Java知识点锦集
【版权声明】未经博主同意,谢绝转载!(请尊重原创,博主保留追究权)
https://blog.csdn.net/m0_69908381/article/details/129740905
出自【进步*于辰的博客】
之前这篇文章中包含了一些我总结的开发经验,由于考虑到将开发经验和java知识点放在同一篇文章会让大家阅读起来很麻烦,于是我把之前那些经验总结提取到了这篇文章【Java开发细节、经验锦集】。
文章目录
- 1、其他知识点链接
- 2、关于重载
- 3、关于重写
- 4、关于创建对象方法
- 5、关于类加载
-
- 5.1 什么是“类加载”?
- 5.2 类加载过程
- 5.3 子类实例化时语句执行顺序
- 5.4 注意事项
- 6、关于String/包装类/基本数据类型三者间的转换关系
- 7、关于构造方法
- 8、关于继承
- 9、关于序列化
-
- 9.1 什么是“序列化”?
- 9.2 序列化特点
- 9.3 关于序列化ID
- 9.4 序列化/反序列化测试
- 10、关于程序与数据库之间数据类型转换说明(基于JDBC)
-
- 10.1 数据存储(DML)
- 10.2 数据查询(select)
- 11、关于数据类型转换
-
- 11.1 int → char
- 11.2 float与int
- 12、关于ORM
- 13、关于`package`
- 14、关于 IPv4
- 15、关于`static`
- 16、关于常量
-
- 16.1 关于赋初值
- 16.2 常将常量声明为`static`的原因
- 17、关于编译与解释
1、其他知识点链接
- 断言;
- 静态代理、动态代理;
- 基本数据类型和引用类型赋值时的底层分析;
- Socket套接字;
- 二进制的原码、补码和反码;
- 设计模式—单例模式;
- 自定义注解;
- 泛型;
- Lambda表达式;
- 反射;
java.lang.Class类Java_API浅析;
2、关于重载
参考笔记二,P26.6、P29.4。
参数列表不同、或返回值类型不同、或都不同的同名方法称之为“重载”。与访问权限无关,其作用是增加代码可读性。注意:
main()也可重载,默认情况下执行参数类型为String[]的main();- 若方法名、参数列表都相同,仅返回值类型不同,则不是“重载”,且不允许。
3、关于重写
参考笔记二,P29.3。
与父类方法参数列表相同、返回值类型相同的同名方法称之为“重写”。注意:
- 重写方法的访问权限不能低于被重写方法;
- 重写方法的异常范围不能大于被重写方法;
- 若子类某方法与父类某方法方法名、参数列表都相同,仅返回值类型不同,这不是“重写”,且不允许。
4、关于创建对象方法
参考笔记二,P39.7、P45.2。
1、new xx()
2、反射
3、xx.clone()
4、反序列化
clone()属Object类方法,使用clone()的类必须实现Cloneable接口和重写clone()。其中,克隆的对象是一个新对象,克隆分为浅克隆 和深克隆 两种,两者的区别是当克隆的类中引用其他类时,深克隆会同时克隆引用类,而浅克隆不会,仍是同一个。深克隆的实现原理是在相应clone()内克隆引用类。
5、关于类加载
参考笔记一,P31.5、P32.2~5;笔记三,P15.2。
5.1 什么是“类加载”?
