论文阅读_AI生成检测_Ghostbuster
英文名称: Ghostbuster: Detecting Text Ghostwritten by Large Language Models
中文名称: 捉鬼人:检测大语言模型生成的文本
文章: http://arxiv.org/abs/2305.15047
代码: https://github.com/vivek3141/ghostbuster
作者: Vivek Verma,Eve Fleisig,Nicholas Tomlin,Dan Klein
日期: 2023-11-13
1 摘要
提出了 Ghostbuster,一种用于检测 AI 生成文本的最先进系统。该方法将文档通过一系列较弱的语言模型,对其特征的可能组合进行结构化搜索,然后训练一个分类器来预测文档是否为 AI 生成的。对于检测黑盒模型或未知模型生成的文本非常有用。并发布了三个新的数据集,可作为学生论文、创意写作和新闻文章领域的检测基准。
2 读后感
通过文章分析,可以看到人工文件与生成文本的主要差异,检测时主要的难点,以及自动生成检测的使用场景和注意事项;并且对比了工具和人类的分辨能力。
从方法上看难度不大,主要组合了现有模型,综合了它们的优势,其中比较有巧思的在特征组合和选择的算法设计(缩减向量维度时可作参考);从实验结果和分析中可以看到,不同子方法的重要程度和产生的效果。
3 引言
由于语言模型容易出现事实错误和幻觉,读者可能希望知道是否在新闻文章或其他信息性文本中使用了这样的工具,以决定是否信任来源。
目前已经提出的几种检测框架常会将真实作品错误地标记为 AI 生成的作品;特别是将非英语为母语的文本常被标记为 AI 生成的。
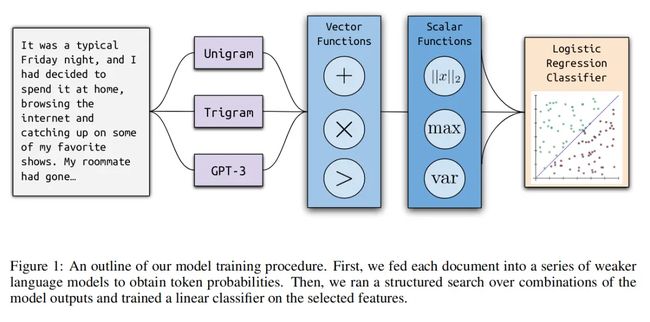
文中提出了 Ghostbuster,将人工撰写和 AI 生成的文档通过一系列较弱的语言模型,从 unigram 模型到未经指导调整的 GPT-3 模型进行处理。给定这些模型的词概率,然后在将这些概率组合成一组特征,可在固定空间中进行搜索。最后,将这些特征输入线性分类器进行分类。
人工智能生成的文本与人类撰写的文本存在质量上的差异,虽然志愿者通常认为 ChatGPT 的回答比人类的更有帮助,但 ChatGPT 的回答仍更正式、更严格,并使用更多的连词。
本文主要关注由语言模型生成整段或整个文档的情况,对有针对性的攻击有待未来实现。
4 数据集
论文收集了三个新的数据集,用于对创意写作、新闻和学生论文的 AI 生成文本检测进行基准测试。
创意写作人工文件基于创作故事的论坛(2022 年 10 月前 50 名发帖者的数据),抓取了每个用户的最后 100 篇帖子;新闻数据集基于路透社数据集,其中包含 50 名记者撰写的 5000 篇新闻文章;学生论文数据集基于IvyPanda 的论文,其中包括高中和大学水平的各个学科的论文。然后收集了与人工撰写文本相对应的 ChatGPT 生成文本,所有的训练数据都使用 gpt-3.5-turbo 生成。
5 模型
Ghostbuster 的主要目标是训练一个具有强大泛化能力的辨别模型,能够适应各种分布变化,包括不同的文本领域、提示和模型。
它使用了两个基准模型,使用困惑度的模型和基于RoBERTa的模型,使用上述语言模型的文档概率的组合特征来对文档进行分类,这种方法比仅使用困惑度的方法具有更大的表达能力,同时对领域变化具有更强的鲁棒性。
Ghostbuster 使用以下三阶段的训练过程:
5.1 概率计算
