SpringCloudStream集成MQ中间件
第零章 序
提问:
众所周知,MQ的集成方案及中间件有很多中,如现在主流的产品:RabbitMQ、RocketMQ、ActiveMQ、KafKa;但有时很意外的是:公司业务服务使用的RabbitMQ,而数据库后台使用的是KafKa,整个项目中使用了2种MQ,可能会导致切换困难,维护成本高等因素。
我们能否像Hibernate时那样,不管底层是Oracle还是MySql亦或者其他数据库,只要给我一组统一的API操作即可?而现在的SpringCloud-Stream就相当于MQ的统一接口。
1、MQ概念
发布/订阅

简单的讲就是一种生产者,消费者模式。发布者是生产,将输出发布到数据中心,订阅者是消费者,订阅自己感兴趣的数据。当有数据到达数据中心时,就把数据发送给对应的订阅者。
消费组
直观的理解就是一群消费者一起处理消息。需要注意的是:每个发送到消费组的数据,仅由消费组中的一个消费者处理。
分区
类比于消费组,分区是将数据分区。举例:某应用有多个实例,都绑定到同一个数据中心,也就是不同实例都将数据发布到同一个数据中心。分区就是将数据中心的数据再细分成不同的区。为什么需要分区?因为即使是同一个应用,不同实例发布的数据类型可能不同,也希望这些数据由不同的消费者处理。这就需要,消费者可以仅订阅一个数据中心的部分数据。这就需要分区这个东西了。
第一章 SpringCloud Stream简介
官网链接:https://spring.io/projects/spring-cloud-stream#overview
中文链接:https://m.wang1314.com/doc/webapp/topic/20971999.html
1、是什么
一句话:屏蔽底层消息中间件的差异,降低切换版本,统一消息的编程模型
2、设计思想
标准的MQ

-
生产者/消费者之间靠消息媒介传递消息内容:Message
-
消息必须走特定的通道:消息通道MessageChannel
-
消息通道里的消息如何被消费呢?谁负责收发消息:消息通道MessageChannel的子接口SubscribableChannel,由MessageHandler消息处理器订阅
为什么要用Cloud Stream
比如说我们用到了RabbitMQ和KafKa,由于这两个消息中间件的架构上的不同,像RabbitMQ有Exchange,KafKa有Topic和Partitions分区。
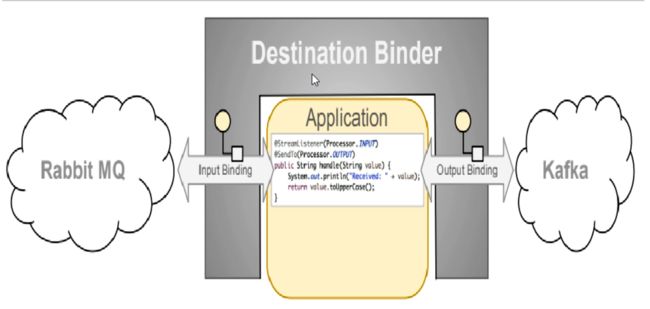
这些中间件的差异性导致我们实际项目开发给我们造成了一定的困扰,我们如果用了两个消息队列的其中一种,后面的业务需求,我想往另外一种消息队列进行迁移,这时候无疑就是一个灾难性的,一大堆东西都要重新推倒重新做,因为它跟我们的系统耦合了,这时候SpringCloud Stream给我们提供了一种解耦合的方式。
CloudStream怎么统一底层差异性
在没有绑定器这个概念的情况下,我们的SpringBoot应用要直接与消息中间件进行信息交互的时候,由于各消息中间件构建的初衷不同,它们的实现细节上会有较大的差异性。
而CloudStream通过定义绑定绑定器作为中间层,完美地实现了应用程序与消息中间件细节之间的隔离。
通过向应用程序暴露统一的Channel通道,使得应用程序不需要再考虑各种不同消息中间件的实现。
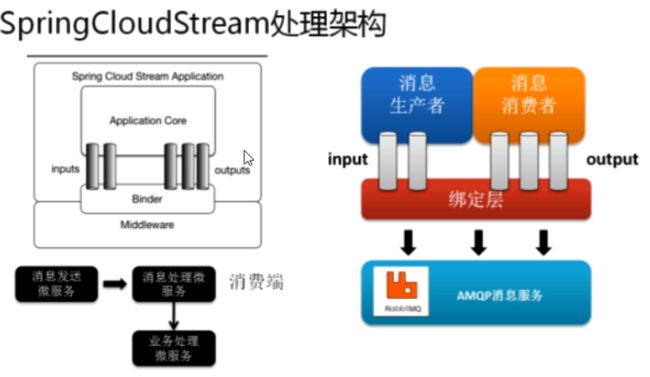
通过Binder(绑定器)作为中间层,实现了应用程序与消息中间件细节之间的隔离,屏蔽底层消息中间件差异,统一开发风格。
- INPUT对应于消费者
- OUTPUT对应于生产者
CloudStream中的消息通信方式遵循了发布-订阅模式,Topic主题方式进行广播,在RabbitMQ就是Exchange,在KafKa中就是Topic。
3、CloudStream标准流程套路

