透彻理解大模型框架:Transformer模型原理详解与机器翻译

注意力,自注意力,transformer研究变迁

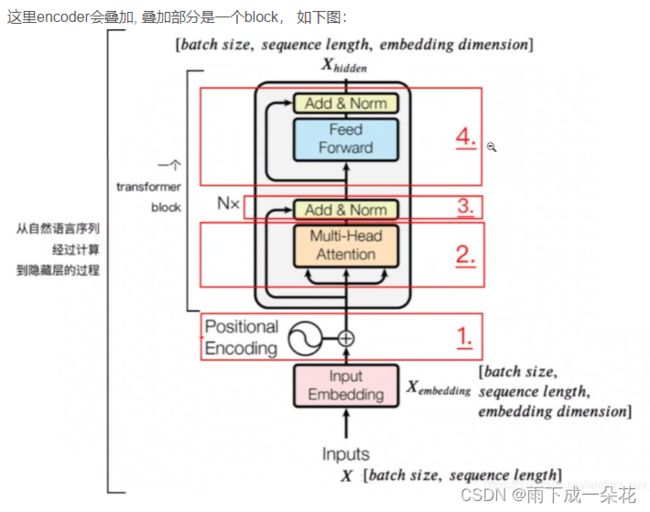
1、模型结构
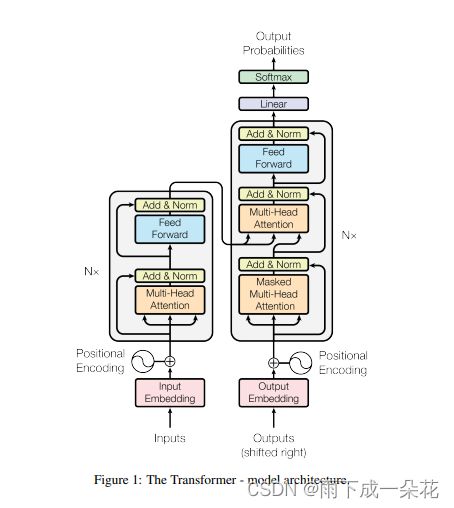
2、模型encoding过程
2.1)注意力机制

input=x={x1,x2}
输入句子:{thiking machine}
embeding:x1,x2
Thinking x1 = { }; Machine x2 = { }
已知神经网络权重:W_q, W_k, W_v
W_q, W_k, W_v
W_q*x1 = q1 = [ 3,1,50], W_q*x2 = q2 = [2,4,8]
W_k*x1 = k1 = [ 4,50,1], W_k*x2 = k2 = [3,37,1]
W_v*x1 = v1 = [ 3,1,4], W_v*x2 = v2 = [2,6,8]
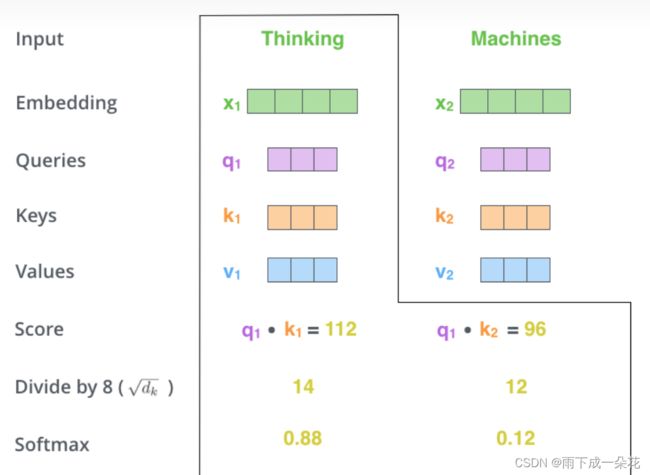
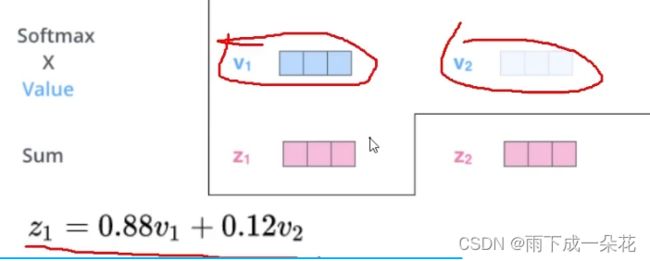
下面计算注意力矩阵,与Z

