使用OpenCV构建会玩石头剪刀布的AI
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()

这个项目的代码可以在我的Github上找到
https://github.com/HOD101s/RockPaperScissor-AI-
简介
这个项目的基础是深度学习和图像分类,目的是创建一个简单而有趣的石头剪刀布游戏。首先,这个项目是我在5月份的COVID19隔离期中无聊的产物,希望当你读到这个时,一切都恢复正常了。我的目的是通过这篇文章用简单的术语向初学者解释这个项目的基本原理。让我们开始吧!
在构建任何类型的深度学习应用程序时,有三个主要步骤:
收集和处理数据
建立一个合适的人工智能模型
部署使用
整个项目都引用了我的Github repo,并与之携手并进,所以请做好参考准备。
项目地址:https://github.com/HOD101s/RockPaperScissor-AI-
收集我们的数据

任何深度学习模型的基础都是数据,任何一位机器学习工程师都会同意这一点,在ML中,数据远比算法本身重要。我们需要收集石头,布和剪刀的符号图像,我没有下载别人的数据并在上面进行训练,而是制作了自己的数据集,鼓励你也建立自己的数据集。之后尝试更改数据并重新训练模型,以查看数据对深度学习模型究竟有怎样的影响。
PATH = os.getcwd()+'\\'
cap = cv2.VideoCapture(0)
label = sys.argv[1]
SAVE_PATH = os.path.join(PATH, label)
try:
os.mkdir(SAVE_PATH)
except FileExistsError:
pass
ct = int(sys.argv[2])
maxCt = int(sys.argv[3])+1
print("Hit Space to Capture Image")
while True:
ret, frame = cap.read()
cv2.imshow('Get Data : '+label,frame[50:350,100:450])
if cv2.waitKey(1) & 0xFF == ord(' '):
cv2.imwrite(SAVE_PATH+'\\'+label+'{}.jpg'.format(ct),frame[50:350,100:450])
print(SAVE_PATH+'\\'+label+'{}.jpg Captured'.format(ct))
ct+=1
if ct >= maxCt:
break
cap.release()
cv2.destroyAllWindows()我使用了Python的OpenCV库进行所有与相机相关的操作,所以这里的label指的是图像属于哪个类,根据标签,图像保存在适当的目录中。ct和maxCt是用来保存图像的起始索引和最终索引,剩下的是标准的OpenCV代码,用于获取网络摄像头源并将图像保存到目录中。需要注意的一点是,我所有的图片维数都是300 x 300的。运行此目录树后,我的目录树如下所示。
C:.
├───paper
│ paper0.jpg
│ paper1.jpg
│ paper2.jpg
│
├───rock
│ rock0.jpg
│ rock1.jpg
│ rock2.jpg
│
└───scissor
scissor0.jpg
scissor1.jpg
scissor2.jpg如果你引用的是Github存储库(https://github.com/HOD101s/RockPaperScissor-AI-) ,则getData.py会为你完成这项工作!
