机器学习(一):简介
机器学习简介
这是一篇机器学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:机器学习初学者,转AI的开发人员。
编程语言:Python
参考书籍:《Python机器学习实践指南》《机器学习实战》

为什么使用Python
-
Python具有清晰的语法结构,简单易上手。大家也把它称作可执行伪代码(executable pseudo-code)。
-
易于操作纯文本文件。
-
使用广泛,存在大量的开发文档。比如可以借助功能全面的框架Django或者轻量的Flask框架快速搭建自己的网站;借助PyGame写一个小游戏;借助Scrapy做一个爬虫;借助Pandas数据框架,做数据统计分析。

-
再包装其他语言的程序。Python又叫做胶水语言,因为它可以用混合编译的方式使用c/c++/java等等语言的库。
数据挖掘十大算法
(可参照博客:10 种机器学习算法的要点)
选择依据:国际权威的学术组织the IEEE International Conference on Data Mining (ICDM) 2007年 12月评选出了数据挖掘领域的十大经典算法。
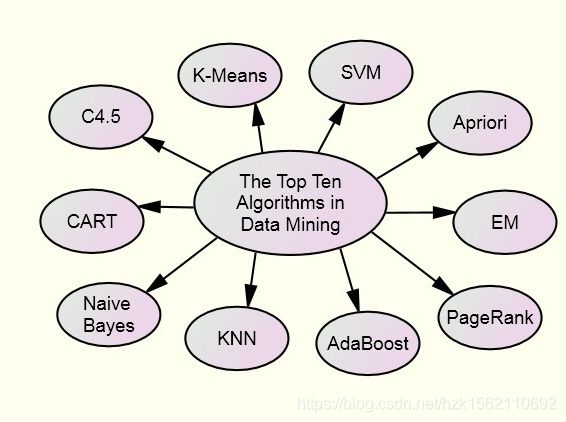
1、C4.5决策树
C4.5,是机器学习算法中的一个分类决策树算法,它是决策树(决策树也就是做决策的节点间的组织方式像一棵树,其实是一个倒树)核心算法ID3的改进算法,所以基本上了解了一半决策树构造方法就能构造它。决策树构造方法其实就是每次选择一个好的特征以及分裂点作为当前节点的分类条件。
2、The k-means algorithm (K-均值算法)
k-means algorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割(k < n)。它与处理混合正态分布的最大期望算法很相似,因为他们都试图找到数据中自然聚类的中心。它假设对象属性来自于空间向量,并且目标是使各个群组内部的均方误差总和最小。
3、 Support vector machines(支持向量机)
支持向量机,英文为Support Vector Machine,简称SVM。它是一种监督式学习的方法,它广泛的应用于统计分类以及回归分析中。支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。
4、The Apriori algorithm
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。
其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
5、最大期望(EM)算法
在统计计算中,最大期望 (EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(Latent Variabl)。最大期望经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。
6、 PageRank算法
PageRank是Google算法的重要内容。2001年9月被授予美国专利,专利人是Google创始人之一拉里•佩奇(Larry Page)。因此,PageRank里的page不是指网页,而是指佩奇,即这个等级方法是以佩奇来命名的。PageRank根据网站的外部链接和内部链接的数量和质量,衡量网站的价值。PageRank背后的概念是,每个到页面的链接都是对该页面的一次投票, 被链接的越多,就意味着被其他网站投票越多。
7、AdaBoost算法
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器 (强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器融合起来,作为最后的决策分类器。
8、 kNN: k-nearest neighbor classification(k-近邻)算法
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
9、 Naive Bayes(朴素贝叶斯)算法
在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBC)。
朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。
