MyBatis使用教程详解<下>
回顾上一篇博文,我们讲了如何使用注解/XML的方式来操作数据库,实际上,一个Mapper接口的实现,这两种方式是可以并存的.
上一篇博文中,我们演示的都是比较简单的SQL语句,没有设计到复杂的逻辑,本篇博文会讲解复杂SQL的实现及一些细节处理.话不多说,让我们开始吧.
一. #{}和${}
1.1 ${}的使用
不论使用注解还是XML,我们通常使用#{}向SQL语句中传递参数.实际上,${}也起到了传递参数的效果.
先来传递一个Integer类型的参数.
这次我们使用的是user表和User实体类.

在UserMapper中定义一个updateAge方法.
//使用${}传递参数
@Update("update user set age=${age} where id=${id}")
int updateAge(Integer age,Integer id);针对该方法生成对应的测试方法.
@Test
void updateAge() {
int result=userMapper.updateAge(28,21);
log.info("更新条目: "+result);
}根据日志打印结果,可以发现更新成功了
![]()
但是我们这次的重点不是更新结果,而是生成的SQL语句.

同学们先回想一下使用#{}传递参数时的SQL语句...
接着我们使用${}来传递String类型的参数.
在UserMapper接口中定义updateName方法.
@Update("update user set name=${name} where id=${id}")
int updateName(String name,Integer id);然后生成对应的测试方法.
@Test
void updateName() {
int result=userMapper.updateName("马小跳",22);
log.info("更新条目: "+result);
}运行测试方法,我们会发现这次代码抛出了异常.

如果还没有发现抛出异常的原因,不妨把打印的SQL语句复制到MySQL命令行上看看.
![]()
看到熟悉的界面,不知道童鞋们有没有想起来SQL语句中的字符串需要加上''或者""
所以我们可以手动给注解中的SQL语句加上''
@Update("update user set name='${name}' where id=${id}")
int updateName(String name,Integer id);再次运行测试方法,可以正常进行更新.

1.2 #和$的区别
看到这个小标题,如果同学们觉得不过就是加不加引号的区别,那就太小看它们两个了.
#{}使用的是预编译的方式进行数据库操作,${}使用的是即时编译.
预编译会使用占位符?提前给要传入的参数占位,即时编译则是直接将传递的参数插入到SQL语句中.
来看下二者SQL语句的打印,屏幕前的你或许就不那么懵逼了.

下面详细列举一下预编译和即时编译的区别:
1. 预编译的性能更高.
一个SQL语句从编译到执行需要一下三步.
预编译SQL,编译一次之后会将编译后的SQL语句缓存起来,如果后面再次执行了该语句,不会再次编译(只是进行了传参操作),省去了前面的两个步骤.
而即时编译每执行一条SQL语句,都要进行上述的全部流程.
2. 预编译更加安全,可以防止SQL注入.
如果想根据查询指定姓名的user,在UserMapper中定义selectByName方法.
吸取上文的经验,如果使用${}传参,我们需要加上''
@Select("select * from user where name='${name}'") ListselectByName(String name); 编写对应的测试方法并输入下面这条数据.
@Test void selectByAge() { Listlist=userMapper.selectByName("' or 1='1"); log.info("根据name查询user:{}",list); } 观察打印的日志,我们会发现查询出来的是user表中的全部数据.
来看一下SQL语句.
这就相当于你提供了一个接口,客户输入姓名即可获取到自己的个人信息,然而hacker可以通过SQL注入的方式获取到全部客户的信息...
肯定有童鞋要问了,#{}的方式难道不是给字符串类型的参数加上''吗,这样不也有SQL注入的风险吗?
我们来试验一下.
@Select("select * from user where name=#{name}") ListselectByName2(String name); 来看一下查询结果
实际上,通过#{}传递参数并不仅仅是判断参数类型,然后添上引号这样简单.{}中的参数只在占位符的位置起效,而不会作为SQL的部分语句执行.
举个栗子~就好像你买了一瓶可乐,然后去禁止自带饮料的餐厅就餐,手边的可乐是不能喝的.



1.3 $的使用场景
你们肯定会疑惑,既然$有这么多的缺点,以后的所有场景全部无脑使用#不就万事大吉了?
#{}也有解决不了的情况.
1.3.1 排序
来实现一个方法,根据用户指定的排序方式对查询结果按照Id排序并返回.
我们先来使用#{}进行传参.
@Select("select * from user order by id #{order}")
List selectByIdOrder(String order); 在测试类中生成对应的测试方法.
@Test
void selectByIdOrder() {
List userList=userMapper.selectByIdOrder("desc");
System.out.println(userList);
} 我们会发现抛出了异常,是因为#{}偷偷加了引号.

