Jetson Nano SUB版本创建C++下yolov7的ros包
从本文主要目的在于记录个人在英伟达开发板中部署C++下的yolo整个过程,如果有人遇到相同的情况,可以作为一个参考。整个过程依附于yahboom的Jetson Nano SUB版本,官方提供了多个镜像,安装文件及教程,在开发过程中遇到问题可以参考官方教程。
烧录系统
Jetson Nano SUB版本相比B01版本,删除了TF卡槽,取而代之的是16G空间的EMMC存储芯片。
下图是Jetson Nano SUB版本的侧面实图,但实际插入TF无法读取。
在实际开发中,16G存储空间不足,在该开发板中,安装系统后剩余空间只只有7.9G,无法再安装如CUDA等深度学习工具,故需要准备一个更大的U盘以供存储。

按照官方的教程,使用U盘扩容需要在Nano的核心板中和外部U盘中烧录相同版本的系统,如Nano核心板中的jetpack版本为V4.5.1,则在U盘中也需要烧录进V4.5.1版本才可以运行。USB启动的思路是先启动核心板中的系统,再由核心板的系统引导到U盘中启动。
注意,本文本仅适用于SUB版本的开发板。
烧录EMMC系统
首先需要在英伟达的官方网站中下载SDK Manager,注意,下载该Manager需要拥有一个英伟达账号
JetPack SDK | NVIDIA Developer
截至2023年6月,jetPack SDK已经更新至5.0.2,由于基础环境和算力限制,选择安装4.6.1版本,而Yahboom官网也提供了对应的镜像文件,可直接下载使用。

在这里选择SDK Manager,并下载,下载后会得到一个deb后缀文件,该文件需要在Ubuntu 20.04 或 Ubuntu 18.04系统下安装,如果手边有对应的系统,可直接安装,如没有,则需要安装虚拟机,并安装对应的系统,以安装SDK Manager。
此处我们下载了1.9.2版本的SDK Manager:

输入以下命令安装SDK Manager:
sudo dpkg -i sdkmanager 1.9.2-10899_amd64.deb如果不是该版本,则按照下载的版本进行安装即可。
如果系统提示找不到依赖文件,则需要额外安装其依赖文件
sudo apt \--fix-broken install注意,apt如果下载过慢,可以更换为国内源,方式如下:
首先备份源:
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak将国内的源粘贴到 /etc/apt/sources.list
sudo gedit /etc/apt/sources.list 将下列文字复制进去并保存
deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse
替换完毕执行
apt-get update更新即可。
安装SDK后,打开Ubuntu18.04系统的程序,搜索SDK,可以找到SDKManager,打开文件。


打开后需要使用英伟达账号进行登录。
之后我们需要将开发板接入到PC端中,首先需要让Nano进入系统REC刷机模式中,将跳线帽连接到FC REC和GND引脚,也就是连接到核心板下方载板的第二和第三个引脚,如下图所示:

之后,将microUSB数据线接入到Nano上,之后接通电源。

在虚拟机中选择对应的开发板和jetPack版本,由于官方提供的U盘内镜像为JetPack 4.6.1版本,故开发板也烧录4.6.1版本。

如果使用虚拟机没有读取到开发板的话,要注意是否虚拟机没有接入设备:
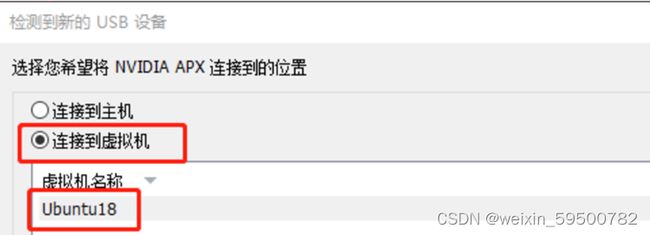
接入虚拟机后,选择需要安装的内容,因为我们会使用U盘进行扩容,因此不需要在开发板中安装额外的内容,仅烧录系统即可:

烧录到最后可能会卡在以下页面,需要手动切换并输入用户名和密码,注意下面输入的内容是开发板将来的用户和密码,而非虚拟机的:

烧录U盘
在烧录完开发板的系统后,我们需要烧录U盘内的系统,yahboom官方提供了JetPack4.6.1版本的镜像,内置了环境,可直接下载使用,烧录U盘,可使用SDFormatter或balenaEtcher,此处使用了balenaEtcher进行烧录:

![]()
该镜像解压后较大,U盘需要有足够的空间。
烧录完成后,将U盘连接到虚拟机中,输入如下命令:
cd boot/extlinux
sudo gedit extlinux.conf把“root=/dev/mmcblk0p1"修改为“root=/dev/sda1”

烧录EMMC引导
完成U盘烧录和EMMC烧录后,需要再在开发板中烧录EMMC引导,首先通烧录EMMC系统一致,将跳线帽连接到FC REC和GND引脚,进入REC刷机模式,接入电源,插入microUSB数据线连接至PC
下载Jetson_Boot_USB.tar.gz并传入Ubuntu系统,并解压:
tar xzvf Jetson_Boot_USB.tar.gz这个Jetson_Boot_USB.tar.gz在yahboom官网上可能不太好找到,可以考虑在第三方处下载
解压后进入Jetson_Boot_USB文件夹,然后运行命令烧录EMMC引导文件
sudo ./flash.sh -r jetson-nano-devkit-emmc mmcblk0p1最后等待文件烧录进入EMMC上,成功会提示:
"The target t210ref has been flashed successfully. Reset the board to boot from internal eMMC."
以上,完成整个Nano的U盘扩容。
Yahboom官方提的镜像详情如下:
账号:jetson
密码:yahboom
已安装:CUDA10.2、CUDNNv8、tensorRT、opencv4.1.1、python2、python3、tensorflow2.3、
jetpack4.6.1、yolov5、jetson-inference包(包括相关模型)、jetson-gpio库、安装pytorch1.8和torchvesion0.9、安装node v15.0.1、npm7.2.3,jupyter,已开启VNC服务。
安装新版本opencv(可选)
Yahboom提供的opencv版本为4.1.1版本,如果需要使用更高版本的opencv,则需要重新安装,注意,如果这里修改了opencv的版本,在后续的安装realsense相机时可能出现问题,到时候需要额外修改realsense的配置文件,如果不需要更高版本的opencv版本,则此步骤可以考虑跳过
清除旧版本
首先完全卸载系统自带的opencv版本
sudo apt-get purge libopencv*
sudo apt autoremove
sudo apt-get update安装cmake以及依赖库
sudo apt-get install cmake
sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg.dev libtiff4.dev libswscale-dev libjasper-dev安装opencv
在opencv官方网址下载源码,官网地址: https://opencv.org/releases/#

下载完成后解压并进行编译:
cd opencv-4.5.4 //进入解压完毕的目录
mkdir build //创建build目录
cd build //生成cmake
cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/usr/local ..
make -j4 //4核编译
sudo make install //安装安装完成后,需要将其添加至环境变量中:
sudo gedit /etc/bash.bashrc //添加环境变量
//在最后加入以下代码
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
source /etc/bash.bashrc
sudo updatedb进行验证:
pkg-config --modversion opencv4 #查看版本号
pkg-config --libs opencv4 #查看libs库安装cv_bridge(可选)
首先卸载原版本cv_bridge:
sudo apt-get remove ros-melodic-cv-bridge安装必要依赖
sudo apt-get install python3-dev python3-numpy python3-yaml ros-melodic-cv-bridge python3-rospkg-modules
pip3 install pip --update
pip3 install rosdep rosinstall catkin_pkg如果pip指令下载慢,可以更换国内源:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple初始化cv_bridge_ws编译工作空间
mkdir -p cv_bridge_ws/src
cd cv_bridge_ws/src
catkin_init_workspace下载cv_bridge源码:
git clone https://github.com/ros-perception/vision_opencv.git编译
cd ../
catkin_make install -DPYTHON_EXECUTABLE=/usr/bin/python3如果有如下报错

