算法通关村第一关—链表高频面试题(白银)
链表高频面试题
一、五种方法解决两个链表的第一个公共子节点的问题
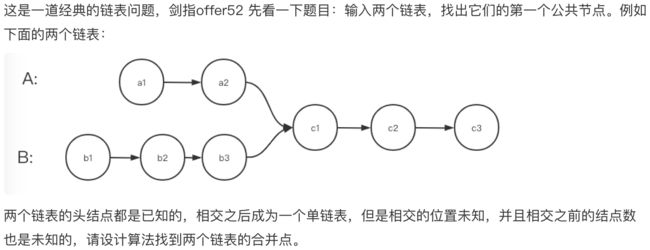
面试 02.07.链表相交
1.首先想到的是暴力解,将第一个链表中的每一个结点依次与第二个链表的进行比较,当出现相等的结点指针时,即为相交结点。虽然简单,但是时间复杂度高,排除
2.Hash,先将第一个链表元素全部存到Map里,然后一边遍历第二个链表,一边检测当前元素是否在Hash中,如果两个链表有交点,那就找到了。OK,第二种方法出来了。
3.既然Hash可以,那集合呢?和Hash一样用,也能解决,OK,第三种方法出来了。
4.队列和栈呢?这里用队列没啥用,但用栈呢?现将两个链表分别压到两个栈里,之后一边同时出栈,一边比较出栈元素是否一致,如果一致则说明存在相交,然后继续找,最晚出栈的那组一致的节点就是要找的位置,于是就有了第四种方法。
除此上面的方法,还有两种比较巧妙的方法,比较巧妙的方法我们放在第六小节看,这里我们先看两种基本的方式。
1.1 哈希表和集合
public ListNode findFirstCommonNodeBySet(ListNode headA,ListNode headB){
Set<ListNode> set = new HashSet<>();
while (headA !null){
set.add(headA);
headA = headA.next;
}
while (headB != null){
if(set.contains(headB)) return headB;
headB = headB.next;
}
return null;
}
1.2 使用栈
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Stack<ListNode> stackA = new Stack<>();
Stack<ListNode> stackB = new Stack<>();
while(headA != null){
stackA.push(headA);
headA = headA.next;
}
while(headB != null){
stackB.push(headB);
headB = headB.next;
}
ListNode node = null;
while(stackA.empty() == false && stackB.empty() == false){
node = stackA.pop();
if(node != stackB.pop()) return node.next;
}
return node;
}
}
二、判断链表是否存在回文序列

234.回文链表
【算法萌新闯力扣】:回文链表-CSDN博客
方法1:将链表元素都赋值到数组中,然后可以从数组两端向中间对比。这种方法会被视为逃避链表,面试不能这么干。
方法2:将链表元素全部压栈,然后一边出栈,一边重新遍历链表,一边比较两者元素值,只要有一个不相等,那就不是。
方法3:优化方法2,先遍历第一遍,得到总长度。之后一边遍历链表,一边压栈。到达链表长度一半后就不再压栈,而是一边出栈,一边遍历,一边比较,只要有一个不相等,就不是回文链表。这样可以节省一半的空间。
方法4:优化方法3:既然要得到长度,那还是要遍历一次涟表才可以,那是不是可以一边遍历一边全部压栈,然后第二遍比较的时候,只比较一半的元素呢?也就是只有一半的元素出栈,链表也只遍历一半,当然可以。
方法5:反转链表法,先创建一个链表newList,将原始链表oldList的元素值逆序保存到newList中,然后重新一边遍历两个链表,一遍比较元素的值,只要有一个位置的元素值不一样,就不是回文链表。
方法6:优化方法5,我们只反转一半的元素就行了。先遍历一遍,得到总长度。然后重新遍历,到达一半的位置后不再反转,就开始比较两个链表。
方法7:优化方法6,我们使用双指针思想里的快慢指针,fast一次走两步,slow一次走一步。当fast到达表尾的时候,slow正好到达一半的位置,那么接下来可以从头开始逆序一半的元素,或者从slow开始逆序一半的元素,都可以。
方法8:在遍历的时候使用递归来反转一半链表可以吗?当然可以,再组合一下我们还能想出更多的方法,