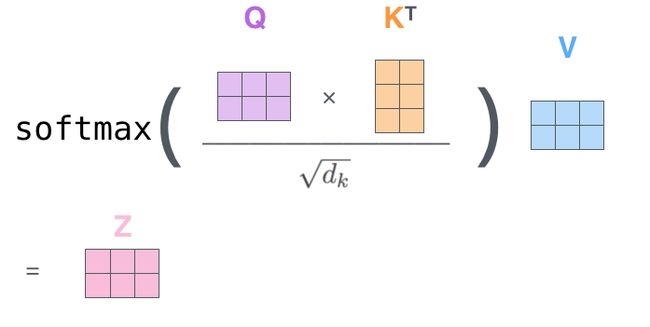
得到注意力矩阵:
注意力矩阵QK/
softmax(QK/)=
![]()
Z=softmax(QK'/)*V
![]()
![]()
注释:1、经过注意力矩阵与v相乘后,得到Z, Z已经不在是两个单词的向量了。但是至少一点是肯定的,Z的信息已经融合了两个单词各个分量以及权重的信息。
2、注意力矩阵的维度,是输入句子长度未n,单词维度为d,即n*d, 也就是输入句子的矩阵的维度(X)n*d,由此可知 注意力矩阵:n*n维数。
3、经过encoding后,Z的大小,也是n*n*n*d=n*d维数,也就是输入(输出)句子的维数。
4、softmax概率分类器,是针对注意力矩阵按行进行概率归一化。

类似的道理,接入多头注意力机制
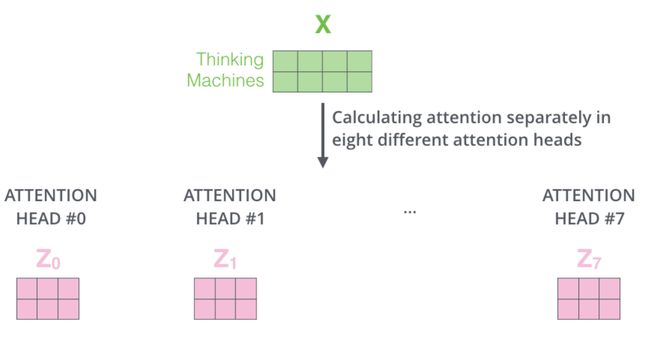

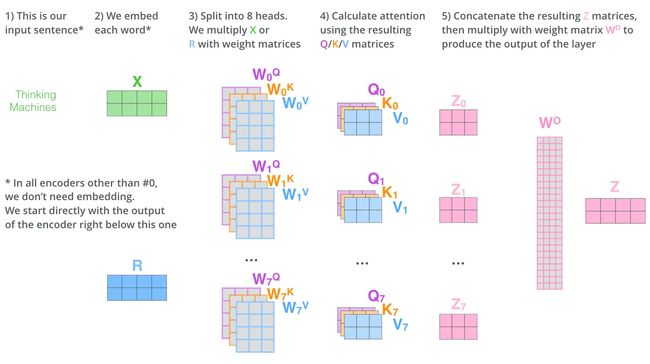
2.2)位置嵌入
将每个位置编号,然后每个编号对应一个向量,通过将位置向量和词向量相加,就给每个词都引入了一定的位置信息,这样 attention 就可以分辨出不同位置的词了。
The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed.

