jvm事故排查--cpu利用率高问题处理
事故说明
不知道从什么时候开始,我的服务整体都超级慢,一个很简单的查询数据库的接口,从调用到查询,总共耗时13秒+,由于涉及到内网环境、rpc接口调用等情况,一直无法精准定位。
系统环境分布:
系统分为nginx + 应用网关 + 应用服务 + tidb数据库 + redis缓存 + nacos
调用链:
-
由浏览器发起请求,调用到nginx。
-
由nginx将请求转发到应用网关
-
网关经过几个拦截器的处理之后,将请求路由到后端服务
-
后端服务通过拦截器,进行认证
-
认证期间,通过nacos调用rpc接口来进行身份识别,期间用到缓存来辅助认证
-
识别后再经过几个拦截器处理,然后调用到实际的http接口
-
接口进行简单的参数校验,然后调用service层(spring 容器内调用)
-
service层什么都没做,将请求转发到innerService中(spring 容器内调用)
-
innerService查询数据库
-
查询数据库之前,经过四五个拦截器,预处理sql
-
处理完之后,真正调用数据库进行查询
-
查询到的结果,进行模型转换
-
转换后的结果返回
经过上述的调用之后,总共耗时十几秒。这就是现象。
问题分析思路
可能问题点定位
根据调用链,分析可能发生问题的点
- 由于网络问题,导致调用nginx时,数据转发很慢(在外部通过调用内网)
- 拦截器太多,导致速度太慢
- nacos配置有问题,导致rpc接口调用非常慢
- 数据库执行很慢
- 缓存执行很慢
- 类型转换器导致的很慢
列出来可能出现的问题,先尝试修复一波
尝试修复问题
先把比较容易修复的给修复一下
- 数据库执行很慢
打印sql执行耗时
- 缓存执行很慢
打印接口执行耗时
- 类型转换器很慢
更换mapstruct进行类型转换(编译期的所以效率很高)
- 拦截器很慢
在方法的入口处打印时间