大家先看个图:
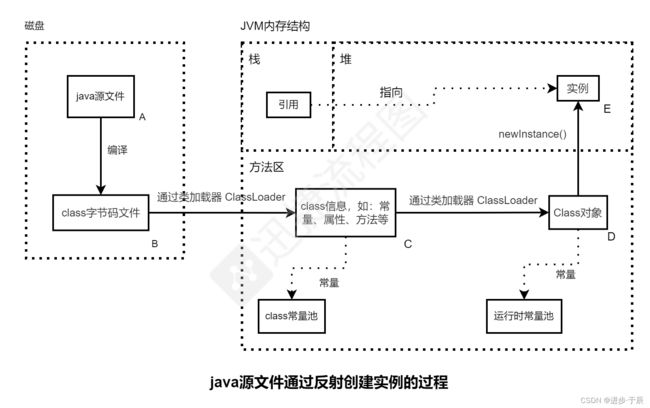
这张是反射的过程图,我曾在博文【关于对Java反射的理解与运用】中使用过。那篇文章中阐述:
图中的 B → D,通过类加载器 ClassLoader 将 class字节码文件 加载进JVM方法区、生成 class 信息、进而创建 Class 对象,这个过程就是 类加载 \color{red}{类加载} 类加载。(注:只有对类的主动使用才会触发类加载,例如:反射、实例化)
下述对此流程进行详述。
5.2 类加载过程
- 过程一:加载,将磁盘中 class 字节码文件 加载进 JVM方法区;
- 过程二:连接,第1步:验证,验证加载进内存的类的正确性;第2步:准备,为类变量分配内存,并赋默认值;第3步:解析,将常量池中的 符号引用 替换成 直接引用 (即内存地址,存于栈);
注:如Person p1中的p1初始就是符号引用,经过解析转为内存地址,常说的“引用就是内存地址”就是这个意思。 - 过程三:初始化,为类变量赋初始值,如:执行静态代码块和
static int a = 10(在静态代码块之外)。
5.3 子类实例化时语句执行顺序
(前提:存在父类)
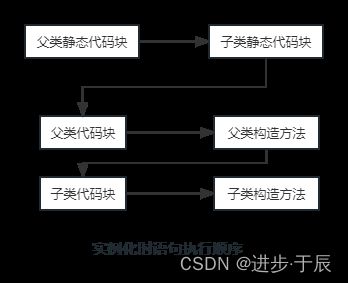
前2项在类初始化时执行,后4项在实例化时执行。
5.4 注意事项
- 只有对类的主动使用(如:反射、实例化)才会触发类初始化,并且,初始化时数据从JVM方法区的全局数据访问区获取;
- 类初始化指类加载的第三过程,实例化指创建对象;
- 一载三化:类加载、类初始化(类加载的第三过程)、实例初始化(实例化前执行)、实例化;
- 实例化过程:
编译 → 类加载 → 实例初始化 → 实例化; - 因为继承,故父类的类加载在子类之前;因为子类拥有父类所有成员,故父类的实例初始化在子类之前。因此,在JVM中,父类的初始化数据存储于子类的存储空间中;
- 类加载仅一次 \color{red}{类加载仅一次} 类加载仅一次,类初始化仅一次;而实例初始化可多次。只要子类实例初始化,父类实例也会初始化,即生成新的子类和父类,因此,即使有多个子类,也不会出现并发性问题。
6、关于String/包装类/基本数据类型三者间的转换关系
参考笔记一,P40.7。

7、关于构造方法
参考笔记一,P34.3。
- 为什么 J V M 会默认为类创建无参构造方法? \color{grey}{为什么JVM会默认为类创建无参构造方法?} 为什么JVM会默认为类创建无参构造方法?因为实例初始化时需要。
- 为什么子类会默认调用父类无参构造方法? \color{grey}{为什么子类会默认调用父类无参构造方法?} 为什么子类会默认调用父类无参构造方法?因为子类拥有父类所有,这需要初始化父类,即调用构造方法。注意:无论子类或父类有没用自定义构造方法,子类都会隐式调用父类无参构造方法。
- 为什么 \color{grey}{为什么} 为什么
super()必须在构造方法的第一行? \color{grey}{必须在构造方法的第一行?} 必须在构造方法的第一行?从第2点可知,子类初始化时会同时初始化父类,但并不能知道super()在第一行的原因。因为父类的初始化数据存储于子类内存空间(具体指堆),即便后续调用(先初始化子类,后初始化父类)也可访问。因此,super()在第一行的原因是:子类要为父类分配内存空间,自然要先知道父类占多少空间,即先初始化父类。
8、关于继承
参考笔记一,P33.7、P34.1、P35.2/3;笔记二,P26.5。
- 子类拥有父类所有,只是无法使用
private修饰部分;父类拥有子类所有,只是无法使用子类扩展部分。故经过上溯或下溯转型,都可使用相应资源; - 只能先进行上溯转型,再进行下溯转型。由于上溯或下溯转型后,很难判断引用所指向的对象到底属于哪个类,故可用
instanceOf判断; - 若子类未重写父类方法,尽管子类拥有父类所有,但那些方法在根本上还是属于父类,因此子类调用的还是父类方法;
super并不代表父类引用,只是用于调用父类成员 \color{green}{并不代表父类引用,只是用于调用父类成员} 并不代表父类引用,只是用于调用父类成员。getClass()是 Object 类的 final 方法(不可重写),故super.getClass()等同于this.getClass(),返回的是当前对象所属类的 Class 对象。
9、关于序列化
参考笔记一,P1、P2.3。
9.1 什么是“序列化”?
