探究Kafka原理-7.exactly once semantics 和 性能测试
- 作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 系列专栏:Spring源码、JUC源码、Kafka原理
- 如果感觉博主的文章还不错的话,请三连支持一下博主哦
- 博主正在努力完成2023计划中:源码溯源,一探究竟
- 联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
文章目录
- 幂等性
-
- 幂等性要点
- kafka 幂等性实现机制
- kafka 事务
-
- 事务要点知识
- 事务 api 示例
- 事务实战案例
- Kafka 速度快的原因
- 分区数与吞吐量(性能测试)
-
- 生产者性能测试
-
- tpc_3: 分区数 3,副本数 1
- tpc_4: 分区数 4,副本数 2
- tpc_5:分区数 5,副本数 1
- tpc_6:分区数 6,副本数 1
- tpc_12:分区数 12
- 消费者性能测试
- 分区数与吞吐量实际测试
- 分区数设置的经验参考
幂等性
幂等性要点
Kafka 0.11.0.0 版本开始引入了幂等性与事务这两个特性,以此来实现 EOS ( exactly once semantics ,精确一次处理语义)
生产者在进行发送失败后的重试时(retries),有可能会重复写入消息,而使用 Kafka 幂等性功能之后就可以避免这种情况。
开启幂等性功能,只需要显式地将生产者参数 enable.idempotence 设置为 true (默认值为 false):props.put(“enable.idempotence”,true);
在开启幂等性功能时,如下几个参数必须正确配置:
- retries > 0
- max.in.flight.requests.per.connection<=5
- acks = -1
如有违反,则会抛出 ConfigException 异常;
kafka 幂等性实现机制
每一个 producer 在初始化时会生成一个 producer_id,并为每个目标分区维护一个“消息序列号”;
producer 每发送一条消息,会将对应的“序列号”加 1
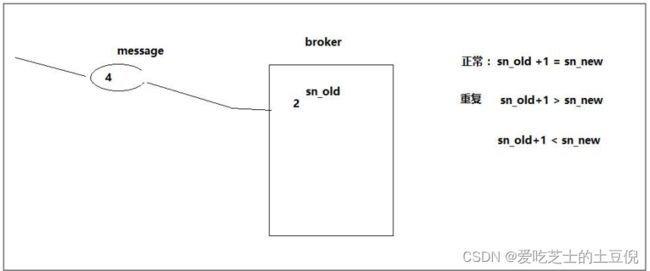
broker 端会为每一对{producer_id,分区}维护一个序列号,对于每收到的一条消息,会判断服务端的 SN_OLD 和接收到的消息中的 SN_NEW 进行对比:
- 如果 SN_OLD + 1 == SN_NEW,正常;
- 如果 SN_NEW < SN_OLD + 1 说明是重复写入的数据,直接丢弃
- 如果 SN_NEW>SN_OLD+1,说明中间有数据尚未写入,或者是发生了乱序,或者是数据丢失,将抛出严重异常:OutOfOrderSequenceException
producer.send(“aaa”) 消息 aaa 就拥有了一个唯一的序列号
如果这条消息发送失败,producer 内部自动重试(retry),此时序列号不变;
producer.send(“bbb”) 消息 bbb 拥有一个新的序列
注意:kafka 只保证 producer 单个会话中的单个分区幂等。
kafka 事务
从kafka读数据,写入mysql的场景中
为了让 偏移量更新 和 数据的落地 一荣俱荣,用了mysql的事务,这样就能实现上述场景中数据传输的端到端,精确一次性语义eos
但是万一存在如下场景:
要你从kafka的source_topic中读数据,做处理,然后写入kafka的dest_topic
这个场景,要想实现eos,就不能利用mysql中的事务了。
假设1-100的数据读了,处理完了,写入kafka目标topic,但是offset还是1,然后,程序崩溃了。
然后,重启,程序会从1开始读,会把1-100重新再读一次,再处理一次,再插入到目标topic一次。
这里和幂等性是有区别的(幂等性,是说producer.send(),在它内部发生重试的时候,可以由broker去除重复数据)
要解决上述场景中的数据重复的问题:需要将偏移量更新 和 数据落地,绑定在一个事务中。
mysql中事务解决上述问题,关键点在于mysql可以实现数据的回滚。
而kafka中的数据是支持不断追加,然后只读。
kafka中的事务,做到了什么效果:
kafka并不能真正把未提交事务的结果进行物理回滚,只做到了让下游消费者,只能看到提交了事务的结果。
事务要点知识
Kafka 的事务控制原理
主要原理:
- 开始事务–>发送一个 ControlBatch 消息(事务开始)
- 提交事务–>发送一个 ControlBatch 消息(事务提交)
- 放弃事务–>发送一个 ControlBatch 消息(事务终止)
开始事务的必须配置参数
Properties props = new Properties();
props.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"doit01:9092");
props.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
props.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
