论文笔记:Bottom-Up and Top-Down Attention for Image Captioningand Visual Question Answering
主要学习该方法在VQA中的用法。
摘要
自顶向下和自底向上结合的注意力机制,使注意力能够在物体和其他显著图像区域的水平上进行计算。自底向上的机制(基于Faster R-CNN)提出图像区域,每个区域都有一个相关的特征向量,而自顶向下的机制确定特征权重。
1、介绍
注意力机制

上图是:左边:注意力模型在CNN特征上运行,这些特征对应于大小相等的图像区域的统一网格。右边:模型在物体和其他显著图像区域的水平上计算注意力。
将非视觉或特定任务环境驱动的注意力机制称为“自顶向下”,将纯视觉前馈注意力机制称为“自底向上”。
自底向上的机制提出了一组显著图像区域,每个区域由一个汇集的卷积特征向量表示(Faster R-CNN)。
自顶而下的机制使用特定任务的上下文来预测图像区域上的注意力分布,然后,所有区域上图像特征的加权平均值作为注意力的特征向量。
该模型在VQA v2.0测试标准服务器上实现了70.3%的总体准确率。
模型及代码位置
2、相关工作
Faster R-CNN,在目标检测数据集上预训练我们的我们的区域建议。
3、方法
给定图像I,我们的VQA模型将k个图像特征的集合作为输入,使得每个图像特征编码图像的一个显著区域。

空间图像特征V可以不同地定义我们自底向上地注意力模型地输出,或作为CNN的空间输出层。我们在3.1节中描述实现自下而上注意力模型的方法,在3.3节概述VQA模型。对于自顶向下的注意成分,模型都使用简单的一次注意机制,而不是最近模型中更复杂的方案,如堆叠,多头或双向注意,也可以应用。
3.1 自底向上的注意模型
我们根据边界框定义空间区域,并使用Faster R-CNN实现自底向上的注意力。Faster R-CNN是一个对象检测模型,旨在识别属于特定类别的对象实例,并使用边界框对他们进行定位。其他区域建议网络也可以作为一种关注机制进行训练。
Faster R-CNN分两个阶段检测物体。第一阶段称为区域提议网络(RPN),预测目标提议。一个小的网络在CNN的中间层次上滑动特征。在每个空间位置,网络预测一个与类别无关的对象得分和多个尺度和宽高比的描盒的边界盒细化。利用贪婪非最大值抑制和交叉-超并(IOU)阈值,选择顶盒方案作为第二个阶段的输入。在第二个阶段,使用感兴趣区域(RoI)池化来为每个盒子提案提取一个小的特征映射(例如14*14),然后将这些特征图作为CNN最后一层的输入批处理在一起。模型的最终输出包括类标签上的softmax分布和针对每个盒子建议的特定于类型的边界框改进。
将Faster R-CNN与ResNet-101 CNN结合使用。为了生成用于VQA的图像特征V的输出集,我们采用模型的最终属于,并使用IoU阈值对每个对象类执行非最大抑制。然后,选择所有类检测概率超过置信度阈值的区域。
对于每个选定的区域i,vi定义为均值池卷积特征,使得D维图像特征向量为2048.Faster R-CNN有效发挥了“硬”注意力机制的作用,因此从大量可能的配置中只选择了相对较少数量的图像边界框特征。
为了预训练自底向上的注意力模型,我们首先用ImageNet上预训练的ResNet-101初始化Faster R-CNN.然后我们在Visual Genome数据上训练。为了帮助学习好的特征表示,我们添加一个额外的训练输出来预测属性类(除了对象类)。
为了预测区域i的属性,我们将平均池化卷积特征vi与直接观察获得的对象类的学习嵌入连接起来,并将其输入到一个额外的输出层中,该输出层定义了每个属性类的softmax分布以及一个“无属性”类。
原始Faster R-CNN多任务损失函数包含4个分量,分别在RPN和最终目标类建议的分类和边界盒回归输出上定义。我们保留这些分量,并添加一个额外的多类损失分量来训练属性预测器。下图时一些模型输出的示例。
3.3 VQA模型
给定一组空间图像特征V,VQA模型还使用“软”自顶向下的注意力机制来加权每个特征,使用问题表示作为上下文。如图所示:

实现问题和图像的联合多模态嵌入,然后对一组候选答案的分数进行回归预测。
网络内的非线性变换是通过门控双曲正切激活实现的。
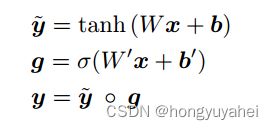
sigmoid激活函数,W、W‘是学习得到的权重,b、b’是学习到的偏差。(Hadmard)哈德曼乘积。向量g作为中间激活y的门倍增作用。
首先将每个问题编码为门控循环单元(GRU)的隐藏状态q,每个输入词使用学习词嵌入表示。给定GRU的输出q,我们生成一个非规范化的注意力权重ai
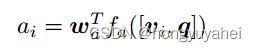
w是学习参数向量。使用如下公式计算归一化关注权和被关注图像特征,可能输出响应y的分布由下式给出:
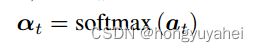
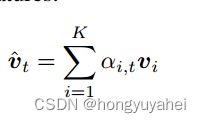
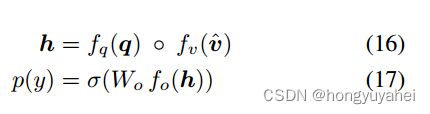
h是问题和图像的联合表示,wo是学习权重。
4、评估
4.1 数据集
4.1.1 Visual Genome 数据集
我们使用Visual Genome数据集来预训练自底而上的注意力模型,并在训练VQA模型时进行数据增强。该数据集包含108K图像,密集标注了包含对象、属性和关系的场景图以及1.7M视觉问题答案。
对于自底向上注意模型的预训练,我们只使用对象和属性数据,我们保留5K图像用于验证,5K图像用于将来的测试,将剩余的98K图像作为训练数据。
由于对象和属性注释由自由注释的字符串组成,而不是由类组成,因此我们对训练数据执行大量的清理和过滤。从2000个对象类和500个属性类开始,我们手动删除了在初始实验中表现出较差检测性能的抽象类。我们最终的训练集包含1600个对象类和400个属性类。请注意,我们不会合并或删除重叠的类(例如“person”,“man”,“guy”),单复数形式的类(例如“tree”,“trees”)和难以精确定位的类(例如“sky”,“grass”,“buildings”)。
在训练VQA模型时,我们使用Visual Genome问题和答案对增强VQA v2.0训练数据,前提是正确答案存在于模型的答案词汇表中。这代表了大约30%的可用数据,或485K个问题。
4.1.3 VQA v2.0数据集
为了评估我们提出的VQA模型,我们使用了最近引入的VQA v2.0数据集[12],该数据集试图通过平衡每个问题的答案来最小化学习数据集先验的有效性。该数据集被用作2017年VQA挑战2的基础,包含与MSCOCO图像相关的110万个问题和1110万个答案
我们执行标准的问题文本预处理和标记化。为了提高计算效率,问题被削减到最多14个单词。候选答案集被限制为训练集中出现8次以上的正确答案,导致输出词汇量为3129。我们的VQA测试服务器提交的内容在训练和验证集以及来自Visual Genome的额外问题和答案上进行了训练。为了评估答案质量,我们使用标准VQA度量[2]报告准确性,该度量考虑了注释者之间对基本真实答案的偶尔分歧。
4.2 ResNet基线
量化自下而上的关注在两方面的影响
在我们的字幕和VQA实验中,我们根据之前的工作和基线评估我们的完整模型(自顶向下)在每种情况下,基线(ResNet)都使用在ImageNet[34]上预训练的ResNet [13] CNN来代替自下而上的注意机制对每张图像进行编码
在VQA实验中,我们使用ResNet-200对调整后的输入图像进行编码[14]。在单独的实验中,我们使用评估将空间输出的大小从原始大小14×14改变为7×7(使用双线性插值)和1×1(即不加注意的平均池化)的效果。
4.4 VQA结果
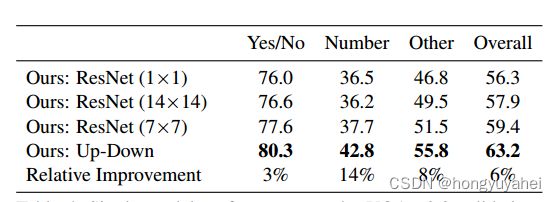
在表4中,我们报告了相对于VQA v2.0验证集上的几个ResNet基线,完整的Up-Down VQA模型的单个模型性能。尽管ResNet基线使用了大约两倍的卷积层,但自底向上关注的添加在所有问题类型上都比最佳ResNet基线有了显著的改进。
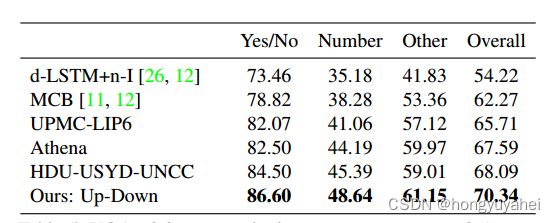
表5报告了30个集成模型在官方VQA 2.0测试标准评估服务器上的性能,以及先前发布的基线结果和其他条目的最高排名。
4.5 定性分析
为了帮助定性地评估我们的注意力方法,在图5中,我们可视化了由Up-Down字幕模型生成的不同单词的参与图像区域。

生成的显示出席图像区域的标题示例。对于每个生成的单词,我们在单个像素上可视化注意力权重,用红色勾勒出最大注意力权重的区域。我们的模型避免了传统的粗细细节之间的权衡,专注于裁剪的细节,比如在生成单词“playing”时的飞盘和绿色球员的护牙,以及大区域,比如在生成单词“dark”时的夜空。
正如这个例子所示,我们的方法同样能够聚焦于精细细节或大图像区域。这种能力的出现是因为我们模型中的关注候选者由许多重叠的区域组成,这些区域具有不同的尺度和长宽比——每个区域与一个对象、几个相关对象或一个显著的图像补丁对齐。
与传统方法不同的是,当一个候选注意区域对应于一个物体或几个相关的物体时,与这些物体相关的所有视觉概念似乎在空间上是共存的,并且被一起处理。换句话说,我们的方法能够同时考虑与对象相关的所有信息。这也是实现注意力的一种自然方式。在人类视觉系统中,将物体的独立特征以正确的组合方式整合的问题被称为特征绑定问题,实验表明,注意力在解决方案中起着核心作用[40,39]。
我们在图6中包含了一个VQA关注的例子。

说明注意力输出的VQA示例。给出“他们在哪个房间?”,该模型将重点放在灶台上,生成答案“厨房”。
5、结论
我们提出了一种新的自下而上和自上而下相结合的视觉注意机制。我们的方法可以更自然地在物体和其他显著区域的层面上计算注意力。将这种方法应用于图像字幕和视觉问答,我们在这两个任务中都获得了最先进的结果,同时提高了所得到的注意力权重的可解释性。
在高层次上,我们的工作更紧密地将涉及视觉和语言理解的任务与最近在目标检测方面的进展结合起来。虽然这为未来的研究提出了几个方向,但我们的方法的直接好处可能是通过简单地用预训练的自下而上的注意力特征替换预训练的CNN特征来获得的。