SQL Sever 复习笔记
SQL Sever 重点-存储过程
- 一、SQL Server 存储过程
-
- 第1节 SQL Server 存储过程基本点
-
- 1.1 创建简单的存储过程
- 1.2 修改存储过程
- 1.3 删除存储过程
- 第2节 SQL Server 存储过程参数
-
- 2.1 创建一个传参存储
- 2.2 使用一个参数执行存储过程
- 2.3 创建具有多个参数的存储过程
- 2.4 使用多个参数执行存储过程
- 2.5 创建可选参数
- 2.6 可选参数执行存储过程
- 第3节 SQL Sever中的变量
-
- 3.1 什么是变量
- 3.2 声明变量
- 3.3 为变量赋值
- 3.4 变量显示
- 3.5 在查询中使用变量
- 3.6 将查询结果存储在变量中
- 3.7 将值累积到变量中
- 第4节 SQL Server 存储过程输出参数
-
- 4.1 创建输出参数
- 4.2 使用输出参数调用存储过程
- 二、控制流语句
-
- 第1节 BEGIN...END
-
- 1.1 声明概述 BEGIN...END
- 1.2 BEGIN...END可嵌套
- 第2节 IF...ELSE
-
- 2.1 控制流语句 IF
- 2.2 声明IF...ELSE
- 2.3 IF...ELSE嵌套(不建议使用,增加代码阅读成本和维护成本)
- 第3节 WHILE
-
- 3.1 WHILE - 条件重复执行语句
- 3.2 变量
- 3.3 BREAK 语句 - 立即退出循环,并在循环中跳过循环后的其余代码。
- 3.4 CONTINUE 语句 - 立即跳过循环的当前迭代并继续下一个迭代
- 三、SQL Server 游标
-
- 什么是数据库游标
- SQL Server 游标的生命周期
- 游标使用实例
- 四、处理异常
-
- 第1节 TRY...CATCH构造
-
- 1.1 TRY...CATCH构造
- 1.2 CATCH 块功能
- 1.3 嵌套TRY...CATCH 结构
- 1.4 TRY...CATCH 示例
- 1.5 带事务TRY...CATCH
- 第2节 RAISERROR
-
- 2.1 SQL Server 语句概述RAISEERROR
- 2.2 message_id字段 - 消息编号
- 2.3 message_text字段 - 消息正文
- 2.3 severity字段 - 严重程度
- 2.4 state字段 - 状态
- 2.5 WITH option字段 - 选项
- 2.6 SQL Server RAISERROR 示例
-
- 2.6.1 使用SQL Server RAISERROR 和 TRY CATCH 块示例
- 2.6.2 使用SQL Server RAISERROR 语句和动态消息文本示例
- 2.7 何时使用 RAISERROR 语句
- 第3节 THROW
-
- 3.1 SQL Server THROW 语句概述
- 3.2 SQL Server THROW 语句示例
-
- 3.2.1 使用 THROW 语句引发异常
- 3.2.2使用 THROW 语句重新抛出异常
- 3.2.3 使用 THROW 语句重新抛出异常
- 3.3 THROW 对比 RAISERROR
- 五、动态SQL
-
- 动态SQL简介
- 使用动态SQL查询任意表示例
- SQL Server动态SQL和存储过程
- SQL Server 动态 SQL 和 SQL 注入
一、SQL Server 存储过程
第1节 SQL Server 存储过程基本点
即SQL Server 中管理存储过程,包括创建、执行、修改和删除存储过程。
1.1 创建简单的存储过程
以下查询语句返回用户购买课程订单表中,用户id,购买课程和购买状态信息。
select user_id,product_name,status
from order_info
order by user_id
若要创建包装此查询的存储过程,可使用如下存储:
CREATE PROCEDURE sel_order_info
AS
BEGIN
select user_id,product_name,status
from order_info
order by user_id
END;
执行成功后会在数据库列表查看此存储过程:

执行存储过程:
EXECUTE sel_order_info
-- or
exec sel_order_info
1.2 修改存储过程
修改流程:找到需要修改存储——>右键——>点击modify——>修改存储代码——>点击执行按钮

修改或查看存储都通过Modify查看,打开存储代码如下:
USE [F_stu_db]
GO
/****** Object: StoredProcedure [dbo].[sel_order_info] Script Date: 2023/11/23 18:19:58 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[sel_order_info]
AS
BEGIN
select user_id,product_name,status
from order_info
order by user_id
END;
打开存储后根据需求修改存储代码即可。修改完成后点击执行,输出台会输出成功提示:
Commands completed successfully.
1.3 删除存储过程
若要删除存储过程,使用 DROP PROCEDURE or DROP PROC语句
drop proc <存储名称>
--------------------------------
drop procedure sel_order_info
-- or
drop proc sel_order_info
第2节 SQL Server 存储过程参数
即存储过程允许向其传递一个或多个值,存储过程的结果将根据参数的值而更改。
2.1 创建一个传参存储
要求根据购买课程名称,查询该课程购买的订单相关数据,创建存储代码如下:
CREATE PROCEDURE sel_order_info
@product_name char(7) --定义变量
AS
BEGIN
select user_id,product_name,status
from order_info
where product_name = @product_name
order by user_id
END;
添加了一个名为product_name 存储过程的参数,每个参数都必须以符号开头,关键字指定参数的数据类型。在select语句的子句中使用了参数,仅查寻所带参数名称的课程。
2.2 使用一个参数执行存储过程
查询‘python’课程购买的单情况:
exec sel_order_info 'python'
执行结果:

将参数更换为‘C++’
exec sel_order_info 'C++'
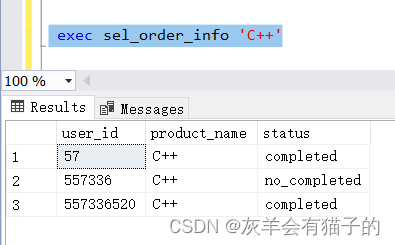
2.3 创建具有多个参数的存储过程
要求根据购买课程名称及订单状态,查询该课程购买的订单相关数据,直接修改上面存储代码,增添一个变量即可,代码如下:
USE [F_stu_db]
GO
/****** Object: StoredProcedure [dbo].[sel_order_info] Script Date: 2023/11/23 18:19:58 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[sel_order_info]
@product_name char(7), --定义变量
@status char(15) --定义变量
AS
BEGIN
select user_id,product_name,status
from order_info
where product_name = @product_name
and status = @status
order by user_id
END;
提示:如果存储过程具有多个参数,则使用命名参数执行存储过程会更好、更清晰。
2.4 使用多个参数执行存储过程
查询‘python’课程且订单购买完成的订单情况:
exec sel_order_info 'python','completed'
执行结果:
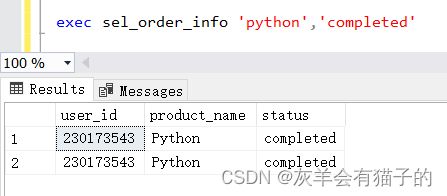
查询‘c++’课程且订单购买未完成的订单情况:
exec sel_order_info 'c++','no_completed'
执行结果:

2.5 创建可选参数
在执行含参存储过程时,必须传递与之对应的参数。SQL Server 允许指定参数的默认值,以便在调用存储过程时,可以跳过具有默认值的参数。
我们修改上例存储,代码如下:
USE [F_stu_db]
GO
/****** Object: StoredProcedure [dbo].[sel_order_info] Script Date: 2023/11/24 8:41:23 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[sel_order_info]
@product_name char(7) , --定义变量
@status char(15) = 'completed' --定义变量,设置默认参数值为completed
AS
BEGIN
select user_id,product_name,status
from order_info
where product_name = @product_name
and status = @status
order by user_id
END;
在此存储过程中,将参数@status设置为默认参数并分配默认值’completed’。编译存储过程后,可以在不传递@status参数的情况下执行它。当然也可以传递新值,执行时新值会替换默认值。
2.6 可选参数执行存储过程
查询‘python’课程且订单购买完成的订单情况:
exec sel_order_info @product_name = 'python'
执行结果如下:

查询‘c++’课程且订单购买未完成的订单情况(此时需要传递新值,因为参数默认是完成状态):
exec sel_order_info @product_name = 'c++',@status = 'no_completed'
执行结果如下:

So:我们可以发现含参存储可设置部分或全部参数为默认参数(即初始化赋值),且在执行时可赋新值,在执行赋值时需要参数名赋值,参数名不能省略。
第3节 SQL Sever中的变量
内容包括声明变量、设置变量值以及将记录的值字段分配给变量。存储过程中的参数就是变量。
3.1 什么是变量
变量是保存特定类型的单个值的对象,例如整数、日期或可变字符串。
我们通常在以下情况下使用变量:
1、作为循环计数器,用于计算循环执行的次数。
2、保存要由流控制语句(如 while)测试的值。
3、存储存储过程或函数返回的值
3.2 声明变量
声明变量就是分配名称和数据类型来初始化变量,定义关键字DECLARE;
变量名称必须以@符号开头;
同时声明多个变量可用逗号隔开;
默认情况下,声明变量时,其值设置为 NULL。
declare @<变量名1> <数据类型>,@<变量名2> <数据类型>...
举例如下:
DECLARE @name CHAR(8),@sex CHAR(2),@age INT
DECLARE @address CHAR(50)
3.3 为变量赋值
关键字SET,或使用select赋值;
set赋值时每次只能赋值一个变量,但select可同时赋值多个变量同样用逗号隔开;
赋值与定义变量时的数据类型对应,可以是数字、字符、字符串等。
--set赋值
set @<变量名> = <值>
--select 赋值
select @<变量名1> = <值1>,@<变量名2> = <值2>....
举例如下:
SELECT @name = 'Flyer',@sex = '男',@age = '22'
SET @address = 'Shanghai, China'
3.4 变量显示
使用PRINT或SELECT查看变量值,显示结果和方式不同:
DECLARE @name CHAR(8),@sex CHAR(2),@age INT
DECLARE @address CHAR(50)
SELECT @name = 'Flyer',@sex = '男',@age = '22'
SET @address = 'Shanghai, China'
print @name
print @sex
print @age
print @address
执行结果:

DECLARE @name CHAR(8),@sex CHAR(2),@age INT
DECLARE @address CHAR(50)
SELECT @name = 'Flyer',@sex = '男',@age = '22'
SET @address = 'Shanghai, China'
select @name as '姓名',@sex as '性别',@age as '年龄',@address as '现居地'
执行结果:

3.5 在查询中使用变量
现有一张员工工资表,里面有员工编号,工资,和入职时间等信息,要求查询2001年入职的员工及相关信息:
DECLARE @iYear int --声明变量
SET @iYear = 2001 --赋值2001年
select *
from salaries
where year(from_date) = @iYear --入职时间是具体日期,可以使用year()函数提取年份
执行结果如下:

3.6 将查询结果存储在变量中
要求查询2001年入职的员工人数:
DECLARE @iYear int,@cnt_id int
SET @iYear = 2001
SET @cnt_id = ( --变量接收结果
select count(*) --count()函数统计总个数
from salaries
where year(from_date) = @iYear
)
PRINT convert(varchar,@iYear)+'年入职的员工共有:'+convert(varchar,@cnt_id)+'人。' --convert()函数用于转换字符串类型
执行结果:
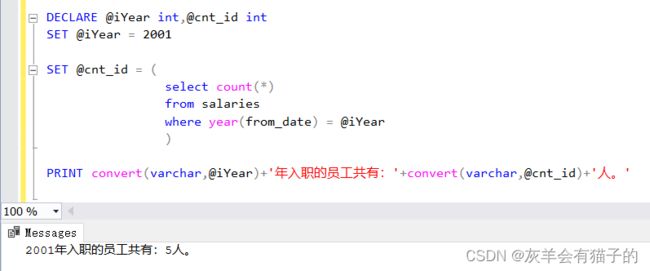
3.7 将值累积到变量中
通过存储过程方式,查询输出2001年入职员工的ID:
CREATE PROC GetuserID (
@iYear int
) AS
BEGIN
DECLARE @print_list VARCHAR(MAX);
SET @print_list = '';
SELECT
@print_list = @print_list + convert(char,emp_no)
+ CHAR(10) ---- CHAR(10)表示回车换行
FROM
salaries
WHERE
year(from_date) = @iYear
ORDER BY
emp_no desc;
PRINT @print_list;
END;
在此存储过程中:
声明了一个名为 @print_list 的变量,该变量具有不同的字符串类型,并将其值设置为空;根据输入@iYear 从 salaries 表中选择 emp_no 名称列表,在选择列表中将员工ID累积到 @print_list 变量中;
Note:CHAR(10)返回换行符;使用PRINT语句打印出产品列表。
执行存储过程:
exec GetuserID 2001
查询结果:

