最佳实践| 一文读懂《MongoDB 使用规范及最佳实践》原理
最佳实践| 一文读懂《MongoDB 使用规范及最佳实践》原理
一、MongoDB 使用规范与限制
MongoDB 灵活文档的优势
- 灵活库/集合命名及字段增减
- 同一字段可存储不同类型数据
- Json 文档可多层次嵌套文档
- 对于开发而言最自然的表达
MongoDB 灵活文档的烦恼
- 数据库集合字段名千奇百怪
- 同一字段数据类型各不一样
- 业务异常可能写入“脏”数据
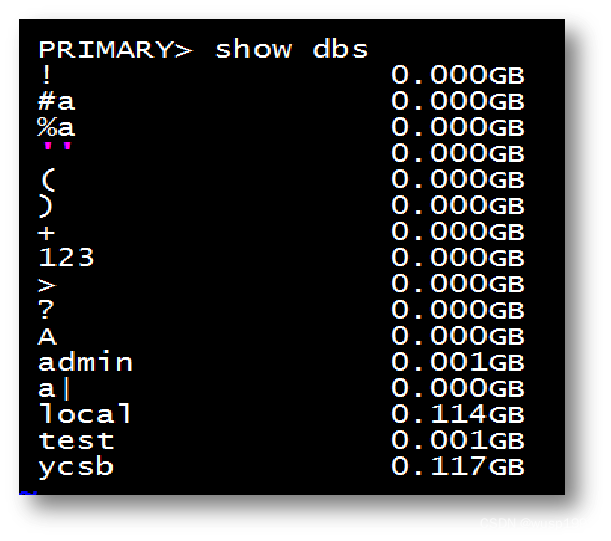
1.1 库命名规范
- 不能为空字符串 “”
- 不能以 $ 开头
- 不能包含 . 号 /\
- 数据库名大小写敏感
- 数据库名最长为 64 个字符
- 不能与系统库相同
最佳实践
- 数据库命名只包含小写英文字符加下划线 _
- 数据库名含多个单词考虑缩小并以下划线连接
- 如:package_manager
1.2 集合名规范
- 不能为空字符串 “”
- 不能以 system. 系统集合名开头
- 不因包含 ~!@#%^&*()-+
最佳实践
- 集合命名只包含下划线和小写英文字母
- 如: students_books
1.3 Bson 单文档的大小及嵌套限制
- 单文档不超过16 MB
- 嵌套不能超过100 层
如果单条记录超过 16 M 怎么办?
第一种办法:先处理后存储。可以先做压缩,或者也可以对字符进行先哈希,然后再存储,这样大概率就不会超过 16 MB。
第二种方法:通常来说 16 MB 的记录都可以直接写到文本文件里面,然后再将文件存到 MongoDB GridFS 里面或者先业务层处理后存储。
1.4 索引限制
-
单个集合最多包含 64 个索引
-
单个索引记录不超过 1024 字节
[failIndexKeyTooLong 默认 true 控制是否报错]
当然其实我们也有其他的方式来解决类似这样的一个问题这个我们后面再说
-
多列索引列个数最多不超过 31
-
前台模式 createIndexes内存限制500 MB
(maxIndexBuildMemoryUsageMegabytes 可调整)
-
不允许创建多列数组的组合索引
实际上为什么有这个限制呢?