上面这些前置工作做好,就可以开始进行问题排查定位了。
首先各种日志打印,本地连接远程debug,调用接口进行调试。
定位耗时根因
通过数据库执行耗时日志,发现数据库执行只需要3-5毫秒,非常快的,不需要关注这点了,那就关注流程问题。
远程debug时,每一层进入的都特别慢,由于网络原因,也会导致这种情况,所以就放弃了远程debug,而是在每一层都打印出来日志。
最终打印的效果就是这样的。
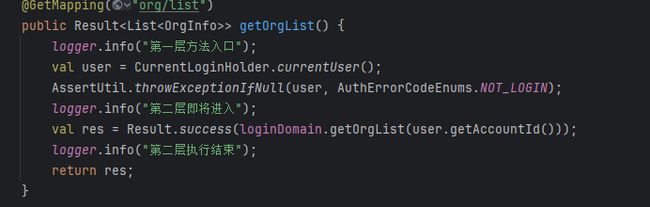
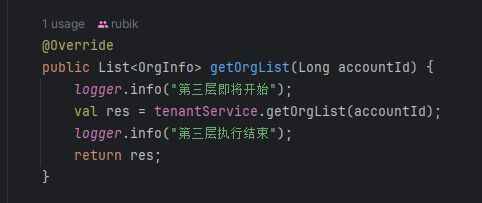
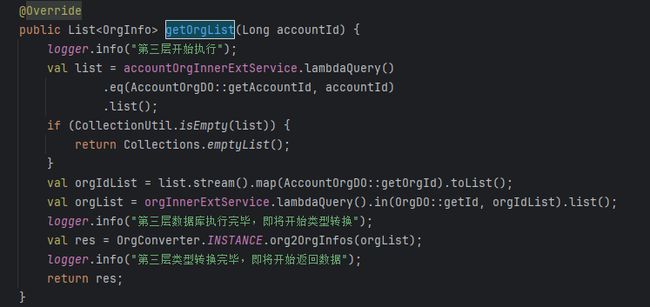
通过这个日志,得到的结果是:

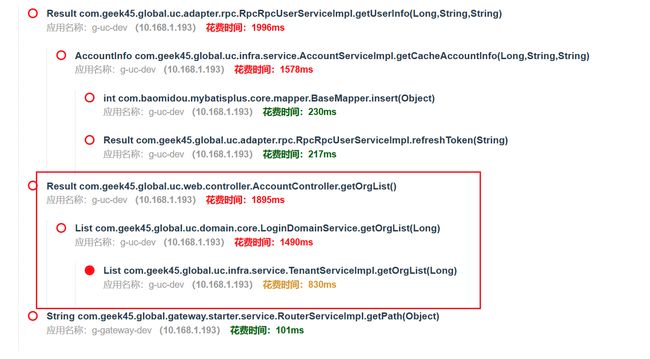
暂且不去考虑rpc接口的损耗,通过这点,可以发现这里肯定存在问题,不要太执着于难啃的骨头,由简入繁,或许问题就能迎刃而解了。
通过日志进行分析,发现每一层的调用,都耗时400毫秒左右,这是非常不健康的,容器内的调用,不应该如此耗时。
一定是有什么东西,导致容器在查找bean对象时非常缓慢。
这个地方已经没有什么可以继续排查下去的必要了,再继续深究,就是框架的问题,这种发生问题的概率很小,不要急着找别人的问题,从自身下手。
根据现象,我想到的就是由于jvm容器问题,导致框架在找bean对象时,非常的慢,所以每一层的调用才会耗时这么久。
因为spring 容器的bean对象都是在内存中,所以我第一反应就是认为jvm调优导致的,堆栈大小不合理。
接着我用性能分析工具,来分析jvm应用。
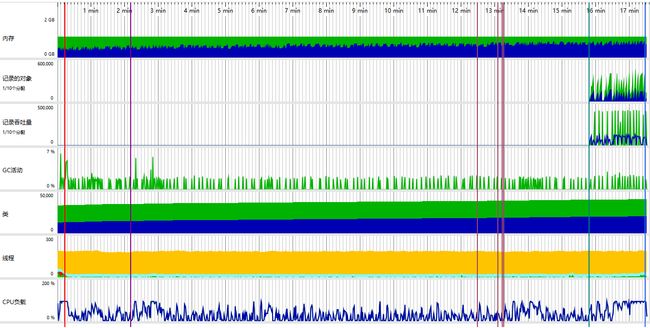
通过这个性能图,发现内存、gc、线程等都还好,数据常规的。
猛地一看,CPU也是正常的,但是仔细看一下会发现,CPU负载的图,左边的图峰值在200,但是jvm最高的峰值是100。那就是这张图最大的才能到中间。
