数据仓库搭建
目录
- 1 数据仓库概念
-
- 1.1 什么是数据仓库
- 1.2 OLTP与OLAP
- 2 项目需求及架构设计
- 3 项目框架
- 4 框架版本选型
-
- 4.1 Hadoop版本综述
- 4.2 社区版与第三方发行版的比较
-
- 4.2.1.Apache社区版
- 4.2.2.第三方发行版(CDH/HDP/MapR)
- 4.3 第三方发行版的比较
- 4.4 版本选择
- 5 服务器选型
- 6 集群资源规划设计
- 7 测试集群服务器规划

想学习架构师构建流程请跳转:Java架构师系统架构设计
1 数据仓库概念
数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
简单的说:
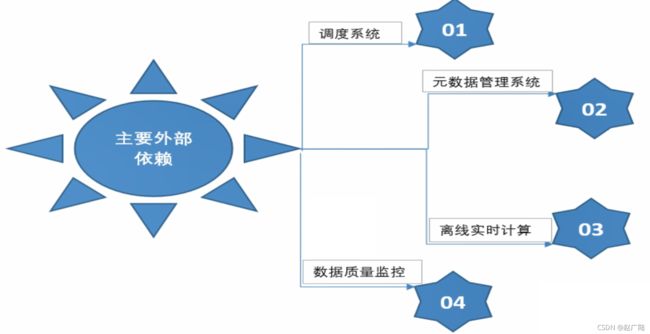
1.1 什么是数据仓库
■ “数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合
■ 我们可以把Hadoop和Spark看成是数据仓库的一种实现方式
■ 数据仓库就是一个数据库,一般只做select
■ 重要:掌握数据仓库搭建的过程
■ 数据仓库又是一种OLAP的应用系统
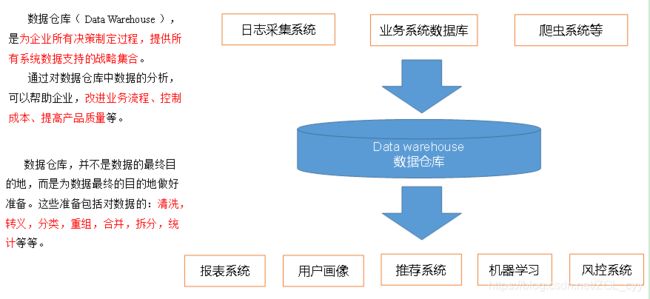
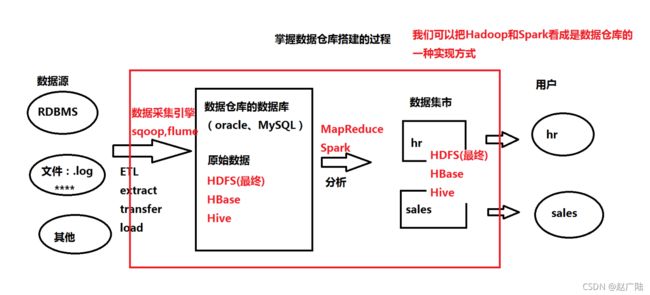
1.2 OLTP与OLAP
■ OLTP:online transaction processing
联机事务处理(Mysql增删改查)
■ OLAP:online analytic processing 联机分析处理
一般:不会修改(删除)数据
2 项目需求及架构设计
本次数仓业务流程主要分为两类,
- 一类是用户下单、提交订单、支付、退款这一条线,
- 另一类是我们收集用户的页面行为数据:用户搜索商品、添加购物车 、提交订单、支付订单 的日志数据,分析电商网站常见的PV,UV,GMV,
GMV (Gross Merchandise Volume):主要是指网站的成交金额,而这里的成交金额包括:付款金额和未付款。
PV(Page View)访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录1次,多次打开或刷新同一页面则浏览量累计。
UV(Unique Visitor)独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客。可以理解成访问某网站的电脑的数量。网站判断来访电脑的身份是通过来访电脑的cookies实现的。如果更换了IP后但不清除cookies,再访问相同网站,该网站的统计中UV数是不变的。如果用户不保存cookies访问、清除了cookies或者更换设备访问,计数会加1。00:00-24:00内相同的客户端多次访问只计为1个访客。
数仓模仿阿里巴巴双十一的大屏显示功能实现的互联网电商指标的离线分析,同时也模仿了阿里巴巴大数据平台上面数据仓库的设计思想和理念。大家通过学习这个项目,能够掌握以下三个核心技能:
1、数据仓库的概念和建设过程
2、离线数据仓库的功能、使用场景和常用的技术栈
3 项目框架
离线数仓:
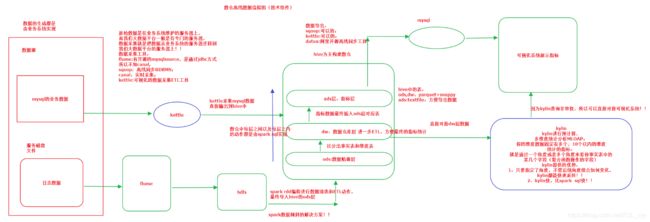
实时数仓:

4 框架版本选型
4.1 Hadoop版本综述
Apache Hadoop的开源协议决定了任何人可以对其进行修改,并作为开源或者商业版发布/销售。故而目前Hadoop发行版非常的多,有华为发行版(收费)、Intel发行版(收费)、Cloudera发行版CDH(免费)、Hortonworks版本HDP(免费),这些发行版都是基于Apache Hadoop衍生出来的。

4.2 社区版与第三方发行版的比较
4.2.1.Apache社区版
Apache Hadoop
优点:
完全开源免费
社区活跃
文档、资料详实
缺点:
版本管理比较混乱,各种版本层出不穷,很难选择,选择生态组件时需要大量考虑兼容性问题、版本匹配问题、组件冲突问题、编译问题等。
集群的部署安装配置复杂,需要编写大量配置文件,分发到每台节点,容易出错,效率低。
集群运维复杂,需要安装第三方软件辅助。
4.2.2.第三方发行版(CDH/HDP/MapR)
优点:
基于Apache协议,100%开源。
版本管理清晰,相比于Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch。
提供了部署、安装、配置工具,大大提高了集群部署的效率
运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
涉及到厂商锁定的问题。
4.3 第三方发行版的比较
Cloudera:最成型的发行版本,拥有最多的部署案例。提供强大的部署、管理和监控工具。
Hortonworks:不拥有任何私有(非开源)修改地使用了100%开源Apache Hadoop的唯一提供商。Hortonworks是第一家使用了Apache HCatalog的元数据服务特性的提供商。并且,它们的Stinger开创性地极大地优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Windows Server和Windows Azure在内的Microsft Windows平台上本地运行。

4.4 版本选择
当我们选择是否采用某个软件用于开源环境时,通常需要考虑:
(1)是否为开源软件,即是否免费。
(2) 是否有稳定版,这个一般软件官方网站会给出说明。
(3) 是否经实践验证,这个可通过检查是否有一些大点的公司已经在生产环境中使用知道。
(4) 是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。

5 服务器选型

6 集群资源规划设计

7 测试集群服务器规划
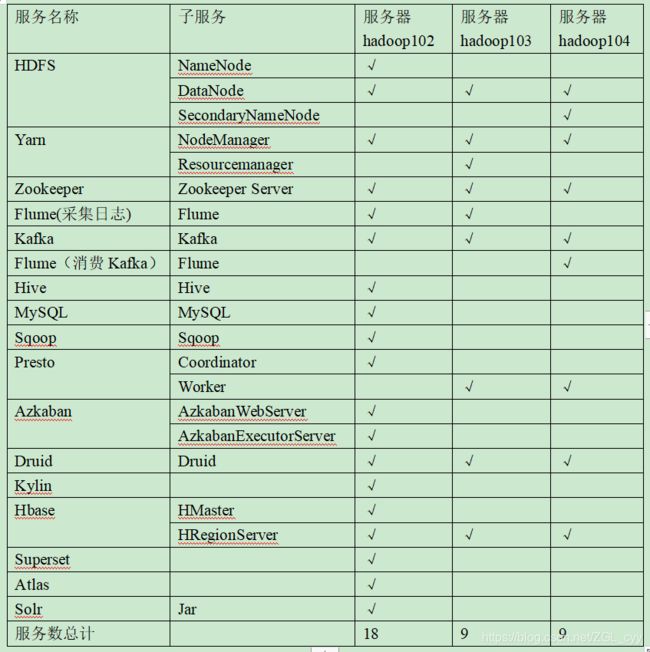
注意:相互之间的依赖关系需要在同一个服务器