解决问题的思路不止这些了,此时单纯增加解法数量没啥意义了。
上面这些解法中,各有缺点,实现难度也不一样,有的甚至算不上一个独立的方法,这么想只是为了开拓思路、举一反三。我们选择最佳的两种实现,其他方法请同学自行写一下试试。
2.1数组
class Solution {
public boolean isPalindrome(ListNode head) {
List<Integer> list = new ArrayList<>(); //创建list集合
ListNode node = head; //创建结点node指向头结点
while(node != null){ //当node不为空时
list.add(node.val); //将该结点添加到集合中
node = node.next; //node指向下一个结点
}
int left = 0, right = list.size() - 1; //创建左右指针,分别指向集合到开头和结尾
while(left < right){ //循环条件是两个指针相遇前
if(list.get(left) != list.get(right)) return false; //两个指针对应的数如果不相等,则不是回文,返回false
left++; //左指针右移
right--; //右指针左移
}
return true;//没有false的情况,返回true
}
}
2.2 使用栈
这里看一下比较基本的全部压栈的解法。将链表元素全部压栈,然后一边出栈,一边重新遍历链表,一边比较,只要有一个不相等,那就不是回文链表了,代码:
class Solution {
public boolean isPalindrome(ListNode head) {
Stack<Integer> stack = new Stack<>(); //创建一个栈
ListNode node = head; //创建node结点指向头结点
while(node != null){ //node不为空时
stack.push(node.val);//把node结点的值压入栈中
node = node.next; //node指向下一个结点
}
node = head; //node重新指向头结点
while(node != null){ //node不为空时
if(stack.pop() != node.val) return false; //栈顶元素出栈,如果栈顶元素与node结点的值不相等,返回false
node = node.next; //node指向下一个结点
}
return true;//没有false的情况,返回true
}
}
三、合并有序链表
3.1 合并两个有序链表
LeetCode21将两个升序链表合并为一个新的升序链表并返回,新链表是通过拼接给定的两个链表的所有节点组成的。
本题虽然不复杂,但是是很多题目的基础,解决思路与数组一样,一般有两种。一种是新建一个链表,然后分别遍历两个链表,每次都选最小的结点接到新链表上,最后排完。另外一个就是将一个链表结点拆下来,逐个合并到另外一个对应位置上去。这个过程本身就是链表插入和删除操作的拓展,难度不算大,这时候代码是否优美就比较重要了。
【算法萌新闯力扣】:合并两个有序链表-CSDN博客
21.合并两个有序链表
下面的代码是新建链表的方式
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
ListNode head = new ListNode(-1); //创建一个头结点,赋值为-1,值是随便赋的。头结点主要是为了方便最后返回链表
ListNode node = head; //创建结点node指向head,之后的操作都由node指向,head就一直处在链表的头
while(list1 != null && list2 != null){ //循环条件是两个链表都不为空时
if(list1.val > list2.val) {//如果表1的值大于表2
node.next = list2; //把表2的值赋给node.next,注意不是node,赋给node的话,head就没意义了
list2 = list2.next; //list2指向下一个结点