但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
10、 CART(分类回归树)算法
CART, Classification and Regression Trees。 在分类树下面有两个关键的思想:第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
数据科学的工作流程
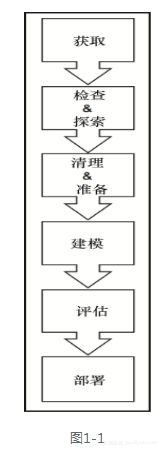
1、 获取
机器学习应用中的数据,可以来自不同的数据源,它可能是通过电子邮件发送的CSV文件,也可能是从服务器中拉取出来的日志,或者它可能需要构建自己的Web爬虫。数据也可能存在不同的格式。在大多数情况下,它是基于文本的数据,但稍后将看到,构建处理图像甚至视频文件的机器学习应用,也是很容易的。不管是什么格式,一旦锁定了某种数据,那么了解该数据中有什么以及没有什么,就变得非常重要了。
2、 检查和探索
一旦获得了数据,下一步就是检查和探索它们。在这个阶段中,主要的目标是合理地检查数据,而实现这一点的最好办法是发现不可能或几乎不可能的事情。举个例子,如果数据具有唯一的标识符,检查是否真的只有一个;如果数据是基于价格的,检查是否总为正数;无论数据是何种类型,检查最极端的情况。它们是否有意义?一个良好的实践是在数据上运行一些简单的统计测试,并将数据可视化。此外,可能还有一些数据是缺失的或不完整的。在本阶段注意到这些是很关键的,因为需要在稍后的清洗和准备阶段中处理它。只有进入模型的数据质量好了,模型的质量才能有保障,所以将这一步做对是非常关键的。
3、清理和准备
当所有的数据准备就绪,下一步是将它转化为适合于模型使用的格式。这个阶段包括若干过程,例如过滤、聚集、输入和转化。所需的操作类型将很大程度上取决于数据的类型,以及所使用的库和算法的类型。例如,对于基于自然语言的文本,其所需的转换和时间序列数据所需的转换是非常不同的。全书中,我们将会看到一些转换的的例子。
4、建模
一旦数据的准备完成后,下一阶段就是建模了。在这个阶段中,我们将选择适当的算法,并在数据上训练出一个模型。在这个阶段,有许多最佳实践可以遵循,我们将详细讨论它们,但是基本的步骤包括将数据分割为训练、测试和验证的集合。这种数据的分割可能看上去不合逻辑——尤其是在更多的数据通常会产生更好的模型这种情况下——但正如我们将看到的,这样做可以让我们获得更好的反馈,理解该模型在现实世界中会表现得如何,并避免建模的大忌:过拟合。
5、评估
一旦模型构建完成并开始进行预测,下一步是了解模型做得有多好。这是评估阶段试图回答的问题。有很多的方式来衡量模型的表现,同样,这在很大程度上依赖于所用数据和模型的类型,不过就整体而言,我们试图回答这样的问题:模型的预测和实际值到底有多接近。有一堆听上去令人混淆的名词,例如根均方误差、欧几里德距离,以及F1得分,但最终,它们还是实际值与预估值之间的距离量度。
6、部署
一旦模型的表现令人满意,那么下一个步骤就是部署了。根据具体的使用情况,这个阶段可能有不同的形式,但常见的场景包括将其作为另一个大型应用程序中的某个功能特性,一个定制的Web应用程序,甚至只是一个简单的cron作业。
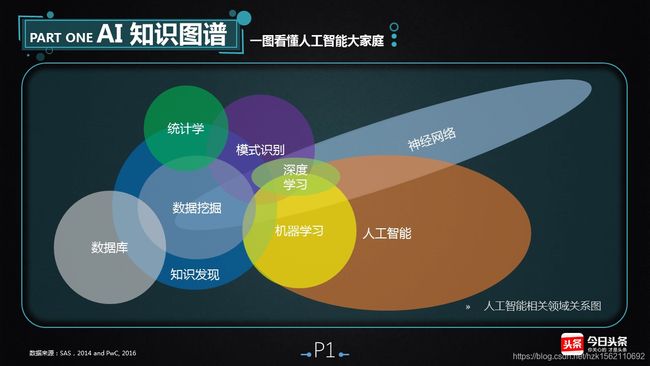
人工智能、数据挖掘、机器学习、深度学习
人工智能(Artifical Intelligence, AI)是计算机科学的一个子领域,创造于 20 世纪 60 年代,它涉及到解决对人类而言简单却对计算机很难的任务。详细来说,所谓的强人工智能系统应该是能做人类所能做的任何事;
数据挖掘(Data Mining)是从海量数据中“挖掘”隐藏信息;
数据挖掘采用的一个重要方法,是机器学习(Machine Learning),即通过程序积累经验,但机器学习是另一门学科,并不从属于数据挖掘,二者相辅相成;
深度学习(Deep Learning)是机器学习的一个子集,就是用复杂、庞大的神经网络进行机器学习。
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。
一般认为人工智能、机器学习、深度学习三者关系如下:

整个人工智能所涉及的各方面的知识如下:
关于机器学习算法的建议
- 开发人员对于数学知识的掌握,能够理解、使用,不需要自己知道公式的推导,有一定的逻辑思维,尤其需要一定的项目实战来加深理解
- .不要着急看公式,多思考原理
- 把复杂的概念通俗化,不要架空算法