大模型没有自我改进能力?苏黎世理工联合Meta AI提出小模型架构,显著提升大模型表现
前段时间,多位大佬发文指出大模型没有自我改进的能力,甚至自我改进之后,回答质量还会明显下降。


自我改进之所以不奏效,是因为LLM并不能准确判断原答案是否错误以及是否需要改进。
近日,苏黎世理工与Meta AI提出一种改进大模型推理答案的策略——ART: Ask, Refine,and Trust,该方法通过提出必要的问题来决定LLM是否需要改进原始输出,并通过对初步输出和改进输出进行评估确定最终的答案,在两个多步推理任务GSM8K和StrategyQA中,ART相对于之前模型自我改进的方法,提升了约5个百分点。
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
http://hujiaoai.cn
论文标题:
The ART of LLM Refinement: Ask, Refine, and Trust
论文链接:
https://arxiv.org/pdf/2311.07961.pdf
方法
方法速览
整体框架如下图所示,作者分别使用与任务相关的语料训练了两个小模型作为Asker和Truster,其中Asker负责对原始问题与输出提出问题,询问原输出是否已经回答了子问题,如果未正确回答,将流转到一下步改进原输出。第四步使用Truster判断原输出与改进后的输出孰优孰劣,确定最后的结果。
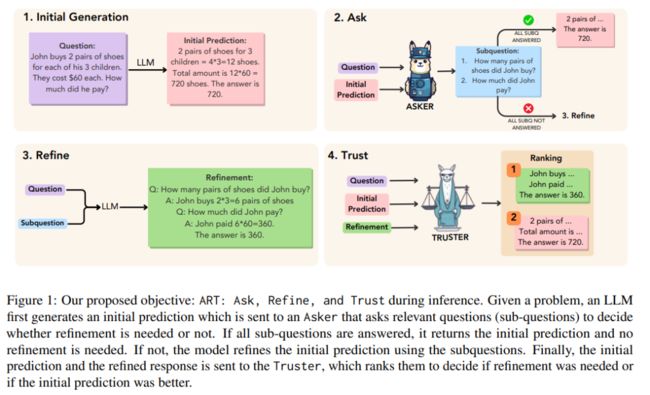
1. 生成初始值
首先使用LLM针对问题生成一个初始预测,在生成初始预测时采用思维链与子问题分解两种方法加强初始预测答案的正确性。
2. Asker
如果对每个样本都进行改进,那么容易误导模型,将更多的正确结果改为错误结果,最终导致模型的性能降低。因此,作者使用任务特定的知识和期望的结果训练了一个小模型作为Asker,判断预测结果是否正确,只对那些Asker不确定的样本进行改进。
那么训练Asker的数据集如何构造呢?具体来说,先使用LLM在训练集的每个样本上生成k个预测。并添加数据集的子问题进行询问,以确认原问题是否得到真正解决,再根据预测是否正确,确认是否需要改进。如下图所示

▲顶部决定改进,底部不需要改进
通过这种方式,Asker学会了首先提出相关的问题,然后将它们映射到预测上,然后决定初始预测是否回答了所有的问题,从而得出是否需要改进的决定。
3. 改进Refine
如果Asker预测结果为“是”(需要改进),则使用LLM根据原输入以及Asker生成的子问题改进原输出,如下图所示:

4. 信任Trust
此时我们拥有两个预测结果:初始输出和改进输出,为了决定哪一个输出作为最终答案,作者训练了一个Truster模型。
由于改进后的答案大概有80%和初步预测的答案是一样的。为了让Truster模型学会识别出最终正确答案的推理链,而不是特定风格的中间推理链。作者使用了和Asker模型相同的训练数据,输入问题为x,并挑选出同时有正确和错误预测的样本构造对比对,损失函数如下所示
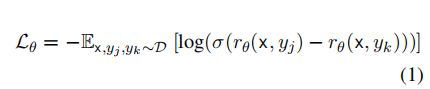
其中,r是"信任者"模型的评分。然后根据每个样本的评分,选择得分最高的预测作为输出。
