数据库导入导出工具 BatchTool 介绍
性能对比
性能实验中,使用到的软件、版本以及系统资源如下表所示:

测试表
测试表为 TPC-H 规格的lineitem表,共5998万行,导出成单个csv文件大小为7.4G。
CREATE TABLE `lineitem` (
`l_orderkey` bigint(20) NOT NULL,
`l_partkey` int(11) NOT NULL,
`l_suppkey` int(11) NOT NULL,
`l_linenumber` bigint(20) NOT NULL,
`l_quantity` decimal(15,2) NOT NULL,
`l_extendedprice` decimal(15,2) NOT NULL,
`l_discount` decimal(15,2) NOT NULL,
`l_tax` decimal(15,2) NOT NULL,
`l_returnflag` varchar(1) NOT NULL,
`l_linestatus` varchar(1) NOT NULL,
`l_shipdate` date NOT NULL,
`l_commitdate` date NOT NULL,
`l_receiptdate` date NOT NULL,
`l_shipinstruct` varchar(25) NOT NULL,
`l_shipmode` varchar(10) NOT NULL,
`l_comment` varchar(44) NOT NULL,
PRIMARY KEY (`l_orderkey`,`l_linenumber`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;数据导出
测试结果

说明:mysqldump 支持导出成csv文件,但是依赖了服务端 MySQL 的select ... into outfile能力,而本文使用的云数据库不开放该功能,因此这里仅测试 mysqldump 原生的导出成sql文件的效率。
mysqldump 导出数据为 sql 文件会自动把多行数据拼接成一条 batch insert 语句,该语句的大小是由参数 net-buffer-length 控制的,默认大小为 1MB;如果想提升后续导入的性能,可以适当调大该值。
BatchTool 在导入 PolarDB-X 的分布式表时,性能比起 mysqldump 的方式明显提升,这是因为 BatchTool 适配了 PolarDB-X 分区表,在获取了逻辑表的元数据后,可以同时建立多条连接并行导出底层存储的物理表,充分利用网络带宽。
数据导入
测试结果

说明:每轮导入测试都是新建一张空表进行导入。
- source 导入 sql 文件:
使用 source 导入 sql 文件的整个过程是串行执行的,但由于 mysqldump 在导出成 sql 文件的时候已经做好了 batch insert 语句的拼接,因此导入效率不会显得太低。

- load data 导入 csv 文件:
在 MySQL 中,尽管 load data 也是单线程执行的,但其执行效率还是远远高于 source 导入 sql 文件,因为 load data 只需要在网络传输文本文件,在 MySQL 侧执行的时候也不需要经历 sql 的解析与优化流程。要进一步提升性能,则需要手动切分文件,开启多条数据库连接并行地进行数据库的导入。

但是在 PolarDB-X 中,load data 要相对更慢是因为文本流需要在计算节点上计算好路由后,再拼接成 batch insert 语句下发到存储节点执行,无法利用 MySQL 原生 load data 协议的高性能实现,因此性能相对较低。
- BatchTool 导入 csv 文件:
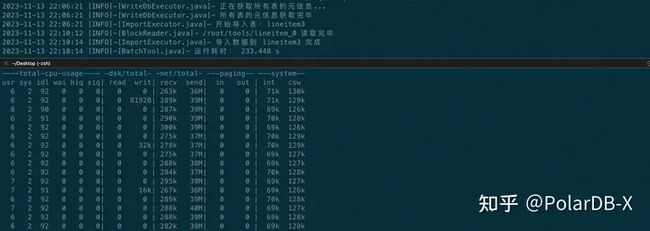
从系统监控可以看到,BatchTool 导入 csv 的网络发送带宽可以达到39MB/s,是 load data 的三倍以上。这是因为 BatchTool 基于生产者消费者模型,支持并发地读取单个文件、然后并发地发送 batch insert 语句至数据库端,充分利用压测机上的硬件资源、提升导入数据时的吞吐量。
实践场景
除了常规的并行导入导出数据之外,BatchTool 还支持很多数据迁移的场景生态功能。下面将结合不同的实践场景,介绍一下 BatchTool 的使用方法以及各种内置模式的参数。
数据库连接
BatchTool 支持兼容 MySQL 协议的各类数据库的导入导出。连接数据库的参数为-h (数据库主机)-  (端口号)-u(用户名)- (密码) -D $(目标数据库)。在此基础上,还支持连接 loadbalance 地址,例如:-lb true -h "host1:3306,host2:3306" -uroot。
(端口号)-u(用户名)- (密码) -D $(目标数据库)。在此基础上,还支持连接 loadbalance 地址,例如:-lb true -h "host1:3306,host2:3306" -uroot。
说明:以下将省略数据库连接的相关参数,仅展示与功能相关的参数设置。
整库迁移

