内存模型与memory orde
概
c++的atomic使用总会配合各种各样的memory order进行使用,memory order控制了执行结果在多核中的可见顺序,,这个可见顺序与代码序不一定一致(第一句代码执行完成的结果不一定比第二句早提交到内存),其一是进行汇编的进行了指令优化重排,其二是cpu实际执行时乱序执行以及部分cpu架构上没有做到内存强一致性(内存强一致性:可以简单的理解为,执行结果出现的顺序应该和指令顺序一样,不存在重排乱序),导致后面的代码执行完成的时候,前面的代码修改的内存却还没改变
结果序和代码序不一致不一定会导致问题,但在可能出现问题的场景下,就需要手动干预以避免问题,汇编(软件)和cpu(硬件)都提供了相应的指令取进行干预控制,c++的atomic中的memory order可以看成是这些控制的封装,隐藏了底层,之所以有六种是因为这种控制是有代价,从松散到严格开销越来越高,在某些场景下,我们是允许部分重排的,只是对于小部分重排会导致问题的才需要加以控制,那么只需要衉一些低开销的控制即可,java也有类似的工具;
这种memory order的控制常见使用在多核的happened-before, synchronized with的模型下,要做的事情就是管理好happened-before和synchronized with顺序,按照箭头的方式运行

正文
c++中的memroy order
c++中的memory order中有如下几种:
namespace std {
typedef enum memory_order {
memory_order_relaxed, memory_order_consume, memory_order_acquire,
memory_order_release, memory_order_acq_rel, memory_order_seq_cst
} memory_order;
其对应着以下三类的memory order(内存顺序模型)
- memory_order_seq_cst: 顺序一致性模型,这个是默认提供的最强的一致性模型。
- memory_order_release/acquire/consume: 提供release、acquire或者consume, release语意的一致性保障
- memory_order_relaxed: 提供松散一致性模型保障,不提供operation order保证。
在概文中提到这些是c++提供的memory order(结果序)的控制,它们的作用是对汇编上做重排干预和硬件上乱序执行干预和执行结果在多核的可见性的控制,但乍看之下很懵,不知道这三类内存顺序模型是啥,就执行结果在多核的可见性的控制入手,首先我们先从硬件的内存模型说起。
硬件的内存模型
因CPU的不断发展,使得CPU的计算能力远超过从主存(DRAM)中读写速度,在硬件上慢慢的加入了cache, store buffer, invalidate queue等硬件以提升数据读写速度,并增加了cpu的乱序执行(指令在实际的cpu运行过程中并非表现得一条执行完了才执行下一条指令的样子,比如一个mov指令会导致的cpu的load unit忙而alu(逻辑计算单元)空闲等,故在等取值的同时,预先做下一个能够做的计算指令,这样的乱序执行提升了cpu的使用率),虽然cpu的乱序执行后面有模型规约着最终执行结果的一致性,但是store buffer, invalidate queue这些硬件上带来的加速却是有代价的,它们的出现带来了不同的内存一致性模型导致执行结果在多核下的可见顺序不同,所以需要人们编程的时候考虑这点, 以下介绍常见的四种内存一致性模型和它们对执行结果的在多核中可见顺序的影响
顺序存储模型(sequential consistency model)
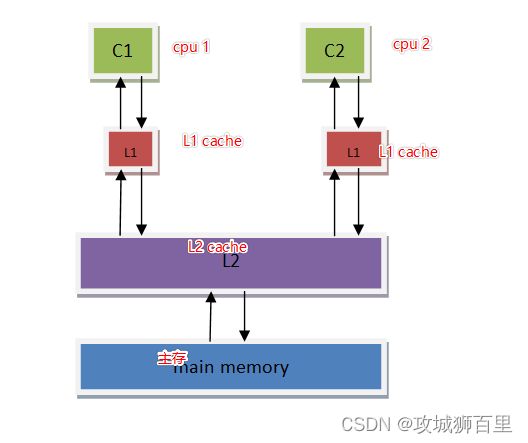
顺序模型(sequential consistency model)又被简称为SC,常对应的硬件结构图如上,在顺序模型的硬件架构中,只看到了cache,在这里额外科普补充以下,多核在cache中的读写使用的是MESI协议进行同步
在这种模型下,多线程程序的运行所期望的执行情况是一致的,不会出现内存访问乱序的情况;
比如说以下的指令运行,会按照 S1->S2->L1->L2 运行完成,最终的r2的值会是NEW;
这便是SC(顺序模型)的特点,指令的执行行为于行为与UP(单核)上是一致的

完全存储定序(total store order)

