C++基础:内存管理和内存排布
文章目录
- 内存分区
-
- 堆、栈、自由存储区、全局/静态存储区和常量存储区
- 堆和栈的区别
- 编译环境差异
-
- 基本数据类型
- 指针类型
- 字符串类型 char[ ]
- 字符串类型 string
- 大端模式和小端模式
- 内存对齐
-
- 内存对齐原则
- 结构体和普通类
- 类的特殊情况
-
- 类对象的内存结构
- 空类
- 虚函数类
- 静态数据成员
- 虚继承
- 多继承虚函数类
运行环境:Win10 + CLion + CMake + MinGW --> 64位程序
内存分区
参考:C/C++内存分配管理
在C++中内存分为5个区,分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
堆、栈、自由存储区、全局/静态存储区和常量存储区
堆:堆是操作系统中的术语,是操作系统所维护的一块特殊内存,用于动态分配内存,C语言使用 malloc 从堆上分配内存,使用 free 释放已分配的对应内存。
栈:在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
自由存储区:自由存储区是C++基于 new / delete 操作符的一个抽象概念,凡是通过new操作符进行内存申请,该内存即为自由存储区。
全局/静态存储区:这块内存是在程序编译的时候就已经分配好的,在程序整个运行期间都存在。例如全局变量,静态变量。
常量存储区:这是一块比较特殊的存储区,他们里面存放的是常量(const),不允许修改。
那么,堆和自由存储区相同吗? ? ? 参考:C++ 自由存储区是否等价于堆
网上很多博客划分自由存储区与堆的分界线就是new/delete与malloc/free。然而,尽管C++标准没有要求,但很多编译器的new/delete都是以malloc/free为基础来实现的。那么请问:借以malloc实现的new,所申请的内存是在堆上还是在自由存储区上?
从技术上来说,堆(heap)是C语言和操作系统的术语。堆是操作系统所维护的一块特殊内存,它提供了动态分配的功能,当运行程序调用malloc()时就会从中分配,稍后调用free可把内存交还。而自由存储是C++中通过new和delete动态分配和释放对象的 抽象概念,通过new来申请的内存区域可称为自由存储区。基本上,所有的C++编译器默认使用堆来实现自由存储,也即是缺省的全局运算符new和delete也许会按照malloc和free的方式来被实现,这时藉由new运算符分配的对象,说它在堆上也对,说它在自由存储区上也正确。但程序员也可以通过重载操作符,改用其他内存来实现自由存储,例如全局变量做的对象池,这时自由存储区就区别于堆了。
结论: 堆是操作系统维护的一块内存,而自由存储是C++中通过new与delete动态分配和释放对象的抽象概念。堆与自由存储区并不等价。
堆和栈的区别
-
分配与释放方式: 栈内存是由编译器自动分配与释放的;堆内存是由程序员手动申请与释放的(malloc/free, new/delete);
-
分配的碎片问题:对堆来说,频繁分配和释放(malloc / free)不同大小的堆空间势必会造成内存空间的不连续,从而造成大量碎片,导致程序效率降低;而对栈来讲,则不会存在这个问题。
-
分配的效率不同:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持,例如,分配专门的寄存器存放栈的地址,压栈出栈都有专门的执行指令,这就决定了栈的效率比较高。一般而言,只要栈的剩余空间大于所申请空间,系统就将为程序提供内存,否则将报异常提示栈溢出。而堆则不同,它是由 C/C++ 函数库提供的,它的机制也相当复杂。例如,为了分配一块堆内存,首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆节点,然后将该节点从空闲节点链表中删除,并将该节点的空间分配给程序。而对于大多数系统,会在这块内存空间的首地址处记录本次分配的大小,这样,代码中的 delete 语句才能正确释放本内存空间。另外,由于找到的堆节点的大小不一定正好等于申请的大小,系统会自动将多余的那部分重新放入空闲链表中。很显然,
堆的分配效率比栈要低得多。 -
申请的大小限制:由于操作系统是用链表来存储空闲内存地址(内存区域不连续)的,同时链表的遍历方向是由低地址向高地址进行的。因此,堆内存的申请大小受限于计算机系统中有效的虚拟内存。而
栈是一块连续的内存区域,其地址向内存地址减小的方向增长。由此可见,栈顶的地址和栈的最大容量一般都是由系统预先规定好的,如果申请的空间超过栈的剩余空间时,将会提示溢出错误。由此可见,相对于堆,能够从栈中获得的空间相对较小。int func(int a, int b){ int c; int d; } 那么在 '栈' 中的内存排布为: "... | d | c | a | b | ..." -
存储的内容:对栈而言,一般用于存放函数的参数与局部变量等。例如,在函数调用时,第一个进栈的是(主函数中的)调用处的下一条指令(即函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数 C 编译器中,参数是由右往左入栈的,最后是函数中的局部变量(注意 static 变量是不入栈的)。对堆而言,具体存储内容由程序员根据需要决定存储数据。
void f(int i) { printf("%d,%d,%d,%d\n", i, i++, i++, i++); } int main(void) { int i = 1; f(i); return 0; } // 根据栈的先进后出原则,输出:“4,3,2,1”
编译环境差异
参考:C++ 32位64位的区别
所谓32位和64位,指的是CPU的字长,其实主要是 GPRS(General Purpose Regisers,通用寄存器)的数据宽度。所谓32位处理器就是一次只能处理32位,也就是4个字节的数据,而64位处理器一次就能处理64位,即8个字节的数据。CPU从32位提升到64位,主要的变化如下:
- 处理能力提升。比如原来要两个周期做的事,可以在一个周期搞定。
- 寻址能力更大。原本32位CPU的32根地址线只可以寻址
2^32 =4GB内存(所以32位系统理论上最大支持4GB的内存条,再大就用不到了),而64位CPU理论上的寻址能力是2^64,足够支持目前的硬件水平。 - 数据精度提升。一些数据类型可以用更大的字长表示,可以表示更大范围或者更精确的数。CPU分为32位和64位,在这基础上就有了32位操作系统和64位操作系统,进而还有32位程序和64位程序。
基本数据类型
| C++基本数据类型 | 别名 | 位数bits | 具体类型 | 取值范围 |
|---|---|---|---|---|
| char | int8_t | 8 位 | 带符号整数 | (-128……127) |
| unsigned char | uint8_t | 8 位 | 无符号整数 | (0……255) |
| short , short int | int16_t | 16 位 | 带符号整数 | (-32768……32767) |
| unsigned short , unsigned short int | uint16_t | 16 位 | 无符号整数 | (0……65535) |
| int | int32_t | 32 位 | 带符号整数 | (-2147483648……2147483647 ) |
| unsigned int | uint32_t | 32 位 | 无符号整数 | (0……4294967295) |
| long long | int64_t | 64位 | 带符号整数 | (-9223372036854775808……9223372036854775807) |
| unsigned long long | uint64_t | 64位 | 无符号整数 | (0……9223372036854775807) |
| float | 32 位 | 单精度浮点数 | ±(1.18e-38……3.40e38) | |
| double | 64 位 | 双精度浮点数 | ±(2.23e-308……1.79e308) |
32位和64位系统在Windows下的基本数据类型是一样的大小。有文章指出,long型数据在win和linux下数据长度不一致:
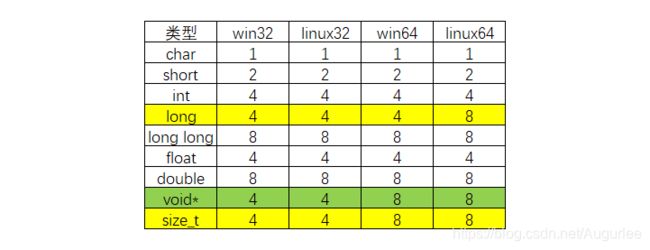
我的环境下long和int是一致的,虽然未在Linux下验证,但应该是正确的。那么,从表中来看,多平台编程应当避免使用long与size_t
指针类型
无论是win还是Linux,指针宽度都等于地址宽度,代表了寻址能力。所以32位的指针大小为4字节,64位的指针大小为8字节。
字符串类型 char[ ]
char* a = "abcde";
cout << "sizeof(char* ): " << sizeof(a) << endl; // 输出 8,指针宽度
char b[] = "abcde";
cout << "sizeof(char[]): " << sizeof(b) << endl; // 输出 6,数组元素个数+结尾空字符'\0'
注意:应当避免用指针直接定义字符串,warning: ISO C++ forbids converting a string constant to 'char*' [-Wwrite-strings] 因为右边是一个const char *的常量,隐式转换后可能出现常量被修改的情况。编译运行的结果会因编译器和操作系统共同决定,有的编译器会通过,有的会抛异常,就算过了也可能因为操作系统的敏感性而被杀掉。
如果打算使用指针,则可以通过显式转换或类型匹配来避免隐式转换的风险:
const char* a = "abcde"; // 避免类型转换
char* b = (char*)"abcde"; // 显式转换
字符串类型 string
string s = "abcde";
cout << "sizeof(string): " << sizeof(s) << endl; // 输出32个字节
本节的参考文章指出,32位下的结果和64位是不一致。
二者相差4字节,其实就是一个指针的差别(8-4),这是因为string内部并不保存字符串本身,而是保存了一个指向堆中的字符串开头的指针。另外,string的实现在各库中可能有所不同,但是在同一库中无论string里放多长的字符串,其sizeof()的结果都是固定的(string类的大小)。
大端模式和小端模式
参考:大端模式和小端模式的起源
大端 Big-Endian 和 Little-Endian 定义如下:
- 小端就是从低位开始取数据进行存储,所以低位字节排放在内存的低地址端,高位字节排放在内存的高地址端;