BatchTool 支持一次性导入或导出整个数据库,包括所有表结构与表数据。 如果一个库下有很多张表(例如上千张表),那么此时基于 mysqldump 导出表结构、然后再执行 source 来进行表结构的迁移效率就会很低,因为该过程是完全单线程的。
而 BatchTool 支持在读取表结构sql文件的同时,并行地执行 DDL建表语句,从而提升效率。
当命令行参数指定了-t $(表名)时,为导入或导出表;若未加入该参数,此时即为整库的导入或导出模式。
元数据对应的命令行参数为-DDL $(迁移模式),迁移模式有三种:
- NONE:不迁移表结构(默认值)
- ONLY:仅迁移表结构,不迁移数据
- WITH:迁移表结构和数据
例如将导出 tpch 库中所有表的表结构:-D tpch -o export -DDL only。
导出文件切分

BatchTool 支持指定导出文件的数量或者单个文件的最大行数。 对于单机 MySQL,BatchTool 默认会将一张表导出成一个文件;对于分布式数据库 PolarDB-X,BatchTool 默认会将一张表下的每个物理分表各导出成一个文件,也就是文件数等于分片数。在此基础上,还有两个参数可以影响导出的文件数量:
- -F $(文件数量):固定导出的文件数量,会按照表的总数据量均匀切分
- -L $(最大行数):指定单个文件的最大行数,当单个文件的行数达到这个限制时,会开启一个新的文件继续写入
例如将 tpch 库中的每张表都分别导出为单独的一个 csv 文件:-D tpch -o export -s , -F 1。
指定列导入导出

BatchTool 支持指定表的部分列进行导入或者导出。 对应的命令行参数为-col "$(分号分隔的列名)",例如指定导出 customer 表的 c_name、c_address 和 c_phone 列,使用逗号分隔,同时文件第一行输出字段名:-o export -t customer -col "c_name;c_address;c_phone" -s , -header true。
文件加密

BatchTool 支持在导出文件时流式地输出为加密后的密文数据,避免导出明文数据后再手动进行加密的操作;也支持直接读取加密后的文件进行数据导入(需要提供正确的密钥),避免重复解密操作。目前支持两种加密算法:
- AES-CBC
- SM4-ECB
对应的命令行参数为-enc (加密算法)−  (密钥)。例如使用 AES算法加密导出 customer表的数据为一个文件,指定密钥为“admin123456”:-o export -s , -t sbtest1 -enc AES -key admin123456 -F 1。
(密钥)。例如使用 AES算法加密导出 customer表的数据为一个文件,指定密钥为“admin123456”:-o export -s , -t sbtest1 -enc AES -key admin123456 -F 1。
文件压缩
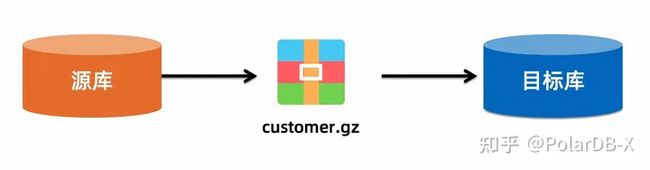
BatchTool 支持在导出文件时流式地输出为压缩文件,减少空间占用;也支持直接读取压缩文件导入数据,避免重复解压数据的操作。 对应的命令行参数为-comp $(压缩算法),例如:
1、将 customer 表导出为 GZIP 压缩文件的,字段分隔符为逗号(,):-o export -t customer -s , -comp GZIP
2、将 customer-data 目录下所有 GZIP 压缩文件导入到表 customer_2 中,字段分隔符为逗号(,):-o import -t customer -s , -comp GZIP -dir data-test
文件格式

BatchTool 支持以下几种文件格式的导入导出:
- CSV(指定字符分隔,文本文件)
- XLS、XLSX(Excel表格,二进制文件)
- ET(WPS表格,二进制文件)
对应的命令行参数为-format $(文件格式),例如将 customer 表导出为 XLSX 格式的表格:-o export -t customer -format XLSX。
数据脱敏