为了提高CPU的性能,芯片设计人员在CPU中包含了一个存储缓存区(store buffer),它的作用是为store指令提供缓冲,使得CPU不用等待存储器的响应。所以对于写而言,只要store buffer里还有空间,写就只需要1个时钟周期(哪怕是ARM-A76的L1 cache,访问一次也需要3个cycles,所以store buffer的存在可以很好的减少写开销),但这也引入了一个访问乱序的问题。
相比于以前的内存模型而言,store的时候数据会先被放到store buffer里面,然后再被写到L1 cache里。让我们来看一段指令:
S1:store flag= set
S2:load r1=data
S3:store b=set
如果在顺序存储模型中,S1肯定会比S2先执行。但是如果在加入了store buffer之后,S1将指令放到了store buffer后会立刻返回,这个时候会立刻执行S2。S2是read指令,CPU必须等到数据读取到r1后才会继续执行。这样很可能S1的store flag=set指令还在store buffer上,而S2的load指令可能已经执行完(特别是data在cache上存在,而flag没在cache中的时候。这个时候CPU往往会先执行S2,这样可以减少等待时间)
这里就可以看出再加入了store buffer之后,内存一致性模型就发生了改变。我们定义store buffer必须严格按照FIFO的次序将数据发送到主存(所谓的FIFO表示先进入store buffer的指令数据必须先于后面的指令数据写到存储器中),cpu必须要严格保证store buffer的顺序执行,所以S3必须要在S1之后执行,这种内存模型就叫做完全存储定序(TSO)。我们常用的物理机上的x86 CPU 就是这种内存模型。
这种架构在单核情况下没问题,但在多核运行多线程的时候会出现问题,对于如下分别运行在core1 和 core2的指令,由于store buffer的存在,L1和S1的store指令会被先放到store buffer里面,然后CPU会继续执行后面的load指令。Store buffer中的数据可能还没有来得及往存储器中写,这个时候我们可能看到C1和C2的r1都为0的情况。这种乱序称之为store-load乱序,对于可能出现store-load乱序的场景,cpu提供了一些指令去控制怎么把这些数据同步到其它核,后面会介绍这些的工具

部分存储定序(part store order)
TSO在store buffer的情况下已经带来了不小的性能提升,但是芯片设计人员并不满足于这一点,于是他们在TSO模型的基础上继续放宽内存访问限制,允许CPU以非FIFO来处理store buffer缓冲区中的指令。CPU只保证地址相关指令在store buffer中才会以FIFO的形式进行处理(大白话就是对同一个相同的地址做store,才会有严格执行顺序制约),而其他的则可以乱序处理,所以这被称为部分存储定序(PSO)。

如上图,S1与S2是地址无关的store指令,cpu执行的时候都会将其推到store buffer中。如果这个时候flag在C1的cahe中存在,那么CPU会优先将S2的store执行完,然后等data缓存到C1的cache之后,再执行store data=NEW指令。
可能的执行顺序:S2->L1 >L2->S1, 这样在C1将data设置为NEW之前,C2已经执行完,r2最终的结果会为0,而不是我们期望的NEW,这样PSO带来的store-store乱序将会对我们的代码逻辑造成致命影响。
控制工具
store buffer控制工具
以下是一个store-store乱序例子,如下图所示,thread1中,由于 a = 1 与 c = 3 存在happen before关系,所以使用c是否等于3在thread2做同步,使得最终到assert()的时候a一定等于1,但是这个例子在pso模型下,是可能出现a的值还在store buffer中还没同步到其它核上,而C值已经在cache中通过cache的一致性同步到core2中

这时就需要编码人员介入了,编码人员需要告诉CPU现在需要将store buffer的数据flush到cache里,于是CPU设计者提供了叫memory barrier的工具。
int a = 0, c = 0;
thread 1:
{
a = 1;
smp_mb(); // memory barrier
c = 3
}
thread 2:
{
while(c != 3);
assert(a == 1);
}
smp_mb()会在执行的时候将storebuffer中的数据全部刷进cache。这样assert就会执行成功了。
