JDK21新特性
目录
- 传送门
- 前言
- 一、虚拟线程
-
- 1、Virtual Threads的开始
- 2、为什么需要Virtual Threads
- 3、那么Virtual Threads是如何应对这些问题
- 4、Virtual Threads 该怎么使用
- 二、Sequedced Collections(有序集合)
- 三、Deprecate the Windows 32-bit x86 Port for Removal
- 四、 Prepare to Disallow the Dynamic Loading of Agents
- 五、Generational ZGC(分代ZGC)
- 六、Pattern Matching for switch(switch 的模式匹配)
- 七、Record Patterns(记录模式)
- 八、Key Encapsulation Mechanism API
- 九、String Templates(字符串模板)(预览)
- 十、外部函数和内存 API(第三次预览)
- 十一、未命名模式和变量(预览)
- 十二、未命名类和实例 main 方法 (预览)
传送门
JDK8新特性
JDK9新特性
JDK10新特性
JDK11新特性
JDK12新特性
JDK13新特性
JDK14新特性
JDK15新特性
JDK16新特性
JDK17新特性
JDK18新特性
JDK19新特性
JDK20新特性
JDK21新特性
前言
JDK 21 于 2023 年 9 月 19 日 发布,这是一个非常重要的版本,里程碑式。
JDK21 是 LTS(长期支持版),至此为止,目前有 JDK8、JDK11、JDK17 和 JDK21 这四个长期支持版了。
JDK个版本含义:

GA,就是我上面框起来的“General Availability”的缩写,直译成中文,虽然是“普通可用”的意思,但是在软件行业,它就代表正式版。
如果对外发布一个 GA 版本,就意味着这个版本已经经过全面的测试,不存在任何重大的 bug,可供普通用户进行使用。
既然说到 GA 了,也顺便给大家普及一下一般我们看到的版本号的含义。
比如我们经常会看到一些软件发布的时候都会带上 Alpha、Beta、Gamma、RC 等等这些莫名其妙的单词,它们代表什么意思呢?
Alpha:软件或系统的内部测试版本,仅内部人员使用。一般不向外部发布,通常会有很多 Bug,除非你也是测试人员,否则不建议使用,alpha 就是 α,是希腊字母的第一位,表示最初级的版本,beta 就是 β,alpha 版就是比 beta 还早的测试版,一般都是内部测试的版本。
Beta:公开测试版。β 是希腊字母的第二个,顾名思义,这一版本通常是在 Alpha 版本后,该版本相对于 Alpha 版已有了很大的改进,消除了严重的错误,但还是存在着一缺陷,需要经过多次测试来进一步消除。这个阶段的版本会一直加入新的功能。
Gamma:软件或系统接近于成熟的版本,只需要做一些小的改进就能发行。是 beta 版做过一些修改,成为正式发布的候选版本。
RC:Release Candidate,发行候选版本。和 Beta 版最大的差别在于 Beta 阶段会一直加入新的功能,但是到了 RC 版本,几乎就不会加入新的功能了,而主要着重于除错。RC 版本是最终发放给用户的最接近正式版的版本,发行后改正 bug 就是正式版了,就是正式版之前的最后一个测试版。
GA:General Available,正式发布的版本,这个版本就是正式的版本。在国外都是用 GA 来说明 release 版本的。比如:MySQL Community Server 5.7.21 GA 这是 MySQL Community Server 5.7 第 21 个发行稳定的版本,GA 意味着 General Available,也就是官方开始推荐广泛使用了。
Release:这个版本通常就是所谓的“最终版本”,在前面版本的一系列测试版之后,终归会有一个正式版本,是最终交付用户使用的一个版本,该版本有时也称为标准版。一般情况下,Release 不会以单词形式出现在软件封面上,取而代之的是符号®。
Stable:稳定版。在开源软件中,都有 stable 版,这个就是开源软件的最终发行版,用户可以放心大胆的用了。这一版本基于 Beta 版,已知 Bug 都被修复,一般情况下,更新比较慢。
除了上面的这些之外,我们还经常看见一个 LTS 的版本号。
LTS,Long Term Support,长期支持版,是指针对软件的某一版本,提供长时间的技术支持、安全更新和错误修复。
相对于非 LTS 版本,LTS 版本被认为是更为稳定、可靠和安全的版本。因此,在需要稳定性和安全性较高的场景中,如生产环境、企业级应用等,LTS 版本得到广泛的应用。
在 Java 领域,LTS 版本是指 Oracle 公司发布的 Java SE(Standard Edition,标准版)中,每隔一段时间发布一个长期支持版本。
自 2018 年开始,Oracle Java SE 8 、Java SE 11、Java SE 17 成为了 LTS 版本,分别提供了 3 年、 8 年、至少 3 年的支持。
你看,一个小小的 GA 里面,隐藏了这么多的小知识点,让一不小心就铺(水)垫(了)这么长。
JDK 21 的 GA 版本,一共发布了 15 个新特性:

并且可以看出下次LTS版本是JDK25

一、虚拟线程

图中可以看出,Tomcat11在JDK21发布之前就预先支持虚拟线程了,非常看好JDK21。
1、Virtual Threads的开始
JDK19 预览版初次出现
在从2017年loom项目正式开始,Virtual Threads的推进算是比较迅速的,JDK19出了预览版之后,很多大佬都对此表示肯定。
相比较后面JDK21的release版本, JDK19的预览版基本没有什么太大的区别,无非是一些细节上的完善以及JDK内部对Virtual Threads的应用。
JDK21 Virtual Threads的正式发布
两年后的现在,千呼万唤始出来,JDK21在23年9月19日正式发布。Virtual Threads作为正式的Feature亮相。
相对于近些年来炙手可热的Go来说,Java算得上一个老前辈了,Java全面的功能,完整的生态,无数开发者的支持,也不算弱的性能,让Java在服务端开发上仍是TOP级别。
但是,大人,时代变了。
Go虽然也不算横空出世,发展了10多年之后,终于在云原生时代崛起,其极佳的性能表现在k8s等基础设施的服务端开放上,有着很大的优势。
虽然Go作为近些年崛起的语言仍然有着不太完备的表现,像2022年才支持的泛型、Go modules、异常处理等基础为开发人员诟病。
但是Go语言的并发处理方式,非常的轻量级,且易于使用,如果你想并发地运行一个函数,只需要使用 go function(arguments)。如果你需要让函数间进行通信,你可以使用通道,这些通道默认会同步执行,即在两端都准备就绪前,会暂停执行。 goroutine、GC机制、快速的编译时间等等强大特性,吸引了众多的开发者在越来越多的服务端应用上使用。
对于进程和线程等简单描述如下:
进程:
进程是应用程序的启动实例,每个进程都有独立的内存空间,不同进程通过进程间的通信方式来通信。
线程:
线程从属于进程,每个进程至少包含一个线程,线程是CPU调度的基本单位,多个线程之间可以共享进程的资源并通过共享内存等线程间的通信方式来通信。
协程:
协程可以理解为一种轻量级线程,与线程相比,协程不受操作系统调度,协程调度器由用户应用程序提供,协程调度器按照调度策略把协程调度到线程中运行。
Go语言的协程,相比于Java,其更好的性能表现、更轻量级、不需要操作系统调度让很多Java开发者垂涎,盼星星盼月亮,也希望Java什么时候也能老树逢春,久旱逢甘霖。
其实很早之前Oracle官方就传出了要给JDK搞一个轻量级线程,最早很多人把它叫做纤程(fibers),听起来就很轻很细~。
2、为什么需要Virtual Threads
Virtual Threads的出现解决了什么问题,相对于之前的操作系统线程或者说平台线程(Platform Threads)有什么优势。
JVM使用平台线程和操作系统线程是一一对应的,有些使用的缺点在Java不断地发展中不断地凸显出来
- 创建单个线程所需资源过多,平台线程本身就是很珍贵的资源
- 受限于机器硬件,平台线程的个数不能创建过多,且创建及回收线程需要耗费一定资源
我们不可能为每个请求或者说任务分配一个单独的线程,当请求量达到一定阈值之后,只能通过线程池或者其他异步的方式来处理请求。 - Java运行中线程上下文的切换非常频繁,切换需要的资源也耗费不少
3、那么Virtual Threads是如何应对这些问题
- Virtual Threads的关键特点是便宜、数量多、轻量级,相对于OS线程代价可能只是千分之一。
- 无需池化使用,寿命周期短
- 每个请求都创建一个虚拟线程,无需上下文切换 thread-per-request style