第4节 SQL Server 存储过程输出参数
使用输出参数将数据返回给调用程序。
4.1 创建输出参数
存储过程可以具有许多输出参数。此外,输出参数可以是任何有效的数据类型,例如整数、日期和可变字符。若要为存储过程创建输出参数,可使用以下语句:
<参数名> <数据类型> OUTPUT
创建一个存储过程,要求带参传入年份,带参输出次年分入职的总人数,代码如下:
CREATE PROCEDURE get_cnt_id
@iYear int,
@cnt int output
AS
BEGIN
SELECT @cnt = count(*)
FROM salaries
WHERE year(from_date) = @iYear
SELECT @cnt as '总人数'
END;
4.2 使用输出参数调用存储过程
使用输出参数调用存储过程,需按照一下步骤操作:
1、声明变量以保存输出参数返回的值;
2、在存储过程调用中使用这些变量。
执行 get_cnt_id 存储过程,如下:
declare @cnt int --声明变量以保存存储过程的输出参数的值
exec get_cnt_id 2001,@cnt output --执行存储过程并传递参数,如果忘记了变量后面的关键字output,则@cnt变量将为 NULL
执行结果:
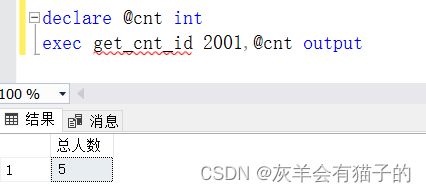
二、控制流语句
第1节 BEGIN…END
创建一个语句块,该语句块由多个一起执行的 Transact-SQL 语句组成。
1.1 声明概述 BEGIN…END
该语句用于定义语句块,语句块由一组一起执行的 SQL 语句组成。BEGIN…END语句块也称为批处理。如果语句是句子,则BEGIN…END语句允许定义段落。声明格式如下:
BEGIN
{ sql_statement | statement_block}
END
实例代码语句如下:
BEGIN
SELECT @cnt = count(*)
FROM salaries
WHERE year(from_date) = @iYear
SELECT @cnt as '总人数'
END
语句限制SQL语句的逻辑块,经常在存储过程和函数的开头和结尾使用,这并不是绝对必要的,但是对于需要包装多个不同语句的时候需要。
1.2 BEGIN…END可嵌套
BEGIN
...
{ sql_statement | statement_block}
BEGIN
{ sql_statement | statement_block}
END
BEGIN
{ sql_statement | statement_block}
END
...
END
第2节 IF…ELSE
根据条件执行语句块。
2.1 控制流语句 IF
IF [条件]
BEGIN
{ SQL语句块 }
END
在此语法中,如果计算结果为True,则执行块中的。否则,将跳过,并将程序的控制权传递给关键字后面的语句。
begin
Declare @cnt int
select @cnt = count(id)
from grade_new
--select @cnt as 总课程数
if @cnt > 5
begin
print N'总课程数超过5个。'
end
end
执行结果:
总课程数超过5个。
2.2 声明IF…ELSE
IF [条件]
BEGIN
{ SQL语句块 } -- 条件 is TRUE
END
ELSE
BEGIN
{ SQL语句块 } -- 条件 is FALSE
END
每个语句都有一个条件。如果条件的计算结果为TRUE,则执行子句中的语句块。如果条件是FALSE,则执行子句中的代码块
代码实例:
begin
Declare @cnt int
select @cnt = count(id)
from grade_new
--select @cnt as 总课程数
if @cnt > 10
begin
print N'总课程数超过5个。'
end
else
begin
print N'总课程数不足10个。'
end
end
执行结果:
总课程数不足10个。
2.3 IF…ELSE嵌套(不建议使用,增加代码阅读成本和维护成本)
实例代码如下:
begin
Declare @cnt int
select @cnt = count(id)
from grade_new
--select @cnt as 总课程数
if @cnt > 5
begin
if @cnt > 10
begin
print N'总课程数超过10个。'
end
else
begin
print N'总课程数超过5个但不足10个。'
end
end
end
执行结果:
总课程数超过5个但不足10个。
第3节 WHILE
根据条件重复执行一组语句,只要条件为真。
3.1 WHILE - 条件重复执行语句
WHILE [判断条件]
{ SQL语句块}
3.2 变量
在循环中,必须更改一些变量才能在某些点进行返回。否则,此循环将会无限循环
begin
declare @num int
set @num = 0
while @num < 5
begin
print @num
set @num = @num + 1
end
end
执行结果:
0
1
2
3
4
3.3 BREAK 语句 - 立即退出循环,并在循环中跳过循环后的其余代码。
若要立即退出循环的当前迭代,使用 BREAK 语句。
WHILE [判断条件1]
BEGIN
-- statement
WHILE [判断条件2]
BEGIN
IF condition
BREAK;
END
END
Note:
BREAK语句仅退出语句中最内层WHILE的循环;
BREAK语句只能在WHILE循环内部使用;
IF语句经常与BREAK语句一起使用,但不必需。
代码实例:
begin
declare @num int
set @num = 0
while @num < 10
begin
set @num = @num + 1
if @num = 5
break;
print @num
end
end
执行结果:
1
2
3
4
3.4 CONTINUE 语句 - 立即跳过循环的当前迭代并继续下一个迭代
若要跳过循环的当前迭代并启动新迭代,使用 CONTINUE 语句。
WHILE [判断条件1]
BEGIN
{执行的代码块1}
IF condition
CONTINUE;
{执行的代码块2;如果满足条件,将跳过此代码}
END
实例代码:
begin
declare @num int
set @num = 0
while @num < 10
begin
set @num = @num + 1
if @num = 5
continue;
print @num
end
end
执行结果:
1
2
3
4
6
7
8
9
10
三、SQL Server 游标
SQL基于集合工作,select语句返回一组称为结果集的行。但是,有时可能希望逐行处理数据集。这就是游标发挥作用的地方。
什么是数据库游标
数据库游标是一个对象,它允许遍历结果集的行并且允许处理查询返回的单个行。
SQL Server 游标的生命周期

使用游标的步骤:
(1)声明游标
用DECLARE语句为一条SELECT语句定义游标:
DECLARE <游标名> CURSOR FOR <SELECT 语句>;
要声明游标,在具有cursor数据类型的declare关键字之后指定其名称,并提供一个SELECT语句来定义游标的结果集。
(2)打开游标
OPEN <游标名>;
通过执行SELECT语句打开并填充游标,此时游标指向查询数据集的第一条数据。
(3)从游标中获取一行到一个或多个变量中
FETCH NEXT FROM <游标名> INTO [变量];
FETCH语句将游标指针向前推进一条记录,同时将缓冲区中的当前记录取出来送至主变量供语句进一步处理。通过循环执行FETCH语句逐条取出结果集中的行进行处理。
(4)关闭游标
CLOSE <游标名>;
关闭游标后将释放结果集占用的缓冲区及其他资源。游标被关闭后就不再和原来的查询结果集相联系。但被关闭的游标可以再次被打开,与新的查询结果相联系。
(5)解除分配游标(删除游标)
DEALLOCATE <游标名>;
游标使用实例
现有如下用户购买课程的订单表,我们采用游标读取用户ID和购买课程以及购买的状态。

