【Linux】进程地址空间
文章目录
- 1. 什么是进程地址空间(what)
- 2. 为什么要有进程地址空间(why)
- 3. 进程地址空间是怎么处理的(how)
1. 什么是进程地址空间(what)
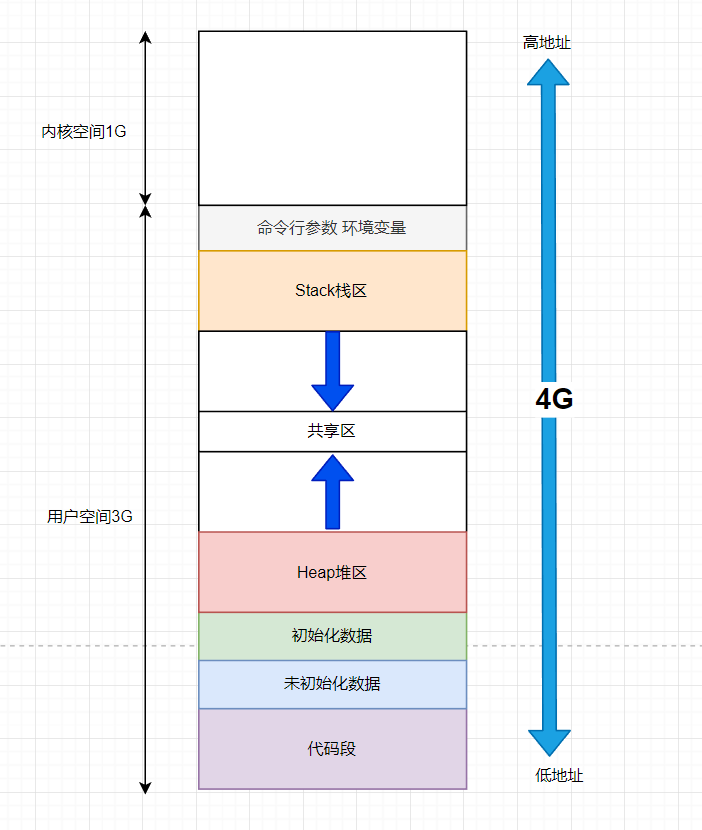
在我们之前的博文中,画过很多次这个图,我们当时说的是内存中的分布情况,但是实际上它并不是所谓内存上的东西,它有一个自己的名字叫做进程地址空间。
首先来一段代码感受一下:
#include 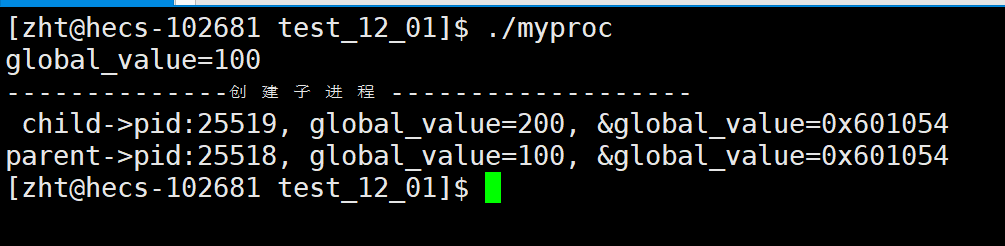
可以看到首先打印的是创建子进程前的global_value的值是100,没有问题,然后创建子进程后,父进程sleep,子进程将global_value修改成200然后打印,3秒后父进程打印global_value,这里父子进程的global_value的值不一样,为什么呢?这个原因我们可以用进程的独立性来解释。再往后看,父子进程的global_value的地址是相同的!!!