// acks
props.setProperty(ProducerConfig.ACKS_CONFIG,"-1");
// 生产者的重试次数
props.setProperty(ProducerConfig.RETRIES_CONFIG,"3");
// 飞行中的请求缓存最大数量
props.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION,"3");
// 开启幂等性
props.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,"true");
// 设置事务 id
props.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"trans_001");
事务控制的代码模板
// 初始化事务
producer.initTransaction( )
// 开启事务
producer.beginTransaction( )
try{
// 干活
// 提交事务
producer.commitTransaction( )
}catch (Exception e){
// 异常回滚(放弃事务)
producer.abortTransaction( )
}
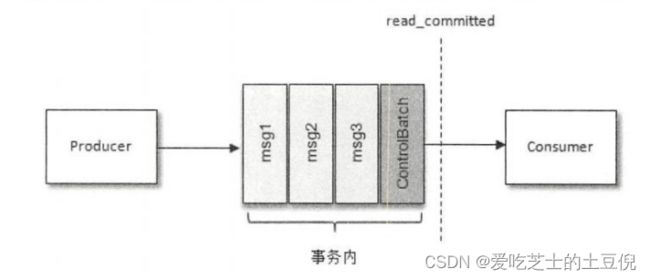
消费者 api 是会拉取到尚未提交事务的数据的;只不过可以选择是否让用户看到!
是否让用户看到未提交事务的数据,可以通过消费者参数来配置:
isolation.level=read_uncommitted(默认值)
isolation.level=read_committed
kafka 还有一个“高级”事务控制,只针对一种场景:
用户的程序,要从 kafka 读取源数据,数据处理的结果又要写入 kafka
kafka能实现端到端的事务控制(比起上面的“基础”事务,多了一个功能,通过producer可以将consumer的消费偏移量绑定到事务上提交)
producer.sendOffsetsToTransaction(offsets,consumer_id)
事务 api 示例
为了实现事务,应用程序必须提供唯一 transactional.id,并且开启生产者的幂等性
properties.put ("transactional.id","transactionid00001");
properties.put ("enable.idempotence",true);
kafka 生产者中提供的关于事务的方法如下:
“消费 kafka-处理-生产结果到 kafka”典型场景下的代码结构示例
package cn.doitedu.kafka.transaction;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.*;
/***
* @author hunter.d
* @qq 657270652
* @wx haitao-duan
* @date 2020/11/15
**/
public class TransactionDemo {
public static void main(String[] args) {
Properties props_p = new Properties();
props_p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"doitedu01:9092,d
oitedu02:9092");
props_p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
StringSerializer.class.getName());
props_p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerial
izer.class.getName());
props_p.setProperty(ProducerConfig.TRANSACTIONAL_ID_CONFIG,"tran_id_001");
Properties props_c = new Properties();
props_c.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props_c.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props_c.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,
"doitedu01:9092,doitedu02:9092");
props_c.put(ConsumerConfig.GROUP_ID_CONFIG, "groupid01");
props_c.put(ConsumerConfig.CLIENT_ID_CONFIG, "clientid");
props_c.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
// 构造生产者和消费者