MongoDB 如果索引字段是数组,那我们可以理解为对每个数组元素创建索引。如果要是多个数组字段建组合索引,就意味着它可能会产生笛卡尔级数据量的索引。所以为了避免这种索引的爆炸性增长,需要对此做了相应的一个限制。
- TTL 索引如果是复合索引则过期将会失效
通常你想创建一个 TTL 索引,但创建的时候构建了多个字段的组合索引,那么 TTL 就会失效。
- Hash 索引只支持单列 【<= 4.4 版本】
另外需要记住的就是哈希索引只支持单例,这个是在 4.4 之前的一个限制,到后面是做了调整,所以在这里也需要给大家提一下。我们本次分享为大部分内容的前提是小于等于 4.2 版本,主要原因在于 4.4 及其以上的 MongoDB 版本其实有很多企业里面都没有使用。
最佳实践
- 使用 background 模式批量创建索引
后台建索引意味着它不会阻塞我们的业务的写,否则的话就会加库级别的锁从而造成业务阻塞。当然还有一个情况就是当我们对同一个集合添加多个索引的时候,建议大家用 createIndexes 批量建索引。因为每次创建索引,实际上可以理解 MongoDB 都会去扫描整个集合,通过扫描整个集合去拿到对应字段的记录,然后将这些记录插入到索引文件里面,使用批量建索引只需要扫描一次,如果分开来建索引那么就需要扫描多次,故批量建索引能大大减少对业务的影响。
- 多列索引尽量不要超过 5 个字段
这个算是一个经验建议,当然 6 个字段也行。有时候要反过来想,当一个索引有 5 、6 个字段或者 7 、8 个字段的时候,我们应该第一时间要反思我们业务设计是否合理。当然有些业务场景比较特殊也确实有这种必要性,那该放开限制还的放开。
- 单个集合索引数量适当控制至 5 个
MongoDB 每次在数据插入更新删除的时候,实际上需要同步的去做索引的变更,所以索引越多,其实对于这些变更来说,它的代价就越大。所以,推荐创建尽量少的索引去满足更多的业务查询。
- 尽量避免对数组字段创建索引
前面说过,对存储数组的字段创建索引,实际上是多数组每个元素创建索引,同时,字段值更新也同步更新索引字段。所以,当数组元素量非常大的时候比如 1 w,5 w,这个时候的索引代价就会比较大。
1.5 副本集限制
- 副本集最多含有 50 个节点
- 副本集只可含 7 个投票节点
最佳问答
问:为何副本集只可含有 7 个投票节点?
答:提高选举效率、减少心跳网络代价
1.6 分布式集群限制
- 分片 key 最大长度不能超过 512 字节
- 分片 key 索引类型不能是 text 、数组索引和 geo 索引
- 分片集合单个文档的条件操作必须带分片 key 或 _id
- 分片 key 及其值不允许修改( 4.2 版本前不允许修改 key 值,4.4 版本前不许变更 key 字段)
虽然 4.2 版本可以修改分片 key 的值,4.4 版本可以调整分片 key 的字段,但依然建议不要轻易调整 key 的值或 key 的字段构成 ,而是建议在初始化分片 key 的时候就评估好。
- 分片集合不允许创建普通(不含分片 key 前缀)唯一性索引
1.7 多文档事务限制(>= 4.0)
- 不支持系统库(config、local、admin)里的集合
- 事务不支持元数据操作的修改(如 drop 集合)
- 非增删改查如用户创建等操作不支持事务 事务执行周期默认最长 60 秒超过即自动崩溃退出
最佳实践
- transactionLifetimeLimitSeconds 参数控制超时时间
- 一般建议不调整或调整为更小,加快资源的释放
- 默认事务申请锁等待时间 5 ms 如果超时即崩溃退出
1.8 其他限制
- 全集合扫描排序的内存限制 32 MB [否则报错]
最佳实践:
为排序添加索引;控制排序数据量
- Aggregation 管道操作的内存限制 100 MB
最佳实践:
控制计算数据量
调整 allowDiskUse 允许磁盘排序
- bulkWrite 操作每批最大操作数限制 1000 或 10 w (>= 3.6)
最佳实践:
通常建议实际业务每次批量控制在 1000 ~ 5000
默认情况下 bulkWrite 操作有序一般建议设置 false
为避免批量操作导致复制延迟可每批适当 sleep
其他建议
- 查询、更新与删除必须带条件并且条件字段具有合适的索引
- Update 必须使用 $set 否则会重置文档
- Find 和 aggregate 操作建议按需返回对应的字段
- 数组元素添加尽量使用 $push 并且避免对中间元素进行更新
