线程池+jsoup+htmlclient实现微博超话社区自动签到
java线程池+jsoup+htmlunit实现微博超话社区自动签到
这是个半夜闲没事写的一个爬虫,所以很多命名可能有点不大好,哈哈,请见谅,程序能运行就行毕竟也只是闲没事摸个鱼写写的,其实里面也有很多东西可以优化的,不过。。。。。。大半夜的,优化个球球,运行完赶紧睡觉去喽
还有一点忘记说了,其实里面只需要用到 java线程池 + jsoup就可以了,只不过使用htmunit解析微博页面js的时候报错,感觉这个htmlunit有点不靠谱,然后自己花了点时间找了找url的一些规律来完成签到
先上个线程池工具类:
/**
* 线程池工具类
*/
public class PoolSend {
BlockingQueue<Runnable> workQueue;//任务队列
ExecutorService es;//线程池的接口
Long startTime;//开始时间
/**
* @param corePoolSize 初始化线程数量、核心线程数
* @param maximumPoolSize 最大线程、非核心线程数
*/
public PoolSend(Integer corePoolSize, Integer maximumPoolSize) {
startTime = System.currentTimeMillis();
/**
* 构造无界的任务队列,资源足够,理论可以支持无线个任务
* 不过如果并发量很大的话,最好指定一下队列的长度,否则把所有东西放进队列里面
* 很可能会导致内存溢出
*/
workQueue = new LinkedBlockingQueue<>(corePoolSize * 4);
/**
* 1、初始化线程数量
* 2、最大线程
* 3、线程存活时间
* 4、时间单位
* 5、阻塞队列,用来存储等待执行的任务
* 6、拒绝策略
*/
es = new ThreadPoolExecutor(corePoolSize, maximumPoolSize,
60, TimeUnit.SECONDS, workQueue,
new ThreadPoolExecutor.CallerRunsPolicy());
}
public void send(Runnable task) {
System.out.println("PoolSend start sending mail...");
es.execute(task);//将任务放入线程池提交
}
public void close() {// 关闭
es.shutdown();
while (true) {//等待所有任务都执行结束
if (es.isTerminated()) {//所有的子线程都结束了
System.out.println("共耗时:" + (System.currentTimeMillis() - startTime) / 1000 + "s");
break;
}
}
}
}
获取WebClient方法 使用jsoup解析页面
//返回一个设置了cookie的webclient
public WebClient getWebClient() {
final WebClient webClient = new WebClient(BrowserVersion.CHROME);//创建对象
webClient.getOptions().setCssEnabled(false);//关闭css
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getCookieManager().setCookiesEnabled(true);
// webClient.setAjaxController(new NicelyResynchronizingAjaxController());
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getCookieManager().addCookie(new Cookie(".weibo.com", "SUB", "_2A25N71AlDeRhGe"));
return webClient;
}
//调用jsoup的方法来获取页面解析网页
public static String userAgentVal = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36";
public Document getPage(String url) throws Exception {
//获取connection
Connection connect = Jsoup.connect(url).ignoreContentType(true);
//配置模拟浏览器
connect.userAgent(userAgentVal);
//配置cookie
HashMap<String, String> map = new HashMap<>();
map.put("SUB", "_2A25N71AlDeRhGeRG61oY-C_JyT2IHXV");
connect.cookies(map);
//获取响应
Connection.Response rs = connect.execute();
Document parse = rs.parse();
return parse;
}
获取所有我关注的超话社区
//首先获取我的所有关注的会话社区链接添加到 urls 这个集合中
@Test
public void test02() throws IOException {
//创建一个线程池
PoolSend poolSend = new PoolSend(10, 10);
//这个集合用于存放
ArrayList<String> urls = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
int finalI = i;
poolSend.send(() -> {
try {
Document page = getPage("https://www.weibo.com/p/1005052808981521/myfollow?t=1&cfs=&Pl_Official_RelationMyfollow__89_page=" + finalI + "#Pl_Official_RelationMyfollow__89");
Elements script = page.select("script").eq(29);
// System.out.println(script);
