locust是开源的、基于python采用协程能产生高并发的性能测试工具。

一、Locust环境安装
1、非虚拟环境安装:pip install locust(目前版本1.6)
2、虚拟环境安装如下:


⚠️注意:虚拟环境的安装必须是在bin目录下进行pip安装!!!
虚拟环境安装完成后如下:
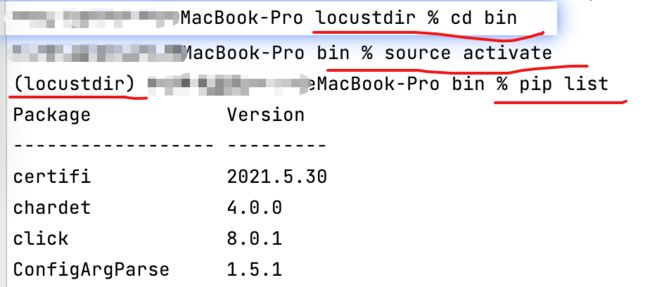
如果不小心退出了虚拟环境,想重回虚拟环境。首先进入bin目录,source activate即可,如下图所示:
二、Locust分布式
locust和LR、jmeter类似都可以实现分布式发压。
locust分布式启动场景有2种,一种是单机设置master和worker模式,另外一种是有多个机器,其中一个机器设置master,其它机器设置worker节点。
无论是单机主从模式还是多机主从模式都是先启动 master,然后再逐一启动若干个 worker
1、单机主从模式(又叫多进程运行)
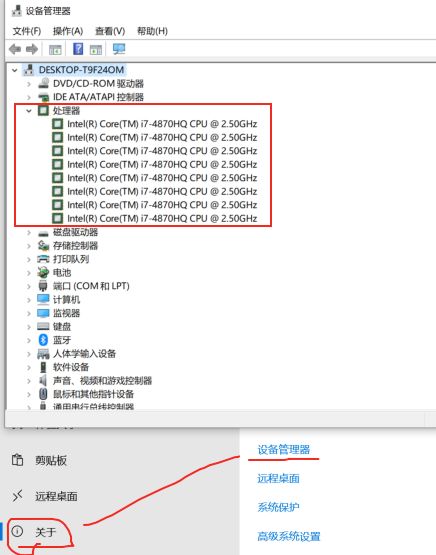
Locust 中使用 master-worker 模式启动多个进程【充分使用多核处理器的处理能力,worker节点数要小于等于本机的处理器数】,如下是Mac和windows的查找方式

主节点:locust -f locustfile.py --master 【master不负责运行task任务,只负责做管理,没有日志输出】
从节点:locust -f locustfile.py --worker【多开几个终端可以充分发挥处理器的核数(worker节点数要小于等于本机的处理器数),会显示输出日志】
2、多机主从模式
选择其中一台电脑做为master节点。主节点无法操作别的节点,所以必须在其它机器上启动从属Locust节点。启动命令后面跟上--worker参数,以及--master-host(指定主节点的IP/主机名)
主节点:locust -f locustfile.py --master
从节点:locust -f locustfile.py --worker --master-host=192.168.x.xx
三、Locust脚本编写
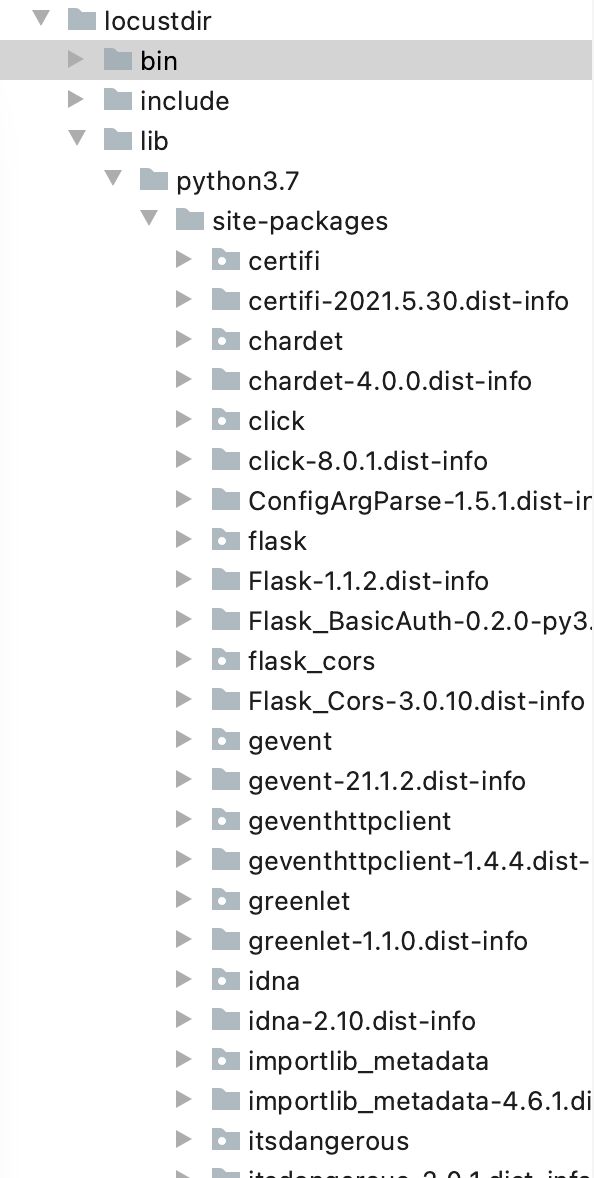
项目文件结构如下【这里我是在python虚拟环境下文件结构】

"""1、locust特别适合做接口侧性能测试2、如果要测试的接口不多,也没有执行顺序上的要求,可以单独的写成一个方法即可,如下第一种和第二种方式3、如果要测试的接口多,有权重的执行要求,这时候就需要写在一个或多个任务集中,如下第三种方式 写在一个任务集中权重分配:task标记 写在多个任务集中权重分配: 按比例分配A类名是B类名下任务的3倍 tasks = {A: 3, B: 1}4、第一种,第二种、第三种都是并行执行,多个类【任务集】运行:tasks = [A, B]5、第四种按一定的顺序执行[TaskSet.SequentialTaskSet]6、参数化取值方式: 循环取数据,数据可重复使用 list(无序) 保证并发测试数据唯一性,循环取值 queue(有序) 保证并发测试数据唯一性,不循环取值 queue(有序)7、关联可采用common中正则提取所要的字符串8、分布式压测:协程在Linux下性能要比windows好很多的,可以设置windows为master,Linux下为worker节点"""
1 import queue
2 from queue import Queue
3 from random import choice
4 from locust import HttpUser, constant, between, task, TaskSet, tag, SequentialTaskSet
5 from locust import HttpLocust # 1.0版本之前在使用HttpLocust
