SQL Sever 复习笔记【一】
SQL Sever 基础知识
- 一、查询数据
-
- 第1节 基本 SQL Server 语句SELECT
- 第2节 SELECT语句示例
-
- 2.1 SELECT - 检索表示例的某些列
- 2.2 SELECT - 检索表的所有列
- 2.3 SELECT - 对结果集进行筛选
- 2.4 SELECT - 对结果集进行排序
- 2.5 SELECT - 对结果集进行分组
- 2.5 SELECT - 对结果集进行筛选器组
- 二 、对数据进行排序
-
- 第1节 ORDER BY 子句简介
- 第2节 ORDER BY 子句示例
-
- 2.1 按一列升序对结果集进行排序
- 2.2 按一列降序对结果集进行排序
- 2.3 按多列对结果集排序
- 2.4 按多列对结果集不同排序
- 2.5 按不在选择列表中的列对结果集进行排序
- 2.6 按表达式对结果集排序
- 2.7 按列的顺序位置排序
- 三、限制行数
-
- 第1节 OFFSET FETCH - 限制查询返回的行数
-
- 1.1 OFFSET 和 FETCH 子句
- 1.2 SQL Server OFFSET 和 FETCH 示例
- 第2节 SELECT TOP - 限制查询结果集中返回的行数或行的百分比
-
- 2.1 SELECT TOP 子句
- 2.2 PERCENT
- 2.3 WITH TIES
- 2.4 SELECT TOP 示例
-
- 2.4.1 使用带有常量值的 TOP
- 2.4.2 使用 TOP 返回行的百分比
- 2.4.3 使用 TOP WITH TIES 包含与最后一行中的值匹配的行
- 四、筛选数据
-
- 第1节 DISTINCT - 去除重复值
-
- 1.1 SELECT DISTINCT 子句简介
- 1.2 SELECT DISTINCT 示例
-
- 1.2.1 DISTINCT 一列示例
- 1.2.2 DISTINCT 多列示例
- 1.2.3 DISTINCT 具有 null 值示例
- 1.2.4 DISTINCT 与 GROUP BY 对比
- 第2节 WHERE - 过滤查询返回的行
-
- 2.1 WHERE 子句简介
- 2.2 WHERE 子句示例
-
- 2.2.1 使用简单等式查找行
- 2.2.2 查找满足两个条件的行
- 2.2.3 使用比较运算符查找行
- 2.2.4 查找满足两个条件之一的行
- 2.2.4 查找值在两个值之间的行
-
- 2.2.4.1 使用between...and...关键字
- 2.2.4.2 使用判断符
- 2.2.5 在值列表中查找具有值的行
- 2.2.6 查找值包含字符串的行 - 模糊查询
- 第3节 NULL
-
- 3.1 NULL 和三值逻辑
- 3.2 IS NULL / IS NOT NULL
- 第4节 AND
-
- 4.1 AND 运算符简介
- 4.2 AND 运算符示例
-
- 4.2.1 一个 AND 运算符
- 4.2.2 多个 AND 运算符
- 4.2.3 将 AND 运算符与其他逻辑运算符一起使用
- 第5节 OR
-
- 5.1 OR 运算符简介
- 5.2 OR 运算符示例
-
- 5.2.1 一个OR运算符
- 5.2.2 多个OR运算符
- 5.2.3 OR运算符同AND运算符一起使用
- 第6节 IN
-
- 6.1 IN运算符概述
- 6.2 IN 运算符示例
-
- 6.2.1 IN 与值列表
- 6.2.2 NOT IN 与值列表
- 6.2.3 IN 运算符用于子查询
- 第7节 BETWEEN
-
- 7.1 BETWEEN 运算符概述
- 7.2 BETWEEN 示例
-
- 7.2.1 BETWEEN 与数字示例
- 7.2.2 BETWEEN 和日期示例
- 第8节 LIKE
-
- 8.1 LIKE运算符概述
- 8.2 转义字符
- 8.3 LIKE 示例
-
- 8.3.1 % (百分号) 通配符示例
- 8.3.2 _(下划线)通配符示例
- 8.3.3
- 8.3.4
- 8.3.5
- 第9节 别名
一、查询数据
介绍了 SQL Server SELECT语句的基础知识,重点介绍如何针对单个表进行查询。
第1节 基本 SQL Server 语句SELECT
数据库表是存储数据库中所有数据的对象。在表中,数据以类似于电子表格的行列格式进行逻辑组织。每行表示表中的一条唯一记录,每列表示记录中的一个字段。SQL Server使用架构对表和其他数据库对象进行逻辑分组。
要从表中查询数据,请使用 SELECT 语句。以下是 SELECT 语句的最基本形式:
select <列名1>,<列名2>,... from [表名]
在此语法中:
①在 SELECT 子句中指定要从中查询数据的逗号分隔列的列表;
②在 FROM 子句中指定源表及其架构名称。
查询语句执行的顺序:
在处理 SELECT 语句时,SQL Server会先处理 FROM 子句,然后再处理 SELECT 子句。

查询的结果称为结果集。
第2节 SELECT语句示例
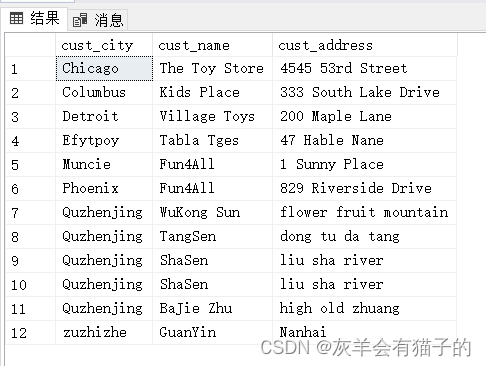
在此使用示ZCustomers 表进行演示,表中数据如下:
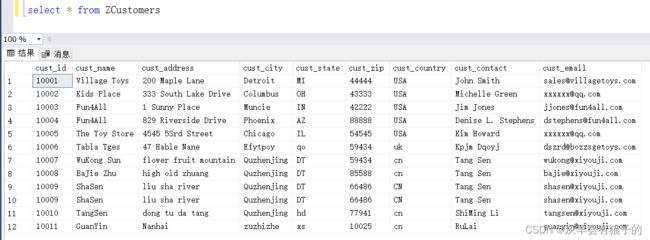
2.1 SELECT - 检索表示例的某些列
查询ZCustomers表中所有客户的名字、地址和邮箱:
select cust_name,cust_address,cust_email
from ZCustomers
执行结果如下:

2.2 SELECT - 检索表的所有列
查询ZCustomers表中所有数据:
select *
from ZCustomers
执行结果:
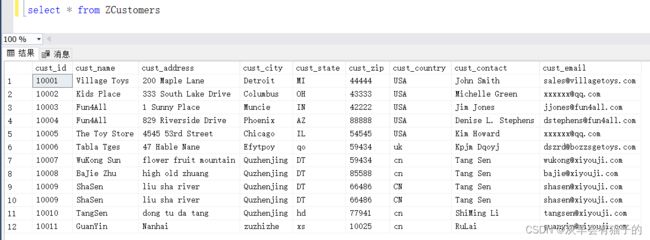
select * 有助于检查不熟悉的表的列和数据,对临时查询也很有帮助。
2.3 SELECT - 对结果集进行筛选
要根据一个或多个条件筛选行,使用 WHERE 子句。我们可以查询表中中国的客户相关信息:
select *
from ZCustomers
where cust_country = 'cn'
执行结果:

当 WHERE 子句可用时,SQL Server按以下顺序处理查询的子句: FROM 、 WHERE 和 SELECT 。

2.4 SELECT - 对结果集进行排序
要根据一个或多个条件筛排序,使用 order by 子句。我们可以查询表中中国的客户相关信息,并将name排序:
select *
from ZCustomers
where cust_country = 'cn'
order by cust_name
执行结果:

当 ORDER BY子句可用时,SQL Server按以下顺序处理查询的子句: FROM 、 WHERE 、 SELECT 和 ORDER BY 。

2.5 SELECT - 对结果集进行分组
统计ZCustomers表中所有客户城市以及每个城市中的客户数:
select cust_country,count(*) as '个数'
from ZCustomers
--where
group by cust_country
order by cust_country
执行结果:
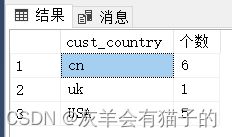
当 GROUP BY子句可用时,SQL Server按以下顺序处理子句: FROM 、 WHERE 、 GROUP BY 、 SELECT 和 ORDER BY 。

2.5 SELECT - 对结果集进行筛选器组
要根据一个或多个条件筛选组,使用 HAVING 子句。下面的示例返回城市的客户数超过3个:
select cust_country,count(*) as '个数'
from ZCustomers
--where
group by cust_country
having count(*) > 3
order by cust_country
执行结果:
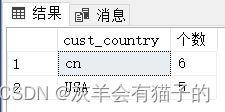
当 HAVING子句可用时,SQL Server按以下顺序处理子句: FROM 、 WHERE 、 GROUP BY 、HAVING、 SELECT 和 ORDER BY 。
Note:
WHERE 子句过滤行,而 HAVING 子句过滤组。
二 、对数据进行排序
按一列或多列对查询的结果集进行排序。
第1节 ORDER BY 子句简介
使用 SELECT 语句从表中查询数据时,结果集中的行的顺序不能保证。说明SQL Server可以返回具有未指定行顺序的结果集,确保结果集中的行已排序的唯一方法是使用 ORDER BY 子句。
以下说明 ORDER BY 子句语法:
select <列名1>,<列名2>,...
from [表名]
order by <列名> [ASC|DESC]; --asc升序排序(默认,可省略);desc降序排序
order by指定一个列名或表达式,根据该列名或表达式对查询的结果集进行排序。如果指定多列,则结果集按第一列排序,然后按第二列排序该排序结果集,依此类推。
出现在order by子句中的列必须对应于选择列表中的列或在 form 子句中指定的表中定义的列。
使用 ASC 或 DESC 指定指定列中的值是否应按升序或降序排序。如果没有显式指定 ASC 或 DESC ,将使用 ASC 作为默认排序顺序。
此外,SQL Server将NULL视为最小值。
第2节 ORDER BY 子句示例
2.1 按一列升序对结果集进行排序
查询ZCustomers表中所有客户姓名,并升序排序:
select cust_name
from ZCustomers
order by cust_name
没有指定 ASC 或 DESC ,所以 ORDER BY 子句默认使用 ASC 。
执行结果:

2.2 按一列降序对结果集进行排序
查询ZCustomers表中所有客户姓名,并降序排序:
select cust_name
from ZCustomers
order by cust_name desc
执行结果:

2.3 按多列对结果集排序
查询ZCustomers表中所有客户的名字和城市。它先按城市然后按名字对客户列表进行排序:
select cust_city,cust_name,cust_address
from ZCustomers
order by cust_city,cust_name
执行结果:

2.4 按多列对结果集不同排序
查询ZCustomers表中所有客户的名字和城市。它先按城市升序然后按名字降序对客户列表进行排序:
select cust_city,cust_name,cust_address
from ZCustomers
order by cust_city,cust_name desc
执行结果:

2.5 按不在选择列表中的列对结果集进行排序
可以按未出现在选择列表中的列对结果集进行排序。查询ZCustomers表中所有客户的名字和城市,对cust_zip升序排列:
select cust_city,cust_name,cust_address
from ZCustomers
order by cust_zip
执行结果:

Note:
order by后列是在表中有定义的;如果未定义,则查询无效。
2.6 按表达式对结果集排序
用到一个LEN( )函数,LEN( )函数的作用是:返回字符串中的字符数。
以下语句使用 ORDER BY 子句中的 LEN( ) 函数检索按名字长度排序的客户列表:
select cust_city,cust_name,cust_address
from ZCustomers
order by len(cust_name)
执行结果:

2.7 按列的顺序位置排序
SQLServer允许根据选择列表中出现的列的序号位置对结果集进行排序。
查询ZCustomers表中所有客户的名字和城市。它先按城市升序然后按名字降序对客户列表进行排序:
select cust_city,cust_name,cust_address
from ZCustomers
order by 1 ,2 desc
执行结果:
在此示例中,1表示 cust_city列,2表示 cust_name列。
不推荐 在 ORDER BY 子句中使用列的顺序位置排序,原因有两个:
①表中的列没有顺序位置,需要通过名称引用。
②当修改选择列表后可能会忘记在 ORDER BY 子句中进行相应的更改。
因此,最好始终在 ORDER BY 子句中显式指定列名。
三、限制行数
第1节 OFFSET FETCH - 限制查询返回的行数
SQL Server中使用 OFFSET FETCH 子句来限制查询返回的行数。
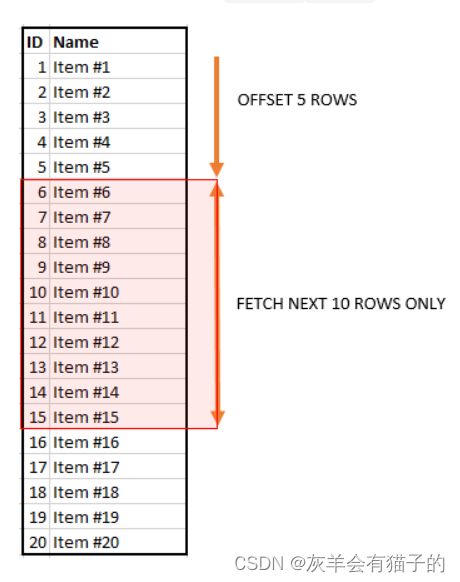
1.1 OFFSET 和 FETCH 子句
OFFSET 和 FETCH 子句是 ORDER BY 子句的选项。它们允许限制查询返回的行数。
以下说明 OFFSET 和 FETCH 子句的语法:
ORDER BY column_list [ASC |DESC]
OFFSET offset_row_count {ROW | ROWS}
FETCH {FIRST | NEXT} fetch_row_count {ROW | ROWS} ONLY
在此语法中:
① OFFSET 子句指定在开始从查询返回行之前要跳过的行数。 offset_row_count 可以是大于或等于零的常量、变量或参数。
② FETCH 子句指定在处理了 OFFSET 子句之后要返回的行数。 offset_row_count 可以是大于或等于1的常量、变量或标量。
③ OFFSET 子句是强制性的,而 FETCH 子句是可选的。此外, FIRST 和 NEXT 是同义词,因此可以互换使用。
下图说明了 OFFSET 和 FETCH 子句:
Note:
① 必须将 OFFSET 和 FETCH 子句与 ORDER BY 子句一起使用,否则会报错。
② 与 TOP 子句相比, OFFSET 和 FETCH 子句更适合实现查询分页解决方案。
1.2 SQL Server OFFSET 和 FETCH 示例
新建一个CustomerInfo数据表作为学习案例。
CREATE TABLE CustomerInfo (
CusID INT IDENTITY(10001,1) PRIMARY KEY,
CusName VARCHAR(50) NOT NULL,
Gender VARCHAR(10),
Age INT,
Phone VARCHAR(20),
Province VARCHAR(50),
City VARCHAR(50),
Status VARCHAR(20)
);
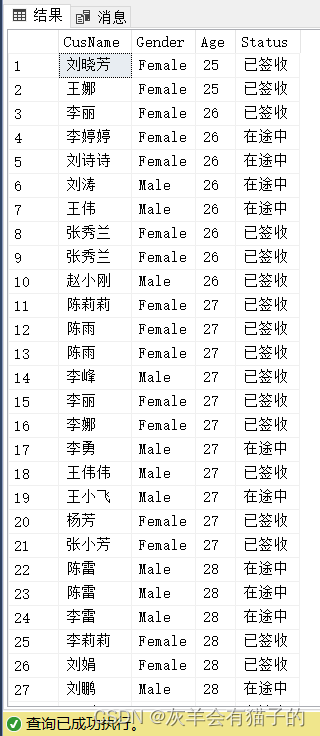
查询返回 CustomerInfo 表中的所有客户的CusName,Gender,Age,Status,并对Age进行排序:
select CusName,Gender,Age,Status
from CustomerInfo
order by Age,CusName;
执行结果:
要跳过前10个客人信息并返回其余客人,使用 OFFSET 子句:
select CusName,Gender,Age,Status
from CustomerInfo
order by Age,CusName
offset 10 rows;
执行结果:
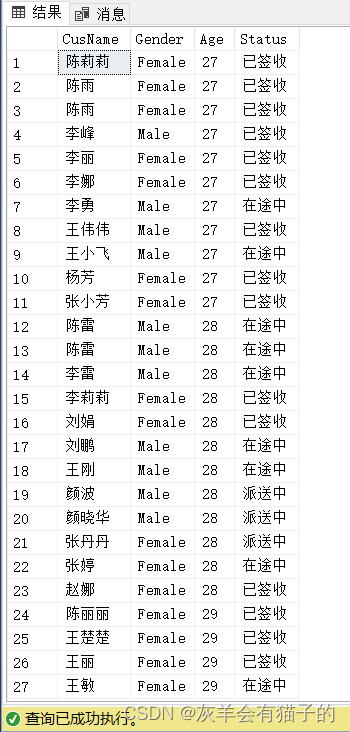
对比前结果,可发现数据集跳过前10行。
要跳过前10个客人信息并返回接下来的10个客人,可同时使用 OFFSET 和 FETCH 子句,如下所示:
select CusName,Gender,Age,Status
from CustomerInfo
order by Age,CusName
offset 10 rows
fetch first 10 rows only;
执行结果:
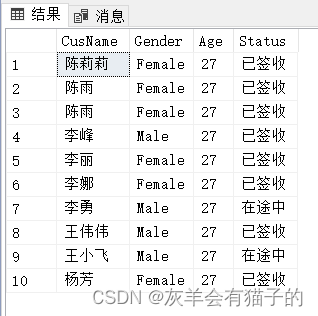
对比前结果,可发现数据集跳过前10行后取到接着的10行数据即结果集的11-20行数据。
如果只取前10个客人信息并可同时使用 OFFSET 和 FETCH 子句,如下所示:
select CusName,Gender,Age,Status
from CustomerInfo
order by Age,CusName
offset 0 rows
fetch first 10 rows only;
执行结果:
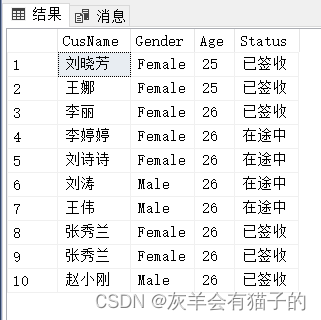
跳过0行,取接后的10行就为前10行,对比前面数据集发现取数据成功!
第2节 SELECT TOP - 限制查询结果集中返回的行数或行的百分比
使用SQL Server SELECT TOP 语句来限制查询返回的行。
2.1 SELECT TOP 子句
因为存储在表中的行的顺序是未指定的,所以 SELECT TOP 语句总是与 ORDER BY 子句一起使用。因此,结果集仅限于第 N 个有序行。
SELECT 语句的 TOP 子句的语法:
select top (expression) [PERCENT][WITH TIES]
from [表名]
ORDER BY <列名>
在此语法中, SELECT 语句可以有其他子句,如 WHERE 、 JOIN 、 HAVING 和 GROUP BY 。
TOP 关键字后面是一个表达式,它指定要返回的行数。如果使用 PERCENT ,表达式将被计算为浮点值,否则,它将被转换为 BIGINT 值。
2.2 PERCENT
PERCENT 关键字表示查询返回前 N 百分比的行,其中 N 是 expression 的结果。
2.3 WITH TIES
WITH TIES 允许您返回更多行,其值与有限结果集中的最后一行匹配。请注意, WITH TIES 可能会导致返回的行数比您在表达式中指定的要多。
【举个栗子】如果想查询年度总成绩第一的学生评优,可以使用 TOP 1查询 。但是,如果有多个同分数的学生,top 1 只会返回一个学生信息。为了避免这种情况,需要使用 TOP 1 WITH TIES,可返回同分数的所有学生信息。
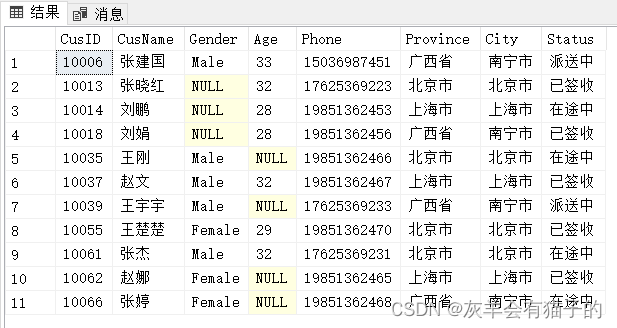
实例:取客户信息表中年龄最大的用户信息(TOP 1 )
select top 1 *
from CustomerInfo
order by Age desc
执行结果:
CusID CusName Gender Age Phone Province City Status
10006 张建国 Male 33 15036987451 广西省 南宁市 派送中
取客户信息表中年龄最大的用户信息(TOP 1 WITH TIES)
select top 1 with ties *
from CustomerInfo
order by Age desc
执行结果
CusID CusName Gender Age Phone Province City Status
10006 张建国 Male 33 15036987451 广西省 南宁市 派送中
10022 王秀华 Female 33 17625369226 广东省 深圳市 在途中
10039 王宇宇 Male 33 17625369233 广西省 南宁市 派送中
10045 王海洋 Male 33 17625369230 广东省 广州市 在途中
10057 李佳佳 Female 33 19851362471 浙江省 宁波市 已签收
10070 王建华 Male 33 17625369234 广东省 深圳市 在途中
2.4 SELECT TOP 示例
2.4.1 使用带有常量值的 TOP
查询前十个年龄中最大的用户信息:
select top 10 *
from CustomerInfo
order by Age desc
2.4.2 使用 TOP 返回行的百分比
查询前(占总数据的10%的数)个年龄中最大的用户信息:
select top 10 PERCENT *
from CustomerInfo
order by Age desc
使用 PERCENT 指定结果集中返回百分比个数,CustomerInfo表中共有78行数据,78的百分之十是一个小数值( 7.8 ),SQL Server将其四舍五入到下一个整数,在这种情况下是8,即返回数据的前8行。
执行结果:
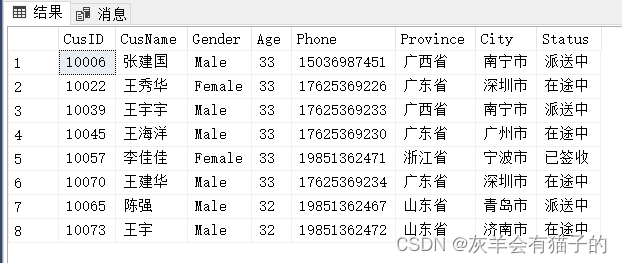
2.4.3 使用 TOP WITH TIES 包含与最后一行中的值匹配的行
查询年龄排前十的客户信息:
select top 10 with ties *
from CustomerInfo
order by Age desc
执行结果:

在此示例中,第10名年龄为32,因为语句使用了 TOP WITH TIES语句 ,所以它返回了另外6个年龄相同的顾客。
四、筛选数据
第1节 DISTINCT - 去除重复值
SELECT DISTINCT 子句来检索指定列列表中的唯一非重复值。
1.1 SELECT DISTINCT 子句简介
SELECT DISTINCT 子句语法:
SELECT DISTINCT <列名>
FROM <表名>
Note:
① 查询仅返回指定列中的非重复值,即从结果集中删除列中的重复值。
② 查询使用 SELECT 列表中所有指定列的值的组合来评估唯一性。
③ 将 DISTINCT 子句应用于具有NULL的列,则 DISTINCT 子句将仅保留一个NULL并消除另一个, DISTINCT 子句将所有NULL“值”视为相同的值。
1.2 SELECT DISTINCT 示例
1.2.1 DISTINCT 一列示例
查询CustomerInfo表中客户所在省份:
select distinct Province
from CustomerInfo
order by Province
执行结果:

1.2.2 DISTINCT 多列示例
查询CustomerInfo表中客户所在省份和城市:
select distinct Province,City
from CustomerInfo
order by Province
执行结果:

1.2.3 DISTINCT 具有 null 值示例
1.2.4 DISTINCT 与 GROUP BY 对比
查询CustomerInfo表中客户所在省份和城市(分组查询):
select Province,City
from CustomerInfo
group by Province,City
order by Province,City
执行结果:

与前面使用DISTINCT对比结果相同,相当于以下使用 DISTINCT 运算符的查询。
DISTINCT 和 GROUP BY 子句都通过删除重复项来减少结果集中返回的行数。但是,如果要对一个或多个列应用聚合函数,则应使用 GROUP BY 子句。
第2节 WHERE - 过滤查询返回的行
根据一个或多个条件筛选查询输出中的行。
2.1 WHERE 子句简介
使用 SELECT 语句查询一个表的数据时,会获得该表的所有行,这不一定必要,有时候可能只处理一组。要从表中获取满足一个或多个条件的行组,可使用where子句,语法如下所示:
select <列名1>,<列名2>,...
from [表]
where <条件>
以上语法:
① 在 WHERE 子句中,指定搜索条件以筛选由 FROM 子句返回的行。 WHERE 子句仅返回导致搜索条件计算为 TRUE 的行。
② 搜索条件是逻辑表达式或多个逻辑表达式的组合。在SQL中,逻辑表达式通常称为谓词。
③ 请注意,SQL Server使用三值谓词逻辑,其中逻辑表达式的计算结果可以是 TRUE 、 FALSE 或 UNKNOWN 。 WHERE 子句不会返回任何导致谓词计算为 FALSE 或 UNKNOWN 的行。
2.2 WHERE 子句示例
2.2.1 使用简单等式查找行
查询CustomerInfo表中已签收的所有顾客信息:
select *
from CustomerInfo
where Status = '已签收'
执行结果:
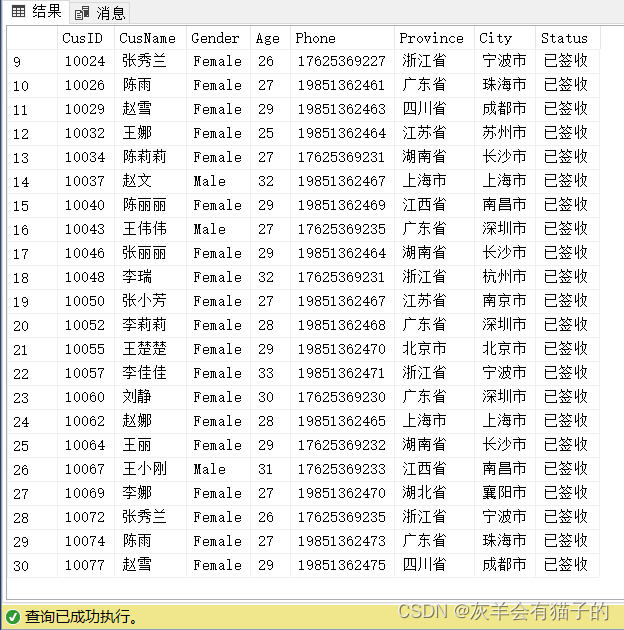
2.2.2 查找满足两个条件的行
查询CustomerInfo表中广东省已签收的所有顾客信息:
select *
from CustomerInfo
where Status = '已签收' and Province = '广东省'
执行结果:

2.2.3 使用比较运算符查找行
查询CustomerInfo表中已签收且年龄大于30岁的所有顾客信息:
select *
from CustomerInfo
where Status = '已签收' and Age > 30
执行结果:

2.2.4 查找满足两个条件之一的行
查询CustomerInfo表中是湖北或者北京地区的所有顾客信息:
select *
from CustomerInfo
where Province = '湖北省' or Province = '北京市'
执行结果:
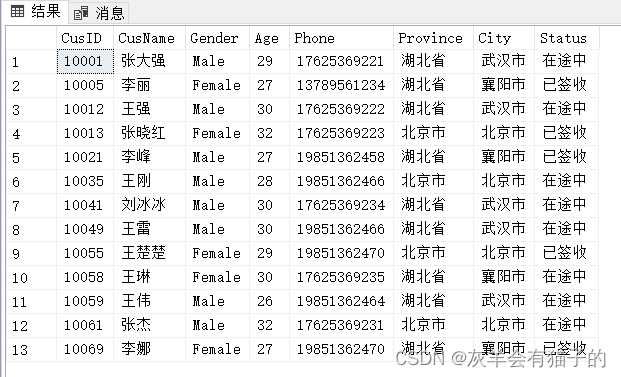
OR 关键字:满足条件之一的任何数据都包含在结果集中
2.2.4 查找值在两个值之间的行
2.2.4.1 使用between…and…关键字
查询年龄在30到35岁之间女性用户信息:
select *
from CustomerInfo
where Age between 30 and 35 and Gender = 'Female'
执行结果:

2.2.4.2 使用判断符
查询年龄在30到35岁之间女性用户信息:
select *
from CustomerInfo
where Age >= 30 and Age <= 35 and Gender = 'Female'
执行结果:

2.2.5 在值列表中查找具有值的行
查询在湖北、湖南和北京地区的客户信息“
select *
from CustomerInfo
where Province in ('湖北省','湖南省','北京市')
执行结果:

2.2.6 查找值包含字符串的行 - 模糊查询
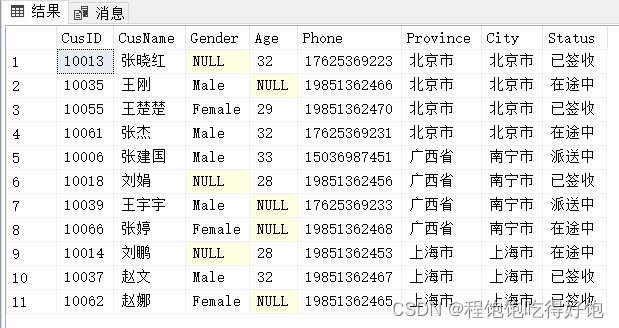
查找‘刘’姓客户的所有信息:
select *
from CustomerInfo
where CusName like'刘%'
执行结果:
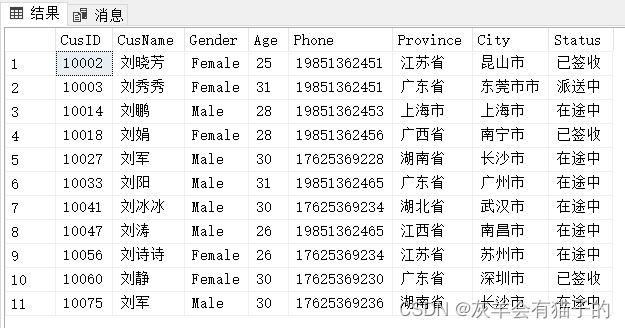
第3节 NULL
NULL 和三值逻辑;使用 IS NULL 和 IS NOT NULL 运算符来测试值是否为 NULL 。
3.1 NULL 和三值逻辑
在数据库中, NULL 用于表示不存在任何数据值。未知的数据在数据库中将其记录为 NULL 。
通常逻辑表达式的结果是 TRUE 或 FALSE 。当 NULL 参与逻辑评估时,结果是 UNKNOWN 。因此,逻辑表达式可以返回三值逻辑之一: TRUE 、 FALSE 和 UNKNOWN 。
执行下列查询代码:
if NULL = 0
print 1
else
print 0
if NULL <> 0
print 1
else
print 0
if NULL > 0
print 1
else
print 0
if NULL < 0
print 1
else
print 0
if NULL = NULL
print 1
else
print 0
执行结果:
0
0
0
0
0
通过结果我们可以发现,NULL 不等于任何东西,甚至不等于(<>)ta自己。这说明NULL 不等于 NULL ,因为每个 NULL 可能不同。(狠起来连自己都不是!)
3.2 IS NULL / IS NOT NULL
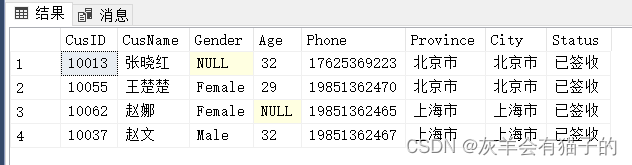
查找在 CustomerInfo表中没有记录Age的客户:
select *
from CustomerInfo
where Age = NULL
执行结果:

可以发现查询返回空结果集,WHERE 子句返回导致其谓词计算为 TRUE 的行。但是‘ Age = NULL ’表达式的计算结果为 UNKNOWN ,所以查询不到任何数据,要查询一个值是否为 NULL ,需要使用 IS NULL 运算符。
改写上述代码:
select *
from CustomerInfo
where Age is NULL
执行结果:

查询返回了没有电话信息的客户,要查询的值不是 NULL ,可以使用 IS NOT NULL 操作符。
以下查询返回记录Age的客户:
select *
from CustomerInfo
where Age is not NULL
第4节 AND
合并两个布尔表达式,如果所有表达式都为 true,则返回 true
4.1 AND 运算符简介
AND 是一个逻辑运算符,允许联合两个布尔表达式。仅当两个表达式的计算结果都为 TRUE 时,它才返回 TRUE 。
下面说明了 AND 运算符的语法:
<表达式1> and <表达式2>
<表达式1,2,...> 是计算结果为 TRUE 、 FALSE 和 UNKNOWN 的任何有效布尔表达式。
下表显示了使用 AND 运算符将 TRUE 、 FALSE 和 UNKNOWN 值组合在一起时的结果:
| TRUE | FALSE | UNKNOWN | |
|---|---|---|---|
| TRUE | TRUE | FALSE | UNKNOWN |
| FALSE | FALSE | FALSE | FALSE |
| UNKNOWN | UNKNOWN | FALSE | UNKNOWN |
Note:在表达式中使用多个逻辑运算符时,执行时会首先计算AND运算符。但是,可以使用括号更改计算顺序。
4.2 AND 运算符示例
4.2.1 一个 AND 运算符
查询CustomerInfo表中已签收且年龄大于30岁的所有顾客信息:
select *
from CustomerInfo
where Status = '已签收' and Age > 30
执行结果:
4.2.2 多个 AND 运算符
查询年龄在30到35岁之间女性用户信息:
select *
from CustomerInfo
where Age >= 30 and Age <= 35 and Gender = 'Female'
执行结果:
4.2.3 将 AND 运算符与其他逻辑运算符一起使用
查询北京或上海地区的顾客且物流状态为已签收的顾客信息:
select *
from CustomerInfo
where Province = '北京市' or Province = '上海市' and Status = '已签收'
order by Province
执行结果:

根据执行结果发现,结果集返回了北京地区的所有物流状态客户信息和上海地区已签收的信息,这并不符合我们的查询要求,原因在于在多个运算符同时存在时,会先计算AND运算,算出来的集在于OR前的表达式做运算,导致查询结果产生误差。
需要修改代码,改变运算顺序:
select *
from CustomerInfo
where (Province = '北京市' or Province = '上海市') and Status = '已签收'
order by Province
执行结果:
第5节 OR
组合两个布尔表达式,如果任一条件为 true,则返回 true
5.1 OR 运算符简介
OR 是一个逻辑运算符,用于联合两个布尔表达式。当任何一个条件的计算结果为 TRUE 时,它返回 TRUE 。
下面显示了 OR 操作符的语法:
<表达式1> or <表达式2>
<表达式1,2,...> 是计算结果为 TRUE 、 FALSE 和 UNKNOWN 的任何有效布尔表达式。
下表显示了使用 OR 运算符将 TRUE 、 FALSE 和 UNKNOWN 值组合在一起时的结果:
| TRUE | FALSE | UNKNOWN | |
|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE |
| FALSE | TRUE | FALSE | UNKNOWN |
| UNKNOWN | TRUE | UNKNOWN | UNKNOWN |
Note:在表达式中使用多个逻辑运算符时,sql 执行时会计算完AND运算符后再计算OR运算符。但是,可以使用括号更改计算顺序。
5.2 OR 运算符示例
5.2.1 一个OR运算符
查询北京、上海地区的客户信息:
select *
from CustomerInfo
where Province = '北京市' or Province = '上海市'
执行结果:

5.2.2 多个OR运算符
查询北京、上海和广西地区的客户信息:
select *
from CustomerInfo
where Province = '北京市' or Province = '上海市' or Province = '广西省'
执行结果:
在使用多个OR运算符且每个表达式条件相同时,可用IN关键字替换使用:
select *
from CustomerInfo
where Province in ('北京市' , '上海市' , '广西省')
执行结果:

5.2.3 OR运算符同AND运算符一起使用
查询北京或上海地区的顾客且物流状态为已签收的顾客信息:
select *
from CustomerInfo
where Province = '北京市' or Province = '上海市' and Status = '已签收'
order by Province
执行结果:
根据执行结果发现,结果集返回了北京地区的所有物流状态客户信息和上海地区已签收的信息,这并不符合我们的查询要求,原因在于在多个运算符同时存在时,会先计算AND运算,算出来的集在于OR前的表达式做运算,导致查询结果产生误差。
需要修改代码,改变运算顺序:
select *
from CustomerInfo
where (Province = '北京市' or Province = '上海市') and Status = '已签收'
order by Province
执行结果:
第6节 IN
检查值是否与列表或子查询中的任何值匹配
6.1 IN运算符概述
IN 运算符是一个逻辑运算符,允许查询指定的值是否与列表中的任何值匹配。
下面显示 IN 运算符的语法:
<列名> | <表达式> in (v1,v2,...)
在此语法中:
① 需要指定要查询的列或表达式。
② 指定要查询的值列表,所有值的类型必须与列或表达式的类型相同。
③ 如果列或表达式中的值等于列表中的任何值,则 IN 运算符的结果为 TRUE 。
IN 运算符等价于多个 OR 运算符,以下执行等价:
--in
column IN (v1, v2, v3)
--or
column = v1 OR column = v2 OR column = v3
若需要对 IN 运算符求反,请使用 NOT IN 运算符,语法如下:
<列名> | <表达式> not in (v1,v2,...)
如果列或表达式不等于列表中的任何值,则 NOT IN 运算符的结果为 TRUE 。
除了值列表之外,还可以使用子查询,该子查询通过 IN 运算符返回值列表,语法如下:
<列名> | <表达式> in (sql_query语句)
在此语法中,子查询是一个 SELECT 语句,返回单个列的值列表。
Note :如果一个列表包含 NULL ,则 IN 或 NOT IN 的结果将是 UNKNOWN 。
6.2 IN 运算符示例
6.2.1 IN 与值列表
查询北京、上海和广西地区的客户信息:
select *
from CustomerInfo
where Province in ('北京市' , '上海市' , '广西省')
执行结果:
6.2.2 NOT IN 与值列表
查询客户所在地区不在’广东省’,‘湖北省’,‘江苏省’,'浙江省’四省的顾客信息:
select *
from CustomerInfo
where Province not in ('广东省','湖北省','江苏省','浙江省')
order by Province
执行结果:

6.2.3 IN 运算符用于子查询
查询在省份客户总人数不足五人的省份的所有顾客信息:
select *
from CustomerInfo
where Province in (
select Province
from (
select Province,count(*) as cnt
from CustomerInfo
group by Province
) t
where cnt < 5
)
order by Province
以上代码在子查询中分组查询每个省的总人数,再查询不足五人的省份信息,in(省份)可查询出所在省份的顾客信息。
执行结果:
第7节 BETWEEN
查询条件是否在值范围之间
7.1 BETWEEN 运算符概述
BETWEEN 运算符是一个逻辑运算符,允许指定要查询的范围。
下面说明了 BETWEEN 运算符的语法:
column | expression BETWEEN start_expression AND end_expression
在此语法中:
① 指定要测试的列或表达式。
② 将 start_expression 和 end_expression 放在 BETWEEN 和 AND 关键字之间。 start_expression 、 end_expression 和 expression 必须具有相同的数据类型。
③ 如果要测试的表达式大于或等于 start_expression 的值且小于或等于 end_expression 的值,则 BETWEEN 运算符返回 TRUE 。
可以使用大于或等于(>=)和小于或等于(<=)来替换 BETWEEN 运算符,如下所示:
column | expression <= end_expression AND column | expression >= start_expression
但是使用 BETWEEN 运算符的条件比使用比较运算符>=、<=和逻辑运算符 AND 的条件可读性更强。
要对 BETWEEN 运算符的结果求反,请使用 NOT BETWEEN 运算符,如下所示:
column | expression NOT BETWEEN start_expression AND end_expresion
如果列或表达式中的值小于 start_expression 的值且大于 end_expression 的值,则 NOT BETWEEN 返回 TRUE 。它等价于以下条件:
column | expression < start_expression AND column | expression > end_expression
如果 BETWEEN 或 NOT BETWEEN 的任何输入是 NULL ,则结果是 UNKNOWN 。
7.2 BETWEEN 示例
7.2.1 BETWEEN 与数字示例
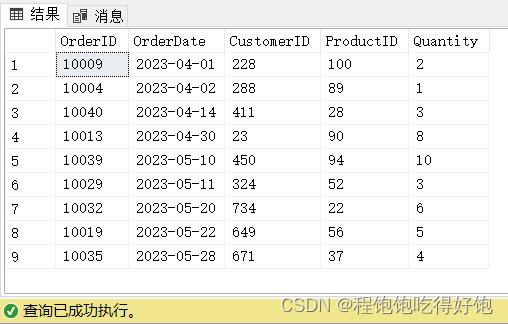
查询OrderDate表中购买数量在8~10的所有订单信息:
select *
from OrderDate
where Quantity between 8 and 10
order by Quantity
执行结果:

7.2.2 BETWEEN 和日期示例
查询OrderDate表中在四、五月份下单的订单信息:
select *
from OrderDate
where OrderDate between '20230401' and '20230531' ----between '2023-04-01' and '2023-05-31'
order by OrderDate
执行结果:
第8节 LIKE
检查字符串是否与指定的模式匹配
8.1 LIKE运算符概述
LIKE 是一个逻辑运算符,用于确定字符串是否与指定的模式匹配。可以包括常规字符和非常规字符。 LIKE 运算符用于 SELECT 、 UPDATE 和 DELETE 语句的 WHERE 子句中,以根据模式匹配筛选行。
LIKE 运算符的语法:
column | expression LIKE pattern [ESCAPE escape_character]
要对 LIKE 运算符的结果求反,请使用 NOT 运算符,如下所示:
column | expression NOT LIKE pattern [ESCAPE escape_character]
在语法中:
Pattern 是要在列或表达式中搜索的字符序列。它可以包含以下有效的通配符:
① 通配符百分比 (%):零个或多个字符的任何字符串。
② 下划线 (_) 通配符:任意单个字符。
③ [字符列表] 通配符:指定集中的任何单个字符。
④ [字符-字符]:指定范围内的任何单个字符。
⑤ [^]:不在列表或范围内的任何单个字符。
通配符使LIKE运算符比等于 (=) 和不等 (!=) 字符串比较运算符更灵活。
8.2 转义字符
转义字符指示 LIKE 操作符将转义字符视为常规字符。转义字符没有默认值,只能计算为一个字符。如果列或表达式与指定的模式匹配,则 LIKE 运算符返回 TRUE 。
8.3 LIKE 示例
8.3.1 % (百分号) 通配符示例
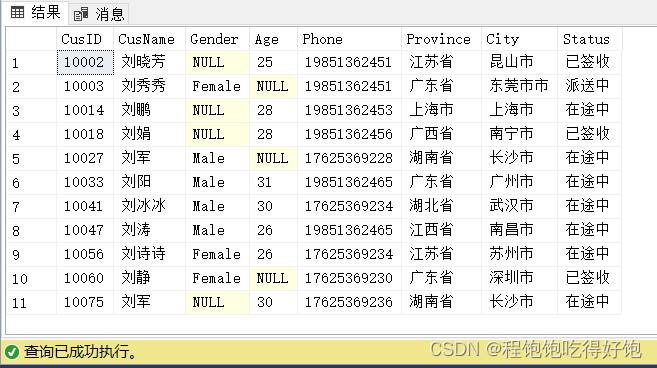
1、查询CustomerInfo表中,所有刘姓顾客的信息:
select *
from CustomerInfo
where CusName like '刘%'
执行结果:
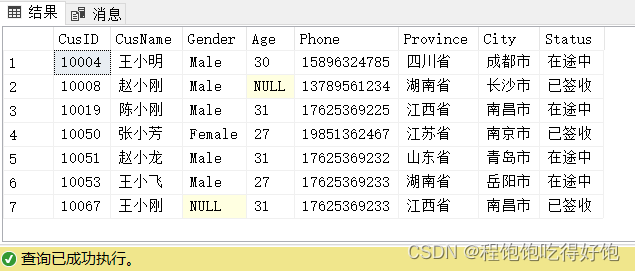
2、查询CustomerInfo表中,所有姓名含有‘小’字顾客的信息:
select *
from CustomerInfo
where CusName like '%小%'
执行结果:
3、查询顾客姓名以‘刚’字结尾的顾客订单信息:
select *
from CustomerInfo
where CusName like '%刚'
执行结果:

4、查询顾客姓名以‘王’开头‘宇’结尾的顾客订单信息:
select *
from CustomerInfo
where CusName like '王%宇'
执行结果:

8.3.2 _(下划线)通配符示例
下划线表示单个字符。查询顾客姓名第二个字是‘小’的所有顾客订单信息:
select *
from CustomerInfo
where CusName like '_小%' -- where CusName like '_小_'
执行结果:
