python字典、元组
一、元组
元组是python的一个重要序列结构,属于不可变序列,一旦创建,没有任何方法可以修改元组中元素的值,也无法为元组增加或删除元素。元组支持切片操作,但是只能通过切片来访问元组中的元素,而不支持使用切片来修改元组中元素的值,也不支持使用切片操作来为元组增加或删除元素。从一定程度上讲,可以认为元组是轻量级的列表,或者“常量列表”。
Python的内部实现对元组做了大量优化,访问和处理速度比列表更快。元组在内部实现上不允许修改其元素值,从而使得代码更加安全,例如,使用函数时使用元组传递参数可以防止在函数中修改元组,使用列表很难做到这一点。
元组的创建
>>> x=(1,2,3) #直接把元组赋值给一个变量
>>> x
(1, 2, 3)
>>> type(x)
<class 'tuple'>
>>> x=(3) #这和x=3是一样的
>>> type(x)
<class 'int'>
>>> x=(3,) #如果元组中只有一个元素,必须在后面多写一个逗号
>>> x
(3,)
>>> tuple(range(5)) #将其他迭代对象转换为元组
(0, 1, 2, 3, 4)
注意:虽然元组属于不可变序列,其元素的值是不可改变的,但是如果元组中包含可变序列,情况就又变得复杂了。
>>> x=([1,2],3) #包含列表元素
>>> x[0][0]=5 #修改元组中的列表元素
>>> x
([5, 2], 3)
>>> x[0].append(8) #为元组中的列表增加元素
>>> x
([5, 2, 8], 3)
>>> x[0]=x[0]+[10] #试图修改元组的值,失败
Traceback (most recent call last):
File "" , line 1, in <module>
x[0]=x[0]+[10]
TypeError: 'tuple' object does not support item assignment
生成器推导式
与列表推导式不同的是,生成器推导式的结果是一个生成器对象,而不是列表,也不是元组。使用生成器对象的元素时,可以根据将其转化为列表或元组,也可以使用生成器的__next__()方法或者内置参数next()进行遍历,或者直接将其作为迭代器对象来使用。但是不管用哪种方法访问其元素,当所有元素访问结束以后,如果需要重新访问其中的元素,必须重新创建改生成器对象。
>>> g=((i+2)**2 for i in range(10)) #创建生成器对象
>>> g
<generator object <genexpr> at 0x0000015AE387F510>
>>> tuple(g) #将生成器对象转换为元组
(4, 9, 16, 25, 36, 49, 64, 81, 100, 121)
>>> list(g) #生成器对象已遍历结束,没有元素了
[]
>>> g=((i+2)**2 for i in range(10))
>>> g.__next__() #使用生成器对象的__next__()方法获取元素
4
>>> next(g) #使用内置函数next()获取生成器对象中的元素
9
>>> list(g)
[16, 25, 36, 49, 64, 81, 100, 121]
>>> g=((i+2)**2 for i in range(10))
>>> for item in g: #使用循环直接遍历生成器对象中的元素
print(item,end=' ')
4 9 16 25 36 49 64 81 100 121
二、字典
字典是包含若干“键:值”元素的无序可变序列,字典中的每个元素包含“键”和“值”两部分,表示一种映射或对应关系,也称为关联数组。字典中的“键”可以是Python中任意不可变数据,如整数、实数、负数、字符串、元组等,但不能使用列表、集合、字典或其他可变类型作为字典的“键”。另外,字典中的“键”不允许重复,而“值”是可以重复的。
2.1字典创建和元素添加、修改与删除
使用赋值运算符“=”将一个字典赋值给一个变量即可创建一个字典变量
>>> a_dict={'server':'adasd','database':'qqddq'}
>>> a_dict
{'server': 'adasd', 'database': 'qqddq'}
也可以使用内置函数dict()通过已有数据快速创建字典:
>>> keys=['a','b','c','d']
>>> values=[1,2,3,4]
>>> dictionary=dict(zip(keys,values))
>>> print(dictionary)
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
还可以使用内置函数dict()根据给定的"键:值"来创建字典:
>>> d=dict(name='Dong',age=37)
>>> d
{'name': 'Dong', 'age': 37}
还可以以给定内容为“键”,创建"值"为空的字典:
>>> adict=dict.fromkeys(['name','age','sex'])
>>> adict
{'name': None, 'age': None, 'sex': None}
当以指定"键"为下标字典元素赋值时,有两种含义:1、若该"键"存在,则表示修改该"键"对应的值;2、若该键不存在,则表示添加一个新的"键:值",也就是添加一个新元素。
>>> adict={'age':35,'name':'Dong','sex':'male'}
>>> adict['age']=38 #修改元素值
>>> adict
{'age': 38, 'name': 'Dong', 'sex': 'male'}
>>> adict['address']='SDIBT' #添加新元素
>>> adict
{'age': 38, 'name': 'Dong', 'sex': 'male', 'address': 'SDIBT'}
>>>
使用字典对象的update()方法可以将另一个字典的“键:值”一次性全部添加到当前字典对象,如果两个字典中存在相同的"键",则以另一个字典中的"值"为准对当前字典进行更新。
>>> adict
{'age': 38, 'name': 'Dong', 'sex': 'male', 'score': [98, 97]}
>>> adict.items()
dict_items([('age', 38), ('name', 'Dong'), ('sex', 'male'), ('score', [98, 97])])
>>> adict.update({'a':97,'age':39})
>>> adict
{'age': 39, 'name': 'Dong', 'sex': 'male', 'score': [98, 97], 'a': 97}
使用del命令可以删除整个字典,也可以删除字典中指定的元素。例如:
>>> adict
{'age': 39, 'name': 'Dong', 'sex': 'male', 'score': [98, 97], 'a': 97}
>>> del adict['age'] #删除字典元素
>>> adict
{'name': 'Dong', 'sex': 'male', 'score': [98, 97], 'a': 97}
>>> del adict #删除整个字典
>>> adict #字典对象被删除后不再存在
Traceback (most recent call last):
File "" , line 1, in <module>
adict
NameError: name 'adict' is not defined
也可以使用字典对象的pop()和popitem()方法弹出并删除指定的元素,例如:
>>> adict={'age': 39, 'name': 'Dong', 'sex': 'male', 'score': [98, 97]}
>>> adict.popitem() #弹出一个元素,对空字典会抛出异常
('score', [98, 97])
>>> adict.pop('age') #弹出指定键对应的元素
39
>>> adict
{'name': 'Dong', 'sex': 'male'}
字典对象的clear()方法用于清空字典对象中的所有元素,copy()方法返回字典对象的浅复制。
2.2访问字典对象的数据
字典中的每个元素表示一种映射关系或对应关系,根据提供的"键"作为下标就可以访问对应的"值",如果字典中不存在这个"键"会抛出异常,
>>> adict={'age': 37, 'name': 'Dong', 'sex': 'male', 'score': [98, 97]}
>>> adict['age'] #指定的“键”存在,返回对应的“值”
37
>>> adict['address'] #指定的“键”不存在,抛出异常
Traceback (most recent call last):
File "" , line 1, in <module>
adict['address']
KeyError: 'address'
为了避免程序运行时引发异常而导致崩溃,在使用下标的方式访问字典元素时,最好能配合条件判断或者异常处理结构,例如:
>>> adict={'age': 37, 'name': 'Dong', 'sex': 'male', 'score': [98, 97]}
>>> if 'address' in adict:
print(adict['age'])
else:
print('No Exists.')
No Exists.
