K8S 网络CNI
1. 简介
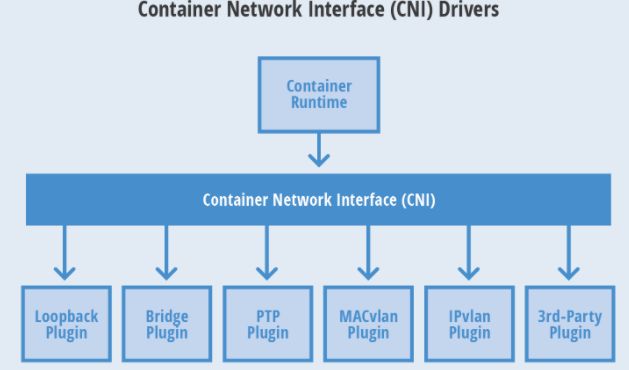
CNI: 容器网络接口(Container Network Interface):由Google和Core OS主导制定的容器网络标准,它仅仅是一个接口,具体的功能由各个网络插件自己去实现:
- 创建容器网络空间(network namespace)
- 将网络接口(interface)放到对应的网络空间
- 为网络接口分配IP等
- 容器删除时,回收网络资源
CNI不仅定义了接口规范,同时也提供了一些内置的标准实现,以及libcni这样的“胶水层”,大大降低了容器运行时与网络插件的接入门槛
注意:Docker并没有采用CNI标准,而是自己的CNM(Container Networking Model)标准。但由于技术和非技术原因,CNM模型并没有得到广泛的应用
接口定义:https://github.com/containernetworking/cni/blob/master/libcni/api.go
2. 官方插件
代码:https://github.com/containernetworking/plugins
官方插件主要分成三类:
- main:实现了某种特定网络功能的插件
- loopback:负责生成
lo网络,并配置地址127.0.0.1/8 - bridge:网桥,即虚拟交换机
- macvlan:从物理网卡虚拟多个虚拟网卡,每个都有独立的ip和mac地址
- ipvlan:与macvlan类似,区别在于虚拟网卡有相同的mac地址
- ptp:通过 veth pair 在容器和主机之间建立通道
- vlan:分配一个vlan设备
- host-device:将已存在的设备移入容器内
- loopback:负责生成
- meta:不提供具体的网络功能,但它会调用其他插件
- bandwidth:使用Token Bucket Filter(TBF) 限流插件
- firewall:通过iptables对容器网络流量控制
- portmap:通过iptables配置端口映射
- sbr:为网卡设置
source based routing - tuning:通过 sysctl 调整网络设备参数
- ipam:不提供网络功能,仅做IP管理
- static
- dhcp
- host-local:基于本地文件的 ip 分配和管理,把分配的 ip地址保存在文件中
3. 接口参数
网络插件时独立的可执行文件,被上层的容器管理平台(CRI)调用。网络插件做两件事:
- 把容器加入到网络
- 把容器从网络中删除
当调用CNI插件口时,实际上是通过gRPC协议调用可执行文件

调用插件的两种方式:
-
环境变量:通过环境变量传递参数
-
CNI_COMMAND:操作命令,ADD/DEL/CHECK/VERSION -
CNI_CONTAINERID:容器ID,唯一标识 -
CNI_NETNS:容器命名空间/run/netns/[nsname]CNI_IFNAME:需要被创建的网络接口名称,eth0
-
CNI_ARGS:调用时传入的额外参数。FOO=BAR;ABC=123 -
CNI_PATH:CNI插件目录/opt/cni/bin
-
-
配置文件
{
"name": "cbr0",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
链式调用:每个CNI擦话剧的职责时单一的,如上flannel负责网桥的相关配置;portmap则负责端口映射相关配置
4. Pod 网络共享
容器就是进程,容器拥有隔离的网络名称空间,就意味着进程所在的网络名称空间也是隔离的且与外界不能通信。为解决这个问题,可通过一个中间设备来连接两个独立的网络,Linux上,可通过网桥方式来实现这个虚拟设备
Network Namespace: 容器具有自己的网络协议栈并且被隔离在它自己的网络名称空间内。该隔离空间会为容器提供网卡、回环设备、IP地址、路由表、防火墙规则等基本网络环境。
Pod中的容器共享网络: Pod中第一个启动的容器为pause,它启动完成后就暂停。这个容器也称为Infra容器,使用汇编编写,当创建Pod时,k8s先创建名称空间,然后把其中的网络名称空间和这个Infra关联,后面创建的容器都是通过Join的方式和这个Infra容器关联在一起,这样这些容器和Infra都属于同一个网络命名空间。
$ kubectl describe pod busybox-deploy-6d65884477-96dgt | grep 'Container ID:'
Container ID: docker://527fb81cc989948b5fd660690f674078718939ea047e9e0593fbcea6abe911b7
# 容器在宿主机上的PID
$ docker inspect --format '{{.State.Pid}}' 527fb81cc989
3212
# 进程所属名称空间
$ ls -l /proc/3212/ns
total 0
lrwxrwxrwx 1 root root 0 Oct 11 09:34 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 root root 0 Oct 11 09:34 ipc -> 'ipc:[4026532657]'
lrwxrwxrwx 1 root root 0 Oct 11 09:34 mnt -> 'mnt:[4026532725]'
lrwxrwxrwx 1 root root 0 Oct 11 09:34 net -> 'net:[4026532660]'
lrwxrwxrwx 1 root root 0 Oct 11 09:34 pid -> 'pid:[4026532727]'
lrwxrwxrwx 1 root root 0 Oct 11 09:34 pid_for_children -> 'pid:[4026532727]'
lrwxrwxrwx 1 root root 0 Oct 11 09:34 user -> 'user:[4026531837]'
lrwxrwxrwx 1 root root 0 Oct 11 09:34 uts -> 'uts:[4026532726]'
