Explainable Multimodal Emotion Reasoning 多模态可解释性的情感推理
1.摘要
多模态情感识别是人工智能领域的一个活跃的研究课题。它的主要目标是整合多种模态(如听觉、视觉和词汇线索)来识别人类的情绪状态。目前的工作通常假设基准数据集的准确情感标签,并专注于开发更有效的架构。但由于情感固有的主观性,现有数据集往往缺乏高标注一致性,导致潜在的不准确标签。因此,建立在这些数据集上的模型可能难以满足实际应用的需求。为了解决这个问题,提高情感标注的可靠性至关重要。在这篇论文中,我们提出了一个新的任务叫做“可解释的多模态情感推理(EMER)”。与以前主要集中于预测情绪的作品相比,EMER更进一步,为这些预测提供了解释。只要预测情绪背后的推理过程是可信的,预测就被认为是正确的。本文介绍了我们在EMER上的初步工作,其中我们引入了一个基准数据集,建立了基线模型,并定义了评估指标。同时,我们注意到整合多方面能力以应对EMER的必要性。因此,我们提出了影响计算中的第一个多模态大语言模型,称为AffectGPT。我们的目标是解决标签歧义的长期挑战,并为更可靠的技术指明道路。此外,EMER提供了一个机会来评估音频视频文本理解能力的最新多模态LLM。为了便于进一步的研究,我们将代码和数据发布在:https://github . com/zero qiaoba/affect GPT
- 多模态情感识别目标:整合多种模态识别人类的情绪状态。
- 论文提出了一个新的任务: 可解释的多模态推理EMER
- 可解释性在于:为预测结果提供了解释
- 提出一个数据集,作为基准
- 情感计算的第一个大模型AffectGPT
- 目标:解决标签歧义的长期挑战,更可靠的技术发展
2.数据集
该文章提出的数据集是新颖的,其独特之处在于:
每个标注者从四个方面标注情感线索:
1)面部表情和肢体动作;
2)声调和语调;
3)演讲内容;
4)视频内容、环境和其他线索。
线索总结:对于每个样本,三个注释者从四个方面提供线索。为了总结所有线索,我们利用chat GPT并使用图1中的提示。但是,我们仍然在生成的结果中观察到一些重复的表达式。因此,我们手动检查并优化输出。
目的:使用gpt的智能性对线索进行总结。
一段视频的多段描述如下。请将这些描述总结如下:
1.请将“线索描述”的多个段落的主语统一为“他”
2 .请将“线索描述”的多个段落进行总结,删除重复的单词、短语或句子,并用完整的句子描述最终结果
3 .检查标点符号
情感总结:在这一步中,我们使用ChatGPT从汇总的线索中推断情绪状态,因为这一策略比MER2023中的原始标签提供了更微妙的情绪。然而,我们在输出中观察到一些不可靠的情绪。为了解决这个问题,我们使用few-shot
ChatGPT进行情感摘要。提示如图2所示。
请总结一下这个人的情绪状态:投入:
他看起来很开心,其实很焦虑。
输出:焦虑
线索和情感的结合:我们把情绪和线索组合成一个段落:在这些“线索”的辅助下,我们可以推断出人物的情绪状态为“情绪”。然后,我们人工评估这个推理过程的合理性,得到最终的描述。


总结:

可解释型多模态情感推理==(线索+情感——>预测情感)
什么是可解释性:
我在这里的理解就是,我有一个很合理的证据去推断出当前的情感。这个证据就是线索和情感。线索是关键信息的提炼,情感是关键信息表征的情感内涵的提炼。这两个因素很大程度上能够指向一个合理的情感,且这个过程是人工可以评估的,那么我的情感预测就是可解释的。
3.任务解决思路
直接方法:使用多模态逻辑线性模型,因为这些模型能够处理各种多模态理解任务。
由于情绪感知依赖于时间信息,我们只选择支持视频输入的多模态LLM,包括VideoChat [9]、Video-ChatGPT [13]、Video-LLaMA [10]、PandaGPT [11]和Valley [14]
多模态LLM背后的基本思想:将其他模态的预训练模型与文本LLM对齐。在对指令数据集进行微调后,这些模型表现出理解指令和多模态输入的非凡能力
例如,VideoChat和Video-LLaMA使用BLIP-2[15]中的Q-Former将可视查询映射到文本嵌入空间。
PandaGPT使用image bind[16]来学习六种模态之间的对齐。
Video-ChatGPT和Valley exploit CLIP[17]来获得文本对齐的视觉特征。
PandaGPT和Video-LLaMA还支持音频输入。
为了在视频中集成字幕信息,我们在提示中包含字幕作为附加内容。——即为需要提取线索信息的原料。
相同的提示信息:
Prompt:The subtitle of this video is
.Now answer my question based on what you have heard,seen,and given subtitles.From what clues can we infer the person’s emotional state?Please summarize the clues in a maximum of 100 words. 此视频的字幕为< Subtitle > < Subtitle _ Here > 。现在根据你所听到的、看到的和给的字幕回答我的问题。从哪些线索可以推断出这个人的情绪状态?请用不超过100字的篇幅总结这些线索
4.评价指标
评价指标主要分为自动评价和人工评价两部分。
自动评价:
利用ChatGPT从三个方面评估预测结果:
1)情感相关线索之间的重叠程度;
2)概括的情绪状态之间的重叠程度;
3)推理过程的模态完备性。对于前两个指标,分数范围为0到10,分数越高表示重叠越多
对于这些指标,我们首先使用提示1总结情绪相关的线索(或情绪状态),然后使用提示2计算重叠部分(见图3和图4)。
所谓重叠度的计算即重复词的概率
##Prompt1:请提取与角色情绪状态相关的描述,然后进一步总结这些描述,
输入:{预测}
输出:##
Prompt2:“真实线索”和“预测线索”在下面给出。请计算“真实线索”和“预测线索”的重叠部分。重叠程度越高,返回的分数越高。分数范围从0-10。
真实线索:抬眉、笑脸
预测线索:抬眉
得分:5
真实线索:{ gt _ clue }
预测线索:{ pred _ clue }
得分:
图3:计算情绪相关线索重叠程度的提示。
##Prompt1:请总结此人的情绪状态:
输入:他看起来很开心,但实际上很焦虑。
输出:焦虑
输入:{预测}
输出:
# #Prompt2:下面给出“真实情绪”和“预测情绪”。请计算“真实情绪”和“预测情绪”的重叠程度。重叠程度越高,返回的分数越高。分数范围从0-10。
真实情绪:快乐
预测情绪:快乐
得分:10
真实情绪:{ gt _ emo }
预测情绪:{ pred _ emo }
得分:
图4:计算情绪状态重叠程度的提示
与此同时,能够从更多模态推断情绪的模型应该得到更高的分数。
因此,我们使用图5中的提示来评估推理过程的完整性。
推理过程的完整性展示:
从那种模态——什么内容——推断出什么情感
请总结输入内容涵盖了多少种模式。您可以从['音频','视觉','内容']:
输入:他看起来很开心,音乐让我开心。
输出:视觉,音频
输入:他看起来很开心,音乐让我开心。同时,他对研究人员表示感谢。
输出:视觉、听觉、内容
输入:{预测}
输出:
图5:评估模态完整性的提示。
人工评估:
对预测结果进行人工评估。
对于每个视频,我们雇佣五个注释者来判断推理过程的合理性。注释者有
“完全错误”、“正确(小部分)”、“正确(大部分)”和“完全正确”四种选择。
我们将这些选择映射到从1到4的分数范围内,分数越高表明推理能力越强。



总结评价:当前的一些评价指标基本都是基于自动指标+人工指标的标准,人工指标多结合认为特别设计,而自动指标常常为该领域的常用指标。
5.AffectGPT
使用初始EMER数据集来训练音频-视频-文本对齐的多模态LLM,称为AffectGPT。
模型:主要框架来自Video-LLaMA,并做了一些修改
修改:
(1)视频-LLaMA分别训练音频和视频分支。我们修改它以支持音频-视频-文本对齐训练。
(2)在Video-LLaMA中,不同指令数据集的输入输出格式不一致。因此,我们统一了输入和输出格式。
代码:https://github . com/zero qiaoba/affect GPT。
数据集处理:一些初步的实验来测试不同样本选择策略的影响
1.训练测试随机划分:80个:20个
2.训练集+Video-LLaMA三个指令数据集结合【训练集扩充】
3.指令微调——模型:gt-eng-remove-test【微调】
4.去除短样本(小于2s)——模型:gt-eng-remove-test remove-short【清洗】
5.训练期间合并训练集和测试集——gt-eng【所有数据训练,测试上限性能】
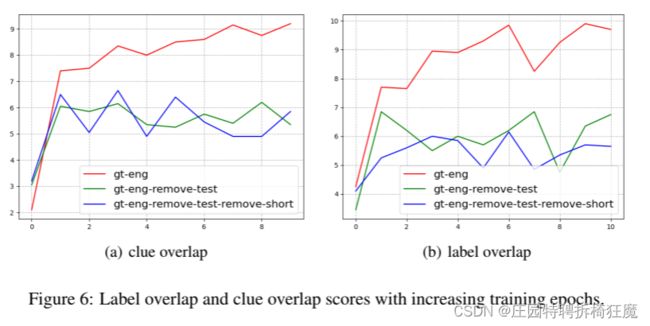
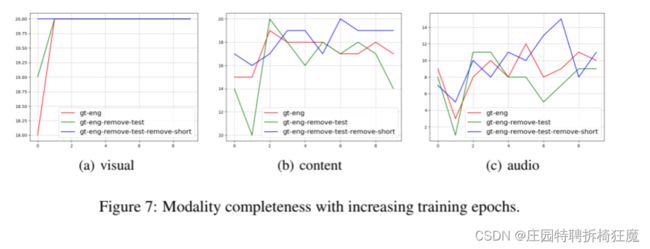
重叠性与性能展示:
总结:
EMER数据集指令微调能够给情感推理带来性能改善——原因很明显,因为EMER数据集是一个情感相关的数据集。
gt-eng训练完美——原因测试数据集参与训练了,为了测试模型性能上限。
总结:
很少有模型从听觉推断情感,当前LLM多模态更关注视觉通道——看数据集也能看出来听觉信息不多叭
提高多通道理解能力,考虑更多音频指令数据集——模态平衡的操作叭
总结:
gt-eng-remove-test: 没有去除短视频
gt-eng-remove test-remove-short : 去除短视频
去除短视频模态完整性更好——短视频情感相关描述更少,取出后,倾向于更长的描述,覆盖更多的模态。
6.实验结果和讨论
评估不同基线在整个EMER数据集上的性能
视频聊天的两个版本:
文本视频聊天:使用视觉模型将视觉数据转换为文本格式
嵌入式视频聊天:将视觉信息与文本嵌入空间对齐的端到端模型
自动评估:
1.实际和预测差异显著:现有多模态LLM在情感推理中的局限性
2.指标趋势具有相似性:
在所有基准中,VideoChat-Text通常表现最差,而Valley通常表现最佳。值得注意的是,音频基准(如PandaGPT和Video-LLaMA)并没有表现出优异的性能。

