Using the Recommendation System in a Real World Program
目录
1.对存在的用户推荐
2.新用户怎么处理
3.寻找相似的产品
1.对存在的用户推荐
这章让我们来谈谈把我们的推荐系统应用于现实世界中的最佳实践。让我们打开Chapter 7/train_recommender.py。
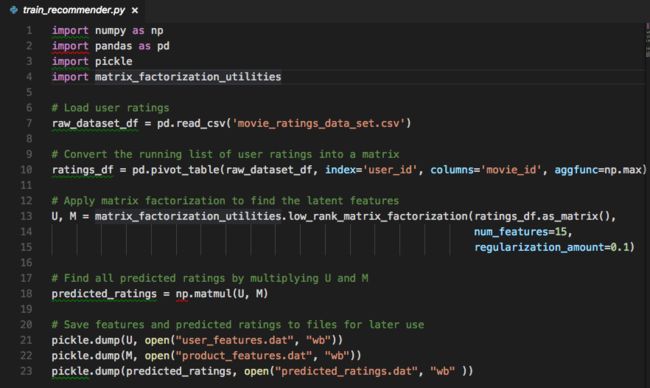
这个文件包含代回顾数据集的代码。我们使用read csv函数读取数据集,然后使用数据透视表函数创建评分矩阵,将矩阵的因子分解为U和M,然后乘以U和M得到预测的评分。由于我们的电影评论数据集较少,这个过程运行得非常快。但是对于更大的数据集,分解过程可能需要几分钟甚至几小时才能运行。
每当我们想要建立一个用户推荐时,我们并不需要每次都分解这个矩阵。相反,将矩阵只分解一次更为实用,并将生成的模型保存到文件中。然后,我们可以稍后使用这些文件来给出推荐,而不需要执行任何计算。 Python提供了一个功能,可以轻松保存和加载来自Pickle(.pkl)文件的数据。所以在代码的最后几行,我们将使用Python的pickle.dump来生成U矩阵,将其命名为user_features.dat。然后,我们将M矩阵生成为product_features.dat。
如果我们要计算产品相似度,这个数据对于保存是有用的。我们还会将预测评级写入一个名为“predicted_ratings.dat”的文件。这是我们需要提供推荐的数据文件。让我们运行脚本来生成这些文件。
在实际使用中,您可能会希望将脚本设置为定期自动运行。这样,当用户写新的评论时,你会定期向你的推荐系统提供新的数据。现在,让我打开文件make_recommendations_from_data_files.py。

该文件的逻辑就是将我们上面生成的数据来推荐电影。首先,我们将使用Pickle重新加载U,M和predicted_ratings文件。我们还会将movie.csv中的电影标题列表加载到df dataframe中,因为我们希望能够访问电影标题。然后,我们要求输入用户ID,然后打印出用户预测评级最高的电影。让我们运行该程序,请注意,当我输入用户ID并按回车时,建议几乎是瞬间的。
那是因为所有的辛苦工作已经提前完成,并保存在数据文件中。将模型生成的缓慢步骤与给出推荐的步骤分开很重要,以减少不必要的等待。
2. 新用户怎么处理
推荐系统在用户已经输入了大量评论的情况下效果很好,但是对于第一次使用者而言,我们对用户还不够了解,而没有提供个性化的建议。有三种方法可以解决这个问题。
第一种,我们可能不会对新用户提出任何推荐。对于某些应用程序,在提出建议之前可能需要等待用户的评价。
第二种方法是使用产品相似性来向没有评价任何内容的用户建议类似的产品,而不是直接给出个性化的推荐。
第三种选择是使用产品的平均评级来提出建议。换句话说,就是向新用户推荐具有最佳综合评级的产品。这可能是有帮助的,因为一些电影通常被多数人认可。如果一部电影对所有用户的平均评分为5星,那么对于推荐给全新用户的电影来说,这可能是比所有用户都有一星评级的电影更好的电影。
关于平均评分,我们只需要对我们的推荐算法进行小小的调整。这是如何工作的。在这里,我们对五位来自五位不同用户的同一部电影进行了五次评价,

首先,我们将计算所有用户对电影的平均评分。在这种情况下,电影的平均评分是4.2分。接下来我们将从每个用户的评分中减去平均评分。对于用户编号1,而不是将等级记录为4,我们将减去4.2并记录为-0.2。这个想法是,这个用户在平均评分下评为0.2星。这些调整的评级是我们将用来做矩阵分解和推荐的。让我们看看这是如何改变的。

假设我们的系统预测特定用户的评分为0.8。我们知道这部电影的平均评分是4.2,所以我们只需要重新加入平均得到用户的最终评分。所以这个用户的预测评级是5星。但最酷的部分是这是如何为全新用户制定出来的。我们可以假设,尚未查看任何内容的全新用户将获得每部电影的预测评分为零。但是现在我们将重新加入平均评分,而电影的预测评分最终为4.2星。所以,即使这个用户还没有看过任何东西,我们可以基于其与其他用户的普及程度来推荐这部电影。
让我们打开train_recommender_cold_start.py,