}
else{ //与上面同理,把list2换成list1
node.next = list1;
list1 = list1.next;
}
node = node.next; //node指向下一个结点
}
if(list1 == null) node.next = list2;//循环结束证明还有至多一个表不为空,让node.next指向不为空的表
else node.next = list1;
return head.next; //返回head.next,注意:head是-1,不是我们要返回的
}
}
3.2 合并k个链表
合并k个链表,有多种方式,例如堆、归并等等。如果面试遇到,我倾向先将前两个合并,之后再将后面的逐步合并进来,这样的的好处是只要将两个合并的写清楚,合并K个就容易很多,现场写最稳妥:
public ListNode mergeKLists(ListNode[]lists){
ListNode res = null;
for (ListNode list:lists){
res = mergeTwoLists(res,list);
}
return res;
}
3.3 合并链表变形

力扣:1669 合并两个链表
题目思路:找到list1的a、b结点和list2的尾结点,然后就按照上图进行拼接
class Solution {
public ListNode mergeInBetween(ListNode list1, int a, int b, ListNode list2) {
ListNode head = new ListNode(-1);
head.next = list1;
ListNode nodeA = list1, nodeB = list1;
int sum = 0;
while(nodeA != null && sum < a - 1){
nodeA = nodeA.next;
sum++;
}
sum = 0;
while(nodeB != null && sum <= b){
nodeB = nodeB.next;
sum++;
}
ListNode nodetail2 = list2;
while(true){
if(nodetail2.next == null)break;
else nodetail2 = nodetail2.next;
}
nodeA.next = list2;
nodetail2.next = nodeB;
return head.next;
}
}
这里需要留意题目中是否有开闭区间的情况,例如如果是从a到b,那就是闭区间a,b]。还有的会说一个开区间(a,b),此时是不包括a和b两个元素,只需要处理a和b之间的元素就可以了。比较特殊的是进行分段处理的时候,例如K个一组处理,此时会用到左闭右开区间,也就是这样子[a,b),此时需要处理a,但是不用处理6,b是在下一个区间处理的。此类题目要非常小心左右边界的问题。
四、双指针专题
4.1 寻找中间结点
LeetCode876.链表的中间结点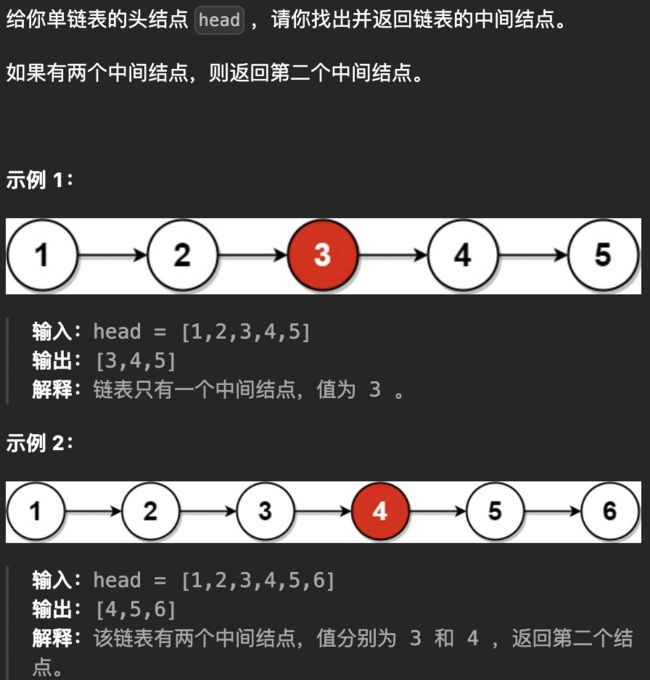
这个问题用经典的快慢指针可以轻松搞定,用两个指针slow与fast一起
遍历链表。slow一次走一步,fast一次走两步。那么当fast到达链表的
末尾时,slow必然位于中间。
教官提出的思考:这里还有个问题,就是偶数的时候该返回哪个,例如上面示例2返回的是4,而3貌似也可以,那该使用哪个呢?如果我们使用标准的快慢指针就是后面的4,而在很多数组问题中会是前面的3,想一想为什么会这样
class Solution {
public ListNode middleNode(ListNode head) {
ListNode slow = head,fast = head;
while(fast!= null && fast.next != null){
fast = fast.next.next;
slow = slow.next;
}
return slow;
}
}
4.2 寻找倒数第k个元素
经典的快慢指针问题
输入一个链表,输出该链表中倒数第k个节点。本题从1开始计数,即链表的尾节点是倒数第1个节点
示例
给定一个链表:1->2->3->4->5,和 k = 2.
返回链表4->5.