实验
数据集
数据集包括两个多步推理的任务。GSM8K数据集是一个小学数学应用题数据集,训练集包含7473个样本,测试集包含1319个样本,每个样本需要2到8个步骤才能解决。该数据集还包括与给定正确解的步骤相对应的子问题。
StrategyQA是一个面向开放域问题的问答基准,需要进行推理步骤才能解决。StrategyQA包含2290个训练示例,作者将前20%用作测试集,剩余的80%用作训练。
实验设置
-
首先分别使用GSM8K和StrategyQA数据集上微调LLaMA变体(7B,13B和70B)。
-
然后再使用收集的数据在已经微调后的LLaMA变体基础上,训练Asker模型来提出相关问题并决定何时进行改进。
-
最后,对LLaMA 13B模型进行微调获得Truster模型,在原始输出和改进输出之间选定最终结果。
每个阶段所用的训练数据大小如下表所示:
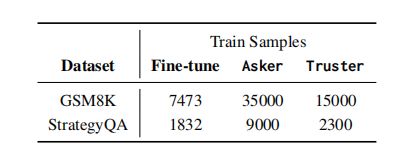
▲每个阶段训练数据的大小比较
实验结果与分析
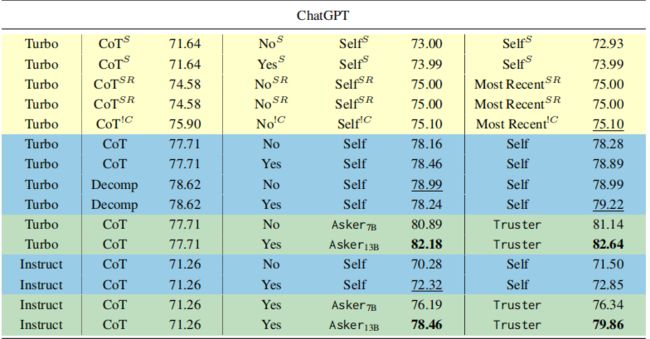
作者分别使用LLaMA 70B(包括预训练和chat版本)、ChatGPT(turbo和instruct)、GPT-4作为基础模型进行比较,实验结果如下图所示。
Initial Prediction指从LLM生成的初始结果,其中的Method是指推理策略包括思维链CoT或子问题分解Decomp。Refinement指的是ART中的Ask和Refine阶段的组合,subquestions代表是否在改进过程中使用子问题。Trust指的是ART中的Trust阶段,其中Self指的是self-refinement,Truster是本文训练的模型,Most Recent指的是选择精化作为最终结果。
黄色是别人工作的结果,蓝色代表作者对基线方法的实现, 绿色代表本文提出的方法。
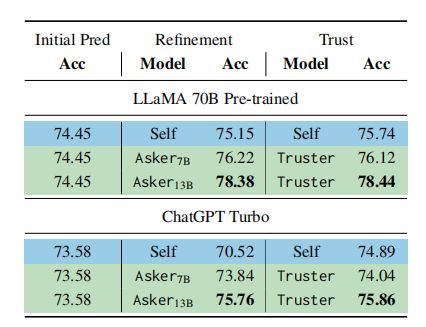
不同方法和改进策略在GSM8K数据集上的准确性:


StrategyQA使用不同模型准确性比较:
1. LLM自我改进能力不足
总体而言,对于GSM8K数据集,LLaMA 70B的性能远低ChatGPT Turbo模型。
此外,在对ChatGPT进行子问题分解(Decomp)时,其性能优于CoT,但在LLaMA 70B中情况正好相反。由于ChatGPT的训练数据和模型架构并不公开,很难理解性能差距的原因。
自我改进(图中的self)在某些情况下能提高性能,但在其他情况下会导致性能下降,而本文将Refinement与Trust模块结合起来,几乎在所有情况下都能稳定提高初始预测的性能。这证明了ART方法的不同组件的实用性。
2.Ask的重要性
GSM8K:
-
当以chatgpt作为基线模型时,与自我优化策略(Self)相比,使用LLaMA 7B训练的Asker 7B模型提高了超过两个点,而Asker13B则将其提高了超过4个点(78.62 → 82.18)。
-
当以LLaMA 70B作为基线模型时趋势类似。拥有Asker模块使得任务准确率有所提升,其表现优于LLaMA 70B的自我优化(Self)能力。
-