# 进入Pod容器,查看命名空间
$ kubectl exec -it busybox-deploy-6d65884477-96dgt -- /bin/sh
/ # ls -l /proc/1/ns
total 0
lrwxrwxrwx 1 root root 0 Oct 11 01:38 cgroup -> cgroup:[4026531835]
lrwxrwxrwx 1 root root 0 Oct 11 01:38 ipc -> ipc:[4026532657]
lrwxrwxrwx 1 root root 0 Oct 11 01:38 mnt -> mnt:[4026532725]
lrwxrwxrwx 1 root root 0 Oct 11 01:38 net -> net:[4026532660]
lrwxrwxrwx 1 root root 0 Oct 11 01:38 pid -> pid:[4026532727]
lrwxrwxrwx 1 root root 0 Oct 11 01:38 pid_for_children -> pid:[4026532727]
lrwxrwxrwx 1 root root 0 Oct 11 01:38 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Oct 11 01:38 uts -> uts:[4026532726]
5. VETH 和 Bridge
- VETH: Virtual Ethernet, Linux内核支持的一种虚拟网络设备,表示一对虚拟网络接口,VETH Pair的两端可以处于不同的网络命名空间,所以可用来做主机和容器之间的网络通信。
- Bridge:类似交换机、用来做二层的交换,可将其他网络设备挂在Bridge上面,当有数据到达时,Bridge会根据报文中的MAC进展广播、转发或丢弃
- Namespace: Linux提供的一种内核级别的环境隔离方法,不同命名空间下的资源无法互访
实战网络拓扑:
+------------------------+
| | iptables +----------+
| br01 10.40.80.1/24 | | |
+----------+ <--------->+ ens33 |
| +------------------+-----+ | |
| | +----------+
+----+---------+ +-----------+-----+
| veth01 | | veth02 |
+--------------+ +-----------+-----+
| |
+--------+------+-----------+ +-------+---+-------------+
| ns01 | eth01 | | ns02 | eth02 |
| | 10.40.80.11 | | | 10.40.80.12 |
| +------------------+ | +-----------------+
| | | |
+---------------------------+ +-------------------------+
Step 1:创建网桥
# 创建网桥
$ brctl addbr br01
# 启用网桥
$ ip link set dev br01 up
# 分配地址
$ ip addr add 10.40.80.1/24 dev br01
Step 2:创建 namespace
# 创建两个ns: ns01和ns02
$ ip netns add ns01
$ ip netns add ns02
# ns 列表
$ ip netns list
Step 3:配置 veth pair
# 创建两对 veth
$ ip link add eth01 type veth peer name veth01
$ ip link add eth02 type veth peer name veth02
# 将veth的其中一端挂在默认命名空间的bridge下面
$ brctl addif br01 veth01
$ brctl addif br01 veth02
# 查看 bridge 下挂的 veth
$ brctl show
bridge name bridge id STP enabled interfaces
br01 8000.3a49144b6896 no veth01
veth02
# 启动两个 veth
$ ip link set dev veth01 up
$ ip link set dev veth02 up
# 将veth的另一端分配给上面创建的两个ns (默认空间的eth01ð02移到ns01/ns02下)
$ ip link set eth01 netns ns01
$ ip link set eth02 netns ns02
Step 4:netns下网络设置
ip netns exec [ns] [command] 在特定网络命名空间下执行命令
# 命名空间中的网络设备
$ ip netns exec ns01 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
13: eth01@if12: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 92:ad:7c:ee:05:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 启动和配置 ns01
ip netns exec ns01 ip link set lo up
ip netns exec ns01 ip addr add 10.40.80.11/24 dev eth01
ip netns exec ns01 ip link set eth01 up
ip netns exec ns01 ip route add default via 10.40.80.1
# 启动和配置 ns02
ip netns exec ns02 ip link set lo up
ip netns exec ns02 ip addr add 10.40.80.12/24 dev eth02
ip netns exec ns02 ip link set eth02 up