但是多进程在读取同一个地址的时候怎么可能出现不同的结果,这个现象说明了这里的地址并不是真正的地址
这里的地址是虚拟地址(线性地址),在Linux内也叫逻辑地址
实际上,操作系统为每一个进程都创建了一个虚拟的进程地址空间,然后通过页表结构将虚拟进程地址空间和物理内存联系起来(映射)。我们在使用内存的时候,获取到的地址只能是虚拟地址,当在访问虚拟地址的时候,操作系统会根据虚拟地址通过页表找到对应的物理内存,从而获取到对应的数据
那么现在就可以解释为什么上面父子进程访问相同地址的时候,访问到的数据内容不一样了,子进程和父进程都拥有自己的单独的进程地址空间, 他们访问的是各自的虚拟地址。
在创建子进程的时候,操作系统会为子进程拷贝父进程的进程地址空间,因此在fork结束之后父子进程的global_value的物理地址是同一个,然后当子进程想要对他的global_value进行修改的时候,操作系统通过虚拟地址找到了对应的物理地址,发现是被两个进程同时使用的,此时为了保证进程的独立性,就会在物理内存中另开辟一块空间,将进程地址空间的内容拷贝到新空间内,再修改对应的页表映射关系,最后再修改新空间的global_value对应物理地址的值。这种在复制过程不真正拷贝,在进行修改的时候才进行拷贝的方式叫做写时拷贝。关于写时拷贝,在之前的博文中有过讲解:
在VS和g++下的string结构的区别vs中string 这篇文中讲了g++中的string使用的写时拷贝技术,大家有兴趣的可以看一看
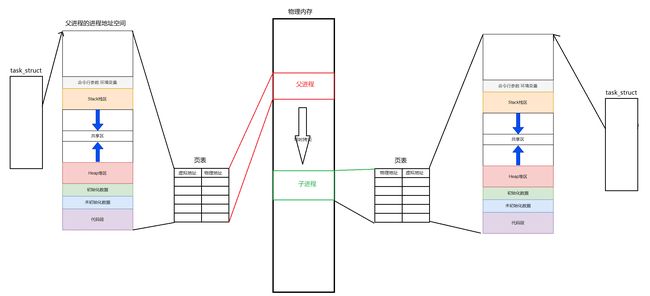
在上文中,我们提到了很多线性地址、虚拟地址、逻辑地址的概念,那么他们有什么区别呢?
在线性地址、虚拟地址和逻辑地址中,线性地址和虚拟地址属于操作系统的概念,而逻辑地址属于程序的概念。它们之间的关系如下:
逻辑地址:是由一个程序发出的地址,它由程序员或编译器定义,用于访问程序中的数据或指令。逻辑地址是相对于进程自身的地址,因此它在不同的进程中可能有不同的值。
虚拟地址:是操作系统为每个进程单独分配的地址,它允许每个进程有自己的地址空间,而不会影响其他进程。虚拟地址是相对于进程而言的,并不是实际的物理地址,需要再通过地址映射才能转换为物理地址。
线性地址:是CPU生成的地址,它是虚拟地址经过分段机制和分页机制所转化而成的地址,即逻辑地址通过分段机制后形成的虚拟地址再通过分页机制后形成的地址。
简单来说,逻辑地址是程序自身生成的地址,虚拟地址是操作系统为程序生成的地址,而线性地址是最终的物理地址。操作系统需要将虚拟地址转化为线性地址,并最终映射到物理地址以进行访问。
2. 为什么要有进程地址空间(why)
上文我们了解了进程地址空间,那么为什么要搞出来这样一个概念呢?
- 进程地址空间保证了数据的安全
OS给每个进程都分配了一块进程地址空间,所有的进程都要通过虚拟地址经过页表的映射找到对应的物理地址,页表内只会存放合法的物理地址,一旦出现了越界访问等操作,在页表这一层就会直接进行拦截,不会出现物理内存上的越界访问的问题。(还记得我们之前说过的内存泄露的概念吗,当时我们说一个程序运行完毕之后,就算没有回收内存也没关系,操作系统会自动回收,其实就是在这里将进程地址空间和物理内存的映射关系断开)