则进入工作目录修改CMakeLists.txt
进入报错文件cv_bridge_ws/src/vision_opencv/cv_bridge/CMakeLists.txt,将11行的python37改成python3,然后重新编译。

之后将其加入环境变量中:
gedit ~/.bashrc
source /home/nvidia/cv_bridge_ws/install/setup.bash –extend在python3中验证:
python3import cv_bridge
from cv_bridge.boost.cv_bridge_boost import getCvType如无报错,则安装成功
C++部署yoloV7到nano中
TensorRT 部署流程主要有以下五步:
训练模型
导出模型为 ONNX 格式
选择精度
转化成 TensorRT 模型
部署模型
现假定我们已经完成了yolov7下模型的训练,此处跳过第一个步骤
导出模型为ONNX格式
首先下载 yolov7 最新的源码:
git clone https://github.com/WongKinYiu/yolov7.git为了成功导出 yolov7 ONNX 模型,需要根据上述的注意事项修改 YOLOv7 的源码。
需要注意的是:下述的代码修改仅为了导出 ONNX 模型用于 TensorRT 部署,训练网络或者跑 detect.py 运行 demo 的时候需要改回来,否则会出错。
此外,YOLOv7 默认输出为三个不同尺度的张量,分别为不同层特征金字塔的检测结果,该输出需要结合锚框信息才能转化为预测框。
为了使用方便,我们希望在输出前就完成预测框的计算,并将这三个输出张量合并成一个。(参考 https://github.com/shouxieai/tensorRT_Pro )
修改 ./model/yolo.py 中的 Detect 类的 forward 函数如下:
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(-1, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
else:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
classif = y[..., 4:]
y = torch.cat([xy, wh, classif], -1)
z.append(y.view(-1, self.na * ny * nx, self.no))
if self.training:
out = x
elif self.end2end:
out = torch.cat(z, 1)
elif self.include_nms:
z = self.convert(z)
out = (z, )
else:
out = torch.cat(z, 1)
return out修改 ./model/yolo.py 中的 IDetect 类的 forward 和 fuseforward 函数如下:
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](self.ia[i](x[i])) # conv
x[i] = self.im[i](x[i])
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(-1, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
else:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
classif = y[..., 4:]
y = torch.cat([xy, wh, classif], -1)
z.append(y.view(-1, self.na * ny * nx, self.no))
return x if self.training else torch.cat(z, 1)
def fuseforward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
else:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
classif = y[..., 4:]
y = torch.cat([xy, wh, classif], -1)
z.append(y.view(-1, self.na * ny * nx, self.no))
if self.training:
out = x
elif self.end2end:
out = torch.cat(z, 1)
elif self.include_nms:
z = self.convert(z)
out = (z, )
else:
out = torch.cat(z, 1)
return out修改 ./export.py 文件如下:
import argparse
import sys
import time
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
import models
from models.experimental import attempt_load, End2End
from utils.activations import Hardswish, SiLU
from utils.general import set_logging, check_img_size
from utils.torch_utils import select_device
from utils.add_nms import RegisterNMS
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./yolor-csp-c.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--dynamic', action='store_true', help='dynamic ONNX axes')
parser.add_argument('--grid', action='store_true', help='export Detect() layer grid')
parser.add_argument('--end2end', action='store_true', help='export end2end onnx')
parser.add_argument('--max-wh', type=int, default=None, help='None for tensorrt nms, int value for onnx-runtime nms')
parser.add_argument('--topk-all', type=int, default=100, help='topk objects for every images')
parser.add_argument('--iou-thres', type=float, default=0.45, help='iou threshold for NMS')
parser.add_argument('--conf-thres', type=float, default=0.25, help='conf threshold for NMS')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--simplify', action='store_true', help='simplify onnx model')
