大数据学习-离线数仓项目实战笔记(上)
1. 前置
1.1. 软件版本
| 产品 | 版本 |
|---|---|
| Hadoop | 2.9.2 |
| Hive | 2.3.7 |
| Flume | 1.9 |
| DataX | 3.0 |
| Airflow | 1.10 |
| Atlas | 1.2.0 |
| Griffin | 0.4.0 |
| Impala | impala-2.3.0-cdh5.5.0 |
| MySQL | 5.7 |
1.2. 软件安装分布情况
| 服务器 | linux121 | linux122 | linux123 |
|---|---|---|---|
| Hadoop | √ namenode | √ | √ seconderynamenode,resourcemanager |
| Hive | √ | ||
| Flume | √ | ||
| MySQL | √ |
1.3. 数据仓库命名规范
1 数据库命名
命名规则:数仓对应分层
命名示例:ods / dwd / dws/ dim / temp / ads
2 数仓各层对应数据库
ods层 -> ods_{业务线|业务项目}
dw层 -> dwd_{业务线|业务项目} + dws_{业务线|业务项目}
dim层 -> dim_维表
ads层 -> ads_{业务线|业务项目} (统计指标等)
临时数据 -> temp_{业务线|业务项目}
备注:本项目未采用
3 表命名(数据库表命名规则)
* ODS层:
命名规则:ods_{业务线|业务项目}_[数据来源类型]_{业务}
* DWD层:
命名规则:dwd_{业务线|业务项目}_{主题域}_{子业务}
* DWS层:
命名规则:dws_{业务线|业务项目}_{主题域}_{汇总相关粒度}_{汇总时间周期}
* ADS层:
命名规则:ads_{业务线|业务项目}_{统计业务}_{报表form|热门排序topN}
* DIM层:
命名规则:dim_{业务线|业务项目|pub公共}_{维度}
1.4. 目录结构
/
- data
- dw
- conf 存放配置文件
- jars 存放jar包
- logs 存放日志文件
- start 存放用户启动日志
- event 存放用户行为日志
- script 存放脚本
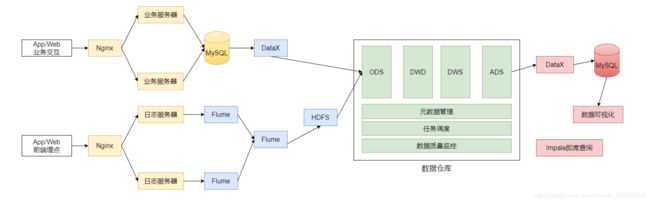
1.5. 系统架构逻辑
1.6. 在Hive中创建每一层的数据库
在linux121、linux123服务器启动hive metastore服务
nohup hive --service metastore &
启动hive
[root@linux123 logs]# hive
执行命令创建数据库
create database if not exists ods;
create database if not exists dwd;
create database if not exists dws;
create database if not exists ads;
create database if not exists dim;
create database if not exists tmp;
2. 会员活跃度
2.1. 计算指标
- 新增会员:每日新增的会员数,以设备id来计数
- 活跃会员:每日,每周,每月的活跃会员,只要有登录一次就算是活跃会员
- 会员留存:1日、2日、3日会员留存数;1日、2日、3日会员留存率
2.2. 读取日志到HDFS
2.2.1. 读取start日志
11:56:07,937 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback-test.xml]
11:56:07,937 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback.groovy]
11:56:07,937 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Found resource [logback.xml] at [jar:file:/data/lagoudw/jars/data-generator-1.1-SNAPSHOT-jar-with-dependencies.jar!/logback.xml]
11:56:07,947 |-INFO in ch.qos.logback.core.joran.spi.ConfigurationWatchList@5c0369c4 - URL [jar:file:/data/lagoudw/jars/data-generator-1.1-SNAPSHOT-jar-with-dependencies.jar!/logback.xml] is not of type file
11:56:07,984 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - debug attribute not set
11:56:07,986 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.ConsoleAppender]
11:56:07,988 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [STDOUT]
11:56:08,027 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.rolling.RollingFileAppender]
11:56:08,030 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [FILE]
11:56:08,036 |-INFO in c.q.l.core.rolling.TimeBasedRollingPolicy@736709391 - No compression will be used
[root@linux123 start]# head -n 100 start0721.small.log
11:56:07,937 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback-test.xml]
11:56:07,937 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Could NOT find resource [logback.groovy]
11:56:07,937 |-INFO in ch.qos.logback.classic.LoggerContext[default] - Found resource [logback.xml] at [jar:file:/data/lagoudw/jars/data-generator-1.1-SNAPSHOT-jar-with-dependencies.jar!/logback.xml]
11:56:07,947 |-INFO in ch.qos.logback.core.joran.spi.ConfigurationWatchList@5c0369c4 - URL [jar:file:/data/lagoudw/jars/data-generator-1.1-SNAPSHOT-jar-with-dependencies.jar!/logback.xml] is not of type file
11:56:07,984 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - debug attribute not set
11:56:07,986 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.ConsoleAppender]
11:56:07,988 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [STDOUT]
11:56:08,027 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.core.rolling.RollingFileAppender]
11:56:08,030 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [FILE]
11:56:08,036 |-INFO in c.q.l.core.rolling.TimeBasedRollingPolicy@736709391 - No compression will be used
11:56:08,037 |-INFO in c.q.l.core.rolling.TimeBasedRollingPolicy@736709391 - Will use the pattern /tmp/logs//app-%d{yyyy-MM-dd}.log for the active file
11:56:08,039 |-INFO in c.q.l.core.rolling.DefaultTimeBasedFileNamingAndTriggeringPolicy - The date pattern is 'yyyy-MM-dd' from file name pattern '/tmp/logs//app-%d{yyyy-MM-dd}.log'.
11:56:08,039 |-INFO in c.q.l.core.rolling.DefaultTimeBasedFileNamingAndTriggeringPolicy - Roll-over at midnight.
11:56:08,042 |-INFO in c.q.l.core.rolling.DefaultTimeBasedFileNamingAndTriggeringPolicy - Setting initial period to Thu Aug 20 11:56:08 CST 2020
11:56:08,046 |-INFO in ch.qos.logback.core.rolling.RollingFileAppender[FILE] - Active log file name: /tmp/logs//app-2020-08-20.log
11:56:08,046 |-INFO in ch.qos.logback.core.rolling.RollingFileAppender[FILE] - File property is set to [null]
11:56:08,046 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate appender of type [ch.qos.logback.classic.AsyncAppender]
11:56:08,048 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - Naming appender as [ASYNC_FILE]
11:56:08,049 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [FILE] to ch.qos.logback.classic.AsyncAppender[ASYNC_FILE]
11:56:08,049 |-INFO in ch.qos.logback.classic.AsyncAppender[ASYNC_FILE] - Attaching appender named [FILE] to AsyncAppender.
11:56:08,049 |-INFO in ch.qos.logback.classic.AsyncAppender[ASYNC_FILE] - Setting discardingThreshold to 0
11:56:08,049 |-INFO in ch.qos.logback.classic.joran.action.RootLoggerAction - Setting level of ROOT logger to INFO
11:56:08,049 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [STDOUT] to Logger[ROOT]
11:56:08,049 |-INFO in ch.qos.logback.core.joran.action.AppenderRefAction - Attaching appender named [ASYNC_FILE] to Logger[ROOT]
11:56:08,050 |-ERROR in ch.qos.logback.core.joran.action.AppenderRefAction - Could not find an appender named [error]. Did you define it below instead of above in the configuration file?
11:56:08,050 |-ERROR in ch.qos.logback.core.joran.action.AppenderRefAction - See http://logback.qos.ch/codes.html#appender_order for more details.
11:56:08,050 |-INFO in ch.qos.logback.classic.joran.action.ConfigurationAction - End of configuration.
