flink源码分析之功能组件(四)-slotpool组件II
简介
本系列是flink源码分析的第二个系列,上一个《flink源码分析之集群与资源》分析集群与资源,本系列分析功能组件,kubeclient,rpc,心跳,高可用,slotpool,rest,metrics,future。
本文解释slotpool组件,严格来说,slotpool组件不属于功能组件,而是业务组件,资源消费者申请到资源后,在本地管有资源slot,避免资源管理器异常导致作业运行失败,同时资源管理器不可用也不会影响作业的继续执行,只有资源不足时才会导致作业执行失败。
slotpool组件也是实现声明式资源管理核心,值得我们细细分析。本文slotpool组件II 分析声明式资源管理, slotpool组件I分析slotpool组件的分配/申请资源
检查资源需求/检查资源声明
检查资源需求/检查资源声明是flink声明式资源管理的核心方法
上面的资源场景分为两类,提出资源需求和提供资源, 检查资源请求/检查资源声明是交汇点,处理资源请求,该分配的分配,该请求新的请求新的资源;检查资源声明,哪些资源可以释放,需要新资源请求新worker。
本章深入分析两方法,上游提出资源需求和下游提供资源的串联,资源状态演变,存储型态
检查资源需求(checkResourceRequirements)
检查资源需求是真正的分配资源
1) 获取作业的未完成资源请求
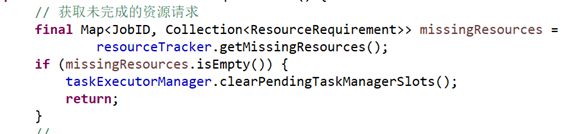
2) 尝试分配可用资源到作业
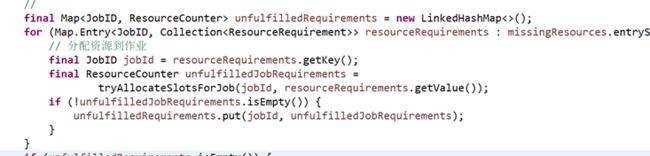
之所以尝试,资源变更触发调用检查资源请求,但不一定是增加,可能是无效分配
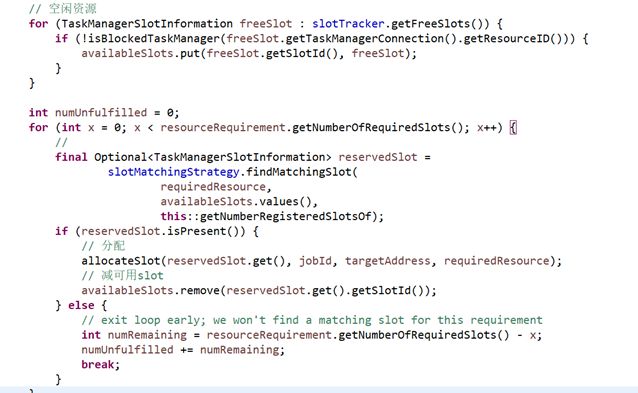
slotTracker获取所有可用资源,与请求匹配,合适的分配allocateSlot,该方法对应场景9.6 请求使用资源/提供资源
3) 尝试使用待定的资源

待定资源是指申请了新的worker或者将要申请新worker所产生的资源,两者都是目前没有物理上的对应资源,通俗说就是先占个坑,等申请了资源再填回去
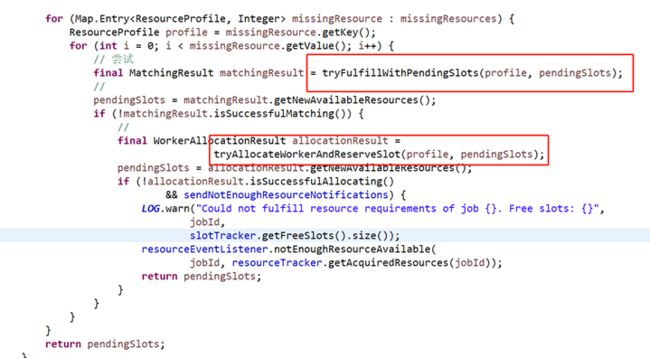
同样,首先匹配现有的待定资源,若还有未分配打开新的待定资源
tryAllocateWorkerAndReserveSlot调用TaskExecutorManager的allocateWorker,预先挖好”坑”,创建待定资源PendingTaskManagerSlot

declareNeededResourcesWithDelay方法下节介绍,按需要申请新的worker,增加物理资源
到此还有一个问题,物理资源到位后怎样填”坑”
自然想到9.5 注册任务管理器/报告资源,使用新增资源抵消待定资源
TaskExecutorManager的registerTaskManager方法

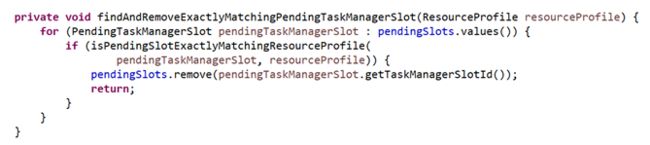
检查资源声明(checkResourceDeclarations)
声明资源,要申请多少资源,可释放多少资源,上一节检查资源请求打开新待定资源,最终调用checkResourceDeclarations,实际申请新worker获得物理资源,为了支持动态/静态资源申请,中间ResourceAllocator转接了一下,这里不详细分析
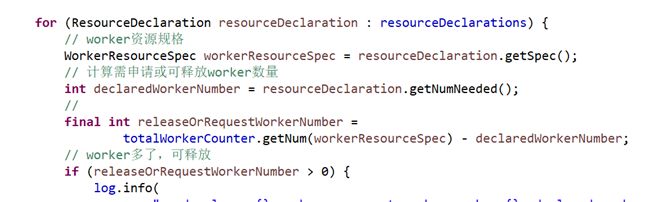
现有的worker数量-需要的worker数量,大于0,worker多了可以释放;反之,worker少了,需要打开新worker
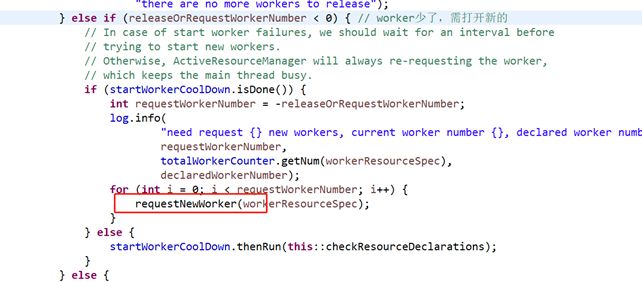
requestNewWorker参看 请求新worker
ResourceDeclaration怎么来?
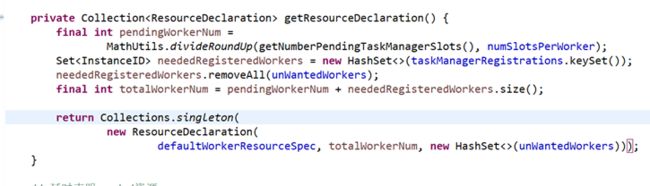
主要是计算totalWorkerNum,目前worker总数量
totalWorkerNum = pendingWorkerNum + neededRegisteredWorkers
pendingWorkerNum 待定的slots除以每个worker的slots,向上修正,只多不少
neededRegisteredWorkers是已经注册的worker减去待释放的worker