- 超高并发写入场景 4.0 版本之前尽量避免读写分离(存在全局复制锁阻塞业务读从库)
二、MongoDB 数据类型及容量评估
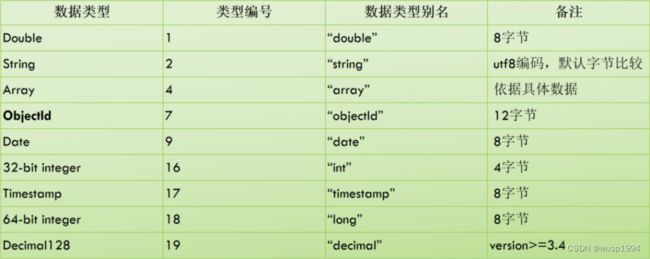
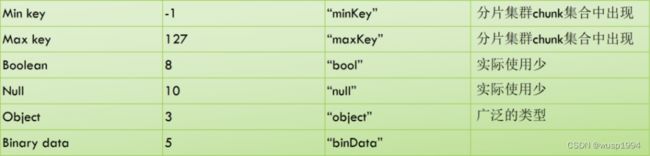
数据类型介绍
列表里面是 MongoDB 常见或者不常见的一些数据类型,可能大部分人没有详细地去梳理过,可以去仔细了解一下做参考。(可能有些不是 100% 的准确)
关于 MongoDB ObjectId
在插入一个文档时如果业务没有显示指定 _id 那么 MongoDB 会为每个文档生成一个ObjectId 类型的 _id 来作为主键其构成如下:
- 4-byte 存储时间戳
- 3-byte 存储机器码
- 2-byte 存储进程 ID
- 3-byte 计数器
自增性问题: _id 不绝对自增前 4 个字节是时间戳故只能精确到秒同一秒进程 ID 大小决定顺序
唯一性问题:同一个机器同一时间下因为计数器的存在,在 2^24-1 个值内都是唯一性
_id 存在意义:解决分布式场景下唯一性标志问题;复制依赖 _id 方便定位修改的记录
ObjectId 用例:
shell 下获取 _id 的时间戳方式
_id.getTimestamp()
关于 MongoDB Date 类型
MongoDB 底层以 BSON 存储而按照 BSON Date/Time 数据类型定义日期时间被称为 UTC 时间,故业务计算时需注意与本地时间进行转换:
- 获取当前本地时间 Date()
- 获取当前 UTC 时间 new Date()
关于 MongoDB Timestamp
作为 BSON 特殊的时间戳类型 Timestamp 主要用于 MongoDB 内部使用期主要构成如下:
- 前 32 位存储时间戳
- 后 32 位存储同一秒内自增值
Timestamp 通常应用与复制中的 oplog,业务层面通常建议使用 Date 类型:
- db.test.insert( { ts : new Timestamp() } )
- 如果 ts 为嵌入式文档则默认时间戳为 0
关于 MongoDB 的 null
如字段 a 不存在 { } 与 {a:null } 相对等价 a
如果 a 字段不存在以及 a 等于空,它其实相对来说就是等价的。
- db.test.insert({ _id: 1, item: null });
- db.test.insert({ _id: 2 });
- db.test.createIndex({item:1},{background:true})
存在性查询
- db.test.find( { item : { $exists: false } } )
null值查询
- db.test.find({item:null})
数据类型验证
$type 查询某个字段具体类型的数据
- db.test.insert({a:1,mk:MinKey(),udt:new Date()})
- db.test.find( { “a” : { $type: “double” } } )
- db.test.find({mk:{$type:”minKey”}})
- db.test.find({udt:{$type:”date”}})
mongo shell 下查看数据类型方法
- typeof 1
- NumberInt(1) instanceof NumberLong
- [] instanceof Array NumberDecimal
- (9999999.4999999999) instanceof Number
数据类型比较
数据类型从小到大比较顺序如下:
-
MinKey
-
Null Numbers
(ints, longs, doubles, decimals)
-
String
-
Object
-
Array
-
BinData
-
ObjectId
-
Boolean
-
Date
-
Timestamp
-
Regular Expression
-
MaxKey
验证用例:
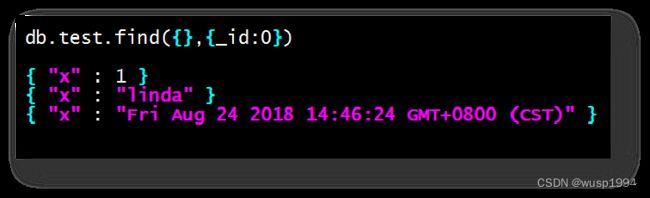
db.test.insert([{a:1},{a:MinKey()},{a:new Date()},{a:Timestamp()},{a:[1]},{a:null},{a:NumberLong(1)}])