ip netns exec ns02 ip route add default via 10.40.80.1
# 命名空间中的网络设备
$ ip netns exec ns01 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
20: eth01@if19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a2:1f:39:f6:55:7f brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.40.80.11/24 scope global eth01
valid_lft forever preferred_lft forever
inet6 fe80::a01f:39ff:fef6:557f/64 scope link
valid_lft forever preferred_lft forever
Step 5:ping 测试
# ping 未通
$ ip netns exec ns01 ping 10.40.80.12 -c 3
PING 10.40.80.12 (10.40.80.12) 56(84) bytes of data.
--- 10.40.80.12 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2040ms
# 抓包: 发现无 ICMP echo reply
$ tcpdump -i br01 -nn
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on br01, link-type EN10MB (Ethernet), capture size 262144 bytes
17:13:21.403498 IP 10.40.80.11 > 10.40.80.12: ICMP echo request, id 10619, seq 1, length 64
17:13:22.418812 IP 10.40.80.11 > 10.40.80.12: ICMP echo request, id 10619, seq 2, length 64
17:13:23.443310 IP 10.40.80.11 > 10.40.80.12: ICMP echo request, id 10619, seq 3, length 64
17:13:25.682865 IP6 fe80::98ed:23ff:fe20:4601 > ff02::2: ICMP6, router solicitation, length 16
# 安装了 docker,FORWARD 链默认策略被 docker 设置成 drop, 从 ns01 发出的 ICMP 报文是会被丢弃的
$ iptables -S | grep 'P FORWARD'
-P FORWARD DROP
# 修改规则为放通
iptables -P FORWARD ACCEPT
iptables -A FORWARD -i br01 -j ACCEPT # 优选
# 再次测试正常
$ ip netns exec ns01 ping 10.40.80.12 -c 3
PING 10.40.80.12 (10.40.80.12) 56(84) bytes of data.
64 bytes from 10.40.80.12: icmp_seq=1 ttl=64 time=0.086 ms
64 bytes from 10.40.80.12: icmp_seq=2 ttl=64 time=0.114 ms
64 bytes from 10.40.80.12: icmp_seq=3 ttl=64 time=0.121 ms
--- 10.40.80.12 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2049ms
rtt min/avg/max/mdev = 0.086/0.107/0.121/0.015 ms
Step 6:arp 测试
$ ip netns exec ns01 arp
Address HWtype HWaddress Flags Mask Iface
10.40.80.1 ether 16:c7:91:fc:d9:d7 C eth01
10.40.80.12 ether 92:8e:70:61:a6:98 C eth01
$ ip addr
18: br01: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 16:c7:91:fc:d9:d7 brd ff:ff:ff:ff:ff:ff
inet 10.40.80.1/24 scope global br01
valid_lft forever preferred_lft forever
$ ip netns exec ns02 ip addr
22: eth02@if21: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 92:8e:70:61:a6:98 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.40.80.12/24 scope global eth02
valid_lft forever preferred_lft forever
inet6 fe80::908e:70ff:fe61:a698/64 scope link
valid_lft forever preferred_lft forever
Step 7:ping 外网
# 不通
$ ip netns exec ns01 ping 8.8.8.8 -c 3
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
--- 8.8.8.8 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2025ms
# 抓包: 发现只有出去的没有回来的包。原因应该是源地址是私有地址,发回来的包目的地址是私有地址的话会被丢弃
$ tcpdump -i br01 -nn