- 大端就是从高位开始取数据进行存储,所以高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。

注意:Java和所有的网络通讯协议都是使用Big-Endian的编码,而不同的文件格式的存储方式也不一样,因此得考虑是否需要格式转换。对于内存数据c = {c[0], c[1], c[2], …}小端模式int a = c[0] + c[1] << 16,大端模式int a = c[0] << 16 + c[1]
一般操作系统都是小端,而通讯协议是大端的。
常见CPU的字节序:
- Big Endian : PowerPC、IBM、Sun
- Little Endian : x86、DEC
- ARM既可以工作在大端模式,也可以工作在小端模式。
对比:
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
用联合体判断小端:
bool isLittleEndian() {
typedef union {
int a;
char c;
} Test;
Test t;
t.a = 0x1234;
return t.c == 0x34;
}
用指针强制转换判断小端:
bool isLittleEndian() {
int a = 0x1234;
char *p = (char *) &a;
return *p == 0x34;
}
代码示例:
int main(){
int b = 0x656667;
int a = 0x61626364;
char* p = (char*)&a;
printf("%s\n", p);
return 0;
}
输出:dcbagfe
内存排布:
... | 64 | 63 | 62 | 61 | 67 | 66 | 65 | 00 | ...
内存对齐
内存对齐原则
在没有定义#pragam pack(n)宏的情况下,struct/class/union内存对齐原则有四个:
-
数据成员对齐规则:结构(struct)(或联合(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始,基本类型不包括struct/class/uinon。
-
结构体作为成员: 如果一个结构里有某些结构体成员, 则结构体成员要从其内部"最宽基本类型成员"的整数倍地址开始存储。比如struct a里存有struct b,b里有char,int ,double等元素,那b应该从8的整数倍开始存储
-
收尾补齐: 结构体的总大小,也就是sizeof的结果,必须是其内部最大成员的"最宽基本类型成员"的整数倍,不足的要补齐。
-
sizeof(union):以结构里面size最大元素为union的size,因为在某一时刻,union只有一个成员真正存储于该地址。
#pragma pack(n) 作为一个预编译指令用来设置多少个字节对齐,n的缺省值一般是8. 如果定义了这个宏,则上述偏移量取决于数据成员类型大小和n的最小值。举例来说,除了第一个数据成员offset位置为0以外,其余的数据成员的offset是该成员大小与pragma pack(n)的最小值的整数倍。
结构体和普通类
在C++中,一般结构体和类是等同的,只是结构体默认访问权限是public,而类是private
以结构体举例,说明上述规则:
struct Test
{
int i=0xff030201;
char c='a';
short j = 0x5AFF;
}t;
内存存储为:(小端模式)
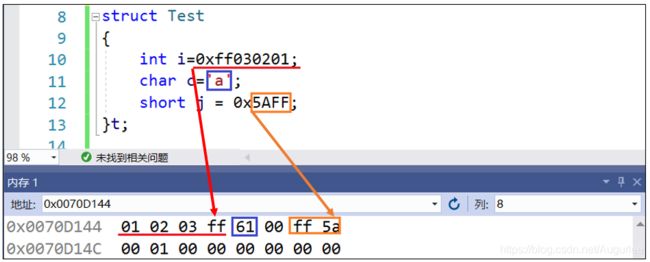
分析:
- 由于未定义
#pragma pack(n)宏,对齐字节默认为8,在64位系统中没有比之更宽的基本数据类型,因此不需要考虑n - 变量
int i是第一个数据成员,偏移量为0,占4个字节{0,1,2,3} - 变量
char c的偏移量应该是自身宽度的整数倍,取4,占1个字节{4} - 变量
short j的偏移量也应该是自身宽度的整数倍,取6,占2个字节{6, 7} - 内存
{5}被空了下来,此时结构体大小为8,等于内部最大成员int宽度(4)的整数倍,所以不需要补齐。结构体最终大小等于8。
再看一个例子:

分析:
- 不需要考虑
pack(n) - 变量
char c1是第一个数据成员,偏移量为0,占1个字节{0} - 变量
int i的偏移量应该是自身宽度的整数倍(4x),取4,占4个字节{4,5,6,7} - 变量
char c2的偏移量应该是自身宽度的整数倍(1x),取8,占1个字节{8} - 结构体变量
Base b的偏移量应该是其内部"最宽基本类型成员"的整数倍(4x),取12,占8个字节{12, 13, ..., 19} - 变量
short j的偏移量也应该是自身宽度的整数倍(2x),取20,占2个字节{20, 21} - 此时结构体大小为22,不等于内部最大成员
int宽度的整数倍(4x),需要补齐,所以结构体最终大小等于24。
思考一下:
上例中总共闲置了8个字节的内存,是一种很大浪费,处理得好可以再存储两个int变量,那就需要调整数据成员的存放顺序了
struct Test
{
char c1 = '0';
char c2 = 'a';
short j = 0xAA55;
int i = 0xffffffff;
Base b;
}t;
cout << sizeof(t) << endl; // 输出 16
结论:
在struct/class/union中定义变量时,长度小的变量先定义,长度大的变量后定义,调整合适的存储顺序可以节省内存。