11:56:08,050 |-INFO in ch.qos.logback.classic.joran.JoranConfigurator@d70c109 - Registering current configuration as safe fallback point
2020-08-20 11:56:08.211 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"2","action":"0","error_code":"0"},"time":1595288248066},"attr":{"area":"三门峡","uid":"2F10092A1","app_v":"1.1.0","event_type":"common","device_id":"1FB872-9A1001","os_type":"0.97","channel":"WM","language":"chinese","brand":"xiaomi-3"}}
2020-08-20 11:56:08.213 [main] INFO com.lagou.ecommerce.AppStart - {"app_active":{"name":"app_active","json":{"entry":"1","action":"1","error_code":"0"},"time":1595263841552},"attr":{"area":"济宁","uid":"2F10092A2","app_v":"1.1.16","event_type":"common","device_id":"1FB872-9A1002","os_type":"1.9","channel":"YR","language":"chinese","brand":"Huawei-8"}}
除了后面的格式统一的日志部分外,还有开头一些不同格式的需要过滤掉。
- 读取日志文件存储到HDFS
2.2.2.1. 设置taildir source
a1.sources.r1.type=TAILDIR
# 配置检查点文件的位置,检查点文件会以json格式保存已经读取的文件位置。用来解决断点续传的问题。
a1.sources.r1.positionFile=/data/dw/conf/startlog_position.json
# 配置监控路径,多个路径使用空格分隔
a1.sources.r1.filegroups=f1
# 配置具体的监控文件路径,使用绝对路径,支持正则表达式匹配
a1.sources.r1.filegroups.f1=/data/dw/logs/start/.*log
2.2.2.2. 设置HDFS sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix=startlog.
# 配置文件滚动方式(文件大小32M),默认1024字节滚动一次
a1.sinks.k1.hdfs.rollSize=33554432
# 基于event的数量滚动,默认10个event滚动一次
a1.sinks.k1.hdfs.rollCount=0
# 基于时间的滚动方式,默认30秒滚动一次
a1.sinks.k1.hdfs.rollInterval=0
# 基于文件空闲时间滚动,默认0,表示禁用
a1.sinks.k1.hdfs.idleTimeout=0
# 默认值与hdfs副本数一致。设为1是为了不让Flume感知到hdfs的块复制,这样其他的滚动方式配置才不会受影响
a1.sinks.k1.hdfs.minBlockReplicas=1
# 向hdsf上刷新event的个数
a1.sinks.k1.hdfs.batchSize=100
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp=true
2.2.2.3. agent配置
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# taildir source
a1.sources.r1.type=TAILDIR
# 配置检查点文件的位置,检查点文件会以json格式保存已经读取的文件位置。用来解决断点续传的问题。
a1.sources.r1.positionFile=/data/dw/conf/startlog_position.json
# 配置监控路径,多个路径使用空格分隔
a1.sources.r1.filegroups=f1
# 配置具体的监控文件路径,使用绝对路径,支持正则表达式匹配
a1.sources.r1.filegroups.f1=/data/dw/logs/start/.*log
# memory channel
a1.channels.c1.type=memory
# The maximum number of events stored in the channel
a1.channels.c1.capatity=100000
# The maximum number of events the channel will take from a source or give to a sink per transaction
a1.channels.c1.transactionCapatity=2000
# hdfs sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/user/data/logs/start/%Y-%m-%d/
a1.sinks.k1.hdfs.filePrefix=startlog.
# 配置文件滚动方式(文件大小32M),默认1024字节滚动一次
a1.sinks.k1.hdfs.rollSize=33554432
# 基于event的数量滚动,默认10个event滚动一次
a1.sinks.k1.hdfs.rollCount=0
# 基于时间的滚动方式,默认30秒滚动一次
a1.sinks.k1.hdfs.rollInterval=0
# 基于文件空闲时间滚动,默认0,表示禁用
a1.sinks.k1.hdfs.idleTimeout=0
# 默认值与hdfs副本数一致。设为1是为了不让Flume感知到hdfs的块复制,这样其他的滚动方式配置才不会受影响
a1.sinks.k1.hdfs.minBlockReplicas=1
# 向hdsf上刷新event的个数
a1.sinks.k1.hdfs.batchSize=100
# 使用本地时间
a1.sinks.k1.hdfs.useLocalTimeStamp=true
# Bind the source and channel to the channel,
# 注意sources的channels有s,而sinks的没有s
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2.2.2.4. 测试
-
启动hdfs
[root@linux121 hadoop-2.9.2]$ sbin/start-dfs.sh [root@linux122 hadoop-2.9.2]$ sbin/start-yarn.sh -
在linux123上,创建配置flume配置文件/data/dw/conf/flume-log2hdfs.conf
[root@linux123 ~]# cd /data/dw/ [root@linux123 conf]# vim flume-log2hdfs.conf -
启动flume agent
flume-ng agent --conf-file /data/dw/conf/flume-log2hdfs.conf -name a1 -Dflume.root.logger=INFO,console
2.2.2.5. 优化
执行ps -ef | grep flume
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5TE3dRG3-1608729820980)(etc/image-20201216213722404.png)]](http://img.e-com-net.com/image/info8/678a71230f2d417eb9eb69b63991360a.jpg)
会发现启动flume的时候只分配了20M的内存给flume jvm堆,这可能会引发java.lang.OutOfMemoryError: GC overhead limit exceeded的错误
因此可以在$FLUME_HOME/conf/flume-env.sh中增加以下内容,来增加分配的内存,-Xms和-Xmx最好一致,减少内存抖动带来的性能影响
export JAVA_OPTS="-Xms500m -Xmx500m" -Dcom.sun.management.jmxremote
使用以下命令启动flume来使配置文件生效
flume-ng agent --conf $FLUME_HOME/conf --conf-file /data/dw/conf/flume-log2hdfs.conf -name a1 -Dflume.root.logger=INFO,console
再次查看启动时分配的内存大小,此时变成了500M

2.2.2.6. 自定义拦截器
目前存在的问题是日志文件存放到hdfs时存放的目录是当天的时间而非日志中的时间,这是因为在flume-log2dhfs.conf文件中使用了系统时间。所以这里需要自定义拦截器来获取日志中的具体时间

-
日志文件json部分分析
{ "app_active":{ "name":"app_active", "json":{ "entry":"2", "action":"1", "error_code":"0" }, "time":1595461782293 }, "attr":{ "area":"文登", "uid":"2F10092A879999", "app_v":"1.1.12", "event_type":"common", "device_id":"1FB872-9A100879999", "os_type":"0.47", "channel":"RA", "language":"chinese", "brand":"xiaomi-1" } }可以看到
app_active.time有具体的日志产生信息 -
定义拦截器原理
- 自定义拦截器要集成Flume的Interceptor
- Event分为header和body(body就是数据)
- 获取header和body
- 从body中获取time,并将时间戳转换成yyyy-MM-dd格式的时间
- 将转换后的时间放到header中
-
自定义拦截器的实现步骤
- 获取event的header
- 获取event的body
- 解析body获取json串
- 解析json串获取time
- 转换time从时间戳变成"yyyy-MM-dd"的字符串
- 将转换后的字符串放到header中
- 返回event
-
代码实现
-
maven依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0modelVersion> <groupId>com.catkeepergroupId> <artifactId>flume-interceptorsartifactId> <version>1.0-SNAPSHOTversion> <properties> <project.build.sourceEncoding>UTF8project.build.sourceEncoding> properties> <dependencies> <dependency> <groupId>org.apache.flumegroupId> <artifactId>flume-ng-coreartifactId> <version>1.9.0version> <scope>providedscope> dependency> <dependency> <groupId>com.alibabagroupId> <artifactId>fastjsonartifactId> <version>1.1.23version> dependency> <dependency> <groupId>junitgroupId> <artifactId>junitartifactId> <version>4.13version> <scope>testscope> dependency> dependencies> <build> <plugins> <plugin> <artifactId>maven-compiler-pluginartifactId> <version>2.3.2version> <configuration> <source>1.8source> <target>1.8target> configuration> plugin> <plugin> <artifactId>maven-assembly-pluginartifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependenciesdescriptorRef> descriptorRefs> configuration> <executions> <execution> <id>make-assemblyid> <phase>packagephase> <goals> <goal>singlegoal> goals> execution> executions> plugin> plugins> build> project> -