字典对象提供了get()方法用来返回指定"键"对应的"值",更妙的是这个方法允许指定该键不存在时返回特定的值。例如:
>>> adict
{'age': 37, 'name': 'Dong', 'sex': 'male', 'score': [98, 97]}
>>> adict.get('age')
37
>>> adict.get('address','Not Exists')
'Not Exists'
字典对象的setdefault()方法用于返回指定"键"对应的"值",如果字典中不存在该"键",就添加一个新元素并设置该"键"对应的"值",如果已存在,则不会改变原字典,例如:
>>> adict.setdefault('address','SDIBT') #增加新元素
'SDIBT'
>>> adict
{'age': 37, 'name': 'Dong', 'sex': 'male', 'score': [98, 97], 'address': 'SDIBT'}
>>> adict.setdefault('age',39) #如果存在,则不改变原值
37
>>> adict
{'age': 37, 'name': 'Dong', 'sex': 'male', 'score': [98, 97], 'address': 'SDIBT'}
最后,当对字典对象进行迭代时,默认是遍历字典的"键",这一点必须清醒地记在脑子里。当然,可以使用字典对象的items()方法返回字典中的元素,即所有"键:值"对,字典对象的keys()方法返回所有"键",values()方法返回所有"值"。例如:
>>> adict
{'age': 37, 'name': 'Dong', 'sex': 'male', 'score': [98, 97]}
>>> for item in adict: #默认遍历字典的"键"
print(item)
age
name
sex
score
>>> for item in adict.items(): #明确指定遍历字典的元素
print(item)
('age', 37)
('name', 'Dong')
('sex', 'male')
('score', [98, 97])
>>> adict.items()
dict_items([('age', 37), ('name', 'Dong'), ('sex', 'male'), ('score', [98, 97])])
>>> adict.keys()
dict_keys(['age', 'name', 'sex', 'score'])
>>> adict.values()
dict_values([37, 'Dong', 'male', [98, 97]])
Python内置函数字典是无序的,如果需要一个可以记住元素插入顺序的字典,可以使用collections.OrderdDict。例如:
>>> import collections
>>> x=collections.OrderedDict()
>>> x['a']=3
>>> x['b']=5
>>> x['c']=8
>>> x
OrderedDict([('a', 3), ('b', 5), ('c', 8)])
>>> type(x)
<class 'collections.OrderedDict'>
内置函数sorted()可以对字典元素进行排序并返回新列表,充分利用key参数可以实现丰富的排序功能
>>> phonebook={'Linda':'7750','Bob':'9345','Carol':'5834'}
>>> from operator import itemgetter
>>> sorted(phonebook.items(),key=itemgetter(1)) #按字典的"值"进行排序
[('Carol', '5834'), ('Linda', '7750'), ('Bob', '9345')]
>>> sorted(phonebook.items(),key=itemgetter(0)) #按字典的"键"进行排序
[('Bob', '9345'), ('Carol', '5834'), ('Linda', '7750')]
>>> sorted(phonebook.items(),key=lambda item:item[0])#按字典的"键"进行排序
[('Bob', '9345'), ('Carol', '5834'), ('Linda', '7750')]
Python支持字典推导式快速生成符合特定条件的字典
>>> {i:str(i) for i in range(5)}
{0: '0', 1: '1', 2: '2', 3: '3', 4: '4'}
>>> x={'A','B','C','D'}
>>> y={'a','b','c','d'}
>>> {i:j for i,j in zip(x,y)}
{'B': 'a', 'C': 'b', 'A': 'c', 'D': 'd'}
深浅拷贝
解析
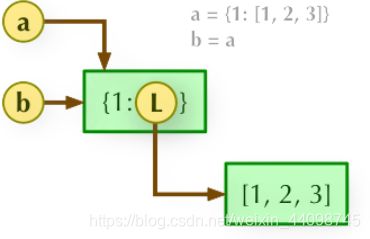
1、b = a: 赋值引用,a 和 b 都指向同一个对象。
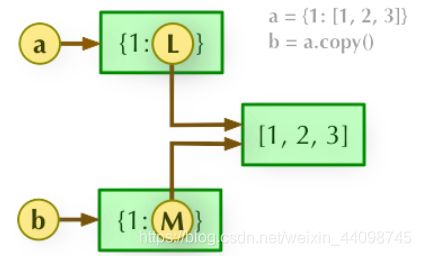
2、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
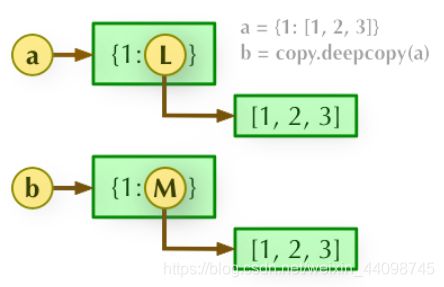
b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
参考:
https://www.runoob.com/w3cnote/python-yield-used-analysis.html