计算机网络第三章--数据链路层第一部分:封帧,差错控制编码
数据链路层和下一章网络层是考研的重点内容,两道大题往往各考一题。
1.数据链路层概述

上图就是本章要学习的全部内容,从数据链路层的功能和应用两方面来谈:
(1)封装:其实数据链路层在用户眼中是看不到的,和程序语言的封装一样,它被提前进行了封装,形成一种看不见的传输状态,这样大家就不用在传输中在意其逻辑。
(2)差错控制:之前就说过,中间节点和计算机都有检错功能,本章将学习检测错误的方法,这是重点也是难点。
(3)流量控制和可靠传输:这是防止发送方发的太快,接收方收不到,具体用协议来控制。可靠传输则是防止其出错。这两个其实也是差错控制,而且也属于大题必考内容。必须掌握。
(4)要学习两种通信方式:点对点和广播机制,这两个常在选择题出现。
(5)最后学习一下一些真实存在的,用来实现数据链路层的设备:交换机,网桥等。
1.1 链路层常见术语
(1)节点:节点其实主机或者路由器。
(2)链路:就是我们在物理层学习的双绞线,空气等,用于连接两个节点的物理信道。
(3)数据链路:在物理信道(也就是链路)上加上通过软件实现的协议的控制,就形成了数据链路。区分一个信道是链路还是数据链路就看它是不是涉及协议。
(4)帧:数据链路层的传输单位,它把数据报封装在里面(什么是数据报上一章也讲过了,但是其实数据报是网络层的内容,在下一章还会细讲,这里你知道它是分组就行)。
1.2 数据链路层的功能概述
一句话,数据链路层负责把数据尽可能无差错地从一个节点传输到另一个节点。这里要注意的是,物理层的传输是可能出错的,但是数据链路层从逻辑上是无错的,这里可能有些难以理解,其实是这样的,因为数据链路层可以检测错误,所以当遇到错误的时候,数据链路层会让物理层重新传输数据,直到没有出错。物理层为数据链路层服务,也就是物理层受到数据链路层控制,同时,数据链路层也受到网络层控制。它为网络层提供:无确认无连接服务,有确认无连接服务和有确认面向连接服务,具体什么意思这里不用太明白,只需要知道它们传输越来越慢但是也越来越准确就行。它还为网络层提供链路管理,组帧,流程控制,等,下面会一一学习。
2.封装成帧和透明传输
2.1 封装成帧
其实封装成帧很简单,就是把网络层传下来的数据报给加上帧首和帧尾,然后就形成一个帧。如图:

原本的数据报就成了帧的数据部分。之所以要封装是因为一个设备接收数据的时候是源源不断地传输数据的,也就是它可能一个接一个地接收很多帧,如果不加上帧首部和尾部,那么信宿将无法把每一个帧从数据流里面提取出来。所以帧首部和帧尾部最初和最后的几个比特也被称为帧定界符。帧首部和帧尾部的其他部分则用来实现差错控制,流量控制以及设置具体的物理地址等。通过帧定界符,信宿能区分出帧首和帧尾的过程也被称之为帧同步。
2.2 透明传输
透明传输是链路层的一个必须的要求,我们可以这样理解透明传输,就是首先数据链路层的任何中间节点都是没有能力查看帧的数据内容的(如果允许查看那么我们的数据就不安全了),其次就是帧的首部和尾部仅有能够进行错误查询,流量控制等和这个帧本身的信息,不能够包括一些控制中间节点或者接收方的信息(比如你不能在帧的首部加上一个让路由器死机命令的比特流,当然,根据协议,一般只要路由知道这是帧首部,你加了它也会当作没加,但是难免有些傻瓜式的路由会中招)。
2.3 封装成帧的方法
几乎都是围绕着透明传输展开的,目的就是要让帧界定符不影响帧的数据:
2.3.1 字符计数法
字符计数法就是用帧的第一个字节表示这个帧一共有多少字节。如图所示:

因为一个字节有8位,所以用这种方法,一个帧最多有256个字节。它的缺点是没有差错检验的能力,因为如果第一个字段从5变成3,那么整个数据流都会出错,所以这种方法优点是简单,缺点就是不适用于实际。
2.3.2 字符填充法
就是帧的首部和尾部的帧定界符都是特殊的字符,通常用SOT和EOT来进行表示。不同的协议,表示的SOT和EOT的机器码是不一样的,比如可以用00000001和00000100来表示:

(1)这就要求帧内的数据的字符不能是SOH或者是EOT,否则也是一样的会导致数据传输出错。这种帧的组装方式常常用于文本文件的传输,这是因为文本文件是用ASCLL码组成的,但是SOH和EOT的编码不在ASCLL码里面,而且组帧的方式又简单。
(2)对于非文本文件,比如图像等,其实也可以用字符填充法,但是这就会麻烦一些,具体做法是这样的:发送端会遍历整个数据部分,当发现里面有SOH或者是EOT的时候,就在它们前面加一个字节的转义字符,通常称为ESC,当遇到ESC的时候,还需要在前面再加一个ESC,这和我们写代码,在涉及到关键的符号前面加上斜杆其实非常类似。如图所示:
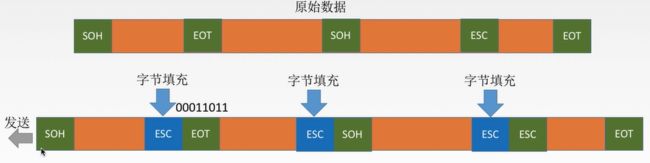
对于中间节点,会忽视ESC后面的内容,对于接收方,遇到第一个ESC会将其删掉:

2.3.3 零比特填充法
零比特填充法和字符填充法很相似,它们都是用特殊的字符作为帧定界符,但是区别在于,零比特填充法的SOH和EOT都是01111110,中间一共6个1。如图所示:

为了防止帧中的数据出现6个1的情况,会在传输前进行扫描,每出现5个1,就会在其后面加一个0。额外需要注意的是:即便只有5个1(0111110),也要在后面加一个0,否则后面接收方恢复的时候会出错(要变成01111100)。
同理,在接收端就需要同步地遇到5个1就删除后面的0。总结起来可以归纳为:5 1 1 0,就是5个1,添加/删除1个0。
2.3.4 违规编码法
违规编码法是目前最常用的,因为它非常简单,并且不容易出错。它是基于曼彻斯特编码产生的:
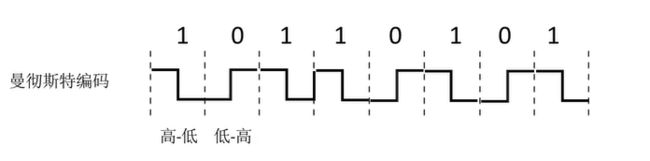
显然,对于曼彻斯特编码,在一个节拍内不会出现连续的两个高节拍或者低节拍,那么我们就用连续的两个高节拍或者连续的两个低节拍来作为帧界定符即可。
这里的要求是,题目给你连续的几个帧,你能分辨出它用的是什么组帧的方法,并且能够分辨出有几个帧即可。
3.差错控制(非常重点,必考内容)
3.1 差错的来源
差错分为两种:
(1)全局差错:这是传输的介质,以及数据本身的电气特性造成的差错,这是信道固有且随机出现的,只能通过提高信噪比的方式来减少差错。
(2)局部差错:这是因为受到外部的短暂干扰(比如说路过汽车的磁场干扰等)引起的,局部差错可以用数据链路层差错控制的方式来加以解决,就是我们要学习的主要内容。
错误还可以根据错的对象分为:
(1)位错:帧里面的某一个或者几个比特的数据从0变1,1变0。
(2)帧错:帧丢失了,帧重复了等。
丢帧的问题可以通过协议来解决,比如等多久就认为没有收到,让发送方重新发送等。位错则是本节学习的重点,所以差错控制旨在解决位错问题。差错控制包括两个部分,检测错误和纠正错误。我们分开来论述:
3.2 检错编码
检测错误是通过在帧首或者帧尾部加上检测错误的编码来实现的,这样的编码我们通常称之为冗余码。冗余码会和要被发送的数据形成一定的特定组合,当接收方收到帧以后,会看这个组合是否被打破了,如果组合和预想的不一样,那就说明发生了错误。常用的冗余码有两种:
3.2.1 奇偶校验码
奇偶校验码的思想很简单,就是这样的:如果需要发送的数据有n-1个比特,那么就在数据的开头或者结尾加一个校验码。奇偶校验还可以分为奇校验码和偶校验码:
(1)奇校验码:如果要发送的n-1个比特的数据,里面1的个数是奇数,校验位是0,1的个数是偶数,校验位是1。也就是发送过去的数据里面如果有偶数个1,则说明出错。
(2)偶校验码:如果要发送的n-1个比特的数据,里面1的个数是偶数,校验位是0,1的个数是奇数,校验位是1。也就是发送过去的数据里面如果有奇数个1,则说明出错。
它的局限很明显,如果帧在发送中,同时有偶数个比特位出错,则会导致无法检测出错误。做个题体会一下:

因为是奇校验码,所以直接看选项哪个不是偶数即可,显然ABC都有偶数个1,发生了明显的错误,而D还是奇数个1,接收方是无法检测的。
因为只能检测奇数错误,不能检测偶数错误,所以奇偶校验码检测能力只有50%。
3.2.2 CRC循环冗余码
目前的数据链路层的通信基本都用这种编码。CRC的实现需要看着王道的这个PPT来学:
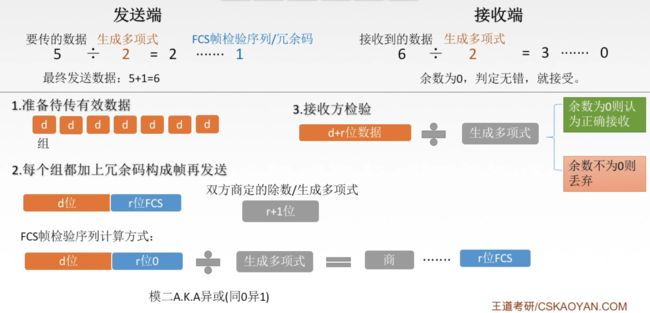
思路就是简单的除法思路,看PPT的最上面。一共分为四步(PPT上是三步,其实是一样的):
(1)发送方准备要发送的有效数据,这不用说。
(2)接收方和发送方一起协商一个r+1位的生成多项式(生成多项式就是PPT上面例子里的除数)。这里要注意的是,生成多项式是01编码,但是有时候题目不会直接给你01序列,而是用数学的形式给你,比如: x 3 + x + 1 x^3+x+1 x3+x+1,它其实代表 1 × x 3 + 0 × x 2 + 1 × x + 1 × x 0 1\times x^3+0\times x^2+1\times x+1\times x^0 1×x3+0×x2+1×x+1×x0,所以是1011。其中,x的最高阶数是多少,其实就代表了FCS有几位。所以FCS的位数和生成多项式的阶数相同。
(3)发送方在要发送的有效数据后面加上r位的0(正好比生成多项式少一位),之后用整段数据模二除法去除以生成多项式,获得的结果的余数就是FCS,然后再用FCS去代替原本的r位的0,然后就可以发送了。
(4)接收方也用模二除法去除以发送过来的数据,如果结果是0,那么就说明没有出错。
这里介绍一下什么是模二除法:
如题:![]()
显然要补上4个0,变成11010110110000来和10011相除,除法过程如下:
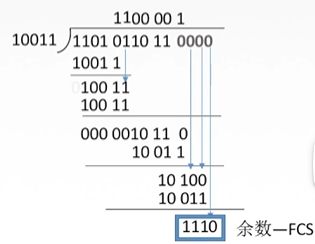
整体上是和我们常用的除法一样,但是不同的是,这里的除法是上下两个数对比,如果相同就是0,不同是1。可以自己算一遍,体会一下。这里再提一句,计算这个的时候,如果被除数的前面几位是0,则是无效的,比如除法竖式的第一步结果是010011,那么前面的0要舍去,就和正常的除法一样。第一次做模二除法很容易在这种地方出错要注意。
所以发送的数据就是1101 0110 11 1110,你可以用这串数字去模二除法10011看看结果是否为0。
这里最后提一句,模二除法可以用硬件瞬间实现,所以采用的是模二除法的方法,底层硬件搞一堆异或门就可以,这个不会考。
使用CRC冗余码的错误检测率几乎是1,所以当除以结果为0的时候,可以认为没有出错。
3.3 纠错编码(海明码)
纠错编码其实不是每一个帧都携带,通常情况,当CRC检测到错误的时候进行重传即可。纠错编码是能够在检测到错误的时候自我恢复(找到错误位置,然后把0变1,1变0)的一种编码,我们常用的纠错编码是海明码,它可以说是奇偶校验码的一种变种。
3.3.1 海明距离
海明距离是学习海明码必不可少的一个概念。海明距离的概念是:两个相同比特位数的编码,对应位置不同的个数(比如:1111和1011只有一位不同,所以它们的海明距离是1)。求海明法的方式其实还可以通过对每一位进行模二除法,然后看结果有多少个1。当对象是一个由多个相同位数的编码集合组成的时候,这个集合的海明距离就是所有集合的元素两两比较后最小的海明距离(比如100, 001和000这个集合的海明距离是1)。
学过计组,我们应该可以知道一个指令集或者符号集里面的编码都是一样长的,所以我们可以计算除任何编码集的海明距。
那么海明距离有什么用呢?如图是两个编码集合:

显然第一个集合的海明码距离是1,第二是2。当出错时,海明码距是1是无法检测出任何错误的,这是因为码距是1,那么不管怎么变,都是集合中的元素。对于第二个,码距是2,则可以检测出一位的错误,但是不能检测出两位的错误,且不能定位是哪里出错了。当码距是3的时候,可以检测出两位的错误,但是只能定位一位的错误。所以这里直接记住一个结论,怎么来的不用太纠结(太纠结可以去百度一下),记住就行,顶多会考选择题:海明码如果需要检测n位比特的错误,那么它要求编码集合的海明距离至少是n+1,如果海明码需要能恢复n位比特的错误,那么它要求编码集合的海明距离至少是2n+1。
3.3.2 用海明码纠错的流程
海明码的使用又和CRC是类似的,需要计算出冗余码,然后给数据加上去。一共是四步走:
(1)确认校验码的位数r:
和之前的RCR不同的是,校验码的位数是用当前数据的位数来进行计算的,我们要求如果会发生x中错误,那么r能表示的数目要大于等于x。我们假设当前数据的位数是m,校验码需要r位,那么就有不等式: 2 r ≥ m + r + 1 2^r\geq m+r+1 2r≥m+r+1
这个不等式也被称之为海明不等式,r的位数是满不等式的最小值。
具体为什么这里简单说一下,因为加上校验码之后,这个数据的总长度就是m+r,如果每次都只有一位发生错误,那么一共就有m+r种错误,然后再加上不发生错误的情况,一共就是m+r+1种,然后r位的校验码最多表示的是 2 r 2^r 2r种情况,所以就有这个不等式,如果说要再考虑到每一次有两位变化的情况你也可以算,但是默认都是每一次只有一位出错。题目不会太难,比如给你一个数据1011,那么让你计算海明校验码的位数,只需要把m换成4,然后对于r从1开始一个个去代入即可。
(2)根据前面的校验码位数,计算出数据的总长度,并且把校验码的位置计算出来:
总长度很好计算,就是m+r,至于校验码的位置只需要填入到 2 n 2^n 2n的位置即可。这么说很抽象,举个例子,比如我们的数据是1011,现在我们还不知道校验码的值是多少,但是我们知道了校验码长是3,需要处于 2 0 , 2 1 , 2 2 2^0,2^1,2^2 20,21,22的位置,也就是在1,2,4的位置(不用担心会溢出的)。这里还需要注意,这里的位置是从右到左的,不是从左到右的,但是之前的数据需要从左到右放:
| 7 | 6 | 5 | 4 | 3 | 2 | 1 |
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 校验码 | 1 | 校验码 | 校验码 |
(3)求校验码的值:
这里直接上一个PPT:

从图上就可以说明为什么第二步需要是 2 n 2^n 2n了,因为要保证对应位置的二进制里面只有一个1,我们把这个1的位置称为通配符,符合通配符的位置的数据都归这个位置的校验码来校验。具体的校验方法就是通过奇校验或者偶校验的方式进行校验,比如图中以1开头的位置一共有偶数个1,所以对应的x4就是0。
(4)检错并纠错:
检错不用说,就是对每一位个校验位都来一次奇偶校验就行。纠错有两种:
【1】把每一个校验位和它对应的位置看作一个集合,然后求出错的交集,再求没有错的差集:
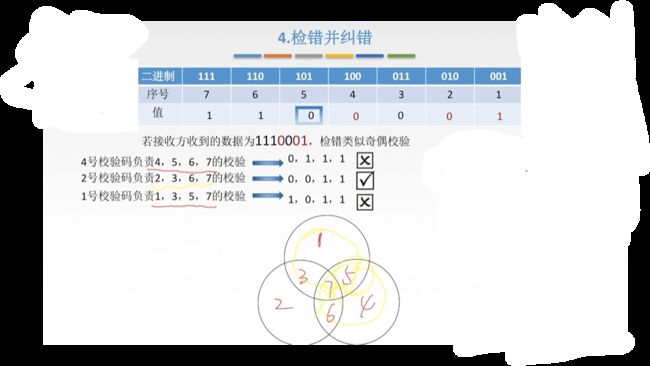
拿王道PPT这例子,很快就可以确认出错的是5(如果1和4都错了就没有办法了,因为只能检测一位的错误)。
【2】第二种方法是一种数论的方法,它更快,只是有些难以理解,做法是这样的:我们先让每一个校验位都根据当前的集合(无论对错)变成对应的奇偶校验码,然后对他们从左到右看,结果就是对应的位置。具体为什么不用深究,理解怎么做就行,还是刚刚的例子:
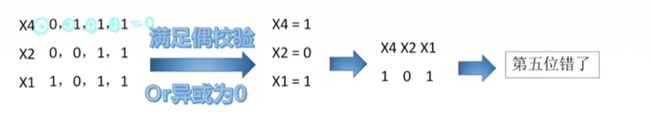
实在理解不了就用第一种方法吧。
因为可靠传输需要大量的协议来实现,并且计网的精髓就是各种协议,所以全部放到下一部分讲解,方便大家快速查看。