先将fast遍历到第k+1个节点,slow仍然指向链表的第1个节点,此时指针fast和slow二者之间刚好间隔k个节点。之后两个指针同步向右走,当fast走向链表的尾部空节点时,slow刚好指向链表的倒数第k个节点
这里需要特别注意链表的长度可能小于k,寻找k位置的时候必须判断fast算法为null,这是本题的关键问题之一
public ListNode getKthFromEnd(ListNode head,int k){
ListNode fast = head;
ListNode slow = head;
while (fast != null & k > 0){
fast fast.next;
k--;
}
while (fast != null){
fast = fast.next;
slow = slow.next;
return slow;
}
}
参考力扣题:面试题02.02.返回倒数第k个节点
class Solution {
public int kthToLast(ListNode head, int k) {
ListNode fast = head, slow = head;
int sum = 1;
while(sum < k + 1){
fast = fast.next;
sum++;
}
while(fast != null){
fast = fast.next;
slow = slow.next;
}
return slow.val;
}
}
4.3 旋转链表

61.旋转链表
这个题有多种解决思路,首先想到的是根据题目要求硬写,但是这样比较麻烦,也容易错。这个题是否在数组里见过类似情况?
观察链表调整前后的结构,我们可以发现从旋转位置开始,链表被分成了两条,例如上面的{1,2,3}和{4,5},这里我们可以参考上一题的倒数K的思路,找到这个位置,然后将两个链表调整一下重新接起来就行了。具体怎么调整呢?脑子里瞬间想到两种思路:
第一种是将整个链表反转变成{5,4,3,2,1},然后再将前K和N-K两个部分分别反转,也就是分别变成了{4,5}和{1,2,3},这样就轻松解决了。这个在后面学习了链表反转之后,请读者自行解决。
第二种思路就是先用双指针策略找到倒数K的位置,也就是{1,2,3}和{4,5}两个序列,之后再将两个链表拼接成{4,5,1,2,3}就行了。具体思路是:
因为k有可能大于链表长度,所以首先获取一下链表长度Ien,如果然后k=k%len,如果k==0,则不用旋转,直接返回头结点。否则:
1.快指针先走k步。
2.慢指针和快指针一起走。
3.快指针走到链表尾部时,慢指针所在位置刚好是要断开的地方。把快指针指向的节点连到原链表头部,慢指针指向的节点断开和下一节点的联系。
4.返回结束时慢指针指向节点的下一节点。
class Solution {
public ListNode rotateRight(ListNode head, int k) {
if(head == null || k == 0) return head; //排除特殊情况,如果不排除,下面的k%sum中会出现sum==0的报错
ListNode fast = head, slow = head; //创建快慢指针
int sum = 0;
ListNode test = head;
while(test != null){ //利用test来遍历整个链表
sum++; //sum统计链表的长度
test = test.next;
}
if(k % sum == 0)return head; //k是sum的整数倍,反转完结果与原链表相同,直接返回原链表
int len = k % sum; //计算出最终要分开的节点
while(len > 0){ //先让快指针领先慢指针len个结点
fast = fast.next;
len--;
}
while(fast.next != null){ //两个指针同时移动,当快指针到尾结点时,慢指针到达分开的位置
fast = fast.next;
slow = slow.next;
}
ListNode newhead = slow.next; //三步操作,让慢指针后面的部分拼接到头结点
slow.next = null;
fast.next = head;
return newhead; //此时原本慢指针到下一个结点变成头结点,返回它
}
}
五、删除链表元素专题
5.1 删除特定结点

对于删除,我们注意到首元素的处理方式与后面的不一样。为此,我们可以先创建一个虚拟节点dummyHead,使其指向head,也就是dummyHead.next=head,这样就不用单独处理首节点了。
完整的步骤是:
1.我们创建一个虚拟链表头dummyHead,使其next指向head。
2.开始循环链表寻找目标元素,注意这里是通过cur.next.val来判断的。
3.如果找到目标元素,就使用cur.next=cur.next.next;来删除。
4.注意最后返回的时候要用dummyHead.next,而不是dummyHead。
代码实现过程:
public ListNode removeElements(ListNode head,int val){
ListNode dummyHead = new ListNode(0);
dummyHead.next = head;
ListNode cur = dummyHead;
while(cur.next != null){
if(cur.next.val == val) cur.next = cur.next.next;
else cur = cur.next;
}
return dummyHead.next;
