一文彻底理解索引下推
了解索引下推吗?二级索引取出的数据是依次回表还是一次回表?索引下推是为了什么发明的?索引下推的流程是?正常使用二级索引的流程是?
看完这个文章你将知道上面的问题。
索引下推的概念
从MySQL5.6开始引入的一个特性,索引下推通过减少回表的次数来提高数据库的查询效率;
注意:索引下推是为了减少回表而发明的。
索引下推的产生一定围绕着回表,没有回表那就没必要产生索引下推,因为上面也说了索引下推的目的就是减少回表,而不是避免回表。(题外话:避免回表使用索引覆盖——建立覆盖索引)
索引下推的目的
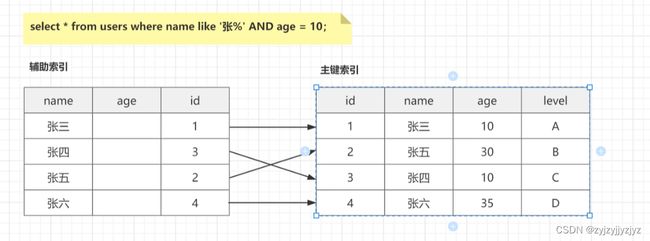


正常不会发生索引下推的情况的流程(二级索引等值查询或者覆盖索引避免回表)
情况1:
select * from table where name = 'zhang' and age = 10;
流程:二级索引根据最左匹配找到name=zhang的第一个记录,之后根据age对比该记录是否满足条件。满足则回表返回完整记录到server层,如果有别的不是二级索引上的条件(例如level=’A‘)再由server层进行过滤。不满足则找到第二个name=zhang的记录(直接通过链表去找),直到查找到符合条件的记录继续回表返回server层,直到找完。
情况2:
create index inx_naaal on table(name,age,level);
select * from table where name = '%zhang' and age = 10;
流程:
因为%在左面,所以用不到索引,但是是覆盖索引则可以避免回表,type=index。相当于在二级索引树上做全表扫描,一条一条的返回给server层。
没有索引下推(mysql5.6之前版本)的流程
情况:
select * from table where name like 'zh%' and age=10;
流程:
上面是个很经典会发生索引下推的情况,但是在5.6之前的版本没有索引下推。流程就是二级索引最左匹配原则找到符合zh开头的第一个记录回表返回完整记录给server层,再由server层通过age=10条件过滤这条记录。之后返回第二个,以此类推。
索引下推的流程
情况:
select * from table where name like 'zh%' and age=10;
流程:
同样的语句,有索引下推会是什么样的流程。流程就是二级索引最左匹配符合zh开头的记录通过id去主键索引回表,但是在回表的过程中发生索引下推判断本条记录的age是否等于10,等于去回表,不等于就不用回表,继续找二级索引zh开头的第二条记录,继续操作,直到找到一个符合age=10的记录,回表返回server层,如果有别的条件由server层过滤。
注意:以上三种情况二级索引都是(name,age)的联合索引。
实验
create table xiatui(
id int PRIMARY Key,
name varchar(10),
age varchar(10),
sex int,
key inx_naa(name,age)
)表中有一个二级索引
语句1:
explain
select * from xiatui where name like '%0' and age = '9802';因为%在前面所以不会走索引,当然如果不是select * ,会使用二级索引的index。
![]()
可以看到extra=using where。这个意思就是在mysql在server层中进行了条件过滤。

语句1补充:
create index inx_naaas on xiatui(name,age,sex);
explain
select * from xiatui where name like '%0' and age = '9802';![]()
覆盖索引避免回表。只要是不产生回表那就不可能发生索引下推,因为索引下推是在存储引擎层,在二级索引回表的过程中发生的。
语句2:
explain
select * from xiatui where name like '0%' and age = '9802';![]() extra=using index condition 发生了索引下推。
extra=using index condition 发生了索引下推。
上面是一个经典的会产生索引下推的情况。若是where后有其他条件会影响索引下推吗,答案是不影响,无非是会在server层多一步过滤。
explain
select * from xiatui where name like '0%' and age = '9802' and sex =0;![]()
可以看到extra=using where说明在server层发生了根据非索引列条件的过滤,using index condition说明发生了索引下推。
索引下推和无索引下推执行时间的对比
set profiling = 1;
select /*+ no_icp(xiatui) */ * from xiatui where name like '0%' and age = '9803' and sex =0;
explain
select /*+ no_icp(xiatui) */ * from xiatui where name like '0%' and age = '9802' and sex =0;
select * from xiatui where name like '0%' and age = '9803' and sex =0;
explain
select * from xiatui where name like '0%' and age = '9802' and sex =0;
show profiles;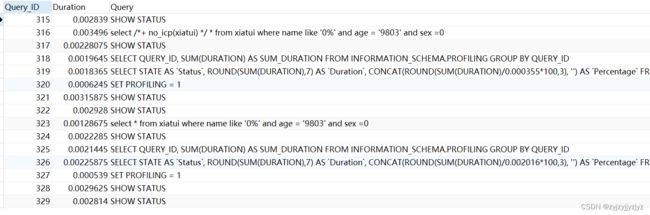
id为316和323的对比,可以看出索引下推的执行时间比无索引下推的执行时间短很多。
总结:
理解上面的知识后就可以回答开始的问题。
二级索引取出的数据是依次回表还是一次回表?答:依次回表。
索引下推是为了什么发明的?答:减少回表,而不是避免回表(避免回表用覆盖索引)