拦截器代码
package com.catkeeper.flume.interceptors; import com.alibaba.fastjson.JSON; import com.alibaba.fastjson.JSONObject; import com.google.common.base.Strings; import com.google.common.collect.Lists; import org.apache.flume.Context; import org.apache.flume.Event; import org.apache.flume.interceptor.Interceptor; import java.time.Instant; import java.time.LocalDateTime; import java.time.ZoneId; import java.time.format.DateTimeFormatter; import java.util.ArrayList; import java.util.List; import java.util.Map; /** * CustomerInterceptor * * @author chenhang * @date 2020/12/16 */ public class CustomerInterceptor implements Interceptor { private DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd"); @Override public void initialize() { } @Override public Event intercept(Event event) { Map<String, String> headers = event.getHeaders(); byte[] bodyBytes = event.getBody(); String body = new String(bodyBytes); ArrayList<String> bodyList = Lists.newArrayList(body.split("\\s+")); try { String jsonStr = bodyList.get(6); if (Strings.isNullOrEmpty(jsonStr)) { return null; } JSONObject bodyJsonObject = JSON.parseObject(jsonStr); JSONObject appActiveJsonObject = bodyJsonObject.getJSONObject("app_active"); String time = appActiveJsonObject.getString("time"); String date = dateTimeFormatter.format( LocalDateTime.ofInstant( Instant.ofEpochMilli(Long.parseLong(time)), ZoneId.systemDefault() ) ); headers.put("logTime", date); } catch (Exception e) { headers.put("logTime", "unknown"); } return event; } @Override public List<Event> intercept(List<Event> list) { List<Event> result = new ArrayList<>(); list.forEach(event -> result.add(intercept(event))); return result; } @Override public void close() { } public static class Builder implements Interceptor.Builder { @Override public Interceptor build() { return new CustomerInterceptor(); } @Override public void configure(Context context) { } } } -
打包放到$FLUME_HOME/lib目录下
-
在flume配置文件中配置拦截器以及目录
a1.sources=r1 a1.channels=c1 a1.sinks=k1 # taildir source a1.sources.r1.type=TAILDIR # 配置检查点文件的位置,检查点文件会以json格式保存已经读取的文件位置。用来解决断点续传的问题。 a1.sources.r1.positionFile=/data/dw/conf/startlog_position.json # 配置监控路径,多个路径使用空格分隔 a1.sources.r1.filegroups=f1 # 配置具体的监控文件路径,使用绝对路径,支持正则表达式匹配 a1.sources.r1.filegroups.f1=/data/dw/logs/start/.*log # 配置拦截器 a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.type.i1=com.catkeeper.flume.interceptors.CustomerInterceptors$Builder # memory channel a1.channels.c1.type=memory # The maximum number of events stored in the channel a1.channels.c1.capatity=100000 # The maximum number of events the channel will take from a source or give to a sink per transaction a1.channels.c1.transactionCapatity=2000 # hdfs sink a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/user/data/logs/start/dt=%{logTime}/ a1.sinks.k1.hdfs.filePrefix=startlog # 配置文件滚动方式(文件大小32M),默认1024字节滚动一次 a1.sinks.k1.hdfs.rollSize=33554432 # 基于event的数量滚动,默认10个event滚动一次 a1.sinks.k1.hdfs.rollCount=0 # 基于时间的滚动方式,默认30秒滚动一次 a1.sinks.k1.hdfs.rollInterval=0 # 基于文件空闲时间滚动,默认0,表示禁用 a1.sinks.k1.hdfs.idleTimeout=0 # 默认值与hdfs副本数一致。设为1是为了不让Flume感知到hdfs的块复制,这样其他的滚动方式配置才不会受影响 a1.sinks.k1.hdfs.minBlockReplicas=1 # 向hdsf上刷新event的个数 a1.sinks.k1.hdfs.batchSize=100 # 使用本地时间 # a1.sinks.k1.hdfs.useLocalTimeStamp=true # Bind the source and channel to the channel, # 注意sources的channels有s,而sinks的没有s a1.sources.r1.channels=c1 a1.sinks.k1.channel=c1 -
测试,启动flume,复制日志文件到/data/dw/logs/start目录下,检查hdfs上的文件
-
2.2.2. 采集event日志
2.2.2.1. 日志格式分析
{
"lagou_event":[
{
"name":"notification",
"json":{
"action":"3",
"type":"3"
},
"time":1595279760340
},
{
"name":"ad",
"json":{
"duration":"17",
"ad_action":"0",
"shop_id":"1",
"event_type":"ad",
"ad_type":"2",
"show_style":"1",
"product_id":"21",
"place":"placecampaign3_right",
"sort":"7"
},
"time":1595286266626
}
],
"attr":{
"area":"玉溪",
"uid":"2F10092A19999",
"app_v":"1.1.7",
"event_type":"common",
"device_id":"1FB872-9A10019999",
"os_type":"6.0.2",
"channel":"EZ",
"language":"chinese",
"brand":"iphone-3"
}
}
事件日志中不同的用户操作有着不同的time,但是time不会相差太久,基本上都是在同一天内,因此可以就以第一条操作记录的time为准。
2.2.2.2. agent配置
- 配置监控路径为start和event的。
a1.sources.r1.filegroups - 配置event日志的具体路径。
a1.sources.r1.filegroups.f2 - 配置HDFS上的存储路径。
a1.sinks.k1.hdfs.path - 根据监控到的不同路径下的文件,给event的headers中添加不同的logType
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# taildir source
a1.sources.r1.type=TAILDIR
# 配置检查点文件的位置,检查点文件会以json格式保存已经读取的文件位置。用来解决断点续传的问题。
a1.sources.r1.positionFile=/data/dw/conf/startlog_position.json
# 配置监控路径,多个路径使用空格分隔
a1.sources.r1.filegroups=f1 f2
# 配置具体的监控文件路径,使用绝对路径,支持正则表达式匹配
a1.sources.r1.filegroups.f1=/data/dw/logs/start/.*log
a1.sources.r1.headers.f1.logType=start
a1.sources.r1.filegroups.f2=/data/dw/logs/event/.*log
a1.sources.r1.headers.f2.logType=event
# 配置拦截器
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.type.i1=com.catkeeper.flume.interceptors.CustomerInterceptors$Builder
# memory channel
a1.channels.c1.type=memory
# The maximum number of events stored in the channel
a1.channels.c1.capatity=100000
# The maximum number of events the channel will take from a source or give to a sink per transaction
a1.channels.c1.transactionCapatity=2000
# hdfs sink
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=/user/data/logs/%{logType}/dt=%{logTime}/
a1.sinks.k1.hdfs.filePrefix=startlog
# 配置文件滚动方式(文件大小32M),默认1024字节滚动一次
a1.sinks.k1.hdfs.rollSize=33554432
# 基于event的数量滚动,默认10个event滚动一次
a1.sinks.k1.hdfs.rollCount=0
# 基于时间的滚动方式,默认30秒滚动一次
a1.sinks.k1.hdfs.rollInterval=0
# 基于文件空闲时间滚动,默认0,表示禁用
a1.sinks.k1.hdfs.idleTimeout=0
# 默认值与hdfs副本数一致。设为1是为了不让Flume感知到hdfs的块复制,这样其他的滚动方式配置才不会受影响
a1.sinks.k1.hdfs.minBlockReplicas=1
# 向hdsf上刷新event的个数
a1.sinks.k1.hdfs.batchSize=100
# 使用本地时间
# a1.sinks.k1.hdfs.useLocalTimeStamp=true
# Bind the source and channel to the channel,
# 注意sources的channels有s,而sinks的没有s
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
2.2.2.3. 更改拦截器
- 因为在配置文件中给不同监控目录下的文件设置了一个logType以区分日志类型,所以在代码中拿到logType以进行不同的操作