db.test.find({},{_id:0}).sort({a:1})
MongoDB 容量评估与计算
MongoDB 因其包含了非常规数据类型故对容量的评估不能参照关系型数据库评估方式
怎么去预估写入量?
实际上特别简单,不用去计算它每个字段的字节数或者有多少索引,每个索引它的字段对应的字节数,直接拿真实的环境或者跟线上环境类似的测试环境直接模拟写数据,然后直接去查看对应的一个数据大小就可以。
show dbs
admin 0.000GB
test 43.398GB //(storageSize+ indexSize) = du -sh test
local 9.794GB
db.stats()
{
"db" : "test",
"collections" : 5,
"views" : 0,
"objects" : 276054256, //所有集合的文档数 dataSize/avgObjSize
"avgObjSize" : 190.81693790296063, //dataSize/objects (bytes)
" dataSize" : 52675827825, //未压缩的数据大小不含索引(bytes)
"storageSize" : 12666482688, //存储引擎分配存储数据大小(bytes)
"numExtents" : 0,
"indexes" : 10,
"indexSize" : 33932251136, //所有集合索引(压缩)大小储(bytes)
"ok" : 1
}
``
三、集合数据类型及合法性校验
对于 MongoDB 来说为什么要做数据类型及合法性校验?曾经在线上库我们看到如下图片的类似数据,看看 boo_id 存储的数据,各种类型数据都可以写入且没有任何问题。

- MongoDB 3.2 开始在创建集合的时候提供了 validator 选项来规范插入和更新数据的规则
- 为了增强 3.2 版本 validator 功能 MongoDB 3.6 提供了 JSON Schema 进一步完善校验规则
- 对于数据库中已经存在集合可使用 collMod 来修改集合从而添加对应的 validator 校验规则
- 对应类似于 validator 与版本相关的特性在数据库升降级过程中需要预先进行处理
- 数据校验功能对插入更新的性能影响非常小线上环境亦可放心使用
Validation 相关概念
validator + 查询逻辑操作符
(除 n e a r 、 near、 near、nearSphere、 t e x t 、 text、 text、where):定义具体的校验规则
**validationLevel:**定义了插入更新记录时应用校验规则的严格程度
-
strict:默认严格级别校验规则会应用到所有的插入与更新上
-
moderate:仅对 insert 和满足校验规则的文档做 update 有效
-
对已存在的不符合校验规则的文档无效
-
off:关闭校验
**validationAction:**定义了当数据不满足校验规则的时候的具体动作
- error:默认直接打印报错并拒绝文档
- warn:日志打印告警提示但接受文档
Validation 使用限制
- 不允许在 local、admin 及 config 等系统库中的集合创建具有校验规则的集合
- 不允许对 system.* 等系统集合创建校验规则
**原因:**避免系统内部操作无法正常写入系统集合而导致不可预料的问题
validation 的使用
db.createCollection( "validate_test",
{ validator: { $and:
[
{ phone: { $type: "long" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "good", "bad" ] } }
]
},
validationLevel: "moderate",
validationAction: "error"
} )
db.validate_test.insert({phone:"123456789",email:"[email protected]",status:"good"})
Validation 属性修改
关闭校验
db.runCommand( {
collMod: "validate_test",
validationLevel: "off"
} )
db.validate_test.insert({phone:"000", status:"A"})