不妨假设序列长度为6(6个单词),维数为8(每个 单词维数), X为6*8的向量,n=6, d=8; 2i = 0,2,4,6,8; 2i+1 = 1,3,5,7;
取绝对位置为:pos=[0, 1,2,3,4,5, 6, 7],其中 i=0, 1,2,3,4;dmodel=8;
得到下面奇数,偶数位置的嵌入向量:
PositionEmbeding=
合并上面式子,得到位置嵌入向量:
因为用正弦波,所以取值为波长0到2pi的整数倍之间。
X的每一个token的词的向量为一个8维数序列,加上位置向量,就完成向量的嵌入。
下面举例:给出句子10个词,每个词用64维向量表示,此时靠近单词位置越近编码效果越明显。前20维的频率变化越明显,数据位置编码效果越明显。

cos,sin位置编码,只考虑了句子间词与词的空间位置,不考虑词的先后顺序。比如课堂举的例子:谁是谢霆锋的儿子?谢霆锋是谁的儿子?这两句话的语义完全不同,采用正弦余弦的位置编码,会截然不同。正因为不考虑词出现的先后顺序导致的弊端,所有有研究改进这一缺陷。
2.3)生成注意力机制后,作残差相加,FFN两个过程

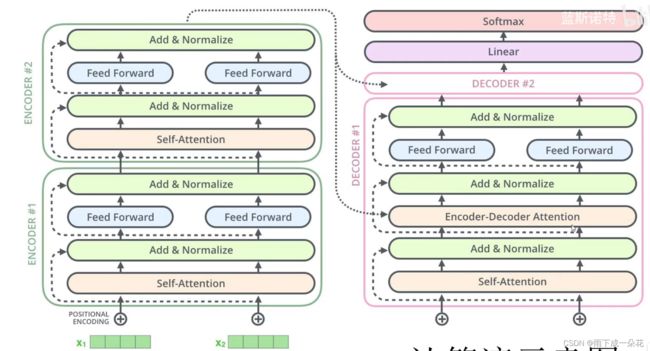
2.4) encoder-decoder执行动图
encoder-decoder 框架
3、transformer 注意力机制








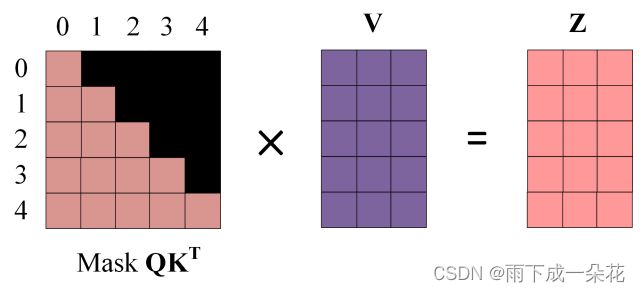
4、 句子补全掩码和注意机制掩码
Padding Mask(句子补丁掩码):
假如是每个batch的句子不等长的情况, 那么我们需要加padding, 使得每个句子的长度变一致. 但是必须保证加的padding不会影响其他句子, 那么这就可以在padding区域加一个mask, 具体来说也就是给无效的区域加个负偏置, 因为softmax是e的对数, 假如是接近负无穷的话相应的注意力部分就接近于0

Masked Self-Attention(自注意力掩码):

之后再做 softmax,就能将 - inf 变为 0,得到的这个矩阵即为每个字之间的权重
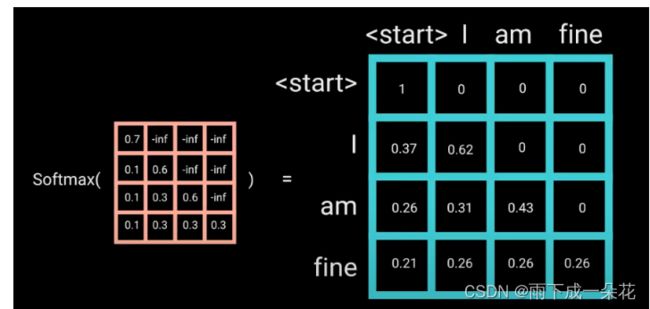
掩码图示:(非常直观)每次只能看到V的各行的单词的当前位置单词和之前的位置的单词,当前单词的后续单词根本看不到。
Decoder中第二个 Multi-Head Attention:
其实也叫cross-attention,融合encoder中的输出矩阵Q,K,V,Z。
- Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 Z计算的。
- 根据 Encoder 的输出 Z计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
- 这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
5、样本数据层正态分布规范化Layer Normalization

