【Java】HashMap 详解(背诵版)
HashMap 背诵版
- 1. HashMap、Hashtable 和 ConcurrentHashMap 的区别?
-
- 1.1 线程安全:
- 1.2 继承关系:
- 1.3 允不允许null值:
- 2. HashMap 的数据结构
-
- 2.1 什么是hash表?
- 2.2 HashMap 的数据结构
- 3. 什么是hash冲突,怎么解决?
-
- 3.1 什么是hash冲突?
- 3.2 为什么不能完全避免hash冲突?
- 3.2 hash冲突怎么解决?
-
- (1)开放定址法(再散列法)
- (2)再哈希法
- (3)建立公共溢出区
- (4)链地址法
- 4. 为什么在 JDK8 中 HashMap 要转成红黑树?
-
- 4.1 为什么不继续使用链表?
- 4.2 为什么是红黑树?
-
- (1)二叉树
- (2)二叉平衡树
- (3)红黑树(自平衡二叉查找树)
- 4.3 链表与红黑树的相互转化条件
- 5. 源码分析
-
- 5.1 HashMap 的 get 方法是如何实现的?
环境:JDK 1.8.0_301
1. HashMap、Hashtable 和 ConcurrentHashMap 的区别?
1.1 线程安全:
HashMap 是非线程安全的。
Hashtable 中的方法是同步的,所以它是线程安全的。
ConcurrentHashMap 在 JDK1.8 之前,使用分段锁以在保证线程安全的同时获得更大的效率。JDK1.8 开始舍弃了分段锁,使用 自旋 + CAS + synchronized 来实现同步。官方的解释中:一是节省内存空间 ,二是分段锁需要更多的内存空间,而大多数情况下,并发粒度达不到设置的粒度,竞争概率较小,反而导致更新的长时间等待(因为锁定一段后整个段就无法更新了)三是提高GC效率。
1.2 继承关系:
HashTable 是基于陈旧的 Dictionary 类继承来的。
HashMap 继承的抽象类 AbstractMap 实现了 Map 接口。
ConcurrentHashMap 同样继承了抽象类 AbstractMap,并且实现了 ConcurrentMap 接口。
1.3 允不允许null值:
HashTable 中,key 和 value 都不允许出现 null 值,否则会抛出 NullPointerException 异常。
HashMap 中,null 可以作为 key、value 都可以。
ConcurrentHashMap 中,key、value 都不允许为 null。
2. HashMap 的数据结构
2.1 什么是hash表?
哈希表(Hash Table)是一种常见的数据结构,也被称为散列表。它通过使用哈希函数将键映射到存储桶中,以实现高效的键值对存储和查找操作。
哈希表的基本原理是,通过将键(key)作为输入,经过哈希函数的计算,得到一个对应的哈希码(hash code)。这个哈希码通常是一个整数,用于确定键在哈希表中的存储位置。
哈希表内部由一个数组(数组的每个元素称为桶)和哈希函数组成。当需要存储一个键值对时,哈希函数计算出键的哈希码,并将其映射到对应的桶中。如果多个键具有相同的哈希码,即发生哈希冲突,常见的解决方法是使用链表或开放地址法来处理冲突。
在哈希表中,通过键的哈希码可以快速定位到对应的桶,从而实现快速的查找和插入操作。哈希表的平均时间复杂度为 O(1),即常数时间,但在最坏情况下,哈希冲突较多时,时间复杂度可能会退化为 O(n),其中n是存储的键值对数量。
哈希表在实际应用中被广泛使用,例如在编程语言中的字典(Dictionary)或映射(Map)数据结构中,用于高效地存储和查找键值对。
2.2 HashMap 的数据结构
在 Java 中,保存数据有两种比较简单的数据结构:数组和链表。
数组的特点是:寻址容易,插入和删除困难;而链表的特点是:寻址困难,插入和删除容易。
-
JDK1.8 以前 HashMap 内部数据结构使用 数组 + 链表 进行存储。(了解即可)
-
JDK1.8 以后 HashMap 内部数据结构使用
数组 + 链表 + 红黑树进行存储。
3. 什么是hash冲突,怎么解决?
3.1 什么是hash冲突?
哈希表内部由一个数组(数组的每个元素称为桶)和哈希函数组成。当需要存储一个键值对时,哈希函数计算出键的哈希码,并将其映射到对应的桶中。如果多个不同键具有相同的哈希码,即发生哈希冲突
比如:对应不同的 key 可能获得相同的 hash code,即 key1 ≠ key2,但是H(key1) = H(key2)。
3.2 为什么不能完全避免hash冲突?
-
哈希函数是从关键字集合和地址集合的映像,通常关键字集合为无限大、长度不受限制(密码、或者文件都可以作为关键字),而地址集合却有限,无限量映射到有限量上肯定是存在重合的部分,这就是冲突。
-
哈希函数的复杂性:设计一个完全避免冲突的哈希函数是非常困难的。哈希函数需要具备均匀地将输入映射到输出空间的特性,但在实际情况下,很难找到一个完美的哈希函数,尤其是当输入数据的特征和分布较为复杂时。
尽管无法完全避免哈希冲突,但我们可以通过合理选择和设计哈希函数、调整哈希表的大小和负载因子等方法来降低冲突的概率。此外,使用解决冲突的方法,如链表法或开放地址法,可以处理哈希冲突并保证数据的正确性和高效性。
3.2 hash冲突怎么解决?