- 如果logType是event的话,取到第一个事件的time放入到headers中。
package com.catkeeper.flume.interceptors;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.google.common.base.Charsets;
import com.google.common.collect.Lists;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* CustomerInterceptor
*
* @author chenhang
* @date 2020/12/16
*/
public class CustomerInterceptor implements Interceptor {
private DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String logType = headers.getOrDefault("logType", "");
byte[] bodyBytes = event.getBody();
String body = new String(bodyBytes, Charsets.UTF_8);
ArrayList<String> bodyList = Lists.newArrayList(body.split("\\s+"));
try {
String jsonStr = bodyList.get(6);
JSONObject bodyJsonObject = JSON.parseObject(jsonStr);
String time = "";
if ("start".equals(logType)) {
JSONObject appActiveJsonObject = bodyJsonObject.getJSONObject("app_active");
time = appActiveJsonObject.getString("time");
} else if ("event".equals(logType)) {
JSONArray lagouEvent = bodyJsonObject.getJSONArray("lagou_event");
if (!lagouEvent.isEmpty()) {
time = lagouEvent.getJSONObject(0).getString("time");
}
}
String date = dateTimeFormatter.format(
LocalDateTime.ofInstant(
Instant.ofEpochMilli(Long.parseLong(time)), ZoneId.systemDefault()
)
);
headers.put("logTime", date);
} catch (Exception e) {
headers.put("logTime", "unknown");
}
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
List<Event> result = new ArrayList<>();
list.forEach(event -> result.add(intercept(event)));
return result;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new CustomerInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
2.2.2.4. 执行
后台启动flume
nohup flume-ng agent --conf /opt/apps/flume-1.9/conf --conf-file /data/lagoudw/conf/flume-log2hdfs3.conf -name a1 -Dflume.root.logger=INFO,LOGFILE > /dev/null 2>&1 &
将event日志文件复制到/data/dw/logs/event/目录下,查看hdfs
![]()
2.3. ODS层的建表以及数据加载
前面一步已经实现了把日志采集到HDFS上,现在创建ODS层,将HDFS上的日志信息存储到ODS层中
ODS层中的数据与源数据的格式基本相同
2.3.1. 创建ods.ods_start_log表
use ODS;
create external table ods.ods_start_log(
`str` string)
comment '用户启动日志信息'
partitioned by (`dt` string)
location '/user/data/logs/start';
-- 加载数据(用以测试)
alter table ods.ods_start_log add partition(dt='2020-07-21');
遇到的问题
加载数据之后查看表ods.ods_start_log,发现乱码
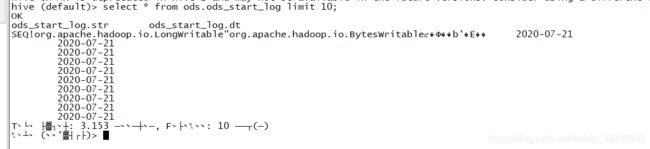
上网查询之后发现是少了一项配置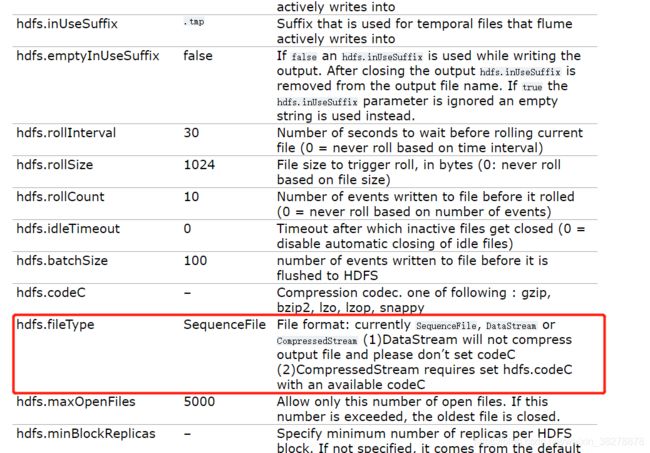
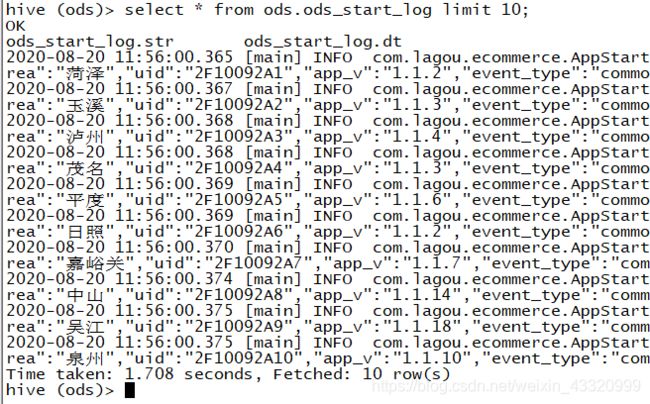
所以需要在配置文件中加上一行a1.sinks.k1.hdfs.fileType=DataStream
再次查询,得到预期的结果
2.3.2. 使用脚本加载数据
前面一步直接在hive中加载数据,但是问题是不能每天都去手动在hive中执行一遍
因此创建脚本/data/dw/script/member_active/ods_load_log.sh,供以后调度
#! /bin/bash
APP=ODS
hive=/opt/lagou/servers/hive-2.3.7/bin/hive
# 输入日期,如果未输入日期则取昨天的日期
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" + %F`
fi
# 定义要执行的SQL
sql="alter table "$APP".ods_start_log add partition(dt='$do_date');"
$hive -e "$sql"
执行sh ods_load_log.sh '2020-07-21'查看表
2.4. JSON数据处理
数据文件中每行必须是一个完整的 json 串,一个 json串不能跨越多行。
Hive 处理json数据总体来说有三个办法:
- 使用内建的函数get_json_object、json_tuple
- 使用自定义的UDF
- 第三方的SerDe
2.4.1. 使用内建函数处理
-
get_json_object(string json_string, string path)
返回值:String
说明:解析json字符串json_string,返回path指定的内容;如果输入的json字符串 无效,那么返回NUll;函数每次只能返回一个数据项;
-
json_tuple(jsonStr, k1, k2, …)
返回值:所有的输入参数、输出参数都是String;
说明:参数为一组键k1,k2,。。。。。和json字符串,返回值的元组。该方法比 get_json_object高效,因此可以在一次调用中输入多个键;
配合explode,使用explode将Hive一行中复杂的 array 或 map 结构拆分成多行。
测试数据:/data/dw/data/weibo.json
user1;18;male;{"id": 1,"ids": [101,102,103],"total_number": 3}
user2;20;female;{"id": 2,"ids": [201,202,203,204],"total_number":4}
user3;23;male;{"id": 3,"ids":[301,302,303,304,305],"total_number": 5}
user4;17;male;{"id": 4,"ids": [401,402,403,304],"total_number":5}
user5;35;female;{"id": 5,"ids": [501,502,503],"total_number": 3}
建表加载数据
CREATE TABLE IF NOT EXISTS tmp.jsont1(
username string,
age int,
sex string,
json string
)
row format delimited fields terminated by ';';
load data local inpath '/data/dw/data/weibo.json' overwrite into table jsont1;
测试
-- 使用get_json_object获取单层值
select username, age, sex, get_json_object(json, "$.id") id, get_json_object(json, "$.ids") ids, get_json_object(json, "$.total_number") num
from jsont1;
-- 使用get_json_object get数组
select username, age, sex, get_json_object(json, "$.id") id,
get_json_object(json, "$.ids[0]") ids0,
get_json_object(json, "$.ids[1]") ids1,
get_json_object(json, "$.ids[2]") ids2,
get_json_object(json, "$.ids[3]") ids3,
get_json_object(json, "$.total_number") num
from jsont1;
-- 使用json_tuple 一次处理多个字段
select json_tuple(json, 'id', 'ids', 'total_number') from jsont1;
-- 有语法错误
select username, age, sex, json_tuple(json, 'id', 'ids', 'total_number') from jsont1;
-- 应该使用lateral view来查看
select username, age, sex, id, ids, total_number
from jsont1
lateral view json_tuple(json, 'id', 'ids', 'total_number') t1 as id, ids, total_number;
-- 使用explode展开
-- 1. 去除“[]”
select regexp_replace("[101, 102, 103]", "\\[|\\]", "");
-- 2. 将字符串转换成数组
select split(regexp_replace("[101, 102, 103]", "\\[|\\]", ""), ",");
-- 3. 使用explode展开
with tmp as (
select username, age, sex, id, ids, total_number
from jsont1
lateral view json_tuple(json, 'id', 'ids', 'total_number') t1 as id, ids, total_number
)
select username, age, sex, id, ids1, total_number
from tmp
lateral view explode(split(regexp_replace(ids, "\\[|\\]", ""), ",")) t1 as ids1;
2.4.2. 使用UDF处理
2.4.2.1. pom依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.catkeepergroupId>
<artifactId>udfartifactId>
<version>1.0-SNAPSHOTversion>
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>2.3.7version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.1.23version>
dependency>
dependencies>
<repositories>
<repository>
<id>pentaho-omniid>
<url>https://repository.pentaho.org/content/groups/omniurl>
<releases>
<enabled>trueenabled>
releases>
<snapshots>
<enabled>falseenabled>
snapshots>
repository>
repositories>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-pluginartifactId>
<version>2.3.2version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
plugins>
build>