采用存储的方式实现,存储过程如下:
USE [F_stu_db] --使用的数据库
GO
/****** Object: StoredProcedure [dbo].[order_info_proc_cursor] Script Date: 2023/11/23 16:54:30 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[order_info_proc_cursor] --创建存储过程
AS
DECLARE @user_id char(10) --定义变量接收用户id
DECLARE @product_name char(5) --定义变量接受用户名称
DECLARE @status char(15) --定义变量接受购买状态信息
DECLARE read_info_cursor CURSOR FOR select user_id, product_name,status from order_info --声明游标 read_info_cursor
OPEN read_info_cursor --打开游标
FETCH NEXT FROM read_info_cursor INTO @user_id, @product_name,@status
WHILE(@@FETCH_STATUS = 0) --遍历所有的数据,@@FETCH_STATUS函数返回值为0表示FETCH语句执行成功
BEGIN
PRINT '游标成功取出一条数据:'
PRINT N'用户:'+@user_id+N',购买了'+@product_name+N'课程。'+N'购买状态:'+@status
PRINT '-----------------------'
FETCH NEXT FROM read_info_cursor INTO @user_id, @product_name,@status --取下一条游标数据
END
CLOSE read_info_cursor --关闭游标
DEALLOCATE read_info_cursor --删除游标
执行存储过程:
EXEC order_info_proc_cursor
结果如下:

值得注意的是:在实践中,很少使用游标以逐行方式处理结果集。
四、处理异常
第1节 TRY…CATCH构造
SQL Server中的用TRY CATCH捕捉异常。
1.1 TRY…CATCH构造
若要使用 TRY…CATCH 构造,需要将一组可能导致异常的sql语句放置在 BEGIN TRY…END TRY 块中,然后在 TRY 块之后立即使用 BEGIN CATCH…END CATCH 块,完整的 TRY CATCH 结构:
BEGIN TRY
-- statements that may cause exceptions
END TRY
BEGIN CATCH
-- statements that handle exception
END CATCH
Note:
如果 TRY 块之间的语句没有错误地完成,则 CATCH 块之间的语句将不会执行;
如果 TRY 块中的任何语句导致异常,则控制转移到 CATCH 块中的语句。
1.2 CATCH 块功能
在 CATCH 块中,可以使用以下函数来获取有关所发生错误的详细信息:
| 函数 | 详细信息 |
|---|---|
| ERROR_LINE( ) | 返回发生异常的行号 |
| ERROR_LINE( ) | 返回发生异常的行号 |
| ERROR_PROCEDURE( ) | 返回发生错误的存储过程或触发器的名称 |
| ERROR_NUMBER( ) | 返回发生的错误的编号 |
| ERROR_SEVERITY( ) | 返回所发生错误的严重级别 |
| ERROR_STATE( ) | 返回发生错误的状态号 |
Note:这些函数只能在 CATCH 块中使用,如果在CATCH块以外使用,所有函数都将返回 NULL 。
1.3 嵌套TRY…CATCH 结构
可以将 TRY…CATCH 构造嵌套在另一个 TRY…CATCH 构造中;TRY块或CATCH块都可以包含嵌套的 TRY…CATCH。通用代码:
BEGIN TRY
--- statements that may cause exceptions
END TRY
BEGIN CATCH
-- statements to handle exception
BEGIN TRY
--- nested TRY block
END TRY
BEGIN CATCH
--- nested CATCH block
END CATCH
END CATCH
1.4 TRY…CATCH 示例
创建一个除法存储过程,带参数输入,结果打印到控制台,存储代码如下:
CREATE PROC sp_num_divide
@num1 int,
@num2 int,
@num3 int output
AS
BEGIN
BEGIN TRY
SET @num3 = @num1 / @num2;
END TRY
BEGIN CATCH
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() AS ErrorState,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage;
END CATCH
END;
GO
执行存储过程:
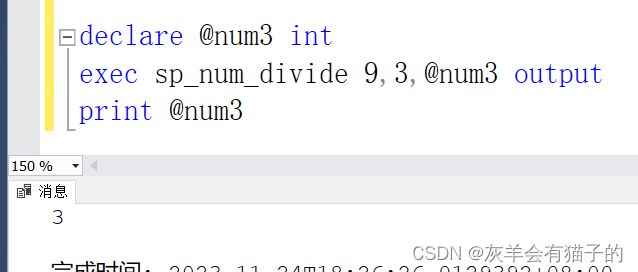
declare @num3 int
exec sp_num_divide 9,3,@num3 output -- 3
print @num3
执行结果
执行返回异常存储过程:
declare @num3 int
exec sp_num_divide 9,0,@num3 output
print @num3
执行结果:

说明:由于公式导致的除以零错误,控制被传递到 CATCH 块中的语句,该语句返回错误的详细信息。
1.5 带事务TRY…CATCH
在 CATCH 块中,可以使用 XACT_STATE( ) 函数测试事务的状态。
| XACT_STATE( ) 函数返回值 | 含义 | 应当采取操作 |
|---|---|---|
| -1 | 一个不可提交的事务处于挂起状态 | ROLLBACK TRANSACTION |
| 1 | 一个可提交事务处于挂起状态 | COMMIT TRANSACTION |
| 0 | 表示没有事务挂起 | 不需要采取任何操作 |
在 CATCH 块中发出 COMMIT TRANSACTION 或 ROLLBACK TRANSACTION 语句之前测试事务状态以确保一致性是很有必要的。
操作实例如下:
1、可以创建一个获取异常的存储 sp_return_error,方便其他程序直接调用:
CREATE PROC sp_return_error
AS
SELECT
ERROR_NUMBER() AS ErrorNumber,
ERROR_SEVERITY() AS ErrorSeverity,
ERROR_STATE() AS ErrorState,
ERROR_PROCEDURE() AS ErrorProcedure,
ERROR_LINE() AS ErrorLine,
ERROR_MESSAGE() AS ErrorMessage;
GO
2、创建一个带参数存储,功能是带用户ID删除工资表中用户信息,代码实现如下:
CREATE PROC sp_del_user(
@emp_no int
) AS
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
-- delete user
DELETE FROM salaries
WHERE emp_no = @emp_no;
-- if delete succeeds, commit the transaction
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- report exception
EXEC sp_return_error;
-- Test if the transaction is uncommittable.
IF (XACT_STATE()) = -1
BEGIN
PRINT N'事务不可提交。' +
'Rolling back transaction.'
ROLLBACK TRANSACTION;
END;
-- Test if the transaction is committable.
IF (XACT_STATE()) = 1
BEGIN
PRINT N'事务可提交。' +
'Committing transaction.'
COMMIT TRANSACTION;
END;
END CATCH
END;
GO
执行存储:
exec sp_del_user 10009
第2节 RAISERROR
生成用户定义的错误消息,并使用与系统错误相同的格式将其返回给应用程序。
2.1 SQL Server 语句概述RAISEERROR
该语句允许生成用户自己的错误消息,并使用与 SQL Server 数据库引擎生成的系统错误或警告消息相同的格式将这些消息返回给应用程序。此外,该语句还允许用户为错误消息设置特定的消息 ID、严重性级别和状态。
RAISERROR语法如下:
RAISERROR ( { message_id | message_text | @local_variable }
{ ,severity ,state }
[ ,argument [ ,...n ] ] )
[ WITH option [ ,...n ] ];
2.2 message_id字段 - 消息编号
message_id 是存储在 sys.messages 目录视图中的用户定义的错误消息编号。要添加新的用户定义的错误消息编号,可以使用存储过程 sp_addmessage 。用户定义的错误消息编号应大于50000。默认情况下, RAISERROR 语句使用 message_id 50000来引发错误。
将自定义错误消息添加到 sys.messages 视图中:
EXEC sp_addmessage
@msgnum = 50005,
@severity = 1,
@msgtext = 'error message';
查询是否添加成功,可使用select语句:
select *
from sys.messages
where message_id = 50005;
要使用此message_id,执行以下 RAISEERROR 语句:
RAISERROR ( 50005,1,1)
执行结果:
error message
Msg 50005, Level 1, State 1
要从 sys.messages 中删除消息,可以使用存储过程 sp_dropmessage 。执行代码如下:
EXEC sp_dropmessage @msgnum = 50005;
2.3 message_text字段 - 消息正文
message_text 是一个用户定义的消息,格式类似于 printf 函数。 message_text 最多可包含2047个字符,最后3个字符用于省略号(…)。如果 message_text 包含2048或更多,它将被截断并用省略号填充。当指定 message_text 时, RAISERROR 语句使用message_id 50000引发错误消息。下面的示例使用 RAISERROR 语句引发带有消息文本的错误:
RAISERROR ( 'There is an error occurred.',1,1)
输出如下所示:
There is an error occurred.
Msg 50000, Level 1, State 1
2.3 severity字段 - 严重程度
严重性级别是0到25之间的整数,每个级别表示错误的严重性:
0–10:Informational messages
11–18:Errors
19–25:Fatal errors
2.4 state字段 - 状态
状态是从0到255的整数。如果在多个位置引发相同的用户定义错误,则可以为每个位置使用唯一的状态号,以便更容易找到导致错误的代码部分。对于大多数实现可以使用1。
2.5 WITH option字段 - 选项
选项可以是 LOG 、 NOWAIT 或 SETERROR :
WITH LOG :在SQL Server数据库引擎实例的错误日志和应用程序日志中记录错误。
WITH NOWAIT :立即向客户端发送错误消息。
WITH SETERROR :将 ERROR_NUMBER 和 @@ERROR 值设置为message_id或50000,而不考虑严重性级别。
2.6 SQL Server RAISERROR 示例
2.6.1 使用SQL Server RAISERROR 和 TRY CATCH 块示例
使用 TRY 块中的 RAISERROR 来使执行跳转到关联的 CATCH 块。在 CATCH 块中,我们使用 RAISERROR 返回调用 CATCH 块的错误信息。
实例代码如下:
DECLARE
@ErrorMessage char(4000),
@ErrorSeverity int,
@ErrorState int;
BEGIN TRY
RAISERROR('测试:TRY块中发生错误!', 17, 1);
END TRY
BEGIN CATCH
SELECT
@ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE();
-- return the error inside the CATCH block
RAISERROR(@ErrorMessage, @ErrorSeverity, @ErrorState);
END CATCH;
执行结果:
消息 50000,级别 17,状态 1,第 16 行
测试:TRY块中发生错误!
2.6.2 使用SQL Server RAISERROR 语句和动态消息文本示例
下面的示例显示如何使用局部变量为 RAISERROR 语句提供消息文本:
DECLARE @MessageText char(100);
SET @MessageText = N'这是一条测试的MessageText。';
RAISERROR(
@MessageText, -- Message text
16, -- severity
1, -- state
N'2001' -- first argument to the message text
);
执行结果如下:
消息 50000,级别 16,状态 1,第 3 行
这是一条测试的MessageText。
2.7 何时使用 RAISERROR 语句
可以在以下场景中使用 RAISERROR 语句:
1、删除Transact-SQL代码。
2、返回包含可变文本的消息。
3、检查数据的值。
4、使执行从 TRY 块跳转到关联的 CATCH 块。
5、将错误信息从 CATCH 块返回给调用者,调用批处理或应用程序。
第3节 THROW
引发异常并将执行转移到 TRY CATCH 构造的 CATCH 块的步骤。
3.1 SQL Server THROW 语句概述
THROW 语句引发异常并将执行转移到 TRY CATCH 构造的 CATCH 块。下面说明 THROW 语句的语法:
THROW [ error_number ,
message ,
state ];
在此语法中:
1、error_number - - 错误号
error_number 是表示异常的整数。 error_number 必须大于 50000 且小于或等于 2147483647 。
2、message - - 消息
message 是一个类型为 NVARCHAR(2048) 的字符串,用于描述异常。
3、state - - 状态
state 是值在0和255之间的 TINYINT 。 state 表示与消息相关联的状态。
如果没有为 THROW 语句指定任何参数,则必须将 THROW 语句放在 CATCH 块中:
BEGIN TRY
-- statements that may cause errors
END TRY
BEGIN CATCH
-- statement to handle errors
THROW;
END CATCH
在这种情况下, THROW 语句引发了被 CATCH 块捕获的错误。
Note:在 THROW 语句之前的语句必须由一个通配符(;)结尾。
3.2 SQL Server THROW 语句示例
3.2.1 使用 THROW 语句引发异常
示例使用 THROW 语句引发异常:
THROW 50005, N'这是一条测试的MessageText。', 1;
执行结果:
消息 50005,级别 16,状态 1,第 1 行
这是一条测试的MessageText。
3.2.2使用 THROW 语句重新抛出异常
有一个departments表,里面有dept_no和dept_name两列,且dept_no为主键。
在 CATCH 块中使用不带参数的 THROW 语句来重新抛出捕获的错误:
BEGIN TRY
INSERT INTO departments VALUES('d003','Testing');
-- cause error
INSERT INTO departments VALUES('d003','Testing');
END TRY
BEGIN CATCH
PRINT('Eorr:重复插入同一主键!');
THROW;
END CATCH
执行结果:

说明:第一个 INSERT 语句成功了。但是,第二个由于主键约束而失败。因此,被 CATCH 块捕获的错误被 THROW 语句再次引发。
3.2.3 使用 THROW 语句重新抛出异常
与 RAISERROR 语句不同, THROW 语句不允许替换消息文本中的参数。因此,要模拟此函数需要使用 FORMATMESSAGE( ) 函数。
以下语句将自定义消息添加到 sys.messages 目录视图:
EXEC sys.sp_addmessage
@msgnum = 50010,
@severity = 16,
@msgtext = N'This is a test MessageText,接受返回值 %s 成功!',
@lang = 'us_english';
GO
使用 message_id 50010并将 %s 占位符替换为待接收‘0001’:
DECLARE @MessageText char(50);
SET @MessageText = FORMATMESSAGE(50010, N'0001');
THROW 50010, @MessageText, 1;
执行结果如下:
消息 50010,级别 16,状态 1,第 13 行
This is a test MessageText,接受返回值 0001 成功!
3.3 THROW 对比 RAISERROR
下表简要说明 THROW 语句和 RAISERROR 语句之间的区别:
| RAISERROR | THROW |
|---|---|
| 传递给 RAISERROR 的 message_id 必须在 sys.messages 视图中定义。 | error_number参数不必在 sys.messages 视图中定义。 |
| message参数可以包含printf格式样式,如 %s 和 %d 。 | message参数不接受printf样式格式。使用 FORMATMESSAGE() 函数替换参数。 |
| severity参数指示异常的严重性。 | 异常的严重性始终设置为16。 |
五、动态SQL
使用SQL Server动态SQL来构建通用和灵活的SQL语句。
动态SQL简介
动态SQL是一种允许在运行时动态构造SQL语句的编程技术。它可以创建出更通用和灵活的SQL语句,因为SQL语句的全文在编译时可能是未知的。如,可以使用动态SQL创建一个存储过程,该存储过程根据一个表查询数据,该表的名称直到运行时才知道。
创建一个动态SQL,将sql语句放在 ’ ’ 内,成为一个字符串:
'select * from salaries';
执行动态SQL语句,调用存储过程 sp_executesql :
exec sp_executesql N'select * from salaries';
Note:因为 sp_executesql 接受动态SQL作为Unicode字符串,所以需要在它前面加上 N 。
关于Unicode字符串知识点拓展(可点击查看):SQL Sever Unicode简单介绍
使用动态SQL查询任意表示例
声明两个变量, @table 用于保存要查询的表的名称, @sql 用于保存动态SQL:
declare
@table char(20),
@sql nvarchar(max);
将 @table 变量的值设置为表 salaries:
set @table = N'salaries';
通过连接 SELECT 语句和表名参数来构造动态SQL:
set @sql = N'select * from ' + @table;
通过传递 @sql 参数调用 sp_executesql 存储过程:
exec sp_executesql @sql;
整合代码如下:
declare
@table char(20),
@sql nvarchar(max);
set @table = N'salaries';
set @sql = N'select * from ' + @table;
exec sp_executesql @sql;
要从另一个表中查询数据,直接更改 @table 变量的值即可;如果我们将上面的T-SQL块包装在存储过程中,则会更具通用性。
SQL Server动态SQL和存储过程
此存储过程接受任何表,并使用动态SQL从指定表返回结果集:
create proc sp_sqlquery
@table nvarchar(50)
as
begin
declare @sql nvarchar(max);
-- construct SQL
set @sql = N'select * from ' + @table;
-- execute the SQL
exec sp_executesql @sql;
end;
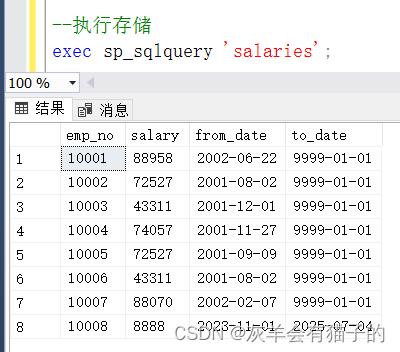
调用 sp_sqlquery 存储过程,返回 salaries 表中的所有行:
exec sp_sqlquery 'salaries';
执行结果:
此存储过程按指定列的值返回表中的前n行:
create proc sp_sqlquery_topn
@table nvarchar(50),
@topN int,
@byColumn nvarchar(100)
as
begin
declare
@sql nvarchar(max),
@topNStr nvarchar(max);
set @topNStr = cast(@topN as nvarchar(max));
-- construct SQL
set @sql = N'select top ' + @topNStr +
' * from ' + @table +
' order by ' + @byColumn + ' desc';
-- execute the SQL
exec sp_executesql @sql;
end;
执行存储,从salaries 表中查询工资排名前3的员工及相关信息:
exec sp_sqlquery_topn 'salaries', 3, 'salary';
执行结果:

SQL Server 动态 SQL 和 SQL 注入
为演示需要,将salaries 表备份一份:
select * into salaries_bak from salaries;
查询表salaries所有数据:
exec sp_sqlquery 'salaries';
但它并不阻止用户按下方式传递表名:
exec sp_sqlquery 'salaries;drop table salaries_bak';
执行结果会查询salaries表所有数据且会删除salaries_bak表,这种技术称为SQL注入。
为了防止这种SQL注入,可以查询中使用 QUOTENAME( ) 函数,打开存储过程 sp_sqlquery,修改代码如下:
alter proc [dbo].[sp_sqlquery] (
@table1 nvarchar(50),
@table2 nvarchar(50)
)
as
begin
declare @sql nvarchar(max);
-- construct SQL
set @sql = N'select * from ' + QUOTENAME(@table1)+'.'+QUOTENAME(@table2);
-- execute the SQL
exec sp_executesql @sql;
end;
执行存储:
exec sp_sqlquery 'dbo','salaries';
执行成功,返回数据集。
再次尝试使用注入语句查询:
exec sp_sqlquery 'dbo','salaries;drop table salaries_bak';
执行不成功,报错信息如下:
消息 208,级别 16,状态 1,第 96 行
Invalid object name 'dbo.salaries;drop table salaries_bak'.