(1)开放定址法(再散列法)
开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
(2)再哈希法
当哈希地址发生冲突用其他的函数计算另一个哈希函数地址,直到冲突不再产生为止。
(3)建立公共溢出区
将哈希表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表中。
(4)链地址法
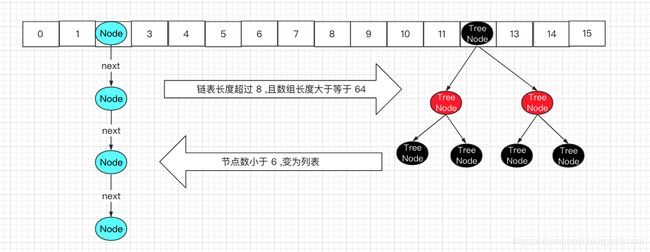
HashMap 把冲突的这些 key 组成一个单向链表,然后采用尾插法,把这样一个 key 保存到链表的尾部,另外为了避免链表过长影响查询效率,在链表长度大于 8,并且数组长度大于等于 64 的时候,HashMap 会把当前链表转化为红黑树,从而减少链表查询时间复杂度的问题,来提升查询效率。
4. 为什么在 JDK8 中 HashMap 要转成红黑树?
4.1 为什么不继续使用链表?
HashMap 解决hash冲突是通过链地址法完成的,在 JDK8 之前,如果产生冲突,就会把新增的元素增加到当前桶所在的链表中。
这样就会产生一个问题,当某个 bucket 冲突过多的时候,其指向的链表就会变得很长,这样如果 put 或者 get 该 bucket 上的元素时,复杂度就无限接近于O(N),这样显然是不可以接受的。
所以在 JDK1.7 的时候,在元素 put 之前做 hash 的时候,就会充分利用扰动函数,将不同 key 的 hash 尽可能的分散开。不过这样做起来效果还不是太好,所以当链表过长的时候,我们就要对其数据结构进行修改。
4.2 为什么是红黑树?
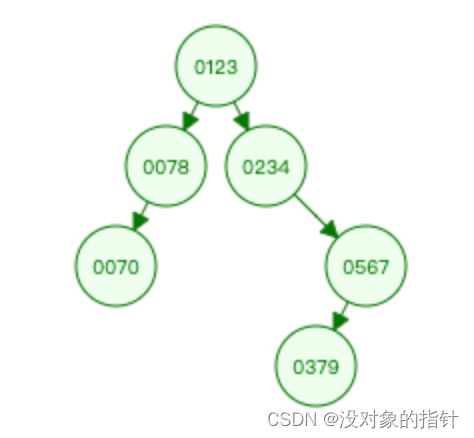
(1)二叉树
所谓的二叉查找树,一定是 left < root < right,这样我们遍历的时间复杂度就会由链表的 O(N) 变为二叉查找树的 O(logN),二叉查找树如下所示:
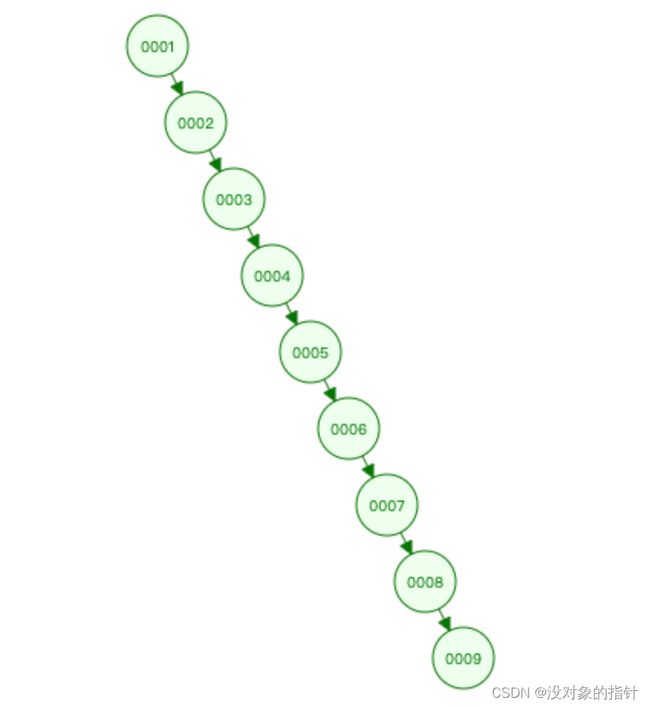
二叉搜索树通过增加了一条搜索路径,提高了查询效率,查找的效率取决于树的深度(高度)。但是,对于极端情况,当子节点都比父节点大或者小的时候,二叉查找树又会退化成链表,查询复杂度会重新变为 O(N),如下所示:
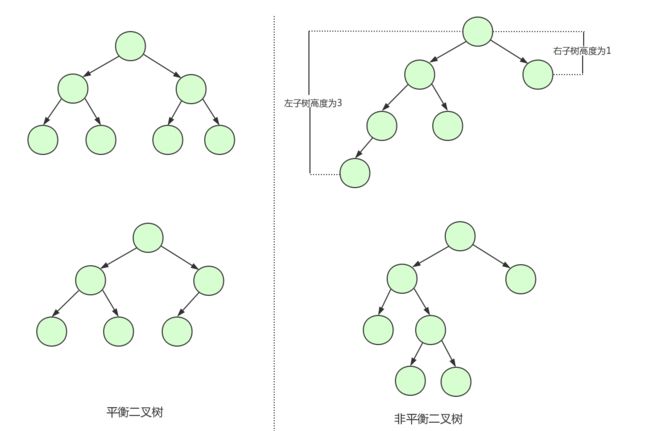
(2)二叉平衡树
二叉平衡树会在每次插入操作时来检查每个节点的左子树和右子树的高度差至多等于1,如果 >1,就需要进行左旋或者右旋操作,使其查询复杂度一直维持在 O(logN)。
但是这样就万无一失了吗?其实并不然,我们不仅要保证查询的时间复杂度,还需要保证插入的时间复杂度足够低,因为平衡二叉树要求高度差最多为 1,非常严格,导致每次插入都需要左旋或者右旋,极大的消耗了插入的时间。
对于那些插入和删除比较频繁的场景,AVL树显然是不合适的。为了保证查询和插入的时间复杂度维持在一个均衡的水平上,所以就引入了红黑树。
(3)红黑树(自平衡二叉查找树)