batch_norm和layer_norm的区别:
BN针对批次内的所有样本作数据正态分布标准化。而 LN正对批次内各个样本做数据正态分布规范,如下图清晰显示。前者是全局数据上的规范,容易导致数据抖动。后者样本内作规范,规范后数据误差明显更小。

三维数据的演示如下图:


6、transformer 整个流程计算公式

提示:为了更好的理解以上内容,是如何编码的,为了360度弄明白transformer的代码是如何巧妙实现的,可以参考一本好书 :邵浩,邵一峰《预训练语言模型》,电子工业出版社,2021.5。
7、transformer实践
1)基于transformer的情感分析实践
见20级电子信息短学期课程(aistuidio)
2)基于transformer的机器翻译
环境要求如上述requirements
简介
本文使用PyTorch自带的transformer层进行机器翻译:从德语翻译为英语。从零开始实现Transformer请参阅PyTorch从零开始实现Transformer,以便于获得对Transfomer更深的理解。
数据集
Multi30k
环境要求
使用torch, torchtext,spacy,其中spacy用来分词。另外,spacy要求在虚拟环境中下载语言模型,以便于进行tokenize(分词)
# To install spacy languages do:
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm
实验代码
代码来源请参考下方的GitHub链接
transformer_translation.py文件
# Bleu score 32.02
import torch
import torch.nn as nn
import torch.optim as optim
import spacy
from utils import translate_sentence, bleu, save_checkpoint, load_checkpoint
from torch.utils.tensorboard import SummaryWriter
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIterator
"""
To install spacy languages do:
python -m spacy download en_core_web_sm
python -m spacy download de_core_news_sm
"""
spacy_ger = spacy.load("de_core_news_sm")
spacy_eng = spacy.load("en_core_web_sm")
def tokenize_ger(text):
return [tok.text for tok in spacy_ger.tokenizer(text)]
# 将英语进行分词
def tokenize_eng(text):
return [tok.text for tok in spacy_eng.tokenizer(text)]
german = Field(tokenize=tokenize_ger, lower=True, init_token="", eos_token="")
english = Field(
tokenize=tokenize_eng, lower=True, init_token="", eos_token=""
)
train_data, valid_data, test_data = Multi30k.splits(
exts=(".de", ".en"), fields=(german, english)
)
german.build_vocab(train_data, max_size=10000, min_freq=2)
english.build_vocab(train_data, max_size=10000, min_freq=2)
class Transformer(nn.Module):
def __init__(
self,
embedding_size,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
max_len,
device,
):
super(Transformer, self).__init__()
self.src_word_embedding = nn.Embedding(src_vocab_size, embedding_size)
self.src_position_embedding = nn.Embedding(max_len, embedding_size)
self.trg_word_embedding = nn.Embedding(trg_vocab_size, embedding_size)
self.trg_position_embedding = nn.Embedding(max_len, embedding_size)
self.device = device
self.transformer = nn.Transformer(
embedding_size,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
)
self.fc_out = nn.Linear(embedding_size, trg_vocab_size)
self.dropout = nn.Dropout(dropout)
self.src_pad_idx = src_pad_idx
def make_src_mask(self, src):
src_mask = src.transpose(0, 1) == self.src_pad_idx
# (N, src_len)
return src_mask.to(self.device)
def forward(self, src, trg):
src_seq_length, N = src.shape
trg_seq_length, N = trg.shape
src_positions = (
torch.arange(0, src_seq_length)
.unsqueeze(1)
.expand(src_seq_length, N)
.to(self.device)
)
trg_positions = (
torch.arange(0, trg_seq_length)
.unsqueeze(1)
.expand(trg_seq_length, N)
.to(self.device)
)
embed_src = self.dropout(
(self.src_word_embedding(src) + self.src_position_embedding(src_positions))
)
embed_trg = self.dropout(
(self.trg_word_embedding(trg) + self.trg_position_embedding(trg_positions))
)
src_padding_mask = self.make_src_mask(src)
trg_mask = self.transformer.generate_square_subsequent_mask(trg_seq_length).to(
self.device
)
out = self.transformer(
embed_src,
embed_trg,
src_key_padding_mask=src_padding_mask,
tgt_mask=trg_mask,
)
out = self.fc_out(out)
return out
# We're ready to define everything we need for training our Seq2Seq model
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
load_model = False