预处理我们的数据
我们需要使用图像,而计算机可以识别数字,因此,我们将所有图像转换为它们各自的矢量表示,另外,我们的标签尚待生成,由于已建立的标签不能是文本,因此我使用shape_to_label字典为每个类手动构建了“独热编码”表示。
DATA_PATH = sys.argv[1] # Path to folder containing data
shape_to_label = {'rock':np.array([1.,0.,0.,0.]),'paper':np.array([0.,1.,0.,0.]),'scissor':np.array([0.,0.,1.,0.]),'ok':np.array([0.,0.,0.,1.])}
arr_to_shape = {np.argmax(shape_to_label[x]):x for x in shape_to_label.keys()}
imgData = list()
labels = list()
for dr in os.listdir(DATA_PATH):
if dr not in ['rock','paper','scissor']:
continue
print(dr)
lb = shape_to_label[dr]
i = 0
for pic in os.listdir(os.path.join(DATA_PATH,dr)):
path = os.path.join(DATA_PATH,dr+'/'+pic)
img = cv2.imread(path)
imgData.append([img,lb])
imgData.append([cv2.flip(img, 1),lb]) #horizontally flipped image
imgData.append([cv2.resize(img[50:250,50:250],(300,300)),lb]) # zoom : crop in and resize
i+=3
print(i)
np.random.shuffle(imgData)
imgData,labels = zip(*imgData)
imgData = np.array(imgData)
labels = np.array(labels)当我们根据类将图像保存在目录中时,目录名用作标签,该标签使用shape_to_label字典转换为独热表示。在我们遍历系统中的文件以访问图像之后,cv2.imread()函数返回图像的矢量表示。
我们通过翻转图像并放大图像来进行一些手动的数据增强,这增加了我们的数据集大小,而无需拍摄新照片,数据增强是生成数据集的关键部分。最后,图像和标签存储在单独的numpy数组中。
cv2.imread()函数
https://www.geeksforgeeks.org/python-opencv-cv2-imread-method/
更多关于数据增强的信息。
https://towardsdatascience.com/data-augmentation-for-deep-learning-4fe21d1a4eb9
通过迁移学习建立我们的模型:
在处理图像数据时,有许多经过预训练的模型可供使用,这些模型已经在具有数千个标签的数据集上进行了训练,由于这些模型通过其应用程序api的Tensorflow和Keras分布,我们可以使用这些模型,这使得在我们的应用程序中包含这些预先训练的模型看起来很容易!

总之,迁移学习采用的是经过预训练的模型,并且不包含进行最终预测的最终层,能够区分这种情况下图像中的特征,并将这些信息传递给我们自己的Dense神经网络。
为什么不训练你自己的模型呢?完全取决于你!然而,使用迁移学习可以在很多时候使你的进步更快,从某种意义上说,你避免了重复造轮子。
其他一些受欢迎的预训练模型:
InceptionV3
VGG16/19
ResNet
MobileNet
这是一篇关于迁移学习的有趣文章!
https://ruder.io/transfer-learning/
注:每当我们处理图像数据时,几乎都会使用卷积神经层,这里使用的迁移学习模型就有这些层。有关CNNs的更多信息,请访问:
https://medium.com/@RaghavPrabhu/understanding-of-convolutional-neural-network-cnn-deep-learning-99760835f148
实现
我已经使用DenseNet121模型进行特征提取,其输出最终将输入到我自己的Dense神经网络中。
densenet = DenseNet121(include_top=False, weights='imagenet', classes=3,input_shape=(300,300,3))
densenet.trainable=True
def genericModel(base):
model = Sequential()
model.add(base)
model.add(MaxPool2D())
model.add(Flatten())
model.add(Dense(3,activation='softmax'))
model.compile(optimizer=Adam(),loss='categorical_crossentropy',metrics=['acc'])
return model
dnet = genericModel(densenet)
history = dnet.fit(
x=imgData,
y=labels,
batch_size = 16,
epochs=8,
callbacks=[checkpoint,es],
validation_split=0.2
)关键点 :
由于我们的图片尺寸为300x300,因此指定的输入形状也为3x300x300,3代表RGB的维度信息,因此该层具有足够的神经元来处理整个图像。
我们将DenseNet层用作第一层,然后使用我们自己的Dense神经网络。
我已将可训练参数设置为True,这也会重新训练DenseNet的权重。尽管花了很多时间,但是这给了我更好的结果。我建议你在自己的实现中尝试通过更改此类参数(也称为超参数)来尝试不同的迭代。
由于我们有3类Rock-Paper-Scissor,最后一层是具有3个神经元和softmax激活的全连接层。
最后一层返回图像属于3类中特定类的概率。
如果你引用的是GitHub repo(https://github.com/HOD101s/RockPaperScissor-AI-) 的train.py,则要注意数据准备和模型训练!