单独打开cpu这块的详细图来看。

通过这个就很能发现问题了,在我调用接口的期间,CPU持续100%不下,导致cpu持续顶点消耗。
在这种情况下,应用几乎是跑不动的情况。
但是我的服务,根本就没有什么特别消耗计算的东西,不应该会这么消耗cpu的。
所以我就看是不是由于docker容器的问题,发现docker容器启动的时候,使用的默认1个cpu,所以我就调整了启动参数,给docker容器分配了4个cpu来启动。
docker run --cpus=4
这样启动之后,这次就关注docker的cpu使用就行了。
docker stats
再次调用接口,容器的cpu使用率依然暴涨在300 - 400之间,看来这个并不能解决问题,而且发现这块使用率是真实存在的,并不是调大就行了。问题的核心点应该去关注为什么会这么高,而不是用扩大来屏蔽问题。
换了思路之后,我就开始定位高的原因。
通过top -C 来查看系统的进程cpu使用率。 Shift + P 通过cpu利用率进行排序
找到最消耗cpu的进程,然后通过 top -Hp {pid} 来查看该进程比较消耗cpu的线程。 同样通过 Shift + P 通过cpu利用率进行排序
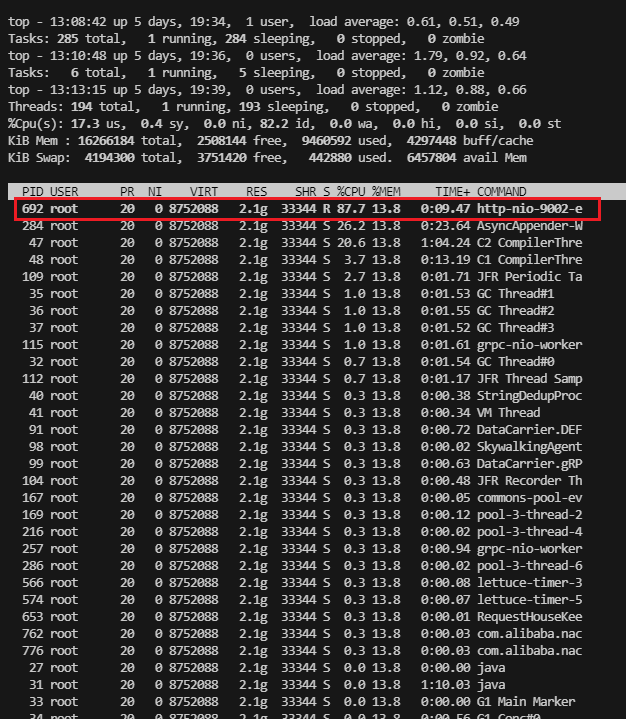
当我调用接口时,这个进程的cpu利用率就很高,飙升到了将近90%,还在持续走高。
定位到这个线程的pid是692,通过进制转换,将该十进制转为十六进制。转换后为 2b4
通过jps,找到java应用的pid

通过jstack -l 27 > /27.stack 来将线程快照导出
通过快照,找到刚才cpu占用最高的线程,看看它在干嘛。
cat /27.stack | grep ‘2b4’ -C 100
查看该线程的信息。通过名字,找到相同的。
