级基于进程对处理器时间的需求和他们自己的价值。高优先级的进程会优先得到调度,而相同优先级的进程会排队循环的得到调度。优先级和时间片的关系也是比较微妙,有的系统是正相关的,比如Linux。也就是说,优先级越高,时间片越大。
1.2.3 优先级
Linux的进程分普通进程和实时进程,而实时进程又分SCHED_FIFO与SCHED_RR,它们只有静态优先级,范围从0到99,而普通进程的优先级是从100到139,所以实时进程比普通进程的优先级高。
#define SCHED_NORMAL 0 //非实时进程,基于优先级的轮回法(Round Robin)
#define SCHED_FIFO 1 //实时进程,先进先出
#define SCHED_RR 2 //实时进程,基于优先级的轮回法(Round Robin)
对相同优先级的任务,SCHED_RR是分配给每个任务一个特定的时间片,然后轮转依次执行;而SCHED_FIFO则是让一个任务执行完再调度下一个任务,而顺序就是按照创建的先后。当一个FIFO进程变得可以运行时,它会持续的跑直到阻塞或自己放弃了CPU,只有高优先级的实时进程可以抢占它。
SCHED_RR和SCHED_FIFO唯一不同的地方是拥有了时间片。当时间片用完时,不管这个线程优先级有多高,都不会在运行,而是进入就绪队列,等待下一个时间片到来。可以这么说,因为有了时间片,RR进程多了一些可以被中断的机会。
SCHED_NORMAL就是普通进程,它不仅有静态优先级,还有动态优先级。
在定义进程的时候就定义了它的静态优先级,这是用nice值换算出来的。nice值从-20到19,它决定了优先级和时间片,19是最低的而-20最高。所以我们也可以认为nice值就是静态优先级。普通进程的静态优先级范围从100(最高优先级)到139(最低优先级)。
NICE值和静态优先级的关系:
/*
* Convertuser-nice values [ -20 ... 0 ... 19 ]
* tostatic priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* andback.
*/
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
#define PRIO_TO_NICE(prio) ((prio) - MAX_RT_PRIO - 20)
#define TASK_NICE(p) PRIO_TO_NICE((p)->static_prio)
动态优先级是由静态优先级和“bonus”一起算出来的,下面这个宏计算某进程的bonus:
#define CURRENT_BONUS(p) \
(NS_TO_JIFFIES((p)->sleep_avg)* MAX_BONUS / \
MAX_SLEEP_AVG)
Bonus是用sleep_avg来算出来的,它随着进程的睡眠而增长,随着进程的运行而减少,可以认为Bonus是平均睡眠时间的一种表达形式,IO倾向的进程会得到调度程序的奖励, 即Bonus为正,CPU倾向的进程会得到调度程序的处罚,即Bonus为负。
而计算动态优先级的函数是
static int effective_prio(task_t *p)
{
intbonus, prio;
if(rt_task(p))
return p->prio;
bonus= CURRENT_BONUS(p) - MAX_BONUS / 2;
prio= p->static_prio - bonus;
if(prio < MAX_RT_PRIO)
prio= MAX_RT_PRIO;
if(prio > MAX_PRIO-1)
prio= MAX_PRIO-1;
returnprio;
}
通常说的优先级指的是动态优先级。
下面的函数用来重新计算时间片,注意是用静态优先级计算的,实时进程的时间片相对普通进程要大一些。所有进程的时间片和优先级成正比,比如-20对应800ms,0对应100ms,19对应5ms,反正无论一个进程优先级多低,它都会有时间片资源的。
#define SCALE_PRIO(x, prio) \
max(x* (MAX_PRIO - prio) / (MAX_USER_PRIO/2), MIN_TIMESLICE)
static unsigned int task_timeslice(task_t*p)
{
if(p->static_prio < NICE_TO_PRIO(0))
returnSCALE_PRIO(DEF_TIMESLICE*4, p->static_prio);
else
returnSCALE_PRIO(DEF_TIMESLICE, p->static_prio);
}
1.2.4 进程调度
/*
*This is the main, per-CPU runqueue data structure.
*
*Locking rule: those places that want to lock multiple runqueues
*(such as the load balancing or the thread migration code), lock
* acquireoperations must be ordered by ascending &runqueue.