project>
2.4.2.2. UDF代码
package com.catkeeper.hive.udfs;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.parquet.Strings;
import java.util.ArrayList;
import java.util.List;
/**
* ParseJsonArray
*
* @author chenhang
* @date 2020/12/21
*/
public class ParseJsonArray extends UDF {
public List<String> evaluate(final String jsonStr, String arrKey) {
if (Strings.isNullOrEmpty(jsonStr)) {
return null;
}
JSONObject jsonObject = JSON.parseObject(jsonStr);
JSONArray jsonArray = jsonObject.getJSONArray(arrKey);
ArrayList<String> strings = new ArrayList<>();
jsonArray.forEach(json -> strings.add(json.toString()));
return strings;
}
}
2.4.2.3. 使用自定义UDF函数
-
上传jar包到/data/dw/jars/目录下
-
在hive命令中添加开发的jar包
add jar /data/dw/jars/udf-1.0-SNAPSHOT-jar-with-dependencies.jar; -
创建临时函数,指定类名一定要使用完整路径
create temporary function my_json_array as 'com.catkeeper.hive.udfs.ParseJsonArray'; -
执行语句
select username, age, sex, id, ids1, num from jsont1 lateral view explode(my_json_array(json, 'ids')) t1 as ids1 lateral view json_tuple(json, 'id', 'total_number') t1 as id, num;
2.4.2.4. 使用SerDe
Hive本身自带了几个内置的SerDe,还有其他一些第三方的SerDe可供选择。
create table t11(id string)
stored as parquet;
create table t12(id string)
stored as ORC;
desc formatted t11;
desc formatted t12;
- LazySimpleSerDe(默认的SerDe)
- ParquetHiveSerDe
- OrcSerde
对于纯 json 格式的数据,可以使用 JsonSerDe 来处理
{"id": 1,"ids": [101,102,103],"total_number": 3}
{"id": 2,"ids": [201,202,203,204],"total_number": 4}
{"id": 3,"ids": [301,302,303,304,305],"total_number": 5}
{"id": 4,"ids": [401,402,403,304],"total_number": 5}
{"id": 5,"ids": [501,502,503],"total_number": 3}
id int,
ids array<string>,
total_number int
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe';
load data local inpath '/data/dw/data/json2.dat' into table
jsont2;
2.5. DWD层建表和数据加载
主要任务:ODS -> DWD,json数据解析,丢弃无用数据,保留有效信息,并将数据展开,形成每日启动明细表
2.5.1. 创建DWD层表
{
"app_active":{
"name":"app_active",
"json":{
"entry":"2",
"action":"1",
"error_code":"0"
},
"time":1595461782293
},
"attr":{
"area":"文登",
"uid":"2F10092A879999",
"app_v":"1.1.12",
"event_type":"common",
"device_id":"1FB872-9A100879999",
"os_type":"0.47",
"channel":"RA",
"language":"chinese",
"brand":"xiaomi-1"
}
}
use DWD;
drop table if exists dwd.dwd_start_log;
create table dwd.dwd_start_log (
`device_id` string,
`area` string,
`uid` string,
`app_v` string,
`event_type` string,
`os_type` string,
`channel` string,
`language` string,
`brand` string,
`entry` string,
`action` string,
`error_code` string
)
partitioned by (dt string)
stored as parquet;
2.5.2. 加载DWD层数据
创建脚本/data/dw/script/member_active/dwd_load_start.sh
#! /bin/bash
# 可以输入日期,如果没有输入则是前一天
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 定义要执行的sql
sql="
with tmp as(
select split(str, ' ')[7] line
from ods.ods_start_log
where dt='$do_date'
)
insert overwrite table dwd.dwd_start_log
partition(dt='$do_date')
select get_json_object(line, '$.attr.device_id'),
get_json_object(line, '$.attr.area'),
get_json_object(line, '$.attr.uid'),
get_json_object(line, '$.attr.app_v'),
get_json_object(line, '$.attr.event_type'),
get_json_object(line, '$.attr.os_type'),
get_json_object(line, '$.attr.channel'),
get_json_object(line, '$.attr.language'),
get_json_object(line, '$.attr.brand'),
get_json_object(line, '$.app_active.json.entry'),
get_json_object(line, '$.app_active.json.action'),
get_json_object(line, '$.app_active.json.error_code')
from tmp;
"
hive -e "$sql"
执行脚本sh dwd_load_start.sh '2020-07-21',查看数据
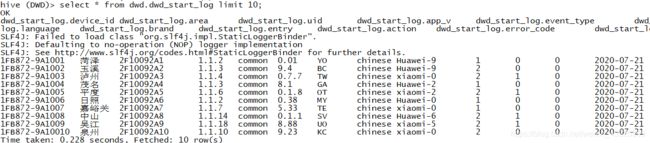
2.6. 活跃会员的DWS层与ADS层
需要算出每日、每周、每月的活跃会员人数,因此可以设计出ADS层的样子
daycnt weekcnt monthcnt dt
周、月分别为自然周、自然月
2.6.1. DWS层表创建
use dws;
drop table if exists dws.dws_member_start_day;
create table dws.dws_member_start_day(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string
) comment '会员日启动汇总'
partitioned by (dt string)
stored as parquet;
drop table if exists dws.dws_member_start_week;
create table dws.dws_member_start_week(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string,
`week` string
) comment '会员周启动汇总'
partitioned by (dt string)
stored as parquet;
drop table if exists dws.dws_member_start_month;
create table dws.dws_member_start_month(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string,
`month` string
) comment '会员月启动汇总'
partitioned by (dt string)
stored as parquet;
2.6.2. 加载数据到DWS层
创建脚本/data/dw/script/member_active/dws_load_member_start.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
# 定义要执行的sql
# 汇总得到每日活跃会员人数
sql="
insert overwrite table dws.dws_member_start_day
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand))
from dwd.dwd_start_log
where dt='$do_date'
group by device_id;
-- 汇总得到每周活跃会员人数
insert overwrite table dws.dws_member_start_week
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_add(next_day('$do_date', 'mo'), -7)
from dws.dws_member_start_day
where dt >= date_add(next_day('$do_date', 'mo'), -7)
and dt <= '$do_date'
group by device_id;
-- 汇总得到每月活跃会员人数
insert overwrite table dws.dws_member_start_month
partition(dt='$do_date')
select device_id,
concat_ws('|', collect_set(uid)),
concat_ws('|', collect_set(app_v)),
concat_ws('|', collect_set(os_type)),
concat_ws('|', collect_set(language)),
concat_ws('|', collect_set(channel)),
concat_ws('|', collect_set(area)),
concat_ws('|', collect_set(brand)),
date_format('$do_date', 'yyyy-MM')
from dws.dws_member_start_day
where dt >= date_format('$do_date', 'yyyy-MM-01')
and dt <= '$do_date'
group by device_id;
"
hive -e "$sql"
2.6.3. 创建ADS层
use ads;
drop table if exists ads.ads_member_active_count;
create table ads.ads_member_active_count(
`daycnt` int comment '当日会员数量',
`weekcnt` int comment '当周会员数量',
`monthcnt` int comment '当月会员数量'
) comment '会员活跃数量'
partitioned by (dt string)
row format delimited fields terminated by ',';
2.6.4. 加载数据到ADS
/data/dw/script/member_active/ads_load_member_active.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with tmp as(
select 'day' datelabel, count(*) cnt, dt
from dws.dws_member_start_day
where dt='$do_date'