这种情况下就不得不使用${}的方式传入参数了.
@Select("select * from user order by id ${order}")
List selectByIdOrder(String order); 这次我们如愿拿到了排序后的结果.
但是在上文中提到,使用${}未免会有SQL注入的风险,如果不得不使用${},我们该如何规避呢?
这种情况下,我们就可以直接把代码写死,比如编写两个方法,根据用户输入的参数决定调用哪种方法进行查询.
1.3.2 模糊查询
来回顾一下模糊查询的SQL语句.
%表示零个或多个字符,_表示一个字符.

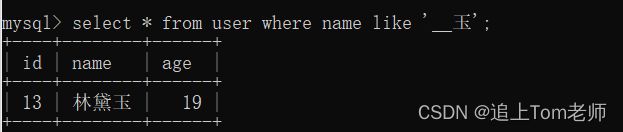
这种情况下,如果我们使用#{}进行模糊查询
@Select("select * from user where name like '%#{name}%'")
List selectLikeName(String name); @Test
void selectLikeName() {
List list=userMapper.selectLikeName("玉");
System.out.println(list);
} 这时候代码会抛出一个异常~
 如果换成${}+单引号的方式.
如果换成${}+单引号的方式.
@Select("select * from user where name like '%${name}%'")
List selectLikeName(String name); 就可以拿到相应结果.
![]()
这种情况下,我们又该怎么防止SQL注入呢?实际上,SQL提供了一种连接字符串的方法.
使用concat函数连接字符串

于是乎,我们就可以在模糊查询中也使用#{}进行传参了.
@Select("select * from user where name like concat('%',#{name},'%')")
List selectLikeName(String name); 同样拿到了正确的结果.

二. 动态SQL的实现
动态SQL是MyBatis强大的特性之一,能够完成不同条件下不同的SQL拼接.
2.1 什么是动态SQL
比如我们要填写下面这张基本信息表,其中昵称是必填项.

可以看到, 客户可能会选择不同的信息填写.如果程序猿要针对每个标签都判断一下是否有填写内容的话,未免太过麻烦.在这种情况下该怎么插入客户的信息呢?
动态SQL就是根据传入参数的不同,编译不同的SQL语句.
MyBatis提供了几个标签帮助我们实现动态SQL.
因为使用XML的方式实现动态SQL比较简单,所以下面主要使用XML的方式进行展示,如何使用注解进行动态SQL将会在本文末尾稍加演示.
2.2 标签
这次我们准备的是Article表及其对应的实体类.

如果用户没有输入title或者content等字段的信息,我们便不进行插入.
那么该如何使用动态SQL来实现呢?
来看代码,首先定义一个ArticleMapper接口.
@Mapper
public interface ArticleMapper {
int insertArticle(Article article);
}接着创建一个对应的XML文件(配置文件中要设置好XML文件的路径)
insert into article(title,content,author_id,create_time,update_time)
values(#{title},#{content},#{authorId},#{createTime},#{updateTime});
一般情况下,我们应该写的SQL语句是下面这样式的.

但是如果用户没有输入对应的字段值,我们需要修改这个SQL语句.该如何动态删除其中的某些字段呢?
可以借助
insert into article(
title,
content,
author_id,
create_time,
update_time )
values(
#{title},
#{content},
#{authorId},
#{createTime},
#{updateTime} )
话不多说,演示一下就能明白了.按照之前的套路,需要先创建一个测试类,然后对insertArticle方法进行测试.
@SpringBootTest
@Slf4j
class ArticleMapperTest {
@Autowired
private ArticleMapper mapper;
@Test
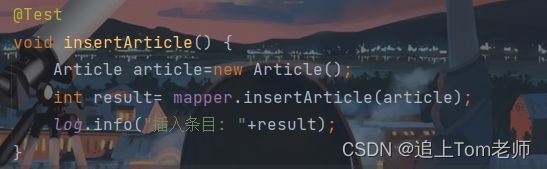
void insertArticle() {
Article article=new Article();
article.setTitle("黑猫爱上了白猫");
article.setContent("从前有一只黑猫...");
article.setCreateTime(new Date());
article.setUpdateTime(new Date());
int result= mapper.insertArticle(article);
log.info