6 # ======================
7 # #第二种写在用户类外定义函数
8 # @task
9 # def http_get(user):
10 # user.client.request(method='GET', url="/getAllUrl", name='打开首页')
11
12
13 # ======================
14 # #第三种写在任务类中
15 # 任务类
16 class ApiTask(TaskSet):
17 @task
18 def http_get(self):
19 self.client.get("/getAllUrl")
20
21 @task(5)
22 def http_post(self):
23 header = {"Content-Type": "application/json"}
24 payload = {
25 "page": 1,
26 "count": 200
27 }
28 with self.client.post("/getWangYiNews", headers=header, data=payload, verify=False, name="获取200条信息")as res:
29 print(res.text)
30
31
32 # ======================
33 # #第四种写在任务类中并按一定顺序执行,SequentialTaskSet是TaskSet类下的按顺序执行的一个函数
34 # 任务类
35 class ApiSeqTask(SequentialTaskSet):
36 # @task
37 # def http_get(self):
38 # self.client.get("/getAllUrl", name="获取所有URL")
39
40 # @task(10)
41 # def http_post(self):
42 # # post请求无序参数化取值
43 # p_c = choice(self.user.payload).split(",")
44 # print(p_c)
45 # header = {"Content-Type": "application/json"}
46 # payload = {
47 # "page": p_c[0],
48 # "count": p_c[1]
49 # }
50 # with self.client.post("/getWangYiNews", headers=header, data=payload, verify=False, name="获取200条信息")as res:
51 # print(res.text)
52
53 # @task
54 # def http_get(self):
55 # # 无序请求参数化取值
56 # p_c = choice(self.user.payload).split(",")
57 # print(p_c)
58 # params = {
59 # "page": p_c[0],
60 # "count": p_c[1]
61 # }
62 # with self.client.get("/poetryFull", params=params, name="获取诗词")as res:
63 # print(res.text)
64
65 @task
66 def http_get(self):
67 # 有序请求参数化取值
68 try:
69 count_page = self.user.count_page.get() # 获取唯一的配置信息
70 print(count_page)
71 except queue.Empty:
72 print("数据已用完")
73 exit(0) # 无错误退出
74 countpage = count_page.split(",")
75 params = {
