基于机器深度学习的交通标志目标识别
在线工具推荐: 三维数字孪生场景工具 - GLTF/GLB在线编辑器 - Three.js AI自动纹理化开发 - YOLO 虚幻合成数据生成器 - 3D模型在线转换 - 3D模型预览图生成服务
智能交通系统(ITS),包括无人驾驶车辆,尽管在道路上,已经逐渐成熟。如何消除各种环境因素造成的干扰,进行准确高效的交通标志检测和识别,是一个关键的技术难题。然而,传统的视觉对象识别主要依赖于视觉特征提取,例如颜色和边缘,这存在局限性。卷积神经网络(CNN)是针对基于深度学习的视觉对象识别而设计的,成功克服了传统对象识别的缺点。
在本文中,我们基于我们的交通标志识别 (TSR) 数据集实施了一个实验来评估最新版本的 YOLOv5 的性能,本项目中的实验利用UnrealSynth虚幻合成数据生成器 生成了试验的数据集。
1、介绍
近年来,随着人工智能(AI)的爆发,车载辅助驾驶系统更新了以往的驾驶模式。通过获取实时路况信息,系统及时提醒驾驶员进行准确操作,从而防止因驾驶员疲劳而发生车祸。除了辅助驾驶系统外,自动驾驶汽车的开发还需要从数字图像中快速准确地检测交通标志。
交通标志识别(TSR)是从数字图像或视频帧中检测交通标志的位置,并给出特定的分类。TSR方法基本上利用了视觉信息,例如交通标志的形状和颜色。然而,传统的TSR算法在实时测试中也存在一些弊端,例如容易受到驾驶条件的限制,包括照明、摄像头角度、障碍物、行驶速度等。实现多目标检测也非常困难,由于识别速度慢,容易遗漏视觉对象。
随着计算机硬件的不断完善,人工神经网络的局限性得到了很好的缓解,使机器学习进入了发展的黄金时期。深度学习是一种机器学习方法。深度神经网络模型在处理信息时模拟我们人脑的神经结构。利用该神经网络模型从道路图像中提取有效特征,远优于传统的TSR算法,具有提高算法鲁棒性和泛化性的潜力。
TSR的研究成果不仅避免了交通事故,保护了驾驶员,还有助于高效准确地检查道路上的交通标志,从而减少了不必要的人力和资源。此外,它还为无人驾驶和辅助驾驶提供技术支持。因此,基于深度学习的研究工作具有巨大的意义,对我们的日常生活具有不可估量的价值。
在本文中,我们主要研究如何实现基于深度学习的准确实时TSR模型。我们的贡献体现在三个方面。首先,我们收集并扩充样本图像,为我们的交通标志形成一个新的数据集。其次,关于最新版本的YOLOv5,我们实现了我们的实验,并基于我们的数据集评估了TSR性能。
2、TSR
TSR一直是近年来的研究热点。为此,研究了TSR对复杂图像场景中的交通标志区域和非交通标志区域的检测,TSR提取了通过交通标志模式表示的特定特征。现有的TSR方法基本上分为两类:一类是基于传统方法,另一类是与深度学习方法有关。
基于给定图像的颜色和形状的TSR方法的主要步骤是提取候选区域中包含的视觉信息,捕获和分割图像中的交通标志,并通过图案分类正确标记标志。尽管 TSR 需要颜色和形状信息,但用于提高识别准确性。交通标志的照度变化或褪色问题,以及交通标志的变形和遮挡,仍是未解决的问题。传统的机器学习方法通常选择指定的视觉特征,并利用这些特征对交通标志的类别进行分类。具体特征包括类似 Haar 的特征、HOG 特征、SIFT 特征等。
传统的TSR方法基于模板匹配,需要提取和利用交通标志的不变和相似视觉特征,运行匹配算法进行模式分类。这些方法的特征表示需要很好地指定,由于交通标志的变化,这是一个很难准确描述视觉特征的问题。