至此,我们已经收集了数据,建立并训练了模型,剩下的部分是使用OpenCV进行部署
OpenCV实现:
此实现的流程很简单:
启动网络摄像头并读取每个帧
将此框架传递给模型进行分类,即预测类
用电脑随意移动
计算分数
def prepImg(pth):
return cv2.resize(pth,(300,300)).reshape(1,300,300,3)
with open('model.json', 'r') as f:
loaded_model_json = f.read()
loaded_model = model_from_json(loaded_model_json)
loaded_model.load_weights("modelweights.h5")
print("Loaded model from disk")
for rounds in range(NUM_ROUNDS):
pred = ""
for i in range(90):
ret,frame = cap.read()
# Countdown
if i//20 < 3 :
frame = cv2.putText(frame,str(i//20+1),(320,100),cv2.FONT_HERSHEY_SIMPLEX,3,(250,250,0),2,cv2.LINE_AA)
# Prediction
elif i/20 < 3.5:
pred = arr_to_shape[np.argmax(loaded_model.predict(prepImg(frame[50:350,100:400])))]
# Get Bots Move
elif i/20 == 3.5:
bplay = random.choice(options)
print(pred,bplay)
# Update Score
elif i//20 == 4:
playerScore,botScore = updateScore(pred,bplay,playerScore,botScore)
break
cv2.rectangle(frame, (100, 150), (300, 350), (255, 255, 255), 2)
frame = cv2.putText(frame,"Player : {} Bot : {}".format(playerScore,botScore),(120,400),cv2.FONT_HERSHEY_SIMPLEX,1,(250,250,0),2,cv2.LINE_AA)
frame = cv2.putText(frame,pred,(150,140),cv2.FONT_HERSHEY_SIMPLEX,1,(250,250,0),2,cv2.LINE_AA)
frame = cv2.putText(frame,"Bot Played : {}".format(bplay),(300,140),cv2.FONT_HERSHEY_SIMPLEX,1,(250,250,0),2,cv2.LINE_AA)
cv2.imshow('Rock Paper Scissor',frame)
if cv2.waitKey(1) & 0xff == ord('q'):
break上面的代码片段包含相当重要的代码块,其余部分只是使游戏易于使用,RPS规则和得分。
所以我们开始加载我们训练过的模型,它在开始程序的预测部分之前显示倒计时,预测后,分数会根据球员的动作进行更新。
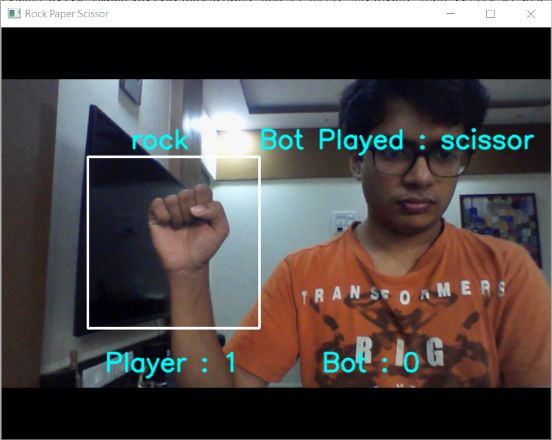
我们使用cv2.rectangle()显式地绘制目标区域,使用prepImg()函数预处理后,只有帧的这一部分传递给模型进行预测。
整个play.py在我的repo上有代码(https://github.com/HOD101s/RockPaperScissor-AI-/blob/master/play.py)。
结论:
我们已经成功地实现并学习了这个项目的工作原理,所以请继续使用我的实现进行其它实验学习。我做的一个主要的改进可能是增加了手部检测,所以我们不需要显式地绘制目标区域,模型将首先检测手部位置,然后进行预测。我鼓励你改进这个项目,并给我你的建议。精益求精!
原文链接:https://towardsdatascience.com/r-scissors-ai-using-tensorflow-and-opencv-d5fc44fc8222
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