KafkaProducer<String, String> p = new KafkaProducer<String, String>(props_p);
KafkaConsumer<String, String> c = new KafkaConsumer<String, String>(props_c);
c.subscribe(Collections.singletonList("tpc_5"));
// 初始化事务
p.initTransactions();
// consumer-transform-produce 模型业务流程
while(true){
// 拉取消息
ConsumerRecords<String, String> records = c.poll(Duration.ofMillis(1000L));
if(!records.isEmpty()){
// 准备一个 hashmap 来记录:"分区-消费位移" 键值对
HashMap<TopicPartition, OffsetAndMetadata> offsetsMap = new HashMap<>();
// 开启事务
p.beginTransaction();
try {
// 获取本批消息中所有的分区
Set<TopicPartition> partitions = records.partitions();
// 遍历每个分区
for (TopicPartition partition : partitions) {
// 获取该分区的消息
List<ConsumerRecord<String, String>> partitionRecords =
records.records(partition);
// 遍历每条消息
for (ConsumerRecord<String, String> record : partitionRecords) {
// 执行数据的业务处理逻辑
ProducerRecord<String, String> outRecord = new
ProducerRecord<>("tpc_sink", record.key(), record.value().toUpperCase());
// 将处理结果写入 kafka
p.send(outRecord);
}
// 将处理完的本分区对应的消费位移记录到 hashmap 中
long offset = partitionRecords.get(partitionRecords.size() -
1).offset();
offsetsMap.put(partition,new OffsetAndMetadata(offset+1));
}
// 向事务管理器提交消费位移
p.sendOffsetsToTransaction(offsetsMap,"groupid");
// 提交事务
p.commitTransaction();
}catch (Exception e){
// 终止事务
p.abortTransaction();
}
}
}
}
}
事务实战案例
在实际数据处理中,consume-transform-produce 是一种常见且典型的场景;
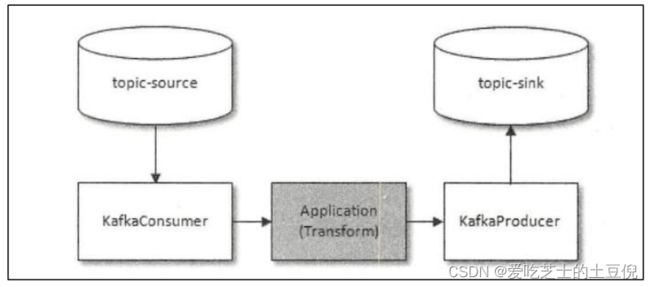
在此场景中,我们往往需要实现,从“读取 source 数据,至业务处理,至处理结果写入 kafka”的整个流程,具备原子性:
要么全流程成功,要么全部失败!
(处理且输出结果成功,才提交消费端偏移量;处理或输出结果失败,则消费偏移量也不会提交)
要实现上述的需求,可以利用 Kafka 中的事务机制:
它可以使应用程序将消费消息、生产消息、提交消费位移当作原子操作来处理,即使该生产或消费会跨多个 topic 分区;
在 消 费 端 有 一 个 参 数 isolation.level , 与 事 务 有 着 莫 大 的 关 联 , 这 个 参 数 的 默 认 值 为“read_uncommitted”,意思是说消费端应用可以看到(消费到)未提交的事务,当然对于已提交的事务也是可见的。这个参数还可以设置为“read_committed”,表示消费端应用不可以看到尚未提交的事务内的消息。
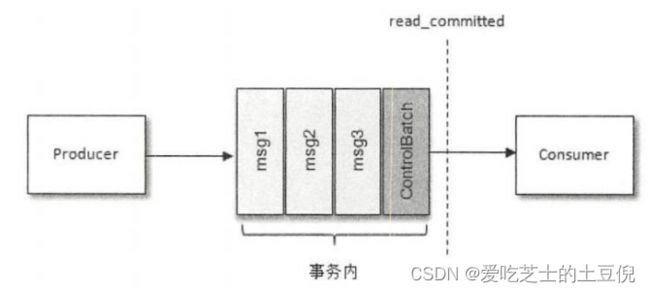
控制消息(ControlBatch:COMMIT/ABORT)表征事务是被提交还是被放弃
Kafka 速度快的原因
- 消息顺序追加(磁盘顺序读写比内存的随机读写还快)
- 页缓存等技术(数据交给操作系统的页缓存,并不真正刷入磁盘;而是定期刷入磁盘)
- 使用 Zero-Copy (零拷贝)技术来进一步提升性能;
扩展阅读:零拷贝
所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手;
零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换;对于 Linux 系统而言,零拷贝技术依赖于底层的 sendfile( )方法实现;对应于 Java 语言,FileChannal.transferTo( )方法的底层实现就是 sendfile( )方法;
- 非零拷贝示意图

- 零拷贝示意图