序列化指将对象 转为字节序列、实现将对象持久化(永久保存)到磁盘、使对象能在网络 或进程间 传递的过程。
(注:实现序列化的类必须实现Serializable接口;若此类引用了其他类,则相应类也必须实现此接口。)
9.2 序列化特点
-
持久性。
将对象转为字节序列存于磁盘,即使JVM死机,对象仍然存于磁盘。当JVM宕机时,可以通过反序列化还原对象,并且,序列化的对象占据更小的磁盘空间; -
序列化的对象在网络上传输会更快捷、更安全;
-
可实现在进程间传递对象。
“进程间”是什么意思?因为无论程序复杂或简单,在启动时,JVM都只会创建一个进程,而进程间无法直接传输对象。
9.3 关于序列化ID
示例:
private static final long serialVersionUID = -5809782578272943999L;
这就是序列化ID,其在类加载时生成,用于作为类在JVM内存中的唯一标识。其作用是通过比较字节序列中的序列化ID和实体类中的序列化ID是否一致来判断是否为同一个类,即是否可反序列化,从而还原对象。
9.4 序列化/反序列化测试
“序列化”与“反序列化*”是一种实现对象持久化的概念,具体实现方法任意。如下示例中使用
ObjectOutputStream实现序列化,使用ObjectInputStream实现反序列化是其中一种实现方法。
1、序列化:将对象 Person 序列化到 Person.txt 文件中。
看下述代码:
@AllArgsConstructor
class Person implements Serializable {
private static final long serialVersionUID = -5809782578272943999L;
private Integer id;
private String name;
}
class TestSerializable {
public static void main(String[] args) throws Exception {
Person person = new Person(1001, "yuchen");
System.out.println(person);// 打印:Person(id=1001, name=yuchen)
// 序列化
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File("C:\\Users\\于辰\\Downloads\\新建文件夹\\Person.txt")));
oos.writeObject(person);
}
}
测试结果:
字节序列文件:

字节序列:

2、反序列化:将 Person.txt 文件中的字节序列 通过反序列化还原成 Person 对象。
看下述代码:
class TestSerializable {
public static void main(String[] args) throws Exception {
// 反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("C:\\Users\\于辰\\Downloads\\新建文件夹\\Person.txt")));
Person person = (Person) ois.readObject();
System.out.println(person);// 打印:com.neusoft.boot.Person@69d0a921
}
}
10、关于程序与数据库之间数据类型转换说明(基于JDBC)
10.1 数据存储(DML)
- String → DateTime,需使用类java.sql.Timestamp。
10.2 数据查询(select)
- DateTime → String,先通过
rs.getTimestamp()(rs是结果集ResultSet对象)获取Timestamp对象,再使用SimpleDateFormat类将其转为String。
11、关于数据类型转换
下述阐述需要计算不同位二进制的表示范围,引用博文【mysql知识点锦集】的第1项中的“求数据类型取值范围的计算通式”。虽然Java与Mysql属不同体系,但是数据类型的取值范围是相同的。因此,大家可以此博文作为参考。
参考笔记二,P65.1。
两个结论: \color{green}{两个结论:} 两个结论:
- 数据类型转换分为显式转换和隐式转换两种方式,显式转换需要强转。具体何种方式取决于转换前后类型所占字节数的大小。
int类型采用有符号二进制存储,char类型采用无符号二进制存储。
11.1 int → char
引用那篇博文中关于数据类型数值范围的计算通式:
![]()
int类型占4个字节,char类型占2个字节,先计算一下这两种类型的数值范围:
int类型数值范围:-2{8*4-1} ~ 2{8*4-1} - 1 =-2.147483648E9 ~ 2.147483647E9;(有符号二进制)char类型取值范围:-2{8*2-1} ~ 2{8*2-1} - 1 =-32768 ~ 32767;(有符号二进制)
注:这个取值范围是按照字节长度计算的。实际上,由于char类型对应 A S C L L 码 \color{blue}{ASCLL码} ASCLL码,ASCLL码是正数,故不能按照有符号二进制的方式进行计算。
char类型由16位无符号二进制表示,故char类型数值范围是:0 ~ 2{8*2} - 1 =0 ~ 65535。
字节长度:int > char,故int类型转为char类型属显式转换。但有一个 特例 \color{red}{特例} 特例:
当转为char类型的整型数据是常量,且数值在char类型的数值范围之内时,可隐式转换。
说明示例:
1、将数值在char类型取值–数值范围内的int常量转为char类型。
char c1 = -1;//----------A
char c2 = 65536//;-------B
char c3 = 0;//-----------C
char c4 = 65535;//-------D
char类型的数值范围是: 0 ~ 65535。故A、B编译报错,而C、D转换成功。
2、将int常量转为char类型。
int a1 = 100;
final int a2 = 100;
char c5 = a1;// 编译报错
char c6 = a2;// 转换成功
尽管100在char类型的取值范围内,但a1是变量,故编译报错;而a2以及举例1中的都是常量,故转换成功。
11.2 float与int
float类型与int类型都占4个字节,且都采用有符号二进制进行存储,但在float中,整数部分占8位,小数部分占23位。
因此,float类型的数值范围是:-2{8*1-1} ~ 2{8*1-1} - 1 = -128 ~ 127。即-128.0 ~ 127.999999...。
补充说明: \color{green}{补充说明:} 补充说明:
因为小数的二进制表示方法我暂未作研究,故此范围目前还不是很明确,仅供大家参考。
12、关于ORM
全称Object Relational Mapping(对象关系映射),指实体类与数据表一一对应,属性与字段一一对应,而实例/对象对应记录,即将对象“存入”数据表中。常用的ORM框架:mybatis、mybatis-plus、hibernate。
优点:
- 提高开发效率;
- 解耦合。如:客户需求变更,需要增删字段来实现功能,使用ORM框架,不用 sql 直接编码,能够像操作对象一样从数据库读取数据。
缺点:降低程序性能。
- 一般ORM框架系统都是多层的,系统层次多会降低程序性能。且ORM框架是完全面向对象,也会降低程序性能;
- ORM框架生成的 sql 语句一般很难写出高效的算法,只能先将对象提取到内存对象中(指
select到程序中),再进行过滤和加工,这会降低程序性能; - 在对象持久化时,ORM框架一般会持久化对象的所有属性,有时这是不需要的,这会降低程序性能。
注:“持久化”指将数据存储进数据库。
13、关于package
参考笔记二,P29.6。
- java 属跨平台语言,与操作系统无关,
package是用来组织源文件的一种虚拟文件系统; import的作用是引入,而不是拷贝,目的是告诉编译器编译时应去哪读取外部文件;- java 的包机制 与 IDE 无关;