将校验级别修改为严格模式
db.runCommand( {
collMod: "validate_test",
validationLevel: "strict"
} );
Validation 属性修改
修改校验之后的动作为告警
db.runCommand( {
collMod: "validate_test",
validationAction: "warn"
} )
验证
db.validate_test.insert({phone:"000", status:"A"})
查看属性修改结果
db.getCollectionInfos({"name":"validate_test"})
MongoDB 3.6 增加 $jsonSchema 操作符 进一步增强了文档校验功能
db.createCollection("person", {
validator: {
$jsonSchema: {
bsonType: "object",
required: [ "name", "age", "sex" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
age: {
bsonType: "int",
minimum: 0,
maximum: 125,
exclusiveMaximum: false
},
sex: {
enum: [ "MAN", "WOMAN", null ]
}}}}})
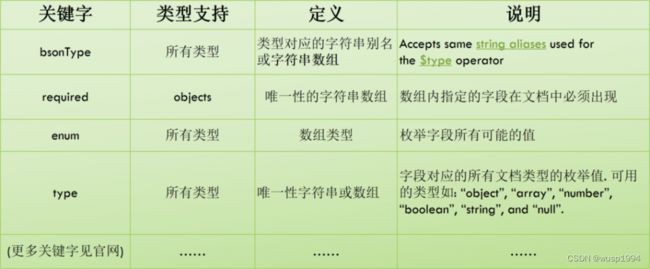
使用 collMod 修改 $jsonSchema 对应的校验规则
db.runCommand( {
collMod: "person",
validator: {
$jsonSchema: { bsonType: "object",
required: [ "name", "age", "sex" ]
properties: {
name: {
bsonType: ["string","int"]
},
age: {
bsonType: "int",
minimum: 0,
maximum: 125,
exclusiveMaximum: false,
},
sex: {
enum: [ "MAN", "WOMAN", null ]
}}}},
validationLevel: "moderate"
} )
Variety 一个开源的 js 脚本集,提供了丰富的数据校验功能
功能特点:
- 输出结果简单清晰
- 可指定过滤条件及限制文档数量
- 可正反序对集合进行分析
- 可对部分字段进行排除
- 可指定对嵌套文档的分析深度
- 可指定输出格式及持久化分析结果
- ……
Variety 用例:
对集合 users 进行分析
mongo 127.0.0.1:27017/test --eval "var collection = 'users'" variety.js
按指定条件进行分析
mongo 127.0.0.1:27017/test --eval "var collection = 'users', query = {'name':'Tom'}" variety.js
分析文档最大深度及指定输出格式
db.users.insert({name:"Walter", someNestedObject:{a:{b:{c:{d:{e:1}}}}}}); mongo
127.0.0.1:27017/test --eval "var collection = 'users', maxDepth = 3,outputFormat='ascii'" variety.js
创建一个集合 test 并且使用 $jsonSchema 定义校验规则
规则如下:
- 集合必须含有 student_id、student_name、score 三个字段
- student_id 必须是长整型
- student_name 必须是字符串类型并且长度不操过 12 字符
- score 必须是 4 字节整型并且大小介于 0 ~ 100 含 100 同时添加注释
- 插入一条非法文档验证规则已经生效并获取 MongoDB 输出信息
- 插入一条合法文档并使用 db.test.find({},{_id:0}) 查询结果必须如下:
{
"student_id": NumberLong("100"),
"student_name": "1234567890",
"score": 0
}