parser.add_argument('--include-nms', action='store_true', help='export end2end onnx')
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
t = time.time()
# Load PyTorch model
device = select_device(opt.device)
model = attempt_load(opt.weights, map_location=device) # load FP32 model
labels = model.names
# Checks
gs = int(max(model.stride)) # grid size (max stride)
opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
# Input
img = torch.zeros(opt.batch_size, 3, *opt.img_size).to(device) # image size(1,3,320,192) iDetection
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv) or isinstance(m, models.common.RepConv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# elif isinstance(m, models.yolo.Detect):
# m.forward = m.forward_export # assign forward (optional)
model.model[-1].export = not opt.grid # set Detect() layer grid export
y = model(img) # dry run
if opt.include_nms:
model.model[-1].include_nms = True
y = None
# ONNX export
try:
import onnx
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
model.eval()
output_names = ['classes', 'boxes'] if y is None else ['output']
if opt.grid and opt.end2end:
print('\nStarting export end2end onnx model for %s...' % 'TensorRT' if opt.max_wh is None else 'onnxruntime')
model = End2End(model,opt.topk_all,opt.iou_thres,opt.conf_thres,opt.max_wh,device)
if opt.end2end and opt.max_wh is None:
output_names = ['num_dets', 'det_boxes', 'det_scores', 'det_classes']
shapes = [opt.batch_size, 1, opt.batch_size, opt.topk_all, 4,
opt.batch_size, opt.topk_all, opt.batch_size, opt.topk_all]
else:
output_names = ['output']
torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'],
output_names=output_names,
dynamic_axes={'images': {0: 'batch'}, # size(1,3,640,640)
'output': {0: 'batch'}} if opt.dynamic and not opt.end2end else None)
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
if opt.end2end and opt.max_wh is None:
for i in onnx_model.graph.output:
for j in i.type.tensor_type.shape.dim:
j.dim_param = str(shapes.pop(0))
if opt.simplify:
try:
import onnxsim
print('\nStarting to simplify ONNX...')
onnx_model, check = onnxsim.simplify(onnx_model)
assert check, 'assert check failed'
except Exception as e:
print(f'Simplifier failure: {e}')
# print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable model
onnx.save(onnx_model,f)
print('ONNX export success, saved as %s' % f)
if opt.include_nms:
print('Registering NMS plugin for ONNX...')
mo = RegisterNMS(f)
mo.register_nms()
mo.save(f)
except Exception as e:
print('ONNX export failure: %s' % e)
# Finish
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))上述代码可直接复制并替换原代码即可
导出 ONNX 模型
到 yolov7 源文件根目录下,运行
python export.py --grid --weight=./weights/yolov7-tiny-ft-best.pt --dynamic --img-szie 640 480此处需要把命令行参数中的weight部分改成自己的模型文件路径。img-size参数需要根据自己的输入图像来指定即可,即使使用默认的参数也没有关系,之后推理的时候有图像预处理的部分会将输入图像缩放、填充至模型输入的大小。
由于我们之后输入图像尺寸固定为640×480大小,直接指定模型输入大小与其一致可以减少后续推理时图像预处理和计算结果的后处理部分,节省算力。
转化成 TensorRT 模型
TensorRT C++ 模型推理使用以下Github 仓库GitHub - shouxieai/tensorRT_Pro: C++ library based on tensorrt integration。对于 YOLO C++ 部署只需要下载文件夹 tensorRT_Pro/example-simple_yolo/即可。
该开源项目有以下优点
依赖少:仅依赖官方的 TensorRT 和 OpenCV
文件少:只有 simple_yolo.hpp 和 simple_yolo.cu 两个文件
使用方便:包含了ONNX 模型转 TRT 引擎,图像输入的预处理和后处理,集成了 NMS 非极大抑制算法,且封装简单,易于使用。
实际使用,只需要修改下src/main文件主函数的参数