人工评估:
人工评价的设计:
尽在20个测试样本进行人工评估
为消除人为误差影响:将ground truth和预测放在一起,打乱评分
结果见表2
总结:
chatGPT和人工评估有一定的相似性: VideoChat-Text 一贯表现最差,而Valley一贯实现最佳表现
指标间存在差异:chatGPT作为参考,主要结论来自人的评价
评估多模态集成效果:
基于chatGPT和人工的相似性,根据线索重叠和情感重叠从基线中选择最佳预测——标记为基线(线索)、基线(情感)
这种策略可以提高情感推理性能,验证了多模型集成的优势。
总结:AffectGPT的性能-表二
AffectGPT在情感推理中得分最高——>AffectGPT(线索)”和“AffectGPT(情感)这两个模型都最好
最好——>在gt-eng-remove-test”和“‘gt-eng-remove-test-remove-short”两种训练集设置中,获取性能最好的模型(最佳预测)。分别被表示为“AffectGPT(线索)”和“AffectGPT(情感)”。
实验结果表明,AffectGPT在情感推理中的得分最高,充分验证了该策略的有效性。

定性分析:
随机选择样本进行可视化展示:
总结:
基线预测都是快乐,但实际标签是愤怒
错误原因:不能理解声音线索(如颤抖的声音和激动的音调)和面部线索(如皱眉)。
Video-LLaMA:错误识别出背景音乐的存在(当根本没有背景音乐时)
Valley和Video-LLaMA的视频描述能力不错——他们成功地识别出一名穿着西装的男子在木窗前对着麦克风说话,尽管这些描述与他的情绪状态无关。
总结:
所有基线只有PandaGPT和Video-ChatGPT准确地将人的情绪状态识别为烦躁。
Video-ChatGPT:错误识别人物正在对着电话说话(当这个人没有拿着电话时)
大多数基线正确地识别出这个人正在喝水,但这种观察与她的情绪状态无关。
原因:即当前的多模态LLM主要是在图像字幕数据集或视频字幕数据集上训练的,这些数据集关注于服装、环境、动作等。,而不是以面部为中心的描述。此外,这些数据集通常忽略多模态信息,从而限制了在这些数据集上训练的多模态LLM的音频-视频-文本理解能力。




7.总结
总结:
提出EMER任务,去做情感多模态。与传统情绪识别不一样,不仅预测情绪状态,还提供了解释。旨在解决:标签歧义问题,提高识别可靠性
为促进研究,构建了初始数据集,开发了基线,并定义评估指标:自动|人工
实验结果证明这项任务有难度——现有技术达不到预期效果。使用AffectGPT整合多方面能力来解决当前问题。EMER成为评估多通道LLM音频-视频-文本理解能力的基础任务。
目标:
降低标注成本,增加数据集大小
设计更有效的基线,改善任务效果
鼓励更多人参与,推进情感计算实际应用
8.读后感
1.作者提出要做可解释的多模态情感推理,为了解决标签歧义和提高可靠性。
2.什么是作者说的可解释多模态情感推理呢? 不仅预测情绪状态还提供解释
3.作者怎么实现即预测情绪又解释的?分两部分:
第一步从现有ground truth中,通过GPT提取线索,然后人工微调重复的生成。然后通过重叠率进行评价。
第二步根据线索,通过GPT提取情感。通过重叠率进行评价。
可解释性==>提线索(重叠率)->提情感(重叠率)
根据情感重叠率,约束情感的提取,且约束线索能够提取更好的情感。
根据线索重叠率,约束线索总是提取出了关键信息。
所以线索总是能支撑情感提取的,即提取的情感的可解释性来自线索,线索是情感预测的解释。
4.实验是怎么做的? 作者实验了很多现有的多模态LLM。
整个流程中第一步和第二步使用两个LLM模型,他们可以是不一样的。
最好的模型,挑选了提取线索最好的模型和提取情感最好的模型的组合,集模型集成的优势。
两步提取都是通过大模型的微调+模板信息提示的模式进行提取的。