17:27:00.906188 IP 10.40.80.11 > 8.8.8.8: ICMP echo request, id 26897, seq 1, length 64
17:27:01.911423 IP 10.40.80.11 > 8.8.8.8: ICMP echo request, id 26897, seq 2, length 64
17:27:02.931241 IP 10.40.80.11 > 8.8.8.8: ICMP echo request, id 26897, seq 3, length 64
# 解决办法:做一下源 nat
iptables -t nat -A POSTROUTING -s 10.40.80.0/24 -j MASQUERADE
# 正常
$ ip netns exec ns01 ping 8.8.8.8 -c 3
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=127 time=35.9 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=127 time=35.7 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=127 time=35.8 ms
--- 8.8.8.8 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2004ms
rtt min/avg/max/mdev = 35.726/35.790/35.867/0.058 ms
Step 8:清理
ip netns del ns01
ip netns del ns02
ifconfig br01 down
brctl delbr br01
iptables -t nat -D POSTROUTING -s 10.40.80.0/24 -j MASQUERADE
6. Macvlan
6.1 简介
macvlan是kernel4.0+新支持的特性。该模式下的container网络同主机网络在同一个LAN里,可具有和主机一样的网络能力。
Macvlan 允许在主机的一个网络接口上配置多个虚拟的网络接口,这些网络接口有独立的 MAC 地址,也可以配置上 IP 地址进行通信。Macvlan 下的虚拟机或者容器网络和主机在同一个网段中,共享同一个广播域。
Macvlan 和 Bridge 比较相似,但因为它省去了 Bridge 的存在,所以配置和调试起来比较简单,而且效率也相对高。除此之外,Macvlan 自身也完美支持 VLAN
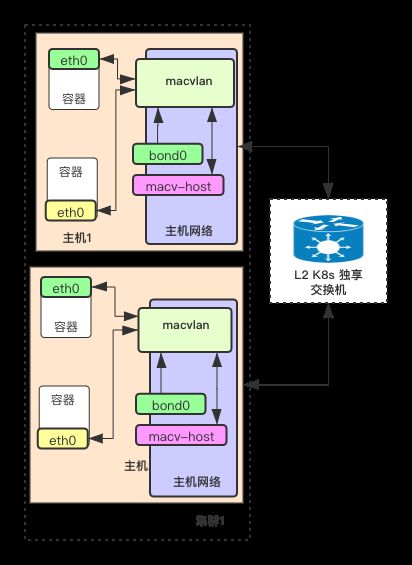
核心思想:
- 容器之间,通过 macvlan 互访,不需要借助外部交换机。所以,macvlan 模式,用的是 bridge 模式,而不是 vepa 模式,vepa 模式的话,需要交换机开启“发夹”模式。
- macvlan 的父接口bond0,它做了网卡聚合,可提高带宽。
- 宿主机网络上,有一个 macv-host 网卡。这个网卡其实是 macvlan 的一个子接口,其目的是为了实现宿主机与容器互访。
- K8s 集群的交换机是独享,且做了高可用的。为了应对以后容器数量增长提前做的准备。
6.2 工作模式
根据子接口通信方式的不同,macvlan存在四种工作模式:
- private:主接口会过滤掉交换机返回来的来自其子接口的报文,不同子接口之间无法互相通信。
- vepa(Virtual Ethernet Port Aggregator): 发送出去的报文经过交换机,交换机再发送到对应的目标地址(即使目标地址就是主机上的其它macvlan子接口),也就是hairpin mode模式,这个模式需要主接口连接的交换机支持 VEPA/802.1Qbg 特性;这种方式允许一个主接口上的多个子接口借助外部交换机进行相互通信,而LAN里面的广播包也会被主接口forward到所有子接口。这个种方式的一个典型应用是如果在外部交换机上有一些策略,则可以使用VEPA模式让所有子接口交互的包都会经由外部交换机的处理,便于统一管理整个子网的所有物理和虚拟接口。
- bridge:通过主机上的macvlan bridge将主接口的所有子接口连接在一起,不同子接口之间能够不借助外部交换机而进行直接通信,不需要将报文发送到主机之外;因为所有子接口的mac地址都是已知的,所以macvlan bridge不需要mac地址学习和STP的能力,所以是一个高效的bridge实现。
- passthru:container可以直接使用主机的网络接口,并具有对接口进行参数调整的能力。
需要注意的是,如果使用macvlan模式,虽然主接口和子接口在同一LAN,但是在主机上通过主接口是没有办法直接和子接口通信的;需要额外建立一个子接口,把主接口的IP配置给这个子接口,这样才能借助原来主接口的IP和子接口进行通信。
6.3 实战
1. 配置 macvlan:
# 1. 若需要,重置kubeadm
kubeadm reset
rm -rf /etc/cni/net.d
rm -rf /etc/kubernetes/
rm -rf /root/.kube
# 2. 重建集群
kubeadm init \
--apiserver-advertise-address=192.168.80.100 \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.21.4 \
--service-cidr=10.96.0.0/12 \
--pod-network-cidr=192.168.80.0/24 \
--ignore-preflight-errors=all
kubeadm join 192.168.80.100:6443 --token kk34dk.6xperiryclvx6aow \
--discovery-token-ca-cert-hash sha256:f84bd0402f8fc862f70daae3fb92be33a384b8ce74c663b7c1d5d95781bc7a1d
# 3. 未配置网络插件
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane,master 46s v1.21.4