group by dt
union all
select 'week' datelabel, count(*) cnt, dt
from dws.dws_member_start_week
where dt='$do_date'
group by dt
union all
select 'month' datelabel, count(*) cnt, dt
from dws.dws_member_start_month
where dt='$do_date'
group by dt
)
insert overwrite table ads.ads_member_active_count
partition(dt='$do_date')
select sum(case when datelabel='day' then cnt end) as day_count,
sum(case when datelabel='week' then cnt end) as weeek_count,
sum(case when datelabel='month' then cnt end) as month_count
from tmp
group by dt;
"
hive -e "$sql"
调用脚本统计7-21至7-23的数据
当执行过程中发现任务失败,查看$HIVE_HOME/logs/hive.log发现OOM:java heap space

- 如何解决
原因:内存分配问题
解决思路:给map、reduce task分配合理的内存;map、reduce task处理合理的数据
查看现在map task分配了多少内存
https://blog.csdn.net/xygl2009/article/details/45531505
查看数据
![]()
2.7. 新增会员
2.7.1. 测试如何计算新增会员
t1数据/data/dw/data/t1.dat
4,2020-08-02
5,2020-08-02
6,2020-08-02
7,2020-08-02
8,2020-08-02
9,2020-08-02
t2数据/data/dw/data/t2.dat
1,2020-08-01
2,2020-08-01
3,2020-08-01
4,2020-08-01
5,2020-08-01
6,2020-08-01
创建表t1
drop table t1;
create table t1(id int, dt string)
row format delimited fields terminated by ',';
load data local inpath '/data/dw/data/t1.dat' into table t1;
创建表t2
drop table t2;
create table t2(id int, dt string)
row format delimited fields terminated by ',';
load data local inpath '/data/lagoudw/data/t2.dat' into table t2;
-- 找出 2020-08-02 的新用户
select t1.id, t1.dt
from t1 left join t2
where t1.id = t2.id
and t1.dt = '2020-08-02'
and t2.id is null;
2.7.2. 创建DWS层
创建表
use dws;
drop table if exists dws.dws_member_add_day;
create table dws.dws_member_add_day(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string,
`dt` string
) comment '每日新增会员明细'
stored as parquet;
加载数据/data/dw/script/member_active/dws_load_member_add_day.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert into dws.dws_member_add_day
select t1.device_id,
t1.uid,
t1.app_v,
t1.os_type,
t1.language,
t1.channel,
t1.area,
t1.brand,
'$do_date'
from dws.dws_member_start_day t1 left join dws.dws_member_add_day t2
on t1.device_id = t2.device_id
where t1.dt = '$do_date'
and t2.device_id is null;
"
hive -e "$sql"
2.7.3. 创建ADS层
创建表
use ads;
drop table if exists ads.ads_new_member_cnt;
create table ads.ads_new_member_cnt(
`cnt` int
)
partitioned by(dt string)
row format delimited fields terminated by ',';
加载数据
data/dw/script/member_active/ads_load_member_add.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert into ads.ads_new_member_cnt
partition (dt='$do_date')
select count(1)
from dws.dws_member_add_day
where dt = '$do_date'
"
hive -e "$sql"
执行脚本并查看结果
在这里插入图片描述
2.7. 留存会员
2.7.1. 创建DWS层
drop table if exists dws.dws_member_retention_day;
create table dws.dws_member_retention_day(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string,
`add_date` string comment '会员新增时间',
`retention_date` int comment '留存天数'
) comment '每日会员留存明细'
partitioned by (`dt` string)
stored as parquet;
2.7.2. 加载数据
/data/dw/script/member_active/dws_load_member_retention_day.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dws.dws_member_retention_day
partition(dt='$do_date')
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
1
from dws.dws_member_start_day t1 join dws.dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('$do_date', -1)
and t1.dt = '$do_date'
union all
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
2
from dws.dws_member_start_day t1 join dws.dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('$do_date', -2)
and t1.dt = '$do_date'
union all
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
3
from dws.dws_member_start_day t1 join dws.dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('$do_date', -3)
and t1.dt = '$do_date'
"
hive -e "$sql"
内存不足,改写sql,创建临时表
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
drop table if exists tmp.tmp_member_retention;
create table tmp.tmp_member_retention as(
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
1
from dws.dws_member_start_day t1 join dws.dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('$do_date', -1)
and t1.dt = '$do_date'
union all
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
2
from dws.dws_member_start_day t1 join dws.dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('$do_date', -2)
and t1.dt = '$do_date'
union all
select t2.device_id,
t2.uid,
t2.app_v,
t2.os_type,
t2.language,
t2.channel,
t2.area,
t2.brand,
t2.dt add_date,
3
from dws.dws_member_start_day t1 join dws.dws_member_add_day t2
on t1.device_id = t2.device_id
where t2.dt = date_add('$do_date', -3)
and t1.dt = '$do_date'
);
insert overwrite table dws.dws_member_retention_day
partition(dt='$do_date')
select * from tmp.tmp_member_retention;
"
hive -e "$sql"
2.7.3. 创建ADS层
use ads;
drop table if exists ads.ads_member_retention_count;
create table ads.ads_member_retention_count(
`add_date` string comment '新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数'
) comment '会员留存数'
partitioned by (`dt` string)
row format delimited fields terminated by ',';
drop table if exists ads.ads_member_retention_rate;
create table ads.ads_member_retention_rate(
`add_date` string comment '新增日期',
`retention_day` int comment '截止当前日期留存天数',
`retention_count` bigint comment '留存数',
`new_mid_count` bigint comment '当日会员新增数',
`retention_ratio` string comment '留存率'
) comment '会员留存率'
partitioned by (dt string)
row format delimited fields terminated by ',';
2.7.4. 加载数据到ADS层
/data/dw/script/member_active/ads_load_member_retention.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_member_retention_count
partition(dt = '$do_date')
select add_date, retention_date, count(1) retention_count
from dws.dws_member_retention_day
where dt = '$do_date'
group by add_date, retention_date;
insert overwrite table ads.ads_member_retention_rate
partition(dt = '$do_date')
select t1.add_date,
t1.retention_day,
t1.retention_count,
t2.cnt,
t1.retention_count / t2.cnt * 100
from ads.ads_member_retention_count t1 join ads.ads_new_member_cnt t2