storebuffer帮助core在进行store操作的时候尽快返回,这里的buffer和cache都是硬件,所以这些一般都比较小(或许就只有几十个字节这么大),当storebuffer满了之后就需要将buffer中的内容刷到cache,刷到cache这部分的数据被更新了,就会触发cache的mesi进行同步,发送cacheline的invalidate message告知其它cache你们持有的数据失效了,赶紧标注一下然后同步,然后其他的core会返回invalidate ack之后这时才会继续向下执行。那么这个时候问题又来了,这些message发到另外的core,这些core需要先invlidate,然后在返回ack,如果这些core本来就很忙的话就会导致message处理被延后,这中间需要等待很长的通讯时间,这对于CPU设计者来说同样是不可接受的。因此CPU设计者又引入了invalidate queue。如下图
- TSO下的invalidate message queue控制工具
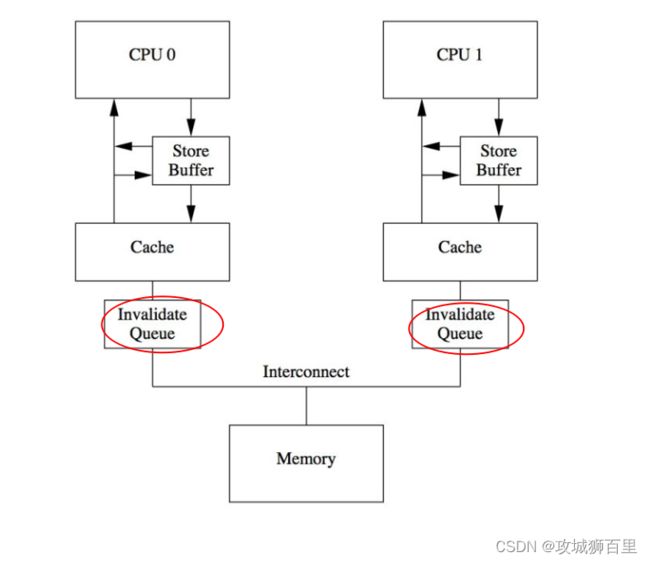
有了invalidate queue之后,发送的invalidate message只需要push到对应core的invalidate queue即可,然后这个core就会返回继续执行,中间不需要等待。这样cache之间的沟通就不会有很大的阻塞了,但是这同样带来了问题。
如果a在invalidate queue中的invalidata message还没到被其它的cpu给处理,那么它们就会持有旧数据,比如说下下面的thread2有可能assert还是会失败,为此需要在 thread2中也添加内存屏障,它会将所在core的storebuffer和invalidate queue都flush上来做完处理再执行下面的指令。
int a = 0, c = 0;
thread 1:
{
a = 1;
smp_mb(); // memory barrier
c = 3
}
thread 2:
{
while(c != 3);
//smp_mb() 此处也需要添加内存屏障
assert(a == 1);
}
上面提到的smp_mb()是一种full memory barrier,他会将store buffer和invalidate queue都flush一遍。但是就像上面例子中体现的那样有时候我们不用两个都flush,于是硬件设计者引入了read memory barrier和write memory barrier。
read memory barrier其实就是将invalidate queue flush。也称lfence(load fence)
write memory barrier是将storebuffer flush。也称sfence(sotre fence)
在x86下,还有一个lock指令:
Lock前缀,Lock不是一种内存屏障,但是它能完成类似内存屏障的功能。Lock会对CPU总线和高速缓存加锁,可以理解为CPU指令级的一种锁。它后面可以跟ADD, ADC, AND, BTC, BTR, BTS, CMPXCHG, CMPXCH8B, DEC, INC, NEG, NOT, OR, SBB, SUB, XOR, XADD, and XCHG等指令。Lock前缀实现了以下作用
-
它先对总线/缓存加锁,然后执行后面的指令,最后释放锁后会把高速缓存中的脏数据全部刷新回主内存。
-
在Lock锁住总线的时候,其他CPU的读写请求都会被阻塞,直到锁释放。Lock后的写操作会让其他CPU相关的cache line失效,从而从新从内存加载最新的数据。这就是通过cache的MESI协议实现的。
宽松存储模型(relax memory order)
丧心病狂的芯片研发人员为了榨取更多的性能,在PSO的模型的基础上,更进一步的放宽了内存一致性模型,不仅允许store-load,store-store乱序。还进一步允许load-load,load-store乱序, 只要是地址无关的指令,在读写访问的时候都可以打乱所有load/store的顺序,这就是宽松内存模型(RMO)。

在PSO模型里,由于S2可能会比S1先执行,从而会导致C2的r2寄存器获取到的data值为0。在RMO模型里,不仅会出现PSO的store-store乱序,C2本身执行指令的时候,由于L1与L2是地址无关的,所以L2可能先比L1执行,这样即使C1没有出现store-store乱序,C2本身的load-load乱序也会导致我们看到的r2为0。从上面的分析可以看出,RMO内存模型里乱序出现的可能性会非常大,这是一种乱序随可见的内存一致性模型, RM的很多微架构就是使用RMO模型,所以我们可以看到ARM提供的dmb内存指令有多个选项:
LD load-load/load-store
ST store-store/store-load
SY any-any
内存模型总结
以上就是我们所有说到的内存模型:SC(完全一致性),TSO(完全存储一致性),PSO(部分存储一致性),RMO(完全宽松),这些都是硬件架构上的不同会带来内存可见性问题,但是除此之外,cpu在执行的时候也会乱序,编译器在编译优化的时候是会对指令做重排的,,也会产生如上的内存模型,所幸c++给我们封装了memory_order,让我们直接忽视硬件-cpu-指令这些运行细节,就只是从内存模型的角度去控制程序的运行;
c++ 中的memory order
在atomic变量的store和load中提供以下选项,现在解释它们的含义:
c++中的memory_order的含义解释
-
memory_order_seq_cst:
这个选项语义上就是要求底层提供顺序一致性模型,这个是默认提供的最强的一致性模型,在这种模型下不存在任何重排,可以解决一切问题
在底层实现上:程序的运行底层架构如果是非内存强一致模型,会使用cpu提供的内存屏障等操作保证强一致,在软件上,并要求代码进行编译的时候不能够做任何指令重排, -
memory_order_release/acquire/consume:
提供release、acquire或者consume, release语意的一致性保障
它的语义是:我们允许cpu或者编译器做一定的指令乱序重排,但是由于tso, pso的存在,可能产生的store-load乱序store-store乱序导致问题,那么涉及到多核交互的时候,就需要手动使用release, acquire去避免这样的这个问题了,与memory_order_seq_cst最大的不同的是,其是对具体代码可能出现的乱序做具体解决而不是要求全部都不能重排 -
memory_order_relaxed: 提供松散一致性模型保障,不提供operation order保证。
这种内存序使用在,完全放开,让编译器和cpu自由搞,如果cpu是SC的话,cpu层不会出现乱序,但是编译层做重排,结果也是无法保证的,很容易出问题,但可用在代码上没有乱序要求的场景或者没有多核交互的情况下,提升性能。
memory order使用例子
这里介绍了使用c++的memory model的例子,以下是搬运:
- 写顺序保证
std::atomic<bool> has_release;
// thread_2
void release_software(int *data) {
int a = 100; // line 1
int c = 200; // line 2
if (!data) {
data = new int[100]; // line 3
}
has_release.store(true, std::memory_order_release); // line 4
}
std::memory_order_release功能如果用一句比较长的话来说,就是:在本行代码之前,有任何写内存的操作,都是不能放到本行语句之后的。简单地说,就是写不后。即,写语句不能调到本条语句之后。以这种形式通知编译器/CPU保证真正执行的时候,写语句不会放到has_release.store(true, std::memory_order_relese)之后。
尽管要求{1,2,3}代码的执行不能放到4的后面,但是{1,2,3}本身是可以被乱序的。比如按照{3,2,1,4}的顺序执行也是可以的,release可以认为是发布一个版本。也就是说,应该在发布之前做的,那么不能放到release之后。
- 读顺序的保证
假设thread_1想要按照{line 1, line2}的顺序呈现给其他线程,比如thread_2。如果thread_2写法如下:
std::atomic<bool> has_release;
int *data = nullptr;
// thread_1
void releae_software() {
if (!data) {
data = new int[100]; // line 1
}
has_release.store(true, std::memory_order_release); // line 2
//.... do something other.