test函数最后一个参数为 ONNX 模型的文件名,
比如yolov7.onnx就输入yolov7即可
该 ONNX 模型文件需要放到可执行文件同目录下。
第二个参数为指定模型的运算精度
可以为SimpleYolo::Mode::FP32或者SimpleYolo::Mode::FP16。
更低的运算精度部署后速度更快。
再修改下CMakeLists.txt文件,主要需要修改下面几个参数,对于 CUDA_GEN_CODE 参数,Jetson Nano的参数为"-gencode=arch=compute_53,code=sm_53"。
# 如果你是不同显卡,请设置为显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute set(CUDA_GEN_CODE "-gencode=arch=compute_53,code=sm_53") # 如果你的opencv找不到,可以自己指定目录 set(OpenCV_DIR "/usr/include/opencv4/") set(CUDA_DIR "/usr/local/cuda-10.2")
然后编译运行即可:
mkdir build
cd build
cmake ..
make -j8
cd ../workspace
./pro到此步骤为止,我们完成了yolov7的C++部署,但根据实际需要,我们需要将其加入到ros中进行通讯,Yahboom中已经提供了ros,故略过ros的安装,直接完成yolo在ros下的部署
创建yolov7工程
创建工作空间
在home目录下创建名称为yolo_ws的工作空间
mkdir -p ros_yolo_ws/src #新建ros_test_ws/src 目录
cd ros_yolo_ws/src
catkin_init_workspace
cd .. #退到 ros_test_ws 路径下
catkin_make #编译
source devel/setup.bash #配置暂时的环境变量
echo $ROS_PACKAGE_PATH # 查看刚刚配置的环境变量是否生效创建软件包
cd catkin_ws/src # 进入工作空间下的 src 目录 (注意路径!!!)
catkin_create_pkg my_ros_helloworld_cpluse cv_bridge image_transport message_filters std_msgs rospy roscpp sensor_msgs
cd .. #退到 catkin_ws 工作空间路径下
catkin_make #编译软件包这里我们需要搭载yolo并进行图像传输,所以额外补充了一些包,如仅单独运行一个普通的C++程序则不需要这么多
编写c++程序
在我的程序逻辑下,我需要同时处理两个图像,一张是当前帧的彩色图像,一张是当前帧的深度图像,我们使用message_filters::Synchronizer对订阅的话题进行同步
为了调用方便,我们需要对程序进行封装,这里封装为一个yoloDetect的对象
class yoloDetect {
private:
SimpleYolo::Type MyType;
ros::NodeHandle nh;
ros::Publisher yolo_image_pub;
ros::Subscriber yolo_sub;
message_filters::Subscriber *col_image;
message_filters::Subscriber *dep_image;
message_filters::Synchronizer *sync;
shared_ptr engine;
public:
yoloDetect(int, const string, SimpleYolo::Type);
void detectImg(cv_bridge::CvImagePtr, cv_bridge::CvImagePtr);
void transfer(const sensor_msgs::ImageConstPtr&, const sensor_msgs::ImageConstPtr&);
void listener();
}; 其中
SimpleYolo::Type MyType;
shared_ptr engine; 是之前“C++部署yoloV7到nano中”部分中需要用的部分,我们需要在yoloDetect类中单独创建出来方便我们后期的调用
定义构造函数:
typedef message_filters::sync_policies::ApproximateTime MySyncPolicy;
yoloDetect::yoloDetect(int deviceid, const string engine_file, SimpleYolo::Type type) {
MyType = type;
yolo_image_pub= nh.advertise("/你的发布话题名", 1);
col_image = new message_filters::Subscriber(nh, "/camera/color/image_raw", 1);
dep_image = new message_filters::Subscriber(nh, "/camera/depth/image_rect_raw", 1);
sync = new message_filters::Synchronizer (MySyncPolicy(1), *col_image, *dep_image);
engine = SimpleYolo::create_infer(engine_file, type, deviceid, 0.4f, 0.5f);
if (engine == nullptr) {
printf("Engine is nullptr\n");
return;
}
} 我们在这里需要定义以下规则,我们每次需要订阅两个Image,队列长度为1,并将上述的
SimpleYolo::Type MyType;
shared_ptr engine; 给定一个赋值