- 同一包下的类可不使用
import而直接调用(不是指实例化时用全类名)。
14、关于 IPv4
关于 IPv4,相关类 → Inet4Address类。
参考笔记一,P75.2。
概述:
ipv4 由4部分组成,包含网络地址 和主机地址,每部分解释为一个字节。故都是0 ~ 255的整数。因此,ipv4 占4个字节(32位)。
分类:(注:a指网络地址,b指主机地址)
- A类:a 占前8位,b 占后24位,a 的最高位必须是
0。因此,范围是:0.0.0.0 ~ 127.255.255.255; - B类:a 占前16位,b 占后16位,a 的最高位必须是
10。因此,范围是:128.0.0.0 ~ 191.255.255.255; - C类:a 占前24位,b 占后8位,a 的最高位必须是
110。因此,范围是:192.0.0.0 ~ 223.255.255.255; - D类:暂未知,a 的最高位必须是
1110。因此,范围是:224.0.0.0 ~ .239.255.255.255; - E类:暂未知,a 的最高位必须是
1111。因此,范围是:240.0.0.0 ~ 255.255.255.255。
15、关于static
- 内部类的所有成员都不能声明为 \color{red}{内部类的所有成员都不能声明为} 内部类的所有成员都不能声明为
static。因为由static声明或定义的变量为所有拥有它的对象共享,而内部类属于外部类,故内部类的static变量为所有外部类的对象共享,这会导致内部类被提升为外部类、则内部类中的局部变量将无意义。除非是静态内部类; - 为什么不能在成员方法和类方法中定义类变量? \color{grey}{为什么不能在成员方法和类方法中定义类变量?} 为什么不能在成员方法和类方法中定义类变量?因为为类变量分配内存空间是在类加载第二过程的准备阶段,而成员方法和类方法是在类加载完成后再进行初始化,此时已不能再为类变量分配内存空间。
16、关于常量
16.1 关于赋初值
常量仅能在声明static int a = 10或构造器(包括:代码块、构造方法)内赋初值。
16.2 常将常量声明为static的原因
若没有static,则属于对象成员,则在每个对象实例化时都会创建一个副本,占据堆空间;而声明为static,则会在类加载时被加载进方法区的全局数据访问区中,即只有一个副本,节省空间。并且,声明为static,还可以在静态代码块中赋初值。
17、关于编译与解释
参考笔记二,P20。
什么是“编译”? \color{grey}{什么是“编译”?} 什么是“编译”?
“编译”是指将源代码一次性转换成目标程序的过程,编译只执行一次,故编译的着重点不是编译速度,而是目标程序的运行速度。因此,编译器一般都会尽可能多地集成优化技术,使生成的目标程序具有更高的执行速度。
特点: \color{red}{特点:} 特点:
- 对于相同的源代码,目标程序执行速度更快;
- 目标程序运行不需要编译器支持,在同类操作系统上使用灵活。
什么是“解释”? \color{grey}{什么是“解释”?} 什么是“解释”?
“解释”是指将源代码逐条转换并同时运行的过程,不会生成目标程序,故解释的着重点是解释速度。因此,解释在每次程序运行时都需要解释器和源代码,也不能集成太多的优化技术,这样会降低程序的运行速度。
特点: \color{red}{特点:} 特点:
- 由于解释不会生成目标程序,因此解释执行需要保留源代码,这样也便于程序的纠错和维护;
- 只要有解释器,源代码在任何操作系统皆可运行,可移植性强。
“编译”与“解释”的运用: \color{green}{“编译”与“解释”的运用:} “编译”与“解释”的运用:
高级语言按照执行方式分为 静态语言 \color{blue}{静态语言} 静态语言和 脚本语言 \color{purple}{脚本语言} 脚本语言。静态语言使用编译,如:C/C++、java;脚本语言使用解释,如:python、js、php。
在实际运用中,会将两者混合使用,以实现在保证程序逐条运行的同时保留目标程序,因为程序逐条运行能大大提升程序运行速度,保留目标程序便于程序纠错和维护。
本文持续更新中。。。