Python爬虫 | 自学笔记记录
文章目录
- 1.urllib
-
- urllib的基本使用
- 1个类型和6个方法
- 下载
-
- 下载网页
- 下载图片
- 下载视频
- 请求对象的定制
- get
-
- get请求的quote方法
- get请求的urlencode方法
- post
-
- post请求百度翻译
- post请求百度翻译之详细翻译
- ajax
-
- ajax的get请求-豆瓣电影第一页
- ajax的get请求-豆瓣电影前十页
- ajax的post请求-肯德基官网
- 异常
- 2.解析
-
- 2.1xpath
- Requests库
-
- Requests库的get( )方法
- 爬取网页的通用代码框架
1.urllib
urllib的基本使用
#使用urllib来获取百度首页的源码
import urllib.request
#1.定义一个url,即想要访问的地址
url="http://www.baidu.com"
#2.模拟浏览器,向服务器发送请求;response为响应
response=urllib.request.urlopen(url)
#3.获取响应中的页面的源码
#read()返回的是字节形式的二进制数据;因此要将其转换为字符串(称为解码)
#解码:decode('编码的格式')
content=response.read().decode('utf-8')
#4.打印数据
print(content)
1个类型和6个方法
一个类型:HTTPResponse
六个方法:read() ,readline() ,readlines() ,getcode() ,geturl() ,getheaders()
import urllib.request
url="http://www.baidu.com"
#模拟浏览器,向服务器发送请求
response=urllib.request.urlopen(url)
#一个类型和六个方法
print(type(response)) #输出为HTTPResponse的类型>
content=response.read()#read()是按照一字节一字节的读
print(content)
content=response.read(5)#只读取5个字节
print(content)
content=response.readline()#读取一行
print(content)
content=response.readlines()#一行一行的读,直到读完
print(content)
print(response.getcode())#返回状态码:若为200,则证明逻辑正确;反之有错
print(response.geturl())#返回uel地址
print(response.getheaders())#返回一个状态信息
下载
下载网页
import urllib.request
url_page="http://www.baidu.com"
#urlretrieve(url,filename),直接将远程数据下载到本地。
#url代表下载的路径,filename代表文件名字
urllib.request.urlretrieve(url_page,'baidu,html')
下载图片
import urllib.request
url_img="https://wx4.sinaimg.cn/mw2000/003gVZ4ply1h468celk9dj614j0sodjp02.jpg"
urllib.request.urlretrieve(url_img,'1.jpg')
结果:

下载视频
import urllib.request
url_video="https://...." #填写视频地址
urllib.request.urlretrieve(url_video,'12.mp4')
请求对象的定制
以 https://www.baidu.com/s?wd=周杰伦 为例,分析url的组成:
协议(http;https)、主机(www.baidu.com)、端口号、路径(s)、参数(wd=周杰伦)、锚点六部分。
import urllib.request
url="https://www.baidu.com"
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
#因为urlopen()方法中不能存储字典,所以headers不能传递进去
#请求对象的定制 为了解决反爬的第一种手段
#request=urllib.request.Request(url,headers) 由于参数顺序的问题。不能直接写url和headers,中间还有个date,因此需要关键字来传递参数
request=urllib.request.Request(url=url,headers=headers)
response=urllib.request.urlopen(request)
content=response.read().decode('utf8')
print(content)
get
get请求的quote方法
#需求:获取某网页的源码
import urllib.request
import urllib.parse
url="https://www.baidu.com/s?wd="
#请求对象的定制,是为了解决反爬的第一种手段
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
#网页中的wd=之后就是要搜索的内容,但中文必须要转换成unicode编码格式才能识别,因此要用到get请求中的quote方法
#利用urllib.parse可将“周杰伦”三个字改为unicode编码格式
name=urllib.parse.quote('周杰伦')
url=url+name
#请求对象的定制
request=urllib.request.Request(url=url,headers=headers)
#模拟浏览器向服务器发送请求
response=urllib.request.urlopen(request)
#获取响应的内容
content=response.read().decode('utf-8')
print(content)
get请求的urlencode方法
#urlencode使用场景:将多个中文的参数转换为unicode编码格式,
#https://www.baidu.com/s?wd=周杰伦&sex=男
import urllib.parse
data={'wd':'周杰伦','sex':'男'}
a=urllib.parse.urlencode(data)
print(a)
输出:
wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7
#获取网页源码:https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7&location=%E4%B8%AD%E5%9B%BD%E5%8F%B0%E6%B9%BE%E7%9C%81
import urllib.request
import urllib.parse
base_url='https://www.baidu.com/s?'