在推理时,我定义了一个detectImg方法,对获取的图像进行推理
在方法中,由于tensorRT_Pro-main中需要传入的是vectorcv::Mat格式,直接调用cv_bridge::CvImagePtr获取不到图片,所以我们需要对部分内容进行修改
void yoloDetect::detectImg(cv_bridge::CvImagePtr img_color, cv_bridge::CvImagePtr img_depth) {
vector> boxes_array;
vector images;
images.push_back(img_color->image);
boxes_array = engine->commits(images);
images.clear();
//你的其他代码
} 在这之后,我们画框也需要指定img_color->image,这里各项参数可以根据实际需要调整
cv::rectangle(img_color->image, cv::Point(obj.left, obj.top), cv::Point(obj.right, obj.bottom), cv::Scalar(b, g, r), 5);之后我们创建一个监听时需要调用的方法,以便同时获取两个图像,在此部份内,我们需要使用cv_bridge进行传输
void yoloDetect::transfer(const sensor_msgs::ImageConstPtr& image1,const sensor_msgs::ImageConstPtr& image2) {
cv_bridge::CvImagePtr img_color = cv_bridge::toCvCopy(image1, sensor_msgs::image_encodings::BGR8);
cv_bridge::CvImagePtr img_depth = cv_bridge::toCvCopy(image2, "mono16");
yoloDetect::detectImg(img_color, img_depth);
}之后创建一个监听方法
void yoloDetect::listener() {
sync->registerCallback(boost::bind(&yoloDetect::transfer, this, _1, _2));
ros::spin();
engine.reset();
}在原有的tensorRT_Pro-main方法中,我们使用的是inference_and_performance方法进行的推断,但因为我们封装了一个yoloDetect对象,因此需要修改这个方法
static void inference_and_performance(int deviceid, const string& engine_file, SimpleYolo::Mode mode, SimpleYolo::Type type, const string& model_name) {
yoloDetect yolo = yoloDetect(deviceid, engine_file, type);
yolo.listener();
}我们在这里使用参数去实例化一个yoloDetect对象,调用监听方法
最后,我们修改main方法,使其可以调用到我们自己的模型,而不是在网上额外下载模型,注意,这里的路径一定要指到模型所在的那一级,模型的后缀应为.onnx,此处代码会为我们自行添加.onnx后缀,不需要我们自己添加,如果添加则会读取yolo.onnx.onnx,会导致无法读取到模型
int main(int argc,char** argv){
ros::init(argc, argv, "yolo_detect");
test(SimpleYolo::Type::V7, SimpleYolo::Mode::FP32, "/home/jetson/yolo_ws/src/yolo/src/yolo");
}如果需要再将检测的图像发布出去,则需要在代码中补充发布的代码
yolo_image_pub.publish(img_color);这里的yolo_image_pub是我上面定义对象是写的内容
yolo_image_pub= nh.advertise("/你的发布话题名", 1); 在这里需要你自己定义你的发布话题名称
此上,我们便完成了C++程序的编写
如果需要修改置信度,则在simple_yolo.hpp内修改第74行的confidence_threshold,同样,其他参数也可在此处修改
shared_ptr create_infer(const string& engine_file, Type type, int gpuid, float confidence_threshold=0.25f, float nms_threshold=0.5f); 安装Realsense相机驱动
本工程使用的是Realsense的D435I相机,安装相机需要完成两个步骤
Realsense相机驱动
编译Realsense相机的Ros包
其中第一步是完成D435i的本地运行,第二步则是将其加入ros中,以便我们的c++代码去订阅他的图像话题
安装驱动时,只有测试的时候需要接入相机,其他的时候不需要接入相机
安装Realsense相机驱动
# 下载安装包
git clone https://github.com/IntelRealSense/librealsense.git
cd librealsense
# 更新依赖库
sudo apt-get update && sudo apt-get upgrade && sudo apt-get dist-upgrade
# 安装依赖库
sudo apt-get install libudev-dev pkg-config libgtk-3-dev
sudo apt-get install libusb-1.0-0-dev pkg-config
sudo apt-get install libglfw3-dev
sudo apt-get install libssl-dev