看看如何在代码中做到这一点。这个文件包含了分解评论数据的代码。我们使用read_csv函数读取数据集,然后使用pivot_table函数创建评分矩阵。现在我们有一个覆盖每部电影的评论矩阵,我们要计算每部电影的平均评分。我们可以使用matrix_factorization_utilities.normalized_ratings函数来做到这一点。这个函数需要一个评级数组来进行平均。所以我们将通过ratings_df数据集。我们调用as_matrix函数来确保评分数据以NumPy数组数据类型的形式传入。
这个函数也返回两个结果。首先它返回每个电影的平均评分。其次它返回一个名为normalized_ratings的评分矩阵的新副本。该副本的平均评分是从每个用户评论中减去的。接下来,我们将矩阵分解为U和M,然后乘以U和M得到预测评分。然后在这里,在我们预测所有用户的评分后,我们需要重新添加每部电影的平均评分。
最后,在底部,我们使用pickle.dump函数将一个方法的副本保存到一个名为means.dat的文件中。让我们来运行程序。我们可以看到文件如期生成。
现在让我们切换到cold_start_recommendations.py

我们在这个文件中的目标是推荐电影给一个全新的用户。首先我们使用pickle.load来加载means.dat文件。然后我们加载电影列表CSV文件,所以我们可以打印出电影标题。
接下来我们使用平均评分作为用户的预测评分。最后,我们会按照平均评分的顺序将影片推荐给用户。让我们运行它,看看结果。右键单击,选择运行。程序推荐了我们拥有的前五名最高平均评分电影。
然鹅,总是向新用户推荐评价最高的电影可能并不完美,但在用户点评某些产品之前,这是一个很好的开始。
3. 寻找相似的产品
在之前的小节中,我们创建了这四个数据文件。如果您现在想创建它们,请在继续之前运行train_recommender_cold_start final.py。现在我们来打开product_similarity_from_data_files.py。当您在真实应用程序中显示相关产品时,您不希望每次重构矩阵,因为它太慢了。相反,您可以使用product_features.dat文件快速计算产品相似度。

首先,我们将使用Python的pickle.load函数加载product_features.dat文件。我们刚刚加载的M矩阵每个电影都有一列。
让我们转置矩阵,使每一列成为一个行。这只是使数据更容易处理,但它不会改变数据。接下来,我们将使用read_csv加载电影列表,以便我们可以访问电影标题。我们将选择一个电影找到类似的电影。我已经选择了movie_id = 5.接下来,我们将在movies_df数据框中查找这部电影,然后打印出电影的标题和流派。现在我们准备好计算电影相似度了。

第一步是从其他电影的特征中减去这部电影的特征。
接下来,我们取这个差值的绝对值,以确保所有的数字是正的。然后,我们将每个电影的不同特征差异总和看作该电影的一个特别的总分。然后,我们将这些特别的分数保存到movies_df数据框中。然后对电影列表进行排序,以便最少的不同电影在列表中排在第一位。最后,我们可以列出列表中的前五部电影。让我们来运行这个。右键单击,选择运行。

好,我们的电影被称为大城市法官2.这个列表中的第一部电影是电影本身。那是因为一部电影与它本身最相似。
让我们忽略那一个。其他四部电影看起来与我们的电影非常相似。他们都像犯罪或法律剧情。在列表中我们甚至可以看到续集-大城市法官3。但请注意,这几乎是瞬间运行的,因为所有计算电影功能的辛苦工作都是提前完成的。现在,我们可以在数据文件中使用这些功能,我们可以使用这些功能来即时查找类似的产品,而不会对用户造成任何延迟。
结尾
在本课程中,我们介绍了您需要知道如何构建推荐系统的基本技能。 我鼓励你用自己的数据尝试你get到的新技能。 去折腾一些东西。 如果您没有任何自己的产品数据可供使用,则可以在网上下载真实数据集。 您可以尝试的一个数据集是免费的MovieLens数据集。 MovieLens数据集包含数以千万计的电影评论,这将让你有机会尝试用你所学到的知识处理大规模数据。 如果您更擅长Java编码,那么您也可以尝试使用Apache Mahout。 Apache Mahout是一个开源应用程序,它实现了我们在本课程中学到的同类协作过滤算法。
Apache Mahout旨在跨多台计算机运行,这对于大型数据集非常有用,而这些数据集太慢而无法在单台计算机上运行。
哦了, 推荐系统入门课程到此结束。
作者:奔IV程序猿
链接:https://www.jianshu.com/p/4d9a0d516854
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。