}
// thread_use
void use_software() {
// 检查是否已经发布了
while (!has_release.load(std::memory_order_relaxed));
// 即然已经发布,那么就从里面取值
int x = *data;
}
在这里,thread_use的代码执行顺序依然是有可能被改变的。因为编译器和cpu在执行的时候,可能会针对thread_use进行代码的优化或者执行流程的变化。比如完全全有可能会被弄成:
void use_software() {
int x = *data;
while (!has_release.load(std::memory_order_relax));
}
到这个时候,thread_use看到的顺序却完全不是thread_1想呈现出来的顺序。这个时候,需要改进一下thread_use -> thread_2。
void acquire_software(void) {
while (!has_release.load(std::memory_order_acquire));
int x = *data;
}
std::memory_order_acquire表示的是,后续的读操作都不能放到这条指令之前。简单地可以写成读不前
- 读顺序的削弱
有时候,std::memory_order_release和std::memory_order_acquire会波及无辜
std::atomic<int> net_con{0};
std::atomic<int> has_alloc{0};
char buffer[1024];
char file_content[1024];
void release_thread(void) {
sprintf(buffer, "%s", "something_to_read_tobuffer");
// 这两个是与buffer完全无关的代码
// net_con表示接收到的链接
net_con.store(1, std::memory_order_release);
// 标记alloc memory for connection
has_alloc.store(1, std::memory_order_release);
}
void acquire_thread(void) {
// 这个是与两个原子变量完全无关的操作。
if (strstr(file_content, "auth_key =")) {
// fetch user and password
}
while (!has_alloc.load(std::memory_order_acquire));
bool v = has_alloc.load(std::memory_order_acquire);
if (v) {
net_con.load(std::memory_order_relaxed);
}
仔细分析代码,可以看出,buffer与file_content的使用,与两个原子变量就目前的这段简短的代码而言是没有任何联系的。按理说,这两部分的代码是可以放到任何位置执行的。但是,由于使用了release-acquire,那么会导致的情况就是,buffer和file_content的访问都被波及。
两者的前面。这样无疑对性能会带来一定的影响。所以c++11这里又定义了sonsume和acquire,就是意图把与真正变量无关的代码剥离出去,让他们能够任意排列。不要被release-acquire误伤。其实就是对PSO模型进行约束
这就是std::memory_order_consume的语义是,所有后续对本原子类型的操作,必须在本操作完成之后才可以执行。简单点就是不得前。但是这个操作只能用来对读进行优化。也就是说release线程是不能使用这个的。也就是说,只能对读依赖的一方进行优化.