*/
struct runqueue {
spinlock_tlock;
/*
* nr_running and cpu_load should be in thesame cacheline because
* remote CPUs use both these fields when doingload calculation.
*/
unsignedlong nr_running;
#ifdef CONFIG_SMP
unsignedlong cpu_load;
#endif
unsignedlong long nr_switches;
/*
* This is part of a global counter where onlythe total sum
* over all CPUs matters. A task can increasethis counter on
* one CPU and if it got migrated afterwards itmay decrease
* it on another CPU. Always updated under therunqueue lock:
*/
unsignedlong nr_uninterruptible;
unsignedlong expired_timestamp;
unsignedlong long timestamp_last_tick;
task_t*curr, *idle;
structmm_struct *prev_mm;
prio_array_t*active, *expired, arrays[2];
intbest_expired_prio;
atomic_tnr_iowait;
#ifdef CONFIG_SMP
structsched_domain *sd;
/*For active balancing */
intactive_balance;
intpush_cpu;
task_t*migration_thread;
structlist_head migration_queue;
#endif
};
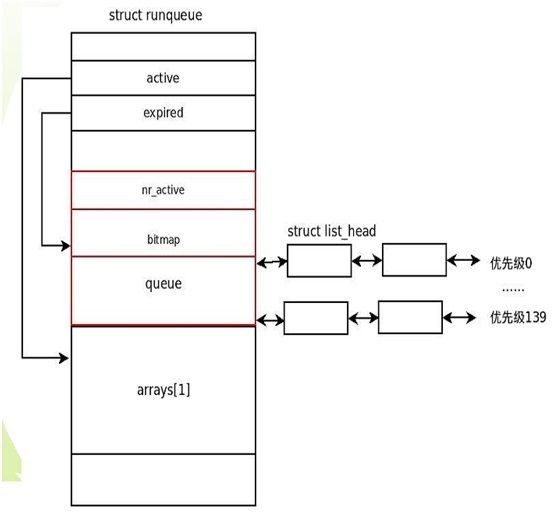
注意里面定义的prio_array_t *active, *expired, arrays[2]; 它定义了活跃的和过期的两个进程数组,分别对应处于TASK_RUNNING状态的有时间片的进程和消耗尽时间片的进程
typedef struct prio_array prio_array_t;
struct prio_array {
unsignedint nr_active;
unsignedlong bitmap[BITMAP_SIZE];
structlist_head queue[MAX_PRIO];
};
注意,BITMAP_SIZE是5,也就是5*32=160个bit,MAX_PRIO是140。而queue里包含了每一种优先级进程组成的链表,一共有140个。Sched.c (kernel)中有一个数据结构是runqueues,每个CPU都有一个runqueue,为了避免死锁,试图锁住很多runqueue的代码需要按照相同的顺序去加锁和解锁,比如采用递增的顺序。例如:
/* to lock ... */
if (rq1 < rq2) {
spin_lock(&rq1->lock);
spin_lock(&rq2->lock);
}else {
spin_lock(&rq2->lock);
spin_lock(&rq1->lock);
}
/* manipulate both runqueues ... */
/* to unlock ... */
spin_unlock(&rq1->lock);
spin_unlock(&rq2->lock);
O(1)算法的实现在于对bitmap的操作,初始情况下所有bit为0,当一个进程状态变为TASK_RUNNING时,active数组中的bitmap对应的位被设置为1。因此寻找哪个优先级的进程可运行的问题就转化为了寻找bitmap中第一个置为1的bit的位置的问题。这个问题显然是个O(1)的问题,函数为sched_find_first_bit。找到这个优先级后,再找到这个优先级对应的进程队列,按照“roundrobin”的方式去找到当前需要运行哪个进程。这种方式是个术语,其实就是指优先级相同的进程公平的获得运行的机会。这段代码是:
idx =sched_find_first_bit(array->bitmap);
queue = array->queue + idx;
next = list_entry(queue->next, task_t,run_list);
queue->next是采用迭代器的方式返回的链表的下一个元素。
时间片算法。很多操作系统会在所有能运行的进程时间片都达到0的时候,统一的,一次性的重新计算时间片。而Linux的算法是一旦某进程时间片耗尽,在送到耗尽数组之前,重算它的时间片。这样,耗尽数组中的进程其实都是有一个新的时间片的,这样,当活跃数组中的进程数达到0时,直接交换active和expire指针即可。 这段代码在schedule函数里:
if (unlikely(!array->nr_active)) {
/*
* Switch the active and expired arrays.