save_model = True
# Training hyperparameters
num_epochs = 10
learning_rate = 3e-4
batch_size = 32
# Model hyperparameters
src_vocab_size = len(german.vocab)
trg_vocab_size = len(english.vocab)
embedding_size = 512
num_heads = 8
num_encoder_layers = 3
num_decoder_layers = 3
dropout = 0.10
max_len = 100
forward_expansion = 4
src_pad_idx = english.vocab.stoi[""]
# Tensorboard to get nice loss plot
writer = SummaryWriter("runs/loss_plot")
step = 0
train_iterator, valid_iterator, test_iterator = BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=batch_size,
sort_within_batch=True,
sort_key=lambda x: len(x.src),
device=device,
)
model = Transformer(
embedding_size,
src_vocab_size,
trg_vocab_size,
src_pad_idx,
num_heads,
num_encoder_layers,
num_decoder_layers,
forward_expansion,
dropout,
max_len,
device,
).to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, factor=0.1, patience=10, verbose=True
)
pad_idx = english.vocab.stoi[""]
criterion = nn.CrossEntropyLoss(ignore_index=pad_idx)
if load_model:
load_checkpoint(torch.load("my_checkpoint.pth.tar"), model, optimizer)
# 'a', 'horse', 'is', 'walking', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.
sentence = "ein pferd geht unter einer brücke neben einem boot."
for epoch in range(num_epochs):
print(f"[Epoch {epoch} / {num_epochs}]")
if save_model:
checkpoint = {
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
save_checkpoint(checkpoint)
model.eval()
translated_sentence = translate_sentence(
model, sentence, german, english, device, max_length=50
)
print(f"Translated example sentence: \n {translated_sentence}")
model.train()
losses = []
for batch_idx, batch in enumerate(train_iterator):
# Get input and targets and get to cuda
inp_data = batch.src.to(device)
target = batch.trg.to(device)
# Forward prop
output = model(inp_data, target[:-1, :])
# Output is of shape (trg_len, batch_size, output_dim) but Cross Entropy Loss
# doesn't take input in that form. For example if we have MNIST we want to have
# output to be: (N, 10) and targets just (N). Here we can view it in a similar
# way that we have output_words * batch_size that we want to send in into
# our cost function, so we need to do some reshapin.
# Let's also remove the start token while we're at it
output = output.reshape(-1, output.shape[2])
target = target[1:].reshape(-1)
optimizer.zero_grad()
loss = criterion(output, target)
losses.append(loss.item())
# Back prop
loss.backward()
# Clip to avoid exploding gradient issues, makes sure grads are
# within a healthy range
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1)
# Gradient descent step
optimizer.step()
# plot to tensorboard
writer.add_scalar("Training loss", loss, global_step=step)
step += 1
mean_loss = sum(losses) / len(losses)
scheduler.step(mean_loss)
# running on entire test data takes a while
score = bleu(test_data[1:100], model, german, english, device)
print(f"Bleu score {score * 100:.2f}")
utils.py文件
import torch
import spacy
from torchtext.data.metrics import bleu_score
import sys
def translate_sentence(model, sentence, german, english, device, max_length=50):
# Load german tokenizer
spacy_ger = spacy.load("de_core_news_sm")
# Create tokens using spacy and everything in lower case (which is what our vocab is)
if type(sentence) == str:
tokens = [token.text.lower() for token in spacy_ger(sentence)]
else:
tokens = [token.lower() for token in sentence]
# Add and in beginning and end respectively
tokens.insert(0, german.init_token)
tokens.append(german.eos_token)