}
5.2 删除倒数第n个结点
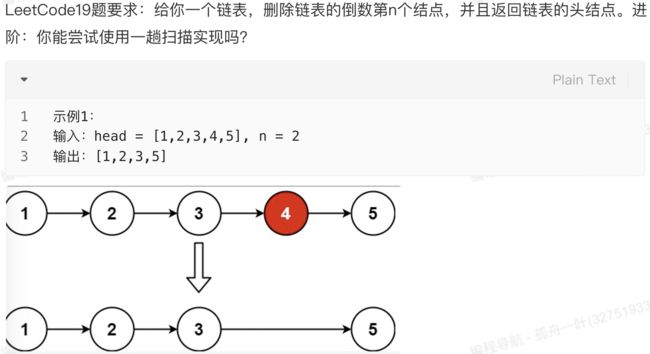
我们前面说过,遇到一个题目可以先在脑子里快速过一下常用的数据结构和算法思想,看看哪些看上去能解决问题。为了开拓思维,我们看能怎么做:
第一种方法:先遍历一遍链表,找到链表总长度L,然后重新遍历,位置L-N+1的元素就是我们要删的。
第二种方法:貌似栈可以,先将元素全部压栈,然后弹出第N个的时候就是我们要的是不?OK,又搞定一种方法。
第三种方法:我们前面提到可以使用双指针来寻找倒数第K,那这里同样可以用来寻找要删除的问题。
上面三种方法,第一种比较常规,第二种方法需要开辟一个O(n)的空间,还要考虑栈与链表的操作等,不中看也不中用。第三种方法一次遍历就行,用双指针也有逼格。接下来我们详细看一下第一和三两种。
方法1:计算链表长度
首先从头节点开始对链表进行一次遍历,得到链表的长度L。随后我们再从头节点开始对链表进行一次遍历,当遍历到第L-n+1个节点时,它就是我们需要删除的节点。代码如下:
public ListNode removeNthFromEnd (ListNode head,int n){
ListNode dummy = new ListNode(0);
dummy.next = head;
int length = getLength(head);
ListNode cur = dummy;
for (int i = 1;i < length - n + 1;++i) cur = cur.next;
cur.next = cur.next.next;
ListNode ans = dummy.next;
return ans;
}
public int getLength(ListNode head){
int length = 0;
while(head != null){
length++;
headhead.next;
}
return length;
}
方法二:双指针
我们定义first和second两个指针,first先走N步,然后second再开始走,当first:走到队尾的时候,second就是要的节点。代码加下:
public ListNode removeNthFromEnd(ListNode head,int n){
ListNode dummy = new ListNode(0);
dummy.next = head;
ListNode first = head;
ListNode second = dummy;
for(int i = 0;i < n; ++i) first = first.next;
while(first != null){
first = first.next;
second = second.next;
}
second.next = second.next.next;
ListNode ans = dummy.next;
return ans;
}
5.3 删除重复元素
LeetCode83存在一个按升序排列的链表,请你删除所有重复的元素,使每个元素只出现一次。
LeetCode82存在一个按升序排列的链表,请你删除链表中所有存在数字重复情况的节点,只保留原始链表中没有重复出现的数字。
两个题其实是一个,区别就是一个要将出现重复的保留一个,一个是只要重复都不要了,处理起来略有差别。
LeetCode1836是在82的基础上将链表改成无序的了,难度要增加不少,感
兴趣的同学请自己研究一下。
5.3.1 重复元素保留一个
LeetCode83存在一个按升序排列的链表,给你这个链表的头节点head,请你删除所有重复的元素,使每个元素只出现一次。返回同样按升序排列的结果链表。
public ListNode deleteDuplicates(ListNode head){
if (head == null) return head
ListNode cur = head;
while (cur.next != null){
if (cur.val == cur.next.val)cur.next = cur.next.next;
else cur = cur.next;
}
return head
}
5.3.2重复元素都不要
LeetCode82:这个题目的要求与83的区别仅仅是重复的元素都不要了。例如:
当一个都不要时,链表只要直接对cur.next以及cur.next.next两个node进行比较就行了,这里要注意两个node可能为空,稍加判断就行了。
public ListNode deleteDuplicates(ListNode head){
if((head == null) return head;
ListNode dummy = new ListNode(0,head);
ListNode cur = dummy;
while(cur.next != null && cur.next.next != null){
if(cur.next.val == cur.next.next.val){
int x = cur.next.val;
while(cur.next != null && cur.next.val == x)
cur.next = cur.next.next;
}
else curcur.next;
}
return dummy.next;
}
六、再论第一个公共子结点问题
在我们第一题寻找公共子节点部分,我们看到使用Hash或者栈是可以解决问题的,但是这样可能只能得80分,因为这不一定是面试官想要的答案,为什么呢?因为不管你使用栈还是集合都需要开辟一个O(n)的空间,那如果只使用一两个变量能否解决问题呢?