data={"wd":"周杰伦",'sex':"男","location":"中国台湾省"}
new_data=urllib.parse.urlencode(data)
url=base_url+new_data #请求资源路径
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
request=urllib.request.Request(url=url,headers=headers) #请求对象的定制
response=urllib.request.urlopen(request) #模拟浏览器向服务器发送请求
content=response.read().decode('utf-8') #获取网页源码的数据
print(content)
post
post请求百度翻译
#post请求
import urllib.request
import urllib.parse
url='https://fanyi.baidu.com/sug'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
data={'kw':'apple'}#参数
data=urllib.parse.urlencode(data).encode('utf8')#post请求的参数,必须进行编码;编码之后必须调用encode方法
#post请求的参数不放在url之后,而需要放在请求对象定制的参数中
request=urllib.request.Request(url=url,data=data,headers=headers)
response=urllib.request.urlopen(request) #模拟浏览器向服务器发送请求
content=response.read().decode('utf8') #获取响应的数据
print(content)
print(type(content)) #输出,表示结果为字符串类型
#将字符串转为json对象
import json
obj=json.loads(content)
print(obj)
结果:
{"errno":0,"data":[{"k":"Apple","v":"n. \u82f9\u679c\u516c\u53f8\uff0c\u539f\u79f0\u82f9\u679c\u7535\u8111\u516c\u53f8"},{"k":"apple","v":"n. \u82f9\u679c; \u82f9\u679c\u516c\u53f8; \u82f9\u679c\u6811"},{"k":"APPLE","v":"n. \u82f9\u679c"},{"k":"apples","v":"n. \u82f9\u679c\uff0c\u82f9\u679c\u6811( apple\u7684\u540d\u8bcd\u590d\u6570 ); [\u7f8e\u56fd\u53e3\u8bed]\u68d2\u7403; [\u7f8e\u56fd\u82f1\u8bed][\u4fdd\u9f84\u7403]\u574f\u7403; "},{"k":"Apples","v":"[\u5730\u540d] [\u745e\u58eb] \u963f\u666e\u52d2"}]}
<class 'str'>
{'errno': 0, 'data': [{'k': 'Apple', 'v': 'n. 苹果公司,原称苹果电脑公司'}, {'k': 'apple', 'v': 'n. 苹果; 苹果公司; 苹果树'}, {'k': 'APPLE', 'v': 'n. 苹果'}, {'k': 'apples', 'v': 'n. 苹果,苹果树( apple的名词复数 ); [美国口语]棒球; [美国英语][保龄球]坏球; '}, {'k': 'Apples', 'v': '[地名] [瑞士] 阿普勒'}]}
post请求百度翻译之详细翻译
#post请求
import urllib.request
import urllib.parse
url='https://fanyi.baidu.com/v2transapi?from=zh&to=en'
headers={'Accept': '*/*',
#'Accept-Encoding': 'gzip, deflate, br',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Acs-Token': 'xxx',
# 'Connection': 'keep-alive',
# 'Content-Length': '149',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
#最关键的信息
'Cookie': 'BIDUPSID=4E530801EC1766332254E921421A06E7; PSTM=1606439419; __yjs_duid=1_d79ddc8c4cc115430f5303180b7523d81617935265598; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=FpCbkdmTElBSE9qV1IyR0R0UndzY0RGUjV-SXFGbUk3eG9qWkxMRm5zLU16M1JpRVFBQUFBJCQAAAAAAQAAAAEAAACBxDcRs73UwrSoutMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIxCTWKMQk1iS; BDUSS_BFESS=FpCbkdmTElBSE9qV1IyR0R0UndzY0RGUjV-SXFGbUk3eG9qWkxMRm5zLU16M1JpRVFBQUFBJCQAAAAAAQAAAAEAAACBxDcRs73UwrSoutMAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAIxCTWKMQk1iS; MCITY=-%3A; BAIDUID=C9CEC228E1166EA508BEEAFCA6AAFEA1:FG=1; BA_HECTOR=a0al0l2hak2ha5202l0k3bah1hd09r617; BAIDUID_BFESS=C9CEC228E1166EA508BEEAFCA6AAFEA1:FG=1; ZFY=JV7vJpwl:BmZ:AvgyVw9pdau0WaYrwqJzKxKYmQ94iJ1g:C; BDRCVFR[2bJV-P92G9m]=mk3SLVN4HKm; delPer=0; PSINO=7; H_PS_PSSID=; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; RT="z=1&dm=baidu.com&si=v5eehd7cn&ss=l5lsvz81&sl=3&tt=4os&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=5m6&ul=av4&hd=aww"; APPGUIDE_10_0_2=1; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1657849782; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1657849827; ab_sr=1.0.1_ZTRlNmNkMmJlY2I0ZmM3N2I3YTJkMmY5NzExOTBjMDE1N2ExYWI4Y2NkYWUwOTU3NjNmMWZmMzg1YmEwODZiNWQwMmMzMzMwYTY5ZmU5ZTZhMmQ5M2JjZmIxM2QwMGQyZjk5MmJiNzEwYThlNGU3MDEwYjA1Y2ZhZWFmMDc0ZTgzNjFmMzZhZTdiMWUzMjUyODcyMTQzMDMzODQ5NGRkYjk0OTRjYzY5NzU4N2U0ZjgwNGFhNjQxMDBmYjU5MDU3',
# 'Host': 'fanyi.baidu.com',
# 'Origin': 'https://fanyi.baidu.com',
# 'Referer': 'https://fanyi.baidu.com/',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
}
data={'from': 'zh','to': 'en','query': '数学','transtype': 'realtime','simple_means_flag': '3','sign': '636725.873476','token': '5a07e831f91c2f43861e7ccb54a77eb3','domain': 'common'} #参数
data=urllib.parse.urlencode(data).encode('utf8') #post请求的参数,必须进行编码;编码之后必须调用encode方法
request=urllib.request.Request(url=url,data=data,headers=headers)#post请求的参数不放在url之后,而需要放在请求对象定制的参数中
response=urllib.request.urlopen(request) #模拟浏览器向服务器发送请求
content=response.read().decode('utf8') #获取响应的数据
print(content)
print(type(content)) #输出,表示结果为字符串类型
#将字符串转为json对象
import json
obj=json.loads(content)
print(obj)
ajax
ajax的get请求-豆瓣电影第一页
#get请求 获取豆瓣纪录片第一页的数据并保存
import urllib.request
import urllib.parse
url='https://movie.douban.com/j/chart/top_list?type=1&interval_id=100%3A90&action=&start=0&limit=20'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36' }
request=urllib.request.Request(url=url,headers=headers)#1.请求对象的定制
response=urllib.request.urlopen(request) #2.模拟浏览器向服务器发送请求
content=response.read().decode('utf8') #3.获取响应的数据
fp=open('douban.json','w',encoding='utf-8')#4.数据下载到本地;open()方法默认使用的是gbk的编码,若想保存为中文,则应指定编码为utf8
fp.write(content)
# 保存数据的另一种写法,与上述第4步相同
# with open('douban.json','w',encoding='utf8') as fp:
# fp.write(content)
ajax的get请求-豆瓣电影前十页
#get请求 获取豆瓣纪录片前十页的数据并保存
# https://movie.douban.com/j/chart/top_list?type=1&interval_id=100%3A90&action=&start=0&limit=20 第一页
# https://movie.douban.com/j/chart/top_list?type=1&interval_id=100%3A90&action=&start=20&limit=20 第二页
# https://movie.douban.com/j/chart/top_list?type=1&interval_id=100%3A90&action=&start=40&limit=20 第三页
import urllib.parse
import urllib.request
def creat_request(page):
base_url='https://movie.douban.com/j/chart/top_list?type=1&interval_id=100%3A90&action=&'
data={'start':20*(page-1),'limit':20}
data=urllib.parse.urlencode(data)
url=base_url+data
print(url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
request=urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf8')
return content
def download(page,content):
# with open('douban'+page+'.json','w',encoding='utf8') as fp:
# 注:Python中字符串拼接时,加号两边必须都是字符串,因此page必须强制类型转换
with open('douban' + str(page) + '.json', 'w', encoding='utf8') as fp:
fp.write(content)
start_page=int(input('请输入起始页码:'))
end_page=int(input("请输入结束的页码:"))
for page in range(start_page,end_page+1):
request=creat_request(page) #使每一页都有 请求对象的定制
content=get_content(request) #获取响应的数据
download(page,content) #下载数据
ajax的post请求-肯德基官网
从肯德基官网中,下载武汉市门店地址信息:
#网页中可看到每一页的信息如下:
#http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword 第1页与第n页的url均一致
# cname:
# pid:
# keyword: 武汉
# pageIndex: 1
# pageSize: 10
import urllib.request
import urllib.parse
def creat_request(page):
base_url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword '
data={'cname':'','pid':'','keyword': '武汉','pageIndex': page,'pageSize': '10'}
data=urllib.parse.urlencode(data).encode('utf8')
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
request=urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response=urllib.request.urlopen(request)
content=response.read().decode('utf8')
return content
def download(page,content):
with open('kfc_' + str(page) + '.json', 'w', encoding='utf8') as fp:
fp.write(content)
start_page=int(input('请输入起始页码:'))
end_page=int(input("请输入结束的页码:"))
for page in range(start_page,end_page+1):
request=creat_request(page) #使每一页都有 请求对象的定制
content=get_content(request) #获取响应的数据
download(page,content) #下载数据
异常
通过urllib发送请求的时候,有时会发送失败,这时候如果想让代码更加健壮,可以通过try-except进行捕获异常。
异常有两类:URLError / HTTPError
2.解析
解析,是为了获取网页中的部分源码。
2.1xpath

# xpath解析
from lxml import etree #先导入lxml.etree
tree=etree.parse('33.html') #1.解析本地文件,使用etree.parse()
# li_list = tree.xpath('//body//ul/li') #查找ul下面的li
# print(li_list)
# print(len(li_list)) #判断列表长度
# li_list = tree.xpath('//ul/li[@id]/text()') #查找所有有id属性的li标签;text()可获取标签中的内容
# print(li_list)
# li_list = tree.xpath('//ul/li[@id="l1"]/text()') #查找id为l1的li标签
# print(li_list)
# li = tree.xpath('//ul/li[@id="l1"]/@class') #查找id为l1的li标签的class的属性值
# print(li)
#查询id中包含l的li标签
li_list=tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list)
Requests库
Requests库的get( )方法
Requests库的7个主要方法:

Requests的get函数的完整使用方法:
Requests.get(url,params=None,**Kwargs)
| 参数 | 作用 |
|---|---|
| url | 拟获取页面的urI链接 |
| params | url中的额外参数,字典或字节流格式,可选 |
| **kwargs | 12 个控制访问的参数,可选 |
Requests库的2个重要对象:

Response对象的属性:

import requests
r=requests.get("http://www.baidu.com")
print(r.status_code)
#检查返回的response对象的状态:若为200,则可继续下一步,解析返回的内容;若为404或其他,则出错
爬取网页的通用代码框架
理解Requests库的异常:
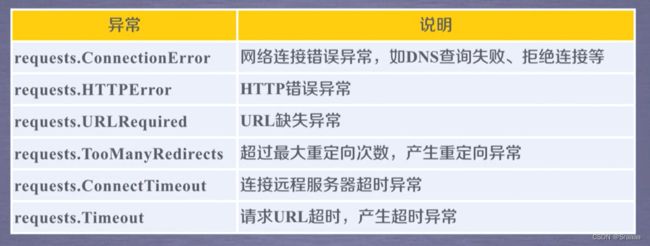
![]()
爬取网页的通用代码框架:
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status() #如果状态不是200,引发HTTPError异常
r.encoding=r.apparent_encoding #用apparent_encoding替代encoding,使得返回内容的解码是正确的
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
'''if __name__ == '__main__'的意思:
当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;
当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行'''
结果:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> 