零拷贝技术通过 DMA (Direct Memory Access)技术将文件内容复制到内核模式下的 Read Buffer。不过没有数据被复制到 Socke Buffer,只有包含数据的位置和长度的信息的文件描述符被加到 Socket Buffer; DMA 引擎直接将数据从内核模式 read buffer 中传递到网卡设备
这里数据只经历了 2 次复制就从磁盘中传送出去了,并且上下文切换也变成了 2 次
零拷贝是针对内核模式而言的,数据在内核模式下实现了零拷贝;
分区数与吞吐量(性能测试)
Kafka 本 身 提 供 用 于 生 产 者 性 能 测 试 的 kafka-producer-perf-test.sh 和 用 于 消 费 者 性 能 测 试 的
kafka-consumer-perf-test. sh,主要参数如下:
- topic 用来指定生产者发送消息的目标主题;
- num-records 用来指定发送消息的总条数
- record-size 用来设置每条消息的字节数;
- producer-props 参数用来指定生产者的配置,可同时指定多组配置,各组配置之间以空格分隔与
producer-props 参数对应的还有一个 producer-config 参数,它用来指定生产者的配置文件; - throughput 用来进行限流控制,当设定的值小于 0 时不限流,当设定的值大于 0 时,当发送的吞吐量大于该值时就会被阻塞一段时间。
经验:如何把 kafka 服务器的性能利用到最高,一般是让一台机器承载( cpu 线程数*2~3 )个分区
测试环境: 节点 3 个,cpu 2 核 2 线程,内存 8G ,每条消息 1k
测试结果: topic 在 12 个分区时,写入、读取的效率都是达到最高
写入: 75MB/s ,7.5 万条/s
读出: 310MB/s
当分区数>12 或者 <12 时,效率都比=12 时要低!
生产者性能测试
tpc_3: 分区数 3,副本数 1
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_3 --num-records 100000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 26068.821689 records/sec (25.46 MB/sec), 926.82 ms avg latency, 1331.00 ms max latency, 924 ms 50th, 1272 ms 95th, 1305 ms 99th, 1318 ms 99.9th.
tpc_4: 分区数 4,副本数 2
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_4 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 25886.616619 records/sec (25.28 MB/sec), 962.06 ms avg latency, 1647.00 ms max latency, 857 ms 50th, 1545 ms 95th, 1622 ms 99th, 1645 ms 99.9th.
tpc_5:分区数 5,副本数 1
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_5 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 28785.261946 records/sec (28.11 MB/sec), 789.29 ms avg latency, 1572.00 ms max latency, 665 ms 50th, 1502 ms 95th, 1549 ms 99th, 1564 ms 99.9th
tpc_6:分区数 6,副本数 1
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_6 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 42662.116041 records/sec (41.66 MB/sec), 508.68 ms avg latency, 1041.00 ms max latency, 451 ms 50th, 945 ms 95th, 1014 ms 99th, 1033 ms 99.9th.
tpc_12:分区数 12
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-producer-perf-test.sh --topic tpc_12 --num-records 100000
--record-size 1024 --throughput -1 --producer-props bootstrap.servers=doitedu01:9092 acks=1
100000 records sent, 56561.085973 records/sec (55.24 MB/sec), 371.42 ms avg latency, 1103.00 ms max latency, 314 ms 50th, 988 ms 95th, 1091 ms 99th, 1093 ms 99.9th.