76 "page": countpage[0],
77 "count": countpage[1]
78 }
79 with self.client.get("/poetryFull", params=params, name="获取诗词")as res:
80 print(res.text)
81
82
83 # 用户类
84 # 定义一个类并继承locust下的HttpUser类
85 class ApiUser(HttpUser):
86 # host = "http://api.apiopen.top" # 设置网站的根地址
87 host = "http://poetry.apiopen.top" # 设置网站的根地址
88
89 # 格式一
90 # wait_time = constant(3) # 每次请求的固定停顿时间(相当于性能测试的思考时间)
91 # 格式二
92 # wait_time = between(2, 5) # 每次请求的停顿时间在2到5秒之间随机取值(也相当于性能测试的思考时间)
93 # 格式三
94 min_wait = 2000 # 模拟负载任务之间执行时的 最小/最大 停顿时间,单位毫秒
95 max_wait = 5000
96
97 # tasks = [http_get] # 与第二种方式结合使用,ApiUser类继承了HttpUser,tasks任务集中也继承了user
98 # tasks = [ApiTask] # 与第三种方式结合使用,tasks任务集后也可以是类
99 tasks = [ApiSeqTask] # 与第四种方式结合使用,执行一次get请求再执行十次post请求
100
101 # ======================
102 # 第一种直接写在用户类下定义函数
103 # @task # task括号内数值越大执行频率越高,默认标记为1
104 # def http_get(self):
105 # self.client.request(method='GET', url = "/getAllUrl", name='打开首页')
106
107 # 无序参数化
108 payload = []
109 with open("data/id.csv",'r')as file:
110 for line in file.readlines():
111 payload.append(line.strip())
112 # print(payload) # ['1,200', '2,100', '3,50', '4,10', '5,5']
113
114 # 有序参数化
115 count_page = Queue()
116 with open("data/id.csv",'r')as file:
117 for line in file.readlines():
118 count_page.put_nowait(line.strip())
tools文件内容及data下数据:
1 """
2 工具:正则匹配出想要的参数,可以用在关联中
3 """
4 import re
5
6
7 def fetch_String(data, LB = None, RB = None):
8 rule = LB + r"(.*?)" + RB
9 slot_list = re.findall(rule, data)
10 return slot_list
1 1,2
2 2,1
3 3,5
4 4,1
5 5,3
本文扩展阅读:
locust官方文档:https://docs.locust.io/en/stable/quickstart.html
requests官方文档:https://docs.python-requests.org/zh_CN/latest/
念师系列:https://www.missshi.cn/?s=Locust#/blogGroupDetail/29?_k=f0iyqp