- 地址空间的存在保证了进程的独立性
每一个进程都有独立的虚拟地址空间及页表,通过页表映射到不同的物理内存上,所以一个进程数据的改变不会影响到另一个进程,保证了进程的独立性,而对于上面我们所说的父进程和子进程而言,子进程的地址空间从父进程拷贝,页表都指向同一块物理内存,但是即使此时的数据是共享的,在修改数据的时候也会发生我们所说的写时拷贝,保证了进程的独立性
- 让进程以统一的视角,看待进程对应的代码和数据各个区域,方便编译器也以统一的视角来进行编译代码
可执行程序被编译器编译的时候每个代码和数据在内存中已经有逻辑地址了,也就是说,地址空间对于操作系统和编译器都是遵守的。所以当程序被加载到内存成为进程后,每个变量/函数都具备了物理地址。
所以现在有两套地址:1.标识物理内存中代码和数据的地址 2.在程序内部互相跳转的时候的虚拟地址
加载完成之后,代码的各个区域的地址已经知道。进程被调度时,CPU拿到虚拟地址,经过地址空间查页表通过映射,进行访问查到物理地址往后执行。也就是CPU通过了虚拟地址——页表映射——物理地址执行。也就是在整个CPU运行过程中,CPU并没有见到物理地址,用的都是虚拟地址
3. 进程地址空间是怎么处理的(how)
根据上文中的知识,我们知道:OS会为每一个进程创建一个进程地址空间;但是OS内部存在着很多进程,所以为了保证这些进程都能够正常运行,OS需要将这些进程进行管理。
那么如何管理呢?看过博主之前文章的童鞋们应该能够轻松拿捏这个问题:管理的本质就是先描述,再组织。
所以首先对这个进程地址空间进行描述,我们可以把进程地址空间抽象成一个线性的数组,然后通过描述每一块的起始地址和结束地址来维护一这块空间。也就是下图的这种形式
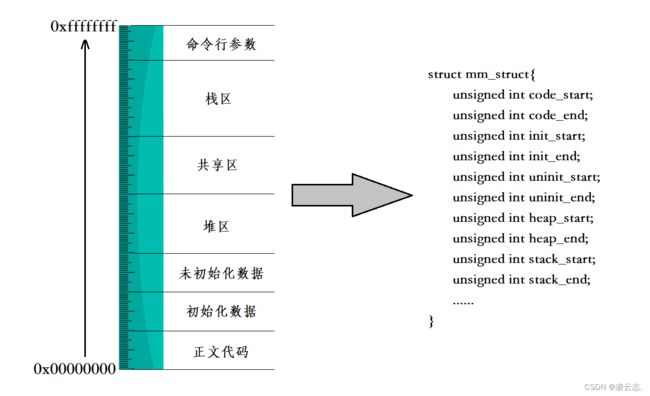
在Linux源码里面我们能够找到一个叫做mm_struct的结构体,这个结构体就是用来描述进程地址空间的结构体。先描述
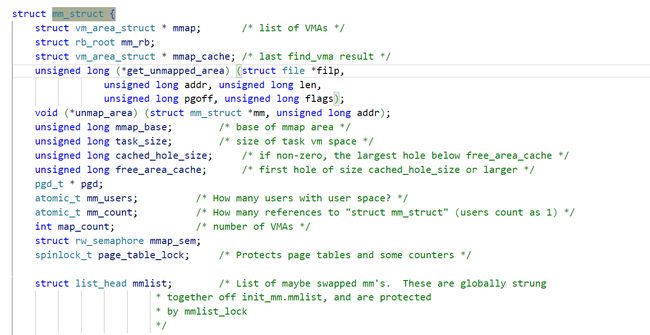
同时,在我们之前提到的进程的描述结构体task_struct中能够找到一个mm_struct类型的指针mm,用于管理这个进程地址空间。再组织
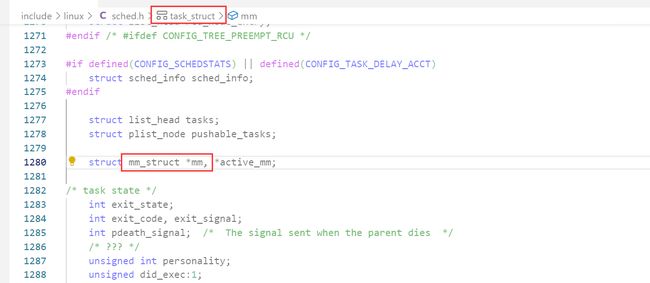
每个进程被创建时,其对应的进程控制块(task_struct)和进程地址空间(mm_struct)也会随之被创建。而操作系统可以通过进程的task_struct找到其mm_struct。根据上文中提到的进程地址空间的描述模型,我们想要调整其中每一块的大小,本质上,调整task_struct->mm指向的相应的块的起始和结束的数值即可。
补充:今天讲的进程地址空间其实只将了一部分,其中还有很多比较复杂的细节我们没有涉及,比如页表分级、缺页、命中等等,这部分内容我们会在后面学习文件系统以及多线程的时候慢慢补充。
本节完…