*/
schedstat_inc(rq,sched_switch);
rq->active= rq->expired;
rq->expired= array;
……
}
这个交换保证整个调度算法O(1)的重要部分。
总结:Linux的调度策略其实是:优先选择处于运行态且有时间片的进程中优先级最高的那个。
1.2.5 scheduler_tick
函数scheduler_tick()会被时钟中断调到, 它更新当前进程的time_slice,并根据time_slice的使用情况(剩余还是耗尽),来做进一步处理。另外,在fork调用中,当改变父进程的时间片时,也会调到这个函数。
如果是实时进程,先判断是否是RR进程,若是,递减它的时间片。如果时间片已经耗尽,则根据静态优先级重新计算时间片,然后仍然把它塞到活跃数组尾部,如此一来它还有可能被调度到。如果是FIFO进程
如果是普通进程,需要递减时间片,更新它的动态优先级,根据静态优先级重填时间片,然后判断此进程是否是一个交互性质的进程。若是,还加入到活跃数组中。
1.3 抢占(preemption)
这篇文章写得很好:http://blog.csdn.net/sailor_8318/article/details/2870184
Linux为了增加自身的实时性,在2.6版本中支持了内核抢占。当一个进程进入running状态后,内核会检查它的优先级是否大于当前运行的进程的优先级,若是,在一定时间内切换,不管当前进程运行在内核态还是用户态。
上面讲的是策略,那么,下面看看具体在什么时候切换。
内核提供了一个标志位need_resched来表示是否需要切换,这个标志位在如下情况下被设置:
1. scheduler_tick()检查到一个进程耗尽了它的时间片
2. try_to_wake_up()唤醒一个进程
一旦回到用户态,或者从中断恢复时,内核会去检查这个标志位,若被设置则调用schedule()。从中断可以恢复到用户态,也可以恢复到内核态。
注意,有几种情况Linux内核不应该被抢占,
1. 内核正进行中断处理。在Linux内核中进程不能抢占中断(中断只能被其他中断中止、抢占,进程不能中止、抢占中断),在中断例程中不允许进行进程调度。进程调度函数schedule()会对此作出判断,如果是在中断中调用,会打印出错信息。
2. 内核正在进行中断上下文的Bottom Half(中断的底半部)处理。硬件中断返回前会执行软中断,此时仍然处于中断上下文中。
3. 内核的代码段正持有spinlock自旋锁、writelock/readlock读写锁等锁,处干这些锁的保护状态中。内核中的这些锁是为了在SMP系统中短时间内保证不同CPU上运行的进程并发执行的正确性。当持有这些锁时,内核不应该被抢占,否则由于抢占将导致其他CPU长期不能获得锁而死等。
4. 内核正在执行调度程序Scheduler。抢占的原因就是为了进行新的调度,没有理由将调度程序抢占掉再运行调度程序。
5. 内核正在对每个CPU“私有”的数据结构操作(Per-CPU date structures)。在SMP中,对于per-CPU数据结构未用spinlocks保护,因为这些数据结构隐含地被保护了(不同的CPU有不一样的per-CPU数据,其他CPU上运行的进程不会用到另一个CPU的per-CPU数据)。但是如果允许抢占,但一个进程被抢占后重新调度,有可能调度到其他的CPU上去,这时定义的Per-CPU变量就会有问题,这时应禁抢占。
为保证Linux内核在以上情况下不会被抢占,抢占式内核使用了一个变量preempt_count,称为内核抢占锁。这一变量被设置在进程的PCB结构task_struct中。每当内核要进入以上几种状态时,变量preempt_count就加1,指示内核不允许抢占。每当内核从以上几种状态退出时,变量preempt_count就减1,同时进行可抢占的判断与调度。
由于在某些情况下无法进行内核抢占,所以我们说Linux是软实时性的,也就是一般保证实时,但极少情况下可能无法做到。