k8s-node01 NotReady <none> 11s v1.21.4
k8s-node02 NotReady <none> 4s v1.21.4
# 4. 配置macvlan
mkdir -p /etc/cni/net.d
# k8s-master
cat > /etc/cni/net.d/10-maclannet.conf <<EOF
{
"name": "macvlannet",
"type": "macvlan",
"master": "ens33",
"mode": "vepa",
"isGateway": true,
"ipMasq": false,
"ipam": {
"type": "host-local",
"subnet": "192.168.80.0/24",
"rangeStart": "192.168.80.120",
"rangeEnd": "192.168.80.129",
"gateway": "192.168.80.2",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
EOF
# k8s-node01
cat > /etc/cni/net.d/10-maclannet.conf <<EOF
{
"name": "macvlannet",
"type": "macvlan",
"master": "ens33",
"mode": "vepa",
"isGateway": true,
"ipMasq": false,
"ipam": {
"type": "host-local",
"subnet": "192.168.80.0/24",
"rangeStart": "192.168.80.130",
"rangeEnd": "192.168.80.139",
"gateway": "192.168.80.2",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
EOF
# k8s-node02
cat > /etc/cni/net.d/10-maclannet.conf <<EOF
{
"name": "macvlannet",
"type": "macvlan",
"master": "ens33",
"mode": "vepa",
"isGateway": true,
"ipMasq": false,
"ipam": {
"type": "host-local",
"subnet": "192.168.80.0/24",
"rangeStart": "192.168.80.140",
"rangeEnd": "192.168.80.149",
"gateway": "192.168.80.2",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
EOF
# 5. 节点已全部Ready
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 114s v1.21.4
k8s-node01 Ready <none> 79s v1.21.4
k8s-node02 Ready <none> 72s v1.21.4
2. 验证:
# 主节点去除污点,方便测试
$ kubectl taint nodes k8s-master node-role.kubernetes.io/master:NoSchedule-
# 创建pod
$ cat > nginx.yaml <<EOF
kind: Deployment
metadata:
labels:
app: busybox
name: busybox
spec:
replicas: 3
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- image: busybox
name: busybox
command:
- sleep
- "3600"
restartPolicy: Always
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- busybox
topologyKey: "kubernetes.io/hostname"
EOF
$ kubectl get pod -l app=busybox -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-6978f56847-bjbhh 1/1 Running 0 43s 192.168.80.123 k8s-master <none> <none>
busybox-6978f56847-c7jl5 1/1 Running 0 43s 192.168.80.141 k8s-node02 <none> <none>
busybox-6978f56847-q74r4 1/1 Running 0 43s 192.168.80.131 k8s-node01 <none> <none>
$ kubectl exec -it busybox-6978f56847-bjbhh -- ip addr show eth0
2: eth0@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue
link/ether ea:a6:97:dc:76:87 brd ff:ff:ff:ff:ff:ff
inet 192.168.80.123/24 brd 192.168.80.255 scope global eth0
valid_lft forever preferred_lft forever
$ ip maddr show ens33
2: ens33
link 01:00:5e:00:00:01 users 5
link 33:33:00:00:00:01 users 5
link 33:33:ff:b0:f1:a6
link 01:80:c2:00:00:00
link 01:80:c2:00:00:03
link 01:80:c2:00:00:0e
inet 224.0.0.1
inet6 ff02::1:ffb0:f1a6
inet6 ff02::1 users 2
inet6 ff01::1