# 运行Intel Realsense许可脚本
./scripts/setup_udev_rules.sh
# 下载并编译内核模块
./scripts/patch-realsense-ubuntu-lts.sh
# 编译SDK2.0
cd librealsense
mkdir build
cd build
cmake ../ -DBUILD_EXAMPLES=true
make
sudo make install
# 测试
cd examples/capture
./rs-capture
# 打开realsense-viewer
realsense-viewer编译Realsense相机的Ros包
# 建立workspace
mkdir -p ~/catkin_ws/src
cd ~/catkin_ws/src/
catkin_init_workspace
cd ..
catkin_make
echo "source ~/catkin_ws/devel/setup.bash" >> ~/.bashrc
source ~/.bashrc
# 在catkin_ws/src/下载源程序
cd src
git clone https://github.com/IntelRealSense/realsense-ros.git
git clone https://github.com/pal-robotics/ddynamic_reconfigure.git
# catkin_make编译
cd ~/catkin_ws && catkin_make
# 测试
roslaunch realsense2_camera demo_pointcloud.launch
# 其他测试
## 查看发布的topic
rostopic list
rostopic echo /camera/aligned_depth_to_color/camera_info
注:aligned_depth_to_color是指已经将深度信息通过相机到RGBD的外参映射到彩色图像上如果我们在更改opencv版本的时候修改了opencv的版本,则此处可能会提示缺少opencv的文件,此时我们需要修改realsense-ros包里面的cmakelist文件,让其可以找到opencv的目录
打开/home/jetson/catkin_ws/src/realsense-ros/realsense2_camera下的CMakeLists.txt
在其中添加
set(OpenCV_DIR /usr/lib/aarch64-linux-gnu/cmake/opencv4)
# 在find_package中添加
OpenCV REQUIRED# 在include_directoried中添加
{OpenCV_INCLUDE_DIRS}# 在target_link_libraries中添加
${OpenCV_LIBS}
这里OpenCV_DIR的路径可以使用mlocate来进行查找,具体可以在网上查找安装方式,此处不再赘述,我这里/usr/lib/aarch64-linux-gnu/cmake/opencv4可以完成编译,所以直接使用了这个路径,如果不行可以尝试其他路径,注意,该路径下面应当有缺少的那两个cmake文件,如果没有,可能需要更换路径
测试
到目前位置,我们应当有了完整的运行环境和代码,此时进入我们编写的yolo的c++代码目录,我这里是yolo_ws,进入命令行模式运行
catkin_make完成后检查以下bashrc文件,是否有我们的代码
sudo gedit ~/.bashrc这里应该有如下的部分
source ~/cv_bridge_ws/install/setup.bash --extend
source ~/yolo_ws/devel/setup.bash
source ~/catkin_ws/devel/setup.bash
如果没有的话,需要补充一下,之后
source ~/.bashrc如果catkin_make报错,则需要根据报错修改一下代码,之后如果又修改了代码,则需要进入yolo_ws中重新执行catkin_make
之后我们分别在三个窗口依次执行如下指令
roscoreroslaunch realsense2_camera rs_aligned_-depth.launch这里是因为我需要使用对齐后的深度图,所以使用了这个指令,如果需要使用别的指令,可以进入/home/jetson/catkin_ws/src/realsense-ros/realsense2_camera/launch目录下查看那个是实际需要使用的,此外,可以修改.launch文件修改参数,详细各个参数的含义可在网上找到,此处不再赘述
rosrun yolo yolo我这里发布了框选完的图像话题,可以在rviz中查看我们刚才yolo检测的内容
rviz在窗口中订阅你发布的话题即可查看到结果
参考:
JETSON NANO B01
GitHub - shouxieai/tensorRT_Pro: C++ library based on tensorrt integration
ubuntu apt 更换为国内源 – 胡超博客
Ubuntu 编译opencv4.5.4+opencv_contrib_ubuntu编译opencv+contrib_哩lililili的博客-CSDN博客
Project ‘cv_bridge‘ specifies ‘/usr/include/opencv‘ as an include dir, which is not found的解决方法_project 'cv_bridge' specifies '/usr/include/opencv_谛听misa的博客-CSDN博客
NVIDIA jetson 在ROS-meloidc中使用python3 cv_bridge_Ponnyao的博客-CSDN博客
YOLOv7 部署到 TensorRT(C++ ) - 知乎
【精华】ROS学习(二):Realsense ROS驱动安装_LeeZhao@的博客-CSDN博客r
如有侵权,请联系删除