很多时候导出的表中可能会包含敏感数据,例如姓名、身份证号码、手机号、邮箱等个人信息,此时需要通过一定的算法将敏感数据进行加工处理、模糊化,使得数据无法识别或还原,从而保护数据安全、防止数据泄露;
这个过程也叫做数据脱敏。 BatchTool 集成了简单的数据脱敏功能,通过简单配置,即可在导出表数据的同时对指定的字段值进行脱敏加工,然后输出到文件。BatchTool 支持的脱敏算法包括如下四种:
- 掩码:掩码脱敏一般是对于字符串型数据采用特殊字符(*等)代替真值,常见于手机号、身份证号等字段;
- 加密:(对称)加密是一种特殊的可逆脱敏方法,使用指定加密算法以及密钥对敏感字段进行加密,对于没有密钥的低权限用户只看到无意义的密文数据,而在一些特殊场景需求下,也能通过密钥进行解密从而访问原始数据;
- 哈希摘要:通过哈希计算摘要值的方法常用于字符串型数据,比如把用户名“PolarDB-X”的字符串替换为“d7f19613a15dcf8a088c73e2c7e9b856”,保护用户隐私,并且还可以指定加盐来避免哈希值的破解;
- 取整:取整的脱敏方法在保持了数据的安全性的同时保证了范围的大致真实性,比如将日期字段从原始值“2023-11-11 15:23:41”取整为“2023-11-11 15:00:00”进行输出。
对应的命令行参数为-mask $(脱敏算法配置)。以 TPC-H 数据集的 cusomter 表为例,导出的表数据只展示手机号 c_phone 前三位与末四位(此处可以使用 yaml 配置文件的方式代替命令行参数):
operation: export
# 使用 | 作为字段分隔符,特殊字符需要使用引号括起
sep: "|"
table: customer
# 按照主键c_custkey进行排序
orderby: asc
orderCol: c_custkey
# 输出字段名
header: true
# 指定脱敏算法,只展示前三位与末四位
mask: >-
{
"c_phone": {
"type": "hiding",
"show_region": "0-2",
"show_end": 4
}
}原数据
c_custkey|c_name|c_address|c_nationkey|c_phone
1|Customer#000000001|IVhzIApeRb ot,c,E|15|25-989-741-2988
2|Customer#000000002|XSTf4,NCwDVaWNe6tEgvwfmRchLXak|13|23-768-687-3665
3|Customer#000000003|MG9kdTD2WBHm|1|11-719-748-3364
...脱敏后数据
c_custkey|c_name|c_address|c_nationkey|c_phone
1|Customer#000000001|IVhzIApeRb ot,c,E|15|25-********2988
2|Customer#000000002|XSTf4,NCwDVaWNe6tEgvwfmRchLXak|13|23-********3665
3|Customer#000000003|MG9kdTD2WBHm|1|11-********3364
...TPC-H导入

TPC-H是业界常用的一套数据库的分析型查询能力的基准测试。传统的 TPC-H 数据集导入是使用 tpck-kit 工具集,先在磁盘上生成 csv 格式的文本数据集,再通过 load data 等数据导入方式写入数据库;该方法不仅需要在压力机上预留对应的磁盘存储空间(比如进行 TPC-H 1T 的测试,则至少需要预留1个T的磁盘空间),而且数据生成和数据导入阶段都需要通过编写脚本的方式来实现并行,总体来说效率低下。
而 BatchTool 内置了 TPC-H 数据集生成的组件,无需预先生成文本数据即可直接流式导入 TPC-H 数据至数据库中,效率大大提升。
对应的命令行参数为-o import -benchmark tpch -scale $(数据集大小)。例如对于100 GB规格的 TPC-H 数据集导入,传统方式生成文本文件需要10分钟、load data导入需要42分钟,共耗时52分钟,而使用 BatchTool 在线导入仅需28分钟,且不会占用额外的磁盘空间,提升基准测试准备的效率。
总结
总的来说,数据库导入导出工具——BatchTool 具备以下特点:
- 轻量化,跨平台
- 高性能(执行模型优化、分布式适配)
- 支持了丰富的功能,适用于各种场景
此外,BatchTool 也在 github 上开源了,欢迎大家来试用!
原文链接
本文为阿里云原创内容,未经允许不得转载。