on t1.add_date = t2.dt
where t1.dt = '$do_date'
"
hive -e "$sql"
3. 广告业务
3.1. 需求分析
事件日志数据样例:
{
"lagou_event":[
{
"name":"goods_detail_loading",
"json":{
"entry":"3",
"goodsid":"0",
"loading_time":"80",
"action":"4",
"staytime":"68",
"showtype":"4"
},
"time":1596225273755
},
{
"name":"loading",
"json":{
"loading_time":"18",
"action":"1",
"loading_type":"2",
"type":"3"
},
"time":1596231657803
},
{
"name":"ad",
"json":{
"duration":"17",
"ad_action":"0",
"shop_id":"786",
"event_type":"ad",
"ad_type":"4",
"show_style":"1",
"product_id":"2772",
"place":"placeindex_left",
"sort":"0"
},
"time":1596278404415
},
{
"name":"favorites",
"json":{
"course_id":0,
"id":0,
"userid":0
},
"time":1596239532527
},
{
"name":"praise",
"json":{
"id":2,
"type":3,
"add_time":"1596258672095",
"userid":8,
"target":6
},
"time":1596274343507
}
],
"attr":{
"area":"拉萨",
"uid":"2F10092A86",
"app_v":"1.1.12",
"event_type":"common",
"device_id":"1FB872-9A10086",
"os_type":"4.1",
"channel":"KS",
"language":"chinese",
"brand":"xiaomi-2"
}
}
采集的信息包括:
- 商品详情页加载:goods_detail_loading
- 商品列表:loading
- 消息通知:notification
- 商品评论:comment
- 收藏:favorites
- 点赞:praise
- 广告:ad
- action。用户行为;0 曝光;1 曝光后点击;2 购买
- duration。停留时长
- shop_id。商家id
- event_type。“ad”
- ad_type。格式类型;1 JPG;2 PNG;3 GIF;4 SWF
- show_style。显示风格,0 静态图;1 动态图
- product_id。产品id
- place。广告位置;首页=1,左侧=2,右侧=3,列表页=4
- sort。排序位置
3.2. 需求指标
-
点击次数统计(分时统计)
- 曝光次数、不同用户id数、不同用户数
- 点击次数、不同用户id数、不同用户数
- 购买次数、不同用户id数、不同用户数
-
转化率-漏斗分析
- 点击率 = 点击次数 / 曝光次数
- 购买率 = 购买次数 / 点击次数
-
活动曝光效果评估
- 行为(曝光、点击、购买)、时间段、广告位、产品,统计对应的次数
- 时间段、广告位、商品,曝光次数最多的前N个
3.3. 日志采集
启动flume,cp事件日志到/data/dw/logs/event/目录下
3.4. 创建ODS层并加载数据
创建ODS层
use ods;
drop table if exists ods.ods_log_event;
create table ods.ods_log_event(`str` string)
partitioned by (`dt` string)
stored as textfile
location '/user/data/logs/event';
加载数据/data/dw/script/advertisement/ods_load_event_log.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="alter table ods.ods_log_event add partition (dt = '$do_date');"
hive -e "$sql"
3.5. 创建DWD层和数据加载
建表
-- 所有事件明细
drop table if exists dwd.dwd_event_log;
create external table dwd.dwd_event_log(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`event_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string,
`name` string,
`event_json` string,
`report_time` string
)
partitioned by (`dt` string)
stored as parquet;
-- 所有广告点击明细
drop table if exists dwd.dwd_ad;
create table dwd.dwd_ad(
`device_id` string,
`uid` string,
`app_v` string,
`os_type` string,
`event_type` string,
`language` string,
`channel` string,
`area` string,
`brand` string,
`report_time` string,
`duration` int,
`ad_action` int,
`shop_id` int,
`ad_type` int,
`show_style` smallint,
`product_id` int,
`place` string,
`sort` int,
`hour` string
)
partitioned by (`dt` string)
stored as parquet;
3.5.1. 自定义UDF函数
用于将jsonArray转换成List
package com.catkeeper.hive.udfs;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.parquet.Strings;
import java.util.ArrayList;
import java.util.List;
/**
* ParseJsonArray
*
* @author chenhang
* @date 2020/12/21
*/
public class JsonArray extends UDF {
public List<String> evaluate(String jsonStr) {
if (Strings.isNullOrEmpty(jsonStr)) {
return null;
}
JSONArray jsonArray = JSON.parseArray(jsonStr);
ArrayList<String> strings = new ArrayList<>();
jsonArray.forEach(json -> strings.add(json.toString()));
return strings;
}
}
3.5.2. 编写脚本加载数据
获取全部日志事件/data/dw/script/advertisement/dwd_load_event_log.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
use dwd;
add jar /data/dw/jars/udf-1.0-SNAPSHOT-jar-with-dependencies.jar;
create temporary function json_array as 'com.catkeeper.hive.udfs.JsonArray';
with tmp_start as(
select split(str, ' ')[7] as line
from ods.ods_log_event
where dt='$do_date'
)
insert overwrite table dwd.dwd_event_log
partition(dt = '$do_date')
select
device_id,
uid,
app_v,
os_type,
event_type,
language,
channel,
area,
brand,
get_json_object(k, '$.name') name,
get_json_object(k, '$.json') json,
get_json_object(k, '$.time') time
from (
select
get_json_object(line, '$.attr.device_id') as device_id,
get_json_object(line, '$.attr.uid') as uid,
get_json_object(line, '$.attr.app_v') as app_v,
get_json_object(line, '$.attr.os_type') as os_type,
get_json_object(line, '$.attr.event_type') as event_type,
get_json_object(line, '$.attr.language') as languague,
get_json_object(line, '$.attr.channel') as channel,
get_json_object(line, '$.attr.area') as area,
get_json_object(line, '$.attr.brand') as brand,
get_json_object(line, '$.lagou_event') as lagou_event
from tmp_start
) t1
lateral view explode(json_array(lagou_event)) t2 as k
"
hive -e "$sql"
从全部的事件日志中获取广告点击事件
/data/dw/script/advertisement/dwd_load_ad_log.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table dwd.dwd_ad
partition (dt = '$do_date')
select
device_id,
uid,
app_v,
os_type,
event_type,
language,
channel,
area,
brand,
report_time,
get_json_object(event_json,'$.duration'),
get_json_object(event_json,'$.ad_action'),
get_json_object(event_json,'$.shop_id'),
get_json_object(event_json,'$.ad_type'),
get_json_object(event_json,'$.show_style'),
get_json_object(event_json,'$.product_id'),
get_json_object(event_json,'$.place'),
get_json_object(event_json,'$.sort'),
from_unixtime(ceil(report_time/1000), 'HH')
from dwd.dwd_event_log
where dt='$do_date' and name='ad'
"
hive -e "$sql"
3.6. 广告点击次数分析
- 曝光次数、不同用户id数(公共信息中的uid)不同用户数(公共信息中的 device_id)
- 点击次数、不同用户id数 不同用户数(device_id)
- 购买次数、不同用户id数、不同用户数(device_id)
3.6.1. 创建ADS层表
use ads;
drop table if exists ads.ads_ad_show;
create table ads.ads_ad_show(
`cnt` bigint,
`u_cnt` bigint,
`device_cnt` bigint,
`ad_action` tinyint,
`hour` string
)
partitioned by (`dt` string)
row format delimited fields terminated by ',';
3.6.2. 编写脚本加载数据
/data/dw/script/advertisement/ads_load_ad_show.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 date" +%F`
fi
sql="
insert overwrite table ads.ads_ad_show
partition (dt = '$do_date')
select
count(1),
count(distinct uid),
count(distinct device_id),