对于GPT-4模型,结果同样遵循类似的趋势,其中7B(Asker7B)和13B(Asker13B)模型将初始生成的结果提高了大约2个点(91.88 → 93.72)。
StrategyQA:
-
在StrategyQA上遵循类似的趋势,Asker7B将LLaMA 70B的得分提高了1个点,将ChatGPT的结果提高超过3个点(70.52 → 73.84)。
-
Asker 13B模型的收益更大,其中LLaMA 70B的性能提高了3个点,ChatGPT提高了5个点,这明确地表明了Asker模块对于优化决策制定的重要性。
3. 不要总是相信改进后的结果
如果将改进后的结果全盘接受,那么在某些情况下也会造成性能的损失,此时Truster模块就发挥了它的作用。Truster模块对初始预测和改进输出进行排序,并决定选择哪个作为最终结果,相当于为结果上了一层双保险。
果然,有了Truster模块的加入,在GSM8KS上不论是以LLaMA 70B还是ChatGPT作为基础模型,都提高了约4-7个百分点。对于GPT-4,增益小一些,这可能是由于GPT-4模型初始性能就非常高达到了93.10,但是Truster仍然提高至94.08。
对于StrategyQA而言,Trust模块并没有太大帮助。这可能是因为在不了解真实事实的情况下很难确定原始输出与改进输出的优劣。
4.微调LLMs的成本 vs. 基于ART的成本
由于GSM8K数据集的训练样本可用,可以直接对LLaMA 70B模型进行微调。微调后的LLaMA 70B在GSM8K上的正确率为63.2% 。这与训练ART结果相接近,但ART训练成本和计算要求要低得多。
如下表显示,Truster使用13B模型训练,而Asker使用7B模型,与直接微调70B模型花费时间更少。此外,直接微调通常使模型过度拟合与训练数据集,降低了在上下文学习中的通用性,而ART框架避免了这个问题。
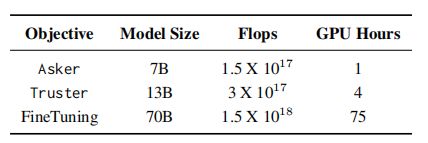
▲比较在GSM8K上训练不同大小的LLaMA模型所需成本
结论与限制
本文提出了一种改进策略,称为ART: Ask, Refine, and Trust, 使用较小的模型训练的Asker模型决定是否改进,而Trust确定是否采纳改进后的答案。结果表明,精心训练的小模型可以胜过大模型的自我改进能力。
但是本文仍然存在一些限制:
-
本文使用了GSM8K和StrategyQA数据集的训练数据来训练Asker。对于许多任务来说,可能无法获取训练数据。虽然可以使用LLMs生成数据,并且在许多情况下,其性能与真实数据相近。但本文并未测试生成的训练数据是否有效。
-
此外,对于StrategyQA,作者在改进预测时使用了数据集提供的可用的事实来支持模型决策。但在现实世界中可能需要借助某些工具或从某些数据库中提取。作者也没有在ART框架中测试过此方法是否可行。
-
ART框架虽然有效,但分步骤训练Asker与Trust比较麻烦。作者还测试了一次性完成全流程的效果,发现性能相比分步骤框架ART来说降低了。
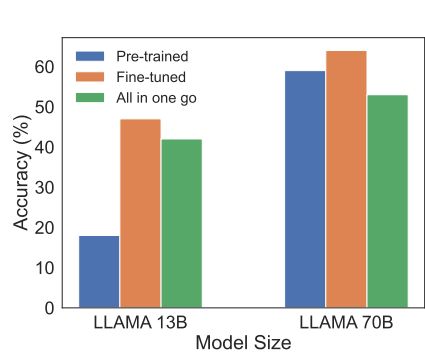
这表明对于LLM来说一次性生成整个环节仍然存在挑战,期待未来有效果拔群的端到端的工作出现~