神经网络、贝叶斯分类器、随机森林和支持向量机(SVM)被用作分类器。然而,传统机器学习方法的性能取决于指定的特征,它们容易遗漏关键特征。此外,对于不同的分类器,需要相应的特征描述信息。因此,传统的机器学习方法存在局限性,其实时性相对来说没有可比性。
深度学习利用多层神经网络自动提取和学习视觉对象的特征,在图像处理方面具有重要意义。CNN 模型是 TSR 最流行的深度学习方法之一。TSR算法是基于区域建议的,又称两阶段检测算法,其核心思想是选择性搜索,其优点是检测定位性能好,但代价是计算量大,计算硬件性能高。
CNN 模型封装了 R-CNN、Fast R-CNN 和 Faster R-CNN。Faster R-CNN结合了边界框回归和目标分类,采用端到端的方法检测视觉对象,不仅提高了目标检测的准确性,而且提升了目标识别的速度。道路标志通常是从驾驶员的角度来检测的,在本文中,我们从卫星图像的角度来观察这些标志。在中,对输入图像采用引导图像滤波来去除图像伪影,如雾和雾。将处理后的图像导入到建议的网络中进行模型训练。
视觉目标检测由分类和定位两个任务组成。在YOLO出现之前,这两个任务在视觉对象检测中是不同的。在YOLO模型中,目标检测被简单地转换为回归问题。此外,YOLO遵循用于视觉目标检测的神经网络的端到端结构,通过一个图像输入同时获得预测边界框的坐标、目标的置信度和目标所属类别的概率。
3、方法论
YOLO系列机型已更新至YOLOv5。视觉目标检测的准确性不断更新;回归始终被采用为核心思想。在本实验中,我们以最新版本的 YOLOv5 作为 NZ-TSR 模型之一。YOLOv5 算法的结构与 YOLOv4 非常相似。整个网络模型分为输入层、骨干层、颈部和预测层四个部分。在图中详细介绍了 YOLOv5 的网络结构。
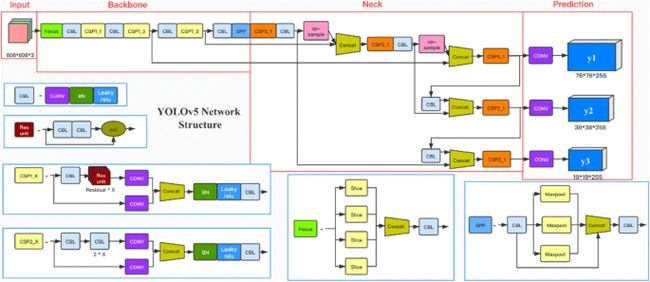
图1
在输入部分,YOLOv5 和 YOLOv4 都利用马赛克方法来增强输入数据。该算法需要将输入图像归一化为固定大小,图像的标准大小为 608 × 608 × 3。此外,网络训练基于初始锚定框,通过与实际注释框进行比对,并迭代更新网络模型参数,得到预测框。
骨干部分包含焦点模块和CSP模块。对焦模型的关键步骤是通过切片操作压缩输入图像的高度和宽度。对图像进行拼接,将图像尺寸信息(即宽度和高度)整合到通道信息中,以增加输入通道。在CSP模块方面,YOLOv5设计了CSP模块的两个分支,分别是CSP1_X和CSP2_X。其中,CSP1_X模块主要用于骨干网,CSP2_X主要用于颈部网络。
YOLOv5 中的颈部部分模仿 YOLOv4,采用 FPN+PAN 结构。特征金字塔网络(FPN)从上到下工作,利用上采样操作来传输和融合信息,以获得预测的特征图。相比之下,PAN(路径聚合网络)是一个从下到上的特征金字塔。
4、实验
数据采集
本实验选取了多类具有较高认知度、重要安全意义的交通标志。由于真实数据的采集的成本高昂,且采集难度大耗时较长。在本文中,将使用UnrealSynth虚幻合成数据生成器 来生成训练所需要的数据集,用户只需要将在UnrealSynth虚幻合成数据生成器中搭建虚拟场景,经过对虚拟场景的简单配置就可以自动生成YOLO模型训练数据集,非常的简单方便:
1. 场景准备
- 将模型导入到场景。