# Go through each german token and convert to an index
text_to_indices = [german.vocab.stoi[token] for token in tokens]
# Convert to Tensor
sentence_tensor = torch.LongTensor(text_to_indices).unsqueeze(1).to(device)
outputs = [english.vocab.stoi[""]]
for i in range(max_length):
trg_tensor = torch.LongTensor(outputs).unsqueeze(1).to(device)
with torch.no_grad():
output = model(sentence_tensor, trg_tensor)
best_guess = output.argmax(2)[-1, :].item()
outputs.append(best_guess)
if best_guess == english.vocab.stoi[""]:
break
translated_sentence = [english.vocab.itos[idx] for idx in outputs]
# remove start token
return translated_sentence[1:]
def bleu(data, model, german, english, device):
targets = []
outputs = []
for example in data:
src = vars(example)["src"]
trg = vars(example)["trg"]
prediction = translate_sentence(model, src, german, english, device)
prediction = prediction[:-1] # remove token
targets.append([trg])
outputs.append(prediction)
return bleu_score(outputs, targets)
def save_checkpoint(state, filename="my_checkpoint.pth.tar"):
print("=> Saving checkpoint")
torch.save(state, filename)
def load_checkpoint(checkpoint, model, optimizer):
print("=> Loading checkpoint")
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
实验结果:
输入德文:(在主程序中间位置)
sentence = "ein pferd geht unter einer brücke neben einem boot."
翻译结果为:
['a', 'horse', 'walks', 'underneath', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '']
跑了10个Epoch,结果如下所示:
# Result
=> Loading checkpoint
[Epoch 0 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'under', 'a', 'boat', 'next', 'to', 'a', 'boat', '.', '']
[Epoch 1 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'underneath', 'a', 'bridge', 'beside', 'a', 'boat', '.', '']
[Epoch 2 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'is', 'walking', 'beside', 'a', 'boat', 'under', 'a', 'bridge', '.', '']
[Epoch 3 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '']
[Epoch 4 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '']
[Epoch 5 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'beside', 'a', 'boat', 'next', 'to', 'a', 'boat', '.', '']
[Epoch 6 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'is', 'walking', 'underneath', 'a', 'bridge', 'under', 'a', 'boat', '.', '']
[Epoch 7 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'under', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '']
[Epoch 8 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'beneath', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '']
[Epoch 9 / 10]
=> Saving checkpoint
Translated example sentence:
['a', 'horse', 'walks', 'underneath', 'a', 'bridge', 'next', 'to', 'a', 'boat', '.', '']
Bleu score 31.73
参考文献:
1、transformer的原理_transformer原理_live_for_myself的博客-CSDN博客
2、https://arxiv.org/abs/1706.03762
3、 https://blog.csdn.net/weixin_43632501/article/details/98731800
4、https://www.youtube.com/watch?v=M6adRGJe5cQ
5、 https://github.com/aladdinpersson/Machine-Collection/blob/masterLearning-/ML/
Pytorch/more_advanced/seq2seq_transformer/seq2seq_transformer.py
6、 https://blog.csdn.net/g11d111/article/details/100103208
数据集:
https://download.csdn.net/download/weixin_42138525/18403891?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169475007116800211579515%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fdownload.%2522%257D&request_id=169475007116800211579515&biz_id=1&utm_medium=distribute.pc_search_result.none-task-download-2~all~insert_down_v2~default-3-18403891-null-null.142^v94^insert_down1&utm_term=Multi30k&spm=1018.2226.3001.4187.4