答案是可以的,这里我们就看一下另外两种解决方式。
6.1 拼接两个字符串
先看下面的链表A和B:
A:0-1-2-3-4-5
B:a-b-4-5
如果分别拼接成AB和BA会怎么样呢?
AB:0-1-2-3-4-5-a-b-4-5
BA:a-b-4-5-0-1-2-3-4-5
我们发现拼接后从最后的4开始,两个链表是一样的了,自然4就是要找的节点,所以可以通过拼接的方式来寻找交点。这么做的道理是什么呢?我们可以从几何的角度来分析。我们假定A和B有相交的位置,以交点为中心,可以将两个链表分别分为left_a和right_a,left_b和right_b这样四个部分,并且right_a和right_b是一样的,这时候我们拼接AB和BA就是这样的
结构: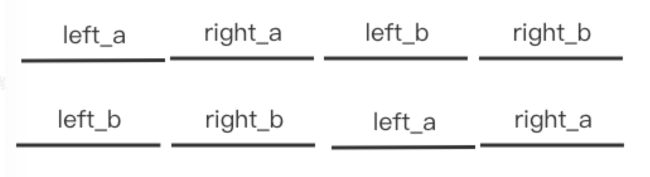
我们说right a和right b是一样的,那这时候分别遍历AB和BA是不是从某个位置开始恰好就找到了相交的点了?
这里还可以进一步优化,如果建立新的链表太浪费空间了,我们只要在每个链表访问完了之后,调整到一下链表的表头继续遍历就行了,于是代码就出来了:
这里很多人会对为什么循环体里 if(p1!=p2) 这个判断有什么作用,我们在代码后面解释
public ListNode findFirstCommonNode(ListNode pHead1, ListNode pHead2){
if (pHead1 == null || pHead2 == null) return null;
ListNode p1 = pHead1;
ListNode p2 = pHead2;
while(p1!= p2){
p1=p1.next;
p2=p2.next;
if(p1!=p2){
//一个链表访问完了就跳到另外一个链表继续访问
if(p1==null) p1=pHead2;
if(p2==null) p2=pHead1;
}
return p1;
}
接下来我们解释一下,循环体里为什么需要加一个判断if(p1!=p2)。简单来说,如果序列不存在交集的时候陷入死循环,例如list1是1,2,3,list2是4,5,很明显,如果不加判断,list1和Iist2会不断循环,出不来。
6.2 差和双指针
我们再看另一个使用差和双指针来解决问题的方法。假如公共子节点一定存在第一轮遍历,假设La长度为L1,Lb长度为L2.则 |L2-L1| 就是两个的差值。第二轮遍历,长的先走|L2-L1|,然后两个链表同时向前走,结点一样的时候就是公共结点了。
public ListNode findFirstCommonNode(ListNode pHead1,ListNode pHead2){
if (pHead1 == null || pHead2 == null) return null;
ListNode current1 = pHead1;
ListNode current2 = pHead2;
int l1 = 0, l2 = 0;
//分别统计两个链表的长度
while(current1 != null){
current1 = current1.next;
l1++;
}
while(current2 != null){
current2 = current2.next;
l2++;
}
current1 = pHead1;
current2 = pHead2;
int sub = l1 > l2 ? l1 - l2 : l2 - l1;
//长的先走sub步
if(l1 > l2){
int a = 0;
while(a < sub){
current1 = current1.next;
a++;
}
}
if(l1 < l2){
int a = 0;
while(a < sub){
current2 = current2.next;
a++;
}
}
//同时遍历两个链表
while(current2!=current1){
current2=current2.next;
currentl=current1.next;
return current1;