在红黑树中,所有的叶子节点都是黑色的的空节点,也就是叶子节点不存数据;任何相邻的节点都不能同时为红色,红色节点是被黑色节点隔开的,每个节点,从该节点到达其可达的叶子节点的所有路径,都包含相同数目的黑色节点。
我们可以得到如下结论:红黑树不会像 AVL树 一样追求绝对的平衡,它的插入最多两次旋转,删除最多三次旋转,在频繁的插入和删除场景中,红黑树的时间复杂度,是优于AVL树的。
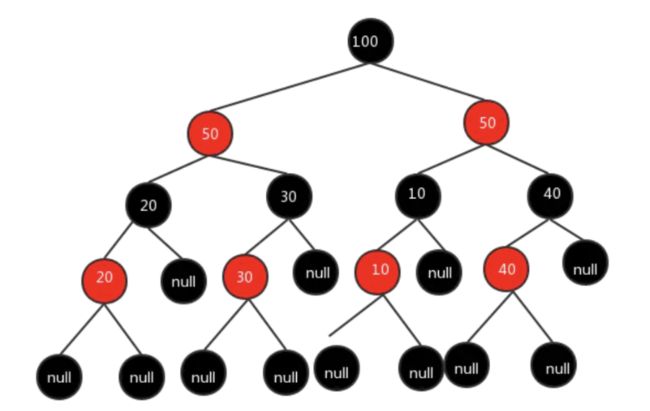
综上所述,这就是HashMap选择红黑树的原因。
4.3 链表与红黑树的相互转化条件
-
链表转红黑树:链表长度大于等于
8,且数组的长度大于64。注意,链表长度大于等于8一个条件并不会把链表转化为红黑树,只有两个条件都满足才会触发链表转红黑树的操作,否则会触发一次resize()。 -
红黑树转链表:红黑树的节点小于等于
6时。
5. 源码分析
5.1 HashMap 的 get 方法是如何实现的?
public V get(Object key) {
HashMap.Node<K, V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final HashMap.Node<K, V> getNode(int hash, Object key) {
// 当前 HashMap 的散列表的引用
HashMap.Node<K, V>[] tab;
// first:桶头元素,e:用于存放临时元素
HashMap.Node<K, V> first, e;
// table 数组的长度
int n;
// 元素中的 k
K k;
// 如果哈希表不为空 && key 对应的桶上不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 桶上的 key 就是要查找的 key,则直接命中,返回该元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 判断是否有后续节点
if ((e = first.next) != null) {
// 如果当前的桶是采用红黑树处理冲突,则调用红黑树的 get 方法去获取节点
if (first instanceof HashMap.TreeNode)
return ((HashMap.TreeNode<K, V>) first).getTreeNode(hash, key);
// 不是红黑树的话,那就是传统的链式结构了,通过循环的方法判断链中是否存在该 key
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
实现步骤大致如下:
1、通过 hash 值获取该 key 映射到的桶。
2、桶上的 key 就是要查找的 key,则直接命中,返回该元素。
3、桶上的 key 不是要查找的 key,则查看后续节点:
如果后续节点是树节点,通过调用树的方法查找该 key。
如果后续节点是链式节点,则通过循环遍历链查找该 key。