消费者性能测试
[root@doitedu01 kafka_2.11-2.0.0]# bin/kafka-consumer-perf-test.sh --topic tpc_3 --messages 100000
--broker-list doitedu01:9092 --consumer.config x.propertie
结果数据个字段含义:
start.time: 2023-11-14 15:43:42:422
end.time : 2023-11-14 15:43:43:347
data.consumed.in.MB: 98.1377
MB.sec : 106.0948
data.consumed.in.nMsg : 100493
nMsg.sec : 108641.0811
rebalance.time.ms : 13
fetch.time.ms : 912
fetch.MB.sec : 107.6071
fetch.nMsg.sec : 110189.6930
结果中包含了多项信息,分别对应
起始运行时间(start. time)、
结束运行时 end.time)、
消息总量(data.consumed.in.MB ,单位为 MB ),
按字节大小计算的消费吞吐量(单位为 MB )、
消费的消息总数( data. consumed.in nMsg )、
按消息个数计算的吞吐量(nMsg.sec)、
再平衡的时间( rebalance time.ms 单位为 MB/s)、
拉取消息的持续时间(fetch.time.ms,单位为 ms)、
每秒拉取消息的字节大小(fetch.MB.sec 单位 MB/s)、
每秒拉取消息的个数( fetch.nM.sec)。
其中
fetch.time.ms= end.time - start.time - rebalance.time.ms
分区数与吞吐量实际测试
Kafka 只允许单个分区中的消息被一个消费者线程消费,一个消费组的消费并行度完全依赖于所消费的分区数;
如此看来,如果一个主题中的分区数越多,理论上所能达到的吞吐量就越大,那么事实真的如预想的一样吗?
我们以一个 3 台普通阿里云主机组成的 3 节点 kafka 集群进行测试,每台主机的内存大小为 8GB,磁
盘 为 40GB, 4 核 CPU 16 线 程 , 主 频 2600MHZ , JVM 版 本 为 1.8.0_112 , Linux 系 统 版 本 为
2.6.32-504.23.4.el6.x86_64。
创建分区数为 1、20、50、100、200、500、1000 的主题,对应的主题名称分别为 topic-1 topic 20
topic-50 topic-100 topic-200 topic-500 topic-1000 ,所有主题的副本因子都设置为 1。
生产者,测试结果如下

消费者,测试结果与上图趋势类同
如何选择合适的分区数?从某种意恩来说,考验的是决策者的实战经验,更透彻地说,是 Kafka 本身、业务应用、硬件资源、环境配置等多方面的考量而做出的选择。在设定完分区数,或者更确切地说是创建主题之后,还要对其追踪、监控、调优以求更好地利用它
一般情况下,根据预估的吞吐量及是否与 key 相关的规则来设定分区数即可,后期可以通过增加分区数、增加 broker 或分区重分配等手段来进行改进。
分区数设置的经验参考
如果一定要给一个准则,则建议将分区数设定为集群中 broker 的倍数,即假定集群中有 3 个 broker 节点,可以设定分区数为 3/6/9 等,至于倍数的选定可以参考预估的吞吐量。
或者根据机器配置的 cpu 线程数和磁盘性能来设置最大效率的分区数:= CPU 线程数 * 1.5~2倍
不过,如果集群中的 broker 节点数有很多,比如大几十或上百、上千,那么这种准则也不太适用。
还有一个可供参考的分区数设置算法:
每一个分区的写入速度,大约 40M/s
每一个分区的读取速度,大约 60M/s
假如,数据源产生数据的速度是(峰值)800M/s ,那么为了保证写入速度,该 topic 应该设置 20个分区(副本因子为 3)。