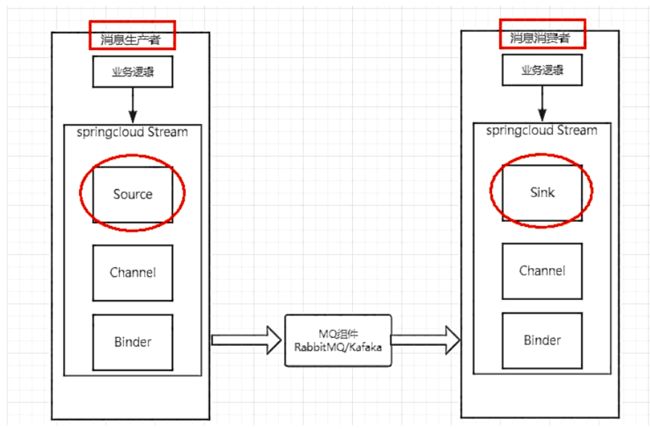
-
Binder:很方便的连接中间件,屏蔽差异
-
Channel:通道,是队列Queue的一种抽象,在消息通讯系统中就是实现存储和转发的媒介,通过对Channel对队列进行配置
-
Source和Sink:简单的可理解为参照对象是Spring Cloud Stream自身,从Stream发布消息就是输出,接受消息就是输入
4、编码API和常用注解
| 组成 | 说明 |
|---|---|
| Middleware | 中间件,目前只支持RabbitMQ和Kafka |
| Binder | Binder是应用与消息中间件之间的封装,目前实行了Kafka和RabbitMQ的Binder,通过Binder可以很方便的连接中间件,可以动态的改变消息类型(对应于Kafka的topic,RabbitMQ的exchange),这些都可以通过配置文件来实现 |
| @Input | 注解标识输入通道,通过该输入通道接收到的消息进入应用程序 |
| @Output | 注解标识输出通道,发布的消息将通过该通道离开应用程序 |
| @StreamListener | 监听队列,用于消费者的队列的消息接收 |
| @EnableBinding | 指信道channel和exchange绑定在一起 |
第二章 实战SpringCloud Stream
激动吧,说了那么多,终于要实战了!!!
1、前菜
-
CloudStream目前整合了KafKa和RabbitMQ两个中间件,而这里我们则使用RabbitMQ来进行案例测试
-
启动RabbitMQ
-
启动Nacos
-
消息生产服务blade-stream-provider
-
消息消费服务blade-stream-consumer-a
-
消息消费服务blade-stream-consumer-b
2、创建生产者服务
POM
org.springframework.cloud
spring-cloud-starter-stream-rabbit
YML
spring:
cloud:
stream:
# 进行rabbit的相关绑定配置
rabbit:
bindings:
stream-output:
# 进行生产端端配置
producer:
#定义 RoutingKey 的表达式配置
routing-key-expression: '''stream-key'''
# 在此处配置要绑定的rabbitmq的服务信息;
binders:
# 表示定义的名称,用于于binding整合
default-rabbit:
# 消息组件类型
type: rabbit
# 设置rabbitmq的相关的环境配置
environment:
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
virtual-host: /
# 服务的整合处理
bindings:
# 设定通道的名称
stream-output:
# 设定Exchange名称定义
destination: queue.stream.messages
# 设定消息类型,对象类型,如果是文本则设置"text/plain"
content-type: application/json
# 设置要绑定的消息服务的定义名称
binder: default-rabbit
# 进行操作的分组,表示持久化
group: stream-group
#数据源配置
datasource:
url: ${blade.datasource.dev.url}
username: ${blade.datasource.dev.username}
password: ${blade.datasource.dev.password}
业务类