类的特殊情况
类对象的内存结构

从类对象的内存结构来看,对象所处内存只包含了数据成员(和虚函数表指针),不包含成员函数的指针。也就是说,类的各个实例对象共享该类的成员函数,但各自的数据成员独立存储。所以,类的大小只需要像上述结构体一样分析数据成员的类型即可。
但要注意以下的特殊情况。
空类
类的实例化就是在内存中分配一块地址,每个实例在内存中都有独一无二的地址。同样空类也会被实例化,编译器会给空类隐含地添加一个字节的占位符,这样空类实例化之后就有地址了,sizeof等于1。
所谓空类,就是类中不含任何数据成员和虚函数,包含任意数量的成员函数。但只声明而未定义的类是非法的,不是空类。
class Empty
{
public:
Empty(); //缺省构造函数
Empty(const Empty &rhs); //拷贝构造函数
~Empty(); //析构函数
Empty& operator=(const Empty &rhs); //重载赋值运算符
Empty* operator&(); //重载取址运算符
const Empty* operator&() const; //重载取址运算符(const版本)
};
cout << "sizeof(Empty):" << (int)sizeof(Empty) << endl; // 输出 1
虚函数类
class A {
public:
virtual void print() {
cout << "virtual A::Print() is running..." << endl;
}
};
class B : public A {
public:
virtual void print() {
cout << "virtual B::Print() is running... " << endl;
}
};
输出:
>> sizeof(A):8
>> sizeof(B):8
分析:
- A类中包含虚函数,所以内存中存在一个指向虚函数表的指针,大小取决于系统架构,本文环境x64所以 sizeof = 8
- B类是A的派生类,从上文类对象的内存结构图来看,派生类包含了基类的大小。也可以根据赋值兼容规则分析:派生类对象中包含了一个无名基类对象。所以派生类的大小应该是“基类大小+自身的数据成员”
静态数据成员
静态数据成员被编译器放在程序的一个global data members中,它是类的一个数据成员,但是不影响类的大小,不管这个类实际产生了多少实例,还是派生了多少新的类,静态成员数据在类中永远只有一个实体存在,被所有实例对象所共用。
class C {
int a;
char c;
};
class D {
int a;
static char c;
};
char D::c = 'a';
输出:
>> sizeof C:8
>> sizeof D:4
虚继承
当存在虚拟继承时,派生类中会有一个指向 虚基类表 的指针。所以虚继承类对象的大小为:所有基类大小 + 自身数据成员大小 + 虚基类表指针大小
class E :
public C,
public D {
char x;
};
class F :
virtual public C,
virtual public D {
char x;
};
class G :
virtual public C,
virtual public D {
};
输出:
>> sizeof E:16
>> sizeof F:24
>> sizeof G:24
分析:
- E多继承了两个基类(8+4),自身1个字节的数据成员,需要对齐int宽度的整数倍(4x),得8+4+1=13 -->16
- F是在E的基础上改为了虚继承,因此加上虚基类表指针大小,其偏移量应该是8x,取8+4+1=13–>16,得16+8 = 24
- G是直接虚继承了两个基类(8+4),虚基类表指针的偏移量应该是8x,取8+4=12–>16,得16+8 = 24
注意:
关于虚继承需要指明的是,一个类继承自多个基类是合理的,但为了避免如下情形:基类BC都是A类的派生,D多继承自BC,那么就会重复包含A基类,造成链接错误,因此需要 virtual 关键字来规避。
多继承虚函数类
当一个类继承多个含虚函数的基类时,将会有多个vptr和vtab,这对运行速度有一定影响,也将占据更多内存空间。但如果是单继承,不论基类中多少个虚函数,都共用一张虚函数表vtab和一个vptr。
class A {
public:
virtual void print() {
cout << "virtual A::Print() is running..." << endl;
}
};
class B {
public:
virtual void test(int x) {
cout << "virtual B::test() is running... " << endl;
}
};
class C : public A, public B {
public:
virtual void print() {
cout << "virtual C::Print() is running..." << endl;
}
virtual void test(int x) {
cout << "virtual C::test() is running... " << endl;
}
};
输出:
>> sizeof A:8
>> sizeof B:8
>> sizeof C:16