手把手教你在AutoDL上部署Qwen-7B-hat Transformers 部署调用
手把手带你在AutoDL上部署Qwen-7B-hat Transformers 调用
项目地址:https://github.com/datawhalechina/self-llm.git
如果大家有其他模型想要部署教程,可以来仓库提交issue哦~ 也可以自己提交PR!
如果觉得仓库不错的话欢迎star!!!
InternLM-Chat-7B Transformers 部署调用
环境准备
在autoal平台中租一个3090等24G显存的显卡机器,如下图所示镜像选择pytorch–>2.0.0–>3.8(ubuntu20.04)–>11.8(要注意在可支持的最高cuda版本>=11.8)

接下来打开自己刚刚租用服务器的JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行demo.

pip换源和安装依赖包
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install modelscope==1.9.5
pip install "transformers>=4.32.0" accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
模型下载
使用modelscope(魔塔社区)中的snapshot_download函数下载模型,第一个参数为模型名称,参数cache_dir为模型的下载路径。
在/root/autodl-tmp路径下新建download.py文件
#将当前工作目录切换到/root/autodl-tmp目录下
cd /root/autodl-tmp
#创建一个名为download.py的空文件
touch download.py
#然后点击该文件夹进行输入
#或者输入以下命令
vim download.py
点击i进入编辑模式
并在其中输入以下内容:
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('Shanghai_AI_Laboratory/internlm-chat-7b', cache_dir='/root/autodl-tmp', revision='master')
粘贴代码后记得保存文件(Ctrl+S),如下图所示。
(如果使用vim命令 粘贴完记得点Esc退出编辑模型然后输入’:wq’回车进行保存退出)


保存后返回终端界面,运行Python /root/autodl-tmp/download.py执行下载,模型大小为15GB,下载模型大概需要10~20分钟。
代码准备
在/root/autodl-tmp路径下新建trans.py文件并在其中输入以下内容
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_dir = '/root/autodl-tmp/qwen/Qwen-7B-Chat'
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation
model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参
# 第一轮对话 1st dialogue turn
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
# 你好!很高兴为你提供帮助。
# 第二轮对话 2nd dialogue turn
response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history)
print(response)
# 这是一个关于一个年轻人奋斗创业最终取得成功的故事。
# 故事的主人公叫李明,他来自一个普通的家庭,父母都是普通的工人。从小,李明就立下了一个目标:要成为一名成功的企业家。
# 为了实现这个目标,李明勤奋学习,考上了大学。在大学期间,他积极参加各种创业比赛,获得了不少奖项。他还利用课余时间去实习,积累了宝贵的经验。
# 毕业后,李明决定开始自己的创业之路。他开始寻找投资机会,但多次都被拒绝了。然而,他并没有放弃。他继续努力,不断改进自己的创业计划,并寻找新的投资机会。
# 最终,李明成功地获得了一笔投资,开始了自己的创业之路。他成立了一家科技公司,专注于开发新型软件。在他的领导下,公司迅速发展起来,成为了一家成功的科技企业。
# 李明的成功并不是偶然的。他勤奋、坚韧、勇于冒险,不断学习和改进自己。他的成功也证明了,只要努力奋斗,任何人都有可能取得成功。
# 第三轮对话 3rd dialogue turn
response, history = model.chat(tokenizer, "给这个故事起一个标题", history=history)
print(response)
# 《奋斗创业:一个年轻人的成功之路》
粘贴代码后记得保存文件,上面的代码有比较详细的注释,大家如有不理解的地方,欢迎提出issue。
部署
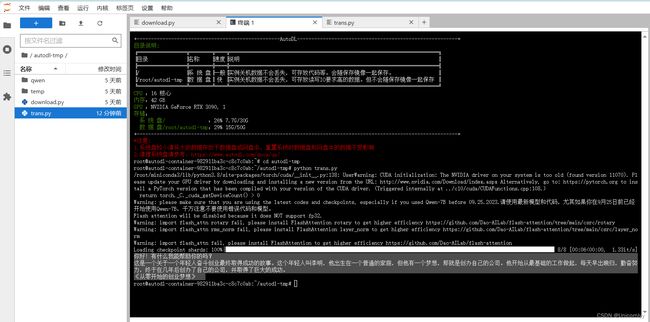
在终端输入以下命令启动transformers服务
cd /root/autodl-tmp
python trans.py
加载完毕后,就可以看到模型生成的对话回答。(需要耐心等待一下哦!)