ad_action,
hour
from dwd.dwd_ad
where dt = '$do_date'
group by ad_action, hour;
"
hive -e "$sql"
3.6. 漏斗分析
3.6.1. 需求分析
分时统计:
点击率 = 点击次数 / 曝光次数
购买率 = 购买次数 / 点击次数
3.6.2. 创建ADS层表
use ads;
drop table if exists ads.ads_ad_show_rate;
create table ads.ads_ad_show_rate(
`hour` string,
`click_rate` double,
`buy_rate` double
)
partitioned by (`dt` string)
row format delimited fields terminated by ',';
3.6.3. 编写脚本加载数据
/data/dw/script/advertisement/ads_load_ad_show_rate.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with tmp as (
select max(case when ad_action = '0' then cnt end) show_cnt,
max(case when ad_action = '1' then cnt end) click_cnt,
max(case when ad_action = '2' then cnt end) buy_cnt,
hour
from ads.ads_ad_show
where dt = '$do_date'
group by hour
)
insert overwrite table ads.ads_ad_show_rate
partition (dt = '$do_date')
select
hour,
click_cnt / show_cnt * 100,
buy_cnt / click_cnt * 100
from tmp;
"
hive -e "$sql"
3.7. 广告效果分析
3.7.1. 需求分析
活动曝光效果评估:
行为(曝光、点击、购买)、时间段、广告位、商品,统计对应的次数
时间段、广告位、商品,曝光次数最多的前100个
3.7.2. 创建ADS层表
use ads;
drop table if exists ads.ads_ad_show_place;
create table ads.ads_ad_show_place(
`ad_action` string,
`hour` string,
`place` string,
`product_id` int,
`cnt` bigint
)
partitioned by (`dt` string)
row format delimited fields terminated by ',';
drop table if exists ads.ads_ad_show_place_window;
create table ads.ads_ad_show_place_window(
`hour` string,
`place` string,
`product_id` string,
`cnt` bigint,
`rank` int
)
partitioned by (`dt` string)
row format delimited fields terminated by ',';
3.7.3. 加载ADS数据
/data/dw/script/advertisement/ads_load_ad_show_page.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_ad_show_place
partition (dt = '$do_date')
select
ad_action,
hour,
place,
product_id,
count(1)
from dwd.dwd_ad
where dt = '$do_date'
group by ad_action, hour, place, product_id;
"
hive -e "$sql"
/data/dw/script/advertisement/ads_load_ad_show_page_window.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_ad_show_place_window
partition (dt = '$do_date')
select * from
(
select
hour,
place,
product_id,
cnt,
row_number() over (partition by hour, place, product_id order by cnt desc) rank
from ads.ads_ad_show_place
where dt = '$do_date' and ad_action = '0'
) t
where rank <= 100
"
hive -e "$sql"
4. ADS层数据导出(使用DataX)
创建文件/data/dw/json/stream2stream.json
{
"job": {
"content": [{
"reader": {
"name": "streamreader",
"parameter": {
"sliceRecordCount": 10,
"column": [{
"type": "String",
"value": "hello DataX"
},
{
"type": "string",
"value": "DataX Stream To Stream"
}, {
"type": "string",
"value": "数据迁移工具"
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "GBK",
"print": true
}
}
}],
"setting": {
"speed": {
"channel": 1
}
}
}
}
python $DATAX_HOME/bin/datax.py /data/dw/json/stream2stream.json
5. 计算最近七天连续三天活跃会员数
连续三天活跃会员数也就是这三天都有登录,那么基础数据可以看会员日启动汇总表
5.1. 测试
连续三天启动,先通过测试数据研究如何实现连续7天登录
/data/dw/data/login.dat
id date 是否登录
1 2019-07-11 1
1 2019-07-12 1
1 2019-07-13 1
1 2019-07-14 1
1 2019-07-15 1
1 2019-07-16 1
1 2019-07-17 1
1 2019-07-18 1
2 2019-07-11 1
2 2019-07-12 1
2 2019-07-13 0
2 2019-07-14 1
2 2019-07-15 1
2 2019-07-16 0
2 2019-07-17 1
2 2019-07-18 0
3 2019-07-11 1
3 2019-07-12 1
3 2019-07-13 1
3 2019-07-14 0
3 2019-07-15 1
3 2019-07-16 1
3 2019-07-17 1
3 2019-07-18 1
-- 建表加载测试数据
use tmp;
drop table if exists tmp.tmp_user_login;
create table tmp.tmp_user_login(
`uid` string,
`dt` date,
`is_login` int
)
row format delimited fields terminated by ' ';
-- 加载数据
load data local inpath '/data/dw/data/login.dat' into table tmp.tmp_user_login;
根据id分组给每行一个行号,然后每行让日期减去行号(这个结果叫做gid),因为日期是逐一增加的,行号也是逐一增加,所以这样连续的登录记录减去行号会得到同样一个日期。但是如果只筛出is_login为1的数据,那么登录不连续会出现断层,日期增加的比行号增加的多,所以gid会出现不同的结果。
这样如果一个人连续登录的话,那么gid都是相同的,gid如果不同那么说明是两次不同的连续登录
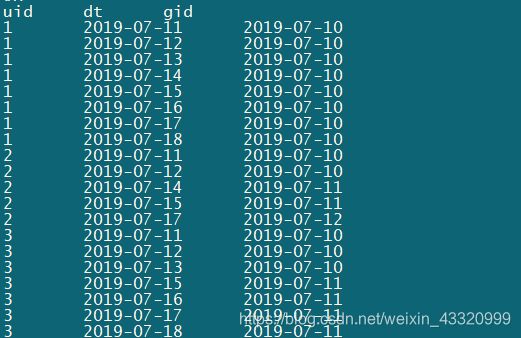
select uid, dt, date_sub(dt, row_number() over (partition by uid order by dt)) as gid
from tmp.tmp_user_login
where is_login = 1
这样只要按照uid和gid来分组,求出数量大于等于7的uid,就可以得到连续登录超过7天的人了,
with tmp as (select uid, dt, date_sub(dt, row_number() over (partition by uid order by dt)) as gid
from tmp.tmp_user_login
where is_login = 1)
select uid, count(*) days
from tmp
group by uid, gid
having days >= 7;
因此只要能够让会员日启动汇总数据展示测试数据的样子就可以实现连续三天活跃会员数了
with tmp1 as (select device_id, dt
from dws.dws_member_start_day
order by device_id, dt),
tmp2 as (
select device_id, dt, date_sub(dt, row_number() over (partition by device_id order by dt)) as gid
from tmp1
)
select device_id, count(1) days
from tmp2
group by device_id, gid
having days >= 3;
然后再做成脚本,统计到dws.dws_member_serial表内
5.2. 创建dws层并加载数据
创建表dws.dws_member_serial_three
use dws;
drop table if exists dws.dws_member_serial_three;
create table dws.dws_member_serial_three(
`device_id` string,
`serial_days` int
)
partitioned by (`dt` string)
stored as parquet;
创建脚本加载数据/data/dw/script/member_active/dws_load_serial_tree.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
with tmp1 as (select device_id,
uid,
app_v,
os_type,
language,
channel,
area,
brand,
dt
from dws.dws_member_start_day
where dt >= date_sub('$do_date', 6)
and dt <= '$do_date'
order by device_id, dt),
tmp2 as (
select device_id,
uid,
app_v,
os_type,
language,
channel,
area,
brand,
dt,
date_sub(dt, row_number() over (partition by device_id order by dt)) as gid
from tmp1
)
insert overwrite table dws.dws_member_serial_three
partition (dt = '$do_date')
select device_id,
count(1) days
from tmp2
group by device_id, gid
having days >= 3;
"
hive -e "$sql"
5.3. 创建ads层并加载数据
创建ads表
use ads;
drop table if exists ads.ads_member_serial_three;
create table ads.ads_member_serial_three(
`cnt` bigint
)
partitioned by (dt string)
row format delimited fields terminated by ',';
编写脚本加载数据/data/dw/script/member_active/ads_load_member_serial_three.sh
#! /bin/bash
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
insert overwrite table ads.ads_member_serial_three
partition (dt = '$do_date')
select count(1)
from dws.dws_member_serial_three
where dt = '$do_date'
"
hive -e "$sql"