【Kafka】如何保证消息可靠性(ack机制)
文章目录
- 1. 消息可靠性
- 2. 发送端如何保证高可用性
-
- 2.1 ack参数解释
- 2.2 ack详细流程
- 参考
1. 消息可靠性
什么是消息可靠性?就是如何确保消息一定能发送到服务器进行存储,并且发生宕机等异常场景,能够从备份数据中恢复。
消息的可靠性需要从2个方面看待消息可靠性
- 第一,发送端能否保证发送的消息是可靠的
- 第二,接收端能否可靠的消费消息
消息发送端:
通过ack机制,定义不同的策略。
消息消费端:
如果消费这边配置的是自动提交,万一消费到数据还没处理完,就自动提交offset了,但是此时你consumer直接宕机了,未处理完的数据丢失了,下次也消费不到了。
消费端就是靠offset来保证的。
2. 发送端如何保证高可用性
Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。通过调节其副本相关参数,可以使得Kafka在性能和可靠性之间运转的游刃有余。Kafka从0.8.x版本开始提供partition级别的复制,replication的数量可以在$KAFKA_HOME/config/server.properties中配置。
Kafka中消息是以topic进行分类的,生产者通过topic向Kafka broker发送消息,消费者通过topic读取数据。然而topic在物理层面又能以partition为分组,一个topic可以分成若干个partition。Kafka中的消息以顺序的方式存储在文件中。
Kafka中的topic的partition有N个副本(replicas)。N个replicas中,其中一个replica为leader,其他都为follower, leader处理partition的所有读写请求,follower定期地去复制leader上的数据。
如果leader发生故障或挂掉,一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader,或者说follower追赶leader数据。
因此在谈到消息可靠性时,一般会想到Kafka的ack机制,而ack机制核心就是和副本同步相关。
2.1 ack参数解释
ack机制核心就是和副本同步相关。

当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别:
-
1(默认):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果leader宕机了,则会丢失数据。
-
0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
此时retries 参数失效,以为客户端无法判断是否失败,也就无法做重试。
-
-1或all:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当ISR中只有leader时,这样就变成了acks=1的情况。
-1或all都可以。
具体的配置为:
Request.required.acks=-1 (全量同步确认,强可靠性保证)
Request.required.acks = 1(leader 确认收到, 默认)
Request.required.acks = 0 (不确认,但是吞吐量大)
消息的发送分为2步:
- 一个是从producer发送到leader角色的broker中
- 第二是从leader同步至follower中
2.2 ack详细流程
如果想实现 kafka 配置为 CP(Consistency & Partition tolerance) 系统, 配置需要如下:
request.required.acks=-1
min.insync.replicas = ${N/2 + 1} '设置有效follower数量,ISR'
unclean.leader.election.enable = false '默认值为false,如果ISR内follower都挂掉,不允许非ISR内follower参与选举'
如果没有设置ack=-1,那么无法保证高可用性。
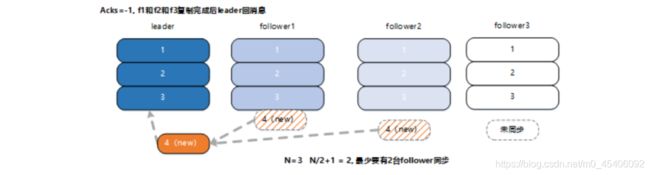
如图所示 ,在 acks=-1 的情况下,新消息只有被 ISR 中的所有 follower(f1 和 f2, f3) 都从 leader 复制过去才会回 ack, ack 后,无论那种机器故障情况(全部或部分), 写入的 msg4,都不会丢失, 消息状态满足一致性 C 要求。
min.insync.replicas 参数用于保证当前集群中处于正常同步状态的副本 follower 数量,当实际值小于配置值时,集群停止服务。如果配置为 N/2+1, 即多一半的数量,则在满足此条件下,通过算法保证强一致性。当不满足配置数时,牺牲可用性即停服。
异常情况下,leader 挂掉,此时需要重新从 follower 选举 leader。可以为 f2 或者 f3。
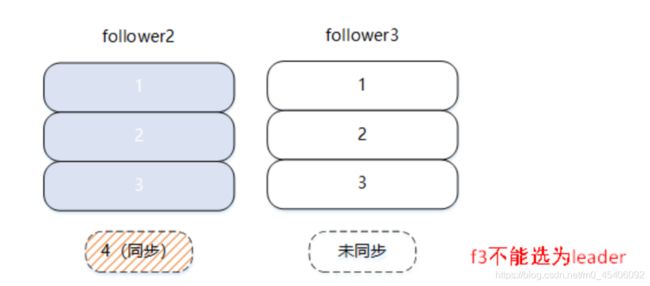
如果选举 f3 为新 leader, 则可能会发生消息截断,因为 f3 还未同步 msg4 的数据。Kafka 的通 unclean.leader.election.enable 来控制在这种情况下,是否可以选举 f3 为 leader。旧版本中默认为 true,在某个版本下已默认为 false,避免这种情况下消息截断的出现。
通过 ack 和 min.insync.replicas 和 unclean.leader.election.enable 的配合,保证在 kafka 配置为 CP 系统时,要么不工作,要么得到 ack 后,消息不会丢失且消息状态一致。
min.insync.replicas 参数默认值为 1,即满足高可用性,只要有 1 台能工作即可。但此时可工作的 broker 状态不一定正确(可以想象为啥?很简单,影响投票算法,3个人投票,2个人投赞成票即可超过一半票数1.5 ,一个人怎么投?)
如果想实现 kafka 配置为 AP(Availability & Partition tolerance)系统:
request.required.acks=1
min.insync.replicas = 1
unclean.leader.election.enable = false
当配置为 acks=1 时,即 leader 接收消息后回 ack,这时会出现消息丢失的问题:如果 leader 接受到了 第 4 条消息,此时还没有同步到 follower 中,leader 机器挂了,其中一个 follower 被选为 leader, 则 第 4 条消息丢失了。当然这个也需要 unclean.leader.election.enable 参数配置为 false 来配合。但是 leader 回 ack 的情况下,follower 未同步的概率会大大提升。
通过 producer 策略的配置和 kafka 集群通用参数的配置,可以针对自己的业务系统特点来进行合理的参数配置,在通讯性能和消息可靠性下寻得某种平衡,决定是AP还是CP。
参考
kafka 同步提交 异步_简单理解 Kafka 的消息可靠性策略