3、创建消费者A
POM
org.springframework.cloud
spring-cloud-starter-stream-rabbit
YML
spring:
cloud:
stream:
# 进行rabbit的相关绑定配置
rabbit:
bindings:
stream-input:
# 进行消费端配置
consumer:
# 设置一个RoutingKey信息
bindingRoutingKey: stream-key
# 在此处配置要绑定的rabbitmq的服务信息;
binders:
# 表示定义的名称,用于于binding整合
default-rabbit:
# 消息组件类型
type: rabbit
# 设置rabbitmq的相关的环境配置
environment:
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
username: guest
password: guest
virtual-host: /
# 服务的整合处理
bindings:
# 设定通道的名称
stream-input:
# 设定Exchange名称定义
destination: queue.stream.messages
# 设定消息类型,对象类型,如果是文本则设置"text/plain"
content-type: application/json
# 设置要绑定的消息服务的定义名称
binder: default-rabbit
# 进行操作的分组,表示持久化
group: stream-group
#数据源配置
datasource:
url: ${blade.datasource.dev.url}
username: ${blade.datasource.dev.username}
password: ${blade.datasource.dev.password}
业务类
4、创建消费者B
同上消费者A
5、启动测试
第三章 SpringCloud Stream进阶
现在运行会存在两个问题:
1、有重复消费问题
2、消息持久化问题
1、重复消费
前提:
比如在如下场景中,订单系统我们做集群部署,都会从RabbitMQ中获取订单信息,那如果一个订单同时被两个服务获取到,那么就会造成数据错误,我们得避免这种情况。
这时我们就可以使用Stream中的消息分组来解决

注意在Stream中处于同一个group中多个消费者是竞争关系,就能保证消息只会被其中一个应用消费一次。
不同组是可以全面消费的(重复消费),同一组内会发生竞争关系,只有其中一个可以消费。
如何解决
目前两个消费者都同时收到消息了,是因为他们监听的是不是同一个消息队列
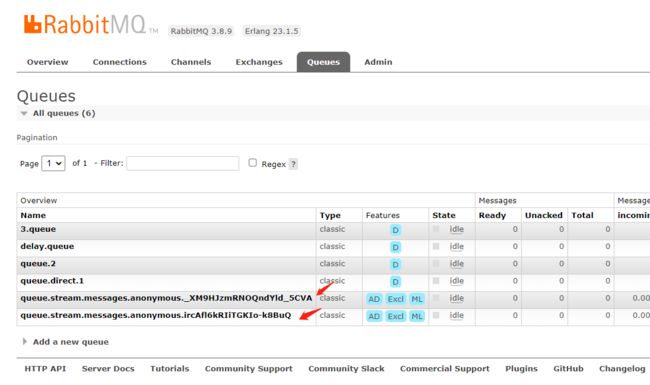
解决方案就是加上分组,在RabbitMQ中就是对应的消息队列名称。如下图
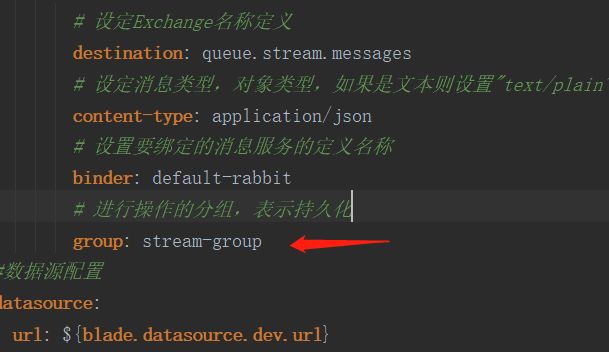
两个消费者设置同一个分组,也就会监听到同一个消息队列,其中消息也就发生了竞争关系,一个消息只能被一个消费者消费。
2、消息持久化
消息持久化的问题其实就是生产者在发送消息,而消费者服务器挂掉,导致消息丢失的问题
实现场景:停止消费者A、B,并且去掉B的分组,然后让消费者开始发送消息,这时再启动A和B,观察消息消费情况。
会发现B消费者消息丢失,而A消费者并没有。
解决方案:
- 设置多个消费者,保证服务器挂掉出现的丢失问题
- 不要随意的修改消息MQ的固定配置,如分组,消息队列名称等。
如果想要替换成KafKa,只需要替换Jar即可