注意:std::memory_order_acquire与std::memory_order_consume的区别在于:
std::memory_order_acquire是要求后面所有的读都不得提前。
std::memory_order_consume是要求后面依赖于本次形成读则不能乱序。 一个是针对所有的读,容易形成误伤。而consume只是要求依赖于consume这条语句的读写不得乱序。
// consume example
std::atomic<int*> global_addr{nullptr};
void func(int *data) {
int *addr = global_addr.load(std::memory_order_consume);
int d = *data;
int f = *(data+1);
if (addr) {
int x = *addr;
}
由于global_addr, addr, x形成了读依赖,那么这时候,这几个变量是不能乱序的。但是d,f是可以放到int *addr = global_addr.load(std::memory_order_consume);前面的。
而std::memory_order_acquire则要求d,f都不能放到int *addr = global_addr.load(std::memory_order_consume);的前面。这就是acquire与consume的区别。
- 读写的加强
有时候,可能还需要对读写的顺序进行加强。想一下std::memory_order_release要求的是写不后,也就是后面对内存的写都不能放到本条写语句之后。 但是,有时候可能需要解决这种情况。假设我们需要响应一个硬件上的中断。硬件上的中断需要进行如下步骤。
- a.读寄存器地址1,取出数据checksum
- b.写寄存器地址2,表示对中断进行响应
- c.写flag,标记中断处理完成
由于读寄存器地址1与写flag,标记中断处理完成这两者之间的关系是读写关系。 并不能被std::memory_order_releaes约束。所以需要更强的约束来处理。
这里可以使用std::memory_order_acq_rel,即对本条语句的读写进行约束。即表示写不后,读不前同时生效。 那么就可以保证a, b, c三个操作不会乱序。
即std::memory_order_acq_rel可以同时表示写不后 && 读不前
- 最强约束
std::memory_order_seq_cst表示最强约束。所有关于std::atomic的使用,如果不带函数。比如x.store or x.load,而是std::atomic a; a = 1这样,那么就是强一制性的。即在这条语句的时候 所有这条指令前面的语句不能放到后面,所有这条语句后面的语句不能放到前面来执行。
汇编层的控制
上述都在讨论c++层和cpu层的控制,可以稍微了解一下汇编指令是如何要用什么东西做控制的, 在使用内存屏障的时候,会使用以下宏
#define set_mb(var, value) do { var = value; mb(); } while (0)
#define mb() __asm__ __volatile__ ("" : : : "memory")
mb()对应的内联汇编上:
volatile 用于告诉编译器,严禁将此处的汇编语句与其它的语句重组合优化。即:原原本本按原来的样子处理这这里的汇编, 注意这个__volatile__与c/c++中的volatile是两个东西,c/c++中的volatile 告诉编译器不要将定义的变量优化掉;告诉编译器总是从缓存取被修饰的变量的值,而不是寄存器取值。
memory 强制 gcc 编译器假设 RAM 所有内存单元均被汇编指令修改,这样 cpu 中的 registers 和 cache 中已缓存的内存单元中的数据将作废。cpu 将不得不在需要的时候重新读取内存中的数据。这就阻止了 cpu 又将 registers, cache 中的数据用于去优化指令,而避免去访问内存。
“”:::表示这是个空指令
在linux/include/asm-i386/system.h将mb()定义成如下:
#define mb() __asm__ __volatile__ ("lock; addl $0,0(%%esp)": : :"memory")
lock前缀表示将后面这句汇编语句:"addl
0,0(%%esp)表示将数值0加到esp寄存器中,而该寄存器指向栈顶的内存单元。加上一个0,esp寄存器的数值依然不变。即这是一条无用的汇编 指令。在此利用这条无价值的汇编指令来配合lock指令,在__asm__,volatile,memory的作用下,用作cpu的内存屏障。
关于lock的作用请见2.2.4,其起内存作用的方式是将总线锁住,不给其它cpu进行读写,执行该条指令后,会将脏数据刷到主存,并使所有core的cache lines失效
以上是老板的mb(),后来又引入了新的mfence, lfence, sfence,如下,关于这三者也在控制工具中进行了详述
#define mb() asm volatile("mfence":::"memory")
#define rmb() asm volatile("lfence":::"memory")
#define wmb() asm volatile("sfence" ::: "memory")
Linux C/C+ +开发(后端/音视频/游戏/嵌入式/高性能网络/存储/基础架构/安全)成长体系
整理了一些Linux C/C++高级全栈开发学习书籍、视频资料(后端/游戏/嵌入式/高性能网络/存储/基础架构),有需要的可以自行添加学习交流群:739729163 领取!