- 由OS线程装载Virtual Threads,并随时可以卸载(特殊同步代码块除外),然后执行其他Virtual Threads
首先需要明确的是Virtual Threads是基于平台线程(OS线程)运行的,并且是由JVM创建并管理的。
它是由JVM调度,mounting (装载)到OS线程上执行的,当阻塞的时候,再从OS线程上unmounting(卸载),OS线程可以继续mounting其他的虚拟线程,继续执行。
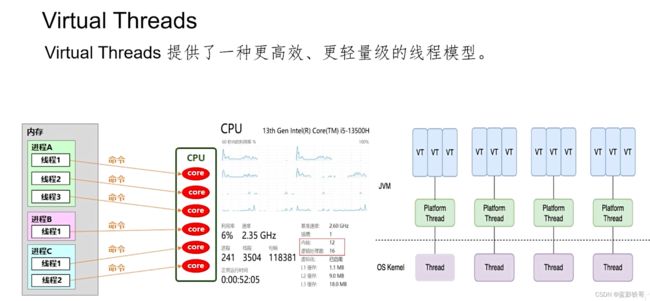
类似的,笔记本电脑有12个物理内核,会虚拟出4个,最后是16个,可以并行处理16个进程。同样类比,java中原来的一个实际线程可以对应n个虚拟线程,这些虚拟线程可以更多的完成任务,大大提高了并发程度,而且由于n个虚拟线程对应一个实际线程,虚拟线程之间的切换频率几何级下降了。

4、Virtual Threads 该怎么使用
先看下说明,为了方便用户使用,JDK提供了一系列使用虚拟线程的API,并且兼容之前线程的使用方式,无需为使用虚拟线程而重写应用程序。

使用静态构造器方法(新API)
Thread.startVirtualThread(() -> {
System.out.println(Thread.currentThread());
});
Thread.ofVirtual().start(() -> {
System.out.println(Thread.currentThread());
});
使用Executors创建虚拟线程池
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
上述代码会创建一个无限的虚拟线程池。


使用时候的注意事项
- Thread.setPriority(int) 和 Thread.setDaemon(boolean) 这俩方法对虚拟线程不起作用
- Thread.getThreadGroup() 会返回一个虚拟的空VirtualThreads group。
- 同一个任务使用Virtual Threads和Platform Threads执行效率上是完全一样的,并不会有什么性能上的提升
- 尽量使用JUC包下的并发控制例如ReentrantLock来进行同步控制,而不使用synchronized 。 synchronized 同步代码块会pinning(别住或者说Block)虚拟线程,这点JDK官方说后面有可能会优化这点
- Virtual Threads 被设计成final类,并不能使用子类来继承
- 不适用于计算密集型任务: 虚拟线程适用于I/O密集型任务,但不适用于计算密集型任务,因为它们在同一线程中运行,可能会阻塞其他虚拟线程。
- 新特性自然有很多BUG,这点在JDK的Issue中确实也体现了,使用请慎重!!

知乎有一个关于 Java 19 虚拟线程的讨论,感兴趣的可以去看看:
https://www.zhihu.com/question/536743167 。
Java 虚拟线程的详细解读和原理可以看下面文章:
JVM 中的线程模型是用户级的么?
虚拟线程极简入门
虚拟线程原理及性能分析|得物技术
Java19 正式 GA!看虚拟线程如何大幅提高系统吞吐量
虚拟线程 - VirtualThread 源码透视
二、Sequedced Collections(有序集合)

新的集合关系图:


JDK 21引入了一种新的集合类型,即序列化集合。序列化集合通过提供可预测的迭代顺序,解决了在多线程环境下遍历集合时可能出现的竞争条件和不确定性问题。
List<String> list = new SequencedArrayList<();
list.add("Apple");
list.add("Banana");
list.add("Orange");
for (String fruit : list.reversed()) {// 反向循环
System.out.println(fruit);// Orange,Banana,Apple
}
在上面的代码中,我们创建了一个 SequencedArrayList,并向其中添加了一些水果。使用增强的 for 反向循环遍历集合时,我们可以确保按照添加的顺序输出水果的名称:Orange,Banana,Apple。
这种可预测的顺序确保了集合在多线程环境下的一致性和可靠性。
JDK 21 引入了一种新的集合类型:Sequenced Collections(序列化集合,也叫有序集合),这是一种具有确定出现顺序(encounter order)的集合(无论我们遍历这样的集合多少次,元素的出现顺序始终是固定的)。序列化集合提供了处理集合的第一个和最后一个元素以及反向视图(与原始集合相反的顺序)的简单方法。
Sequenced Collections 包括以下三个接口:
- SequencedCollection
- SequencedSet
- SequencedMap
SequencedCollection 接口继承了 Collection接口, 提供了在集合两端访问、添加或删除元素以及获取集合的反向视图的方法。
interface SequencedCollection<E> extends Collection<E> {
// New Method
SequencedCollection<E> reversed();
// Promoted methods from DequeList 和 Deque 接口实现了SequencedCollection 接口。
这里以 ArrayList 为例,演示一下实际使用效果:
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(1); // List contains: [1]
arrayList.addFirst(0); // List contains: [0, 1]
arrayList.addLast(2); // List contains: [0, 1, 2]
Integer firstElement = arrayList.getFirst(); // 0
Integer lastElement = arrayList.getLast(); // 2
List<Integer> reversed = arrayList.reversed();
System.out.println(reversed); // Prints [2, 1, 0]
SequencedSet接口直接继承了 SequencedCollection 接口并重写了 reversed() 方法。
interface SequencedSet<E> extends SequencedCollection<E>, Set<E> {
SequencedSet<E> reversed();
}
SortedSet 和 LinkedHashSet 实现了SequencedSet接口。
这里以 LinkedHashSet 为例,演示一下实际使用效果:
LinkedHashSet<Integer> linkedHashSet = new LinkedHashSet<>(List.of(1, 2, 3));
Integer firstElement = linkedHashSet.getFirst(); // 1
Integer lastElement = linkedHashSet.getLast(); // 3
linkedHashSet.addFirst(0); //List contains: [0, 1, 2, 3]
linkedHashSet.addLast(4); //List contains: [0, 1, 2, 3, 4]
System.out.println(linkedHashSet.reversed()); //Prints [5, 3, 2, 1, 0]
SequencedMap 接口继承了 Map接口, 提供了在集合两端访问、添加或删除键值对、获取包含 key 的 SequencedSet、包含 value 的 SequencedCollection、包含 entry(键值对) 的 SequencedSet以及获取集合的反向视图的方法。
interface SequencedMap<K,V> extends Map<K,V> {
// New Methods
SequencedMap<K,V> reversed();
SequencedSet<K> sequencedKeySet();
SequencedCollection<V> sequencedValues();
SequencedSet<Entry<K,V>> sequencedEntrySet();
V putFirst(K, V);
V putLast(K, V);
// Promoted Methods from NavigableMapSortedMap 和LinkedHashMap 实现了SequencedMap 接口。
这里以 LinkedHashMap 为例,演示一下实际使用效果:
LinkedHashMap<Integer, String> map = new LinkedHashMap<>();
map.put(1, "One");
map.put(2, "Two");
map.put(3, "Three");
map.firstEntry(); //1=One
map.lastEntry(); //3=Three
System.out.println(map); //{1=One, 2=Two, 3=Three}
Map.Entry<Integer, String> first = map.pollFirstEntry(); //1=One
Map.Entry<Integer, String> last = map.pollLastEntry(); //3=Three
System.out.println(map); //{2=Two}
map.putFirst(1, "One"); //{1=One, 2=Two}
map.putLast(3, "Three"); //{1=One, 2=Two, 3=Three}
System.out.println(map); //{1=One, 2=Two, 3=Three}
System.out.println(map.reversed()); //{3=Three, 2=Two, 1=One}
三、Deprecate the Windows 32-bit x86 Port for Removal

JEP 449 Deprecate the Windows 32-bit x86 Port for Removal旨在废弃并最终移除 Windows 32 位 x86 平台上的 Java 支持。这是基于该平台已经逐渐被淘汰、性能限制和安全问题等原因做出的合理举措。废弃该平台上的 Java 支持可以提高应用程序的性能和安全性,并与现代计算机趋势相符。开发者需要及时关注 JEP 449 的实施情况,并根据需要进行相应的迁移和调整。Windows 32 位 x86 平台上的 Java 用户需要考虑升级到 64 位架构的计算机和操作系统,以继续获得最新的 Java 更新和功能改进。
四、 Prepare to Disallow the Dynamic Loading of Agents

动态加载代理禁用准备是一个 Java 增强提案,旨在禁止动态加载代理以提高应用程序的安全性。它通过修改类加载器、Instrumentation API 和安全管理器来实现禁止动态加载代理的功能。尽管这样做可以增加应用程序的安全性,但也可能影响依赖于动态加载代理的现有代码。因此,在使用该功能之前需要仔细评估现有代码的依赖关系。
五、Generational ZGC(分代ZGC)


Generational ZGC 是一种用于 Java 虚拟机的垃圾回收器,旨在提供低延迟和高吞吐量的垃圾回收解决方案。它通过并发处理和分代回收的策略,实现了非常低的停顿时间,并且能够处理非常大的堆内存。然而,使用 Generational ZGC 需要注意性能开销和配置复杂性。
六、Pattern Matching for switch(switch 的模式匹配)



Pattern Matching for switch 是 Java 14 中引入的一个新特性,它允许在 switch 语句中使用模式匹配。通过这个特性,我们可以更方便地对变量进行类型判断和提取。它简化了对变量类型的判断和提取逻辑,使代码更加简洁、清晰,并且增强了代码的可读性和可维护性。但需要注意的是,目前只支持基本数据类型和引用类型的模式匹配,不支持其他特殊类型的模式匹配。
七、Record Patterns(记录模式)




Record Patterns 是 Java 16 引入的一个新特性,它提供了一种简洁、清晰的方式来进行模式匹配,并且可以方便地从记录类型中提取字段值。使用 Record Patterns 可以使代码更加简洁、可读,并提高开发效率。然而,由于记录类型是不可变的,因此在修改字段值时需要创建新的对象。同时,Record Patterns 目前只能用于记录类型,不能用于其他类。
八、Key Encapsulation Mechanism API

Key Encapsulation Mechanism API 是一个用于支持密钥封装机制的 Java API。它提供了一组方法和类,用于生成、封装和解封装密钥。通过使用公钥进行密钥交换,避免了传统密钥交换方式中存在的安全风险。API 的实现原理基于非对称加密算法和密钥封装机制,能够提供较高的安全性和灵活性。开发者可以轻松地使用 API 进行密钥封装和解封装操作,并与现有的密码学算法和协议集成,满足不同场景的需求。然而,API 的使用需要注意私钥的安全性和密文的传输安全。
九、String Templates(字符串模板)(预览)
String Templates(字符串模板) 目前仍然是 JDK 21 中的一个预览功能。String Templates 提供了一种更简洁、更直观的方式来动态构建字符串。通过使用占位符${},我们可以将变量的值直接嵌入到字符串中,而不需要手动处理。在运行时,Java 编译器会将这些占位符替换为实际的变量值。并且,表达式支持局部变量、静态/非静态字段甚至方法、计算结果等特性。实际上,String Templates(字符串模板)再大多数编程语言中都存在:
"Greetings {{ name }}!"; //Angular
`Greetings ${ name }!`; //Typescript
$"Greetings { name }!" //Visual basic
f"Greetings { name }!" //Python
Java 在没有 String Templates 之前,我们通常使用字符串拼接或格式化方法来构建字符串:
//concatenation
message = "Greetings " + name + "!";
//String.format()
message = String.format("Greetings %s!", name); //concatenation
//MessageFormat
message = new MessageFormat("Greetings {0}!").format(name);
//StringBuilder
message = new StringBuilder().append("Greetings ").append(name).append("!").toString();
这些方法或多或少都存在一些缺点,比如难以阅读、冗长、复杂。
Java 使用 String Templates 进行字符串拼接,可以直接在字符串中嵌入表达式,而无需进行额外的处理:
String message = STR."Greetings \{name}!";
在上面的模板表达式中:
- STR 是模板处理器。
- {name}为表达式,运行时,这些表达式将被相应的变量值替换。
Java 目前支持三种模板处理器:
- STR:自动执行字符串插值,即将模板中的每个嵌入式表达式替换为其值(转换为字符串)。
- FMT:和 STR 类似,但是它还可以接受格式说明符,这些格式说明符出现在嵌入式表达式的左边,用来控制输出的样式
- RAW:不会像 STR 和 FMT 模板处理器那样自动处理字符串模板,而是返回一个 StringTemplate 对象,这个对象包含了模板中的文本和表达式的信息
String name = "Lokesh";
//STR
String message = STR."Greetings \{name}.";
//FMT
String message = STR."Greetings %-12s\{name}.";
//RAW
StringTemplate st = RAW."Greetings \{name}.";
String message = STR.process(st);
除了 JDK 自带的三种模板处理器外,你还可以实现 StringTemplate.Processor 接口来创建自己的模板处理器。
我们可以使用局部变量、静态/非静态字段甚至方法作为嵌入表达式:
//variable
message = STR."Greetings \{name}!";
//method
message = STR."Greetings \{getName()}!";
//field
message = STR."Greetings \{this.name}!";
还可以在表达式中执行计算并打印结果:
int x = 10, y = 20;
String s = STR."\{x} + \{y} = \{x + y}"; //"10 + 20 = 30"
为了提高可读性,我们可以将嵌入的表达式分成多行:
String time = STR."The current time is \{
//sample comment - current time in HH:mm:ss
DateTimeFormatter
.ofPattern("HH:mm:ss")
.format(LocalTime.now())
}.";
十、外部函数和内存 API(第三次预览)
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 JEP 412 提出。第二轮孵化由JEP 419 提出并集成到了 Java 18 中,预览由 JEP 424 提出并集成到了 Java 19 中。
JDK 21 中是第三次预览,由 JEP 442 提出。
在 Java 19 新特性有详细介绍。
十一、未命名模式和变量(预览)
未命名模式和变量使得我们可以使用下划线 _ 表示未命名的变量以及模式匹配时不使用的组件,旨在提高代码的可读性和可维护性。
未命名变量的典型场景是 try-with-resources 语句、 catch 子句中的异常变量和for循环。当变量不需要使用的时候就可以使用下划线 _代替,这样清晰标识未被使用的变量。
try (var _ = ScopedContext.acquire()) {
// No use of acquired resource
}
try { ... }
catch (Exception _) { ... }
catch (Throwable _) { ... }
for (int i = 0, _ = runOnce(); i < arr.length; i++) {
...
}
未命名模式是一个无条件的模式,并不绑定任何值。未命名模式变量出现在类型模式中。
if (r instanceof ColoredPoint(_, Color c)) { ... c ... }
switch (b) {
case Box(RedBall _), Box(BlueBall _) -> processBox(b);
case Box(GreenBall _) -> stopProcessing();
case Box(_) -> pickAnotherBox();
}
十二、未命名类和实例 main 方法 (预览)
这个特性主要简化了 main 方法的的声明。对于 Java 初学者来说,这个 main 方法的声明引入了太多的 Java 语法概念,不利于初学者快速上手。
没有使用该特性之前定义一个 main 方法:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
使用该新特性之后定义一个 main 方法:
class HelloWorld {
void main() {
System.out.println("Hello, World!");
}
}
进一步精简(未命名的类允许我们不定义类名):
void main() {
System.out.println("Hello, World!");
}
备注:
大神参考资料:https://blog.csdn.net/njpkhuan/article/details/133177862
Java 21 String Templates:https://howtodoinjava.com/java/java-string-templates/
Java 21 Sequenced Collections:https://howtodoinjava.com/java/sequenced-collections/