- 配置场景先关参数,如:生成的图片数据集的图片分辨率、生成的图片的数量等。



2. 生成数据集
设置参数后,点击【确定】后会在本地目录中...\UnrealSynth\Windows\UnrealSynth\Content\UserData 生成本地合成数据集,本地数据包含两个文件夹以及一个 yaml 文件:images、labels、test.yaml 文件;images中存放着生成的图片数据集,labels中存放着生成的标注数据集。

images和labels目录下各有两个目录:train 和 val,train 目录表示训练数据目录,val 表示验证数据目录,标注数据的格式如下所示:
0 0.68724 0.458796 0.024479 0.039815
0 0.511719 0.504167 0.021354 0.034259
0 0.550781 0.596759 0.039062 0.04537
0 0.549219 0.368519 0.023438 0.044444
0 0.47526 0.504167 0.009896 0.030556
0 0.470313 0.69537 0.027083 0.035185
0 0.570052 0.499074 0.016146 0.040741
0 0.413542 0.344444 0.022917 0.037037
0 0.613802 0.562037 0.015104 0.027778
0 0.477344 0.569444 0.017188 0.016667synth.yaml是数据的配置文件,数据格式如下:
path:
train: images
val: images
test:
names:
0: traffic sign4,4 实验结果
YOLOv5模型在结果中具有出色的可视化功能。首先,我们直观地显示其数据集的最终识别结果,如图5图4、我们清楚地观察到 YOLOv5 实验中的 TSR 非常准确。

图4
最后,YOLOv5 在数据集中的所有具体评估指标如图5所示, 特别是,第二列和第三列分别是用于视觉目标检测和分类的训练数据集和验证数据集的损失函数的平均值。该值越小,模型的识别性能越好。
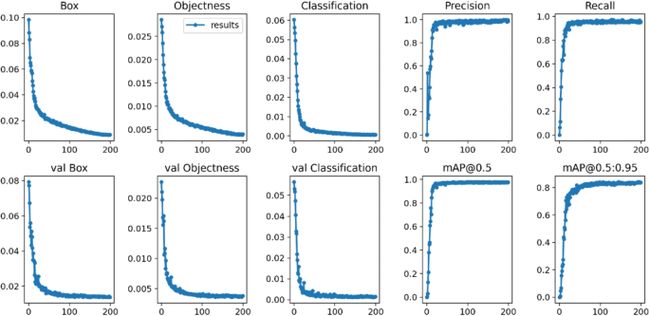
图5
通常,评估实验结果最方便、最直接的方法是准确性。在本文中,我们利用PR曲线来证明模型TSR性能的准确率和召回率之间的权衡。
5 结论和今后的工作
本项目旨在基于交通标志数据集,探究TSR的准确性和速度。因此,本文选择了YOLO系列算法的最新版本,即YOLOv5,来评估其性能。在这个实验中,我们使用UnrealSynth虚幻合成数据生成器 ,通过搭建虚拟场景的方式,生成了交通标志的数据集。然后,我们基于具有非常强计算能力的Google Colab平台实现了精心设计的实验。从实验结果来看,YOLOv5在所有类中的准确率均高达97.70%,各类的平均精度均在90.00%以上。
未来,我们将继续扩展我们的数据集,以涵盖所有类别的交通标志。同时,将包括更多新开发的视觉对象识别模型,如Mask R-CNN、CapsNet和Siamese神经网络。胶囊神经网络(CapsNet)已被用于有效识别一类具有空间关系的交通标志。
转载:基于机器深度学习的交通标志目标识别 (mvrlink.com)