方法使用了一个 unigram fertility 模型、一个 Kneser-Ney trigram 模型和两个早期的 GPT-3 模型(ada 和 davinci,未引导精调)来获取概率。模型训练细节见附录 B。
5.2 特征选择
算法一用于查找所有可能有用的特征,其中 p 是之前的特征,V 是子模型输出的向量,标量函数 Fs,向量函数 Fv:

标量函数(长度均值等)将向量转换为标量,向量函数(加减乘除等)将两个向量合并为一个。具体的向量和标量函数共 13 个,见表 -9:

将训练文档转换为一系列 token 概率向量,由于文档的长度不同,向量不能直接输入分类模型,这里使用了构造特征再筛选特征的方法,最终产生固定数量的标量来表示文档。
调用算法 1 运行了四次,以生成大量可能的特征。每次以每个模型的概率向量作为起始特征,并设置最大深度为 3。特征的形式是将三个任意的概率向量与向量函数组合起来,然后将它们缩减为标量。
这种方法定义了一个结构化的搜索空间(维数固定),其中只使用了有限的易于解释的特征作为我们分类模型的输入。
5.3 训练分类器
训练逻辑回归分类器,使用 L2 正则化;对概率的组合特征进行训练,还包括基于词长度和最大标记概率的七个附加特征(附录 C)。这些附加特征旨在融入关于 AI 生成文本的定性启发。
6 基线
文中模型是一个线性分类器,根据训练集学习一个阈值参数。此外,还在相同的数据上对一个基于 RoBERTa 的有监督模型进行了微调。
另外,收集了人工注释来验证数据集的难度,并提供一个人类基准线。随机选择了 6 名本科生和博士生,他们之前有使用文本生成模型的经验,要求他们标记这些文档是由人类还是 AI 撰写的。平均人类准确率为 59%(最高 80%,最低 34%)。
7 结果
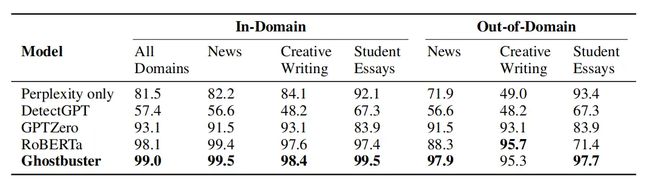
从表 -2 中可以看到 Ghostbuster 在领域内和领域外的评估效果。
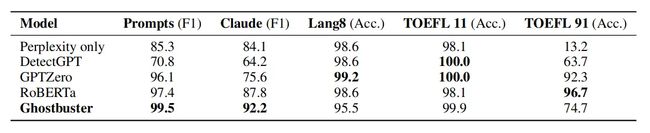
从表 -3 中可以看到,Ghostbuster 性能不受提示策略风格的影响;在 ChatGPT 上训练的模型在 Claude 上效果略下降,但也能达到 92.2;
8 分析
消融实验结果如下:
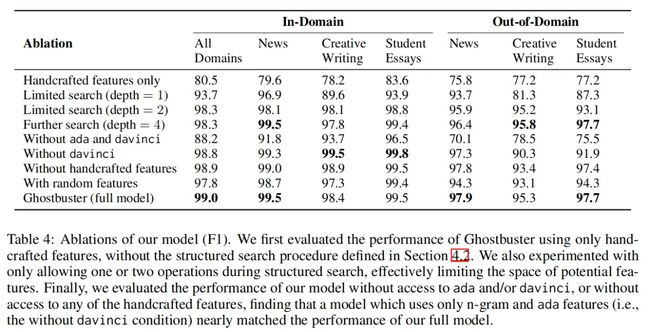
消融实验结果表明结构化搜索和使用神经 LLM 的概率对性能至关重要(领域外更重要);在不同扰动下编辑文章,评测模型鲁棒性(是否可以通过简单地拼写错误或添加无意义的标记来规避检测),发现大多数全局编辑对性能影响不大,而需要大量局部编辑才能欺骗模型;在较短的文档上分析性能时,文章越长效果越好,在超过 100 个 token 的文档上通常更可靠。
9 伦理与限制
Ghostbuster 的错误预测可能特别容易出现在较短的文本、与 Ghostbuster 训练的领域更远的领域(如短信)、英语标准美式或英式以外的英语变体或非英语语言的文本、非英语母语者撰写的文本、由人类编辑或改写的 AI 生成文本,以及通过提示 AI 模型进行改写或调整人类输入生成的文本。
建议在人类监督下谨慎使用 Ghostbuster,不同应用场景下,对检测器的假阳性和假阴性率之间进行权衡。例如,在检测学生论文是否由 AI 生成时,需要优先降低假阳性的风险,以避免错误指控学生行为不端。而在其他场合,假阳性可能不那么严重。例如,检测器用于防止 AI 生成的文本被用于语言模型训练数据,或者标记网络上可能由 AI 生成的内容。