String replace = StringUtils.replace(script.toString(), "\\n", "");
String replace1 = StringUtils.replace(replace, "\\r", "");
String replace2 = StringUtils.replace(replace1, "\\t", "");
String replace3 = StringUtils.replace(replace2, "\\", "");
String replace4 = StringUtils.replace(replace3, "", "");
replace5 = s + replace5 + f;
Document parse = Jsoup.parse(replace5);
Elements elements = parse.select(".title.W_fb.W_autocut");
for (Element element : elements) {
if (element.html().indexOf("W_ficon ficon_supertopic S_ficon") != -1) {
String attr = element.select("a").attr("href");
urls.add(attr);
}
}
} catch (Exception e) {
e.printStackTrace();
}
});
}
poolSend.close();//所有会话社区链接获取完毕后关闭线程池
//遍历urls调用qiandao这个方法,这边也可以使用多线程,看自己
for (String url : urls) {
System.out.println(url);
//调用签到方法
signIn(url);
}
}
签到方法
//这里我使用的工具类是:import org.springframework.util.StringUtils;
//前缀
String s = "\n" +
"\n" +
"\n" +
" \n" +
" Title \n" +
"\n" +
"";
String f = "\n" +
"";
void qiandao(String url) {
try {
//这样我建议直接换成jsoup来抓页面
WebClient webClient = getWebClient();
HtmlPage page = webClient.getPage(url);
//对html进行解析
Document parse = Jsoup.parse(page.asXml());
Elements script = parse.select("script").eq(9);
String replace = StringUtils.replace(script.toString(), "\\n", "");
String replace1 = StringUtils.replace(replace, "\\r", "");
String replace2 = StringUtils.replace(replace1, "\\t", "");
String replace3 = StringUtils.replace(replace2, "\\", "");
String replace4 = StringUtils.replace(replace3, "", "");
replace5 = StringUtils.replace(replace5, "//]]>", "");
replace5 = StringUtils.replace(replace5, "\"})", "");
replace5 = s + replace5 + f;
Document parse2 = Jsoup.parse(replace5);//到了这一步 html 就已经解析完毕了
//还是获取解析签到发送链接
Elements eq = parse2.select(".W_btn_b.btn_32px").eq(1);
Element element = eq.get(0);
String attr = element.attr("action-data");
String[] split = attr.split("=");
split[0]="";
split[1]="https://weibo.com/p/aj/general/button?ajwvr=6&api=http://i.huati.weibo.com/aj/super/checkin&texta";
StringBuilder stringbuiler = new StringBuilder();
for (String s1 : split) {
stringbuiler.append(s1+"=");
}
stringbuiler.append("&location=page_100808_super_index&timezone=GMT+0800&lang=zh-cn&plat=Win32&ua=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67&screen=1536*864&__rnd=1626028188044");
// stringbuiler.append(URLEncoder.encode("&location=page_100808_super_index&timezone=GMT+0800&lang=zh-cn&plat=Win32&ua=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67&screen=1536*864&__rnd=1626028188044", "UTF-8"));
String x = stringbuiler.toString();
x = x.substring(1, x.length() - 1);
x = StringUtils.replace(x,"=&location=","&location=");
System.out.println(x);
Document page1 = getPage(x);//发送请求
System.out.println(page1);
} catch (Exception e) {
e.printStackTrace();
}
}
运行(记得要联网):
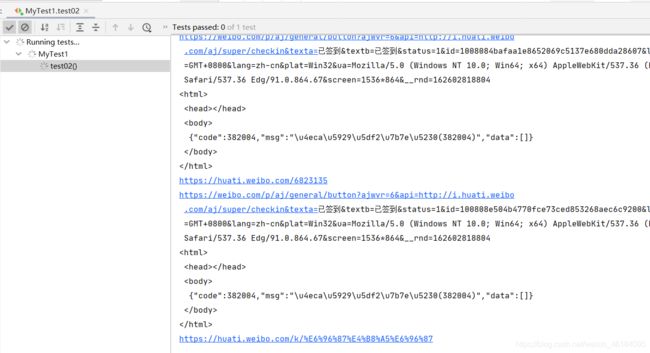
运行成功!
如果需要分析思路或者爬虫过程的话可以跟我说声,我回头重新编辑写一下