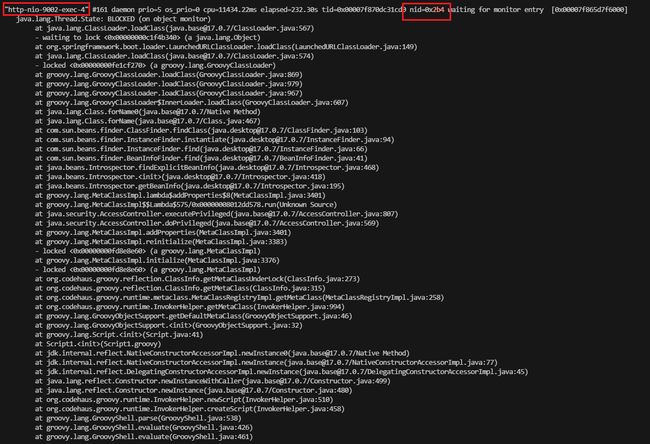
定位到就是这个线程占用cpu特别高,看下它的堆栈信息,看看它当时在干嘛。
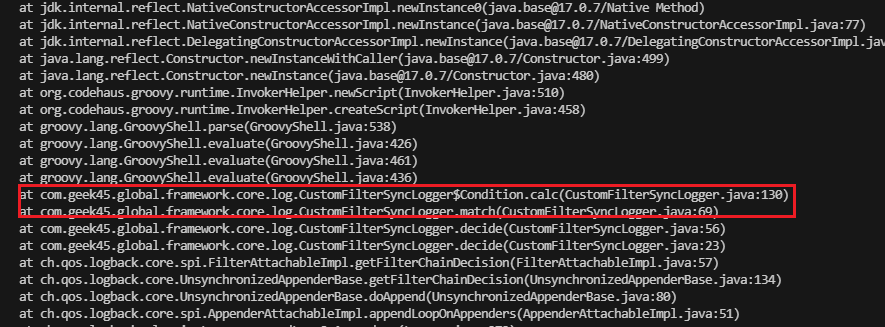
通过这个,发现它执行了一个拦截器,是一个日志拦截器。
这个拦截器已经非常久远了,忘记它的存在了,也不知道它是干嘛的,于是通过堆栈,进去看看这个方法都做了什么。

发现这个方法,是通过guava的计算引擎来计算一个规则。
这个拦截器是用在logback上面的一个拦截器,当每一次需要打印日志的时候,都会调用到这个方法,不管是否真的打印出,但会调用这个计算一下,框架内部很多debug的日志输出,都要调用这个。
所以CPU突然的飙升,是由于有逻辑执行时,疯狂的调用这个来计算,导致的CPU资源被占满。
解决问题
问题验证
定位到问题了,先来验证一下这个问题。
通过logback的配置,将这个拦截器给移除掉,然后重新部署项目,看下效果。
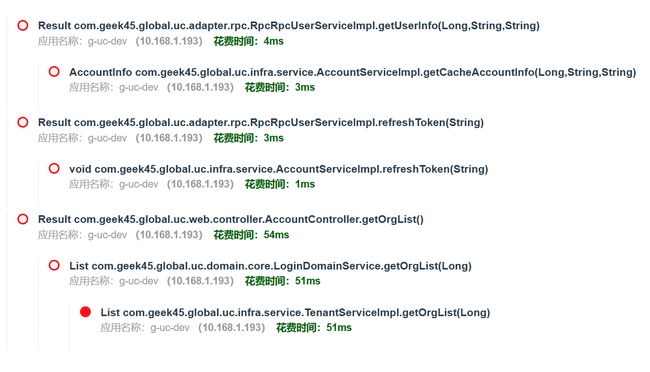
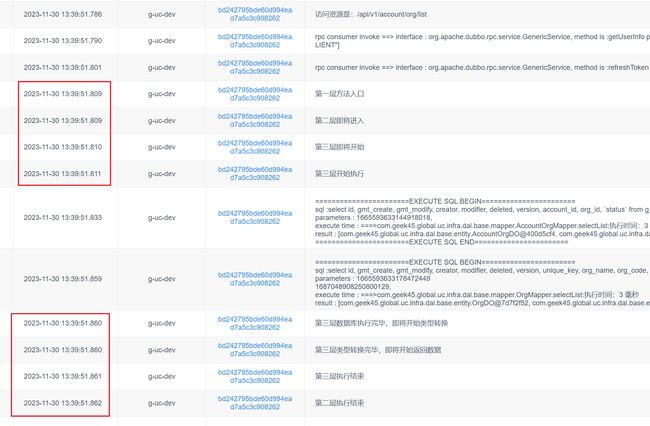
通过这里,基本可以确定,这块已经非常快了,问题已经解决了。

原本十几秒的调用,现在也只需要669毫秒。
问题解决
问题已经验证了,确实是这块导致的,所以现在来解决下这个问题。拦截器还是需要,不过需要换一种实现方式
既然这块的触发频率这么高,那就不能消耗cpu资源无休止的去计算,或者是不应该用计算引擎这么高消耗的组件来计算。
看这块逻辑,计算实际非常简单,只是一个简单的比较而已,那就换一个简单的实现方式。
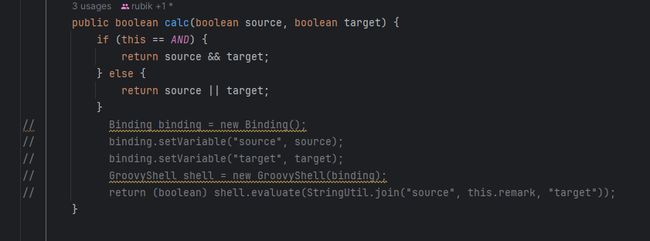
只是一个简单的 and or的计算,没必要用计算引擎,简单的判断,做一个计算就行了。
简单的东西复杂化,反而会导致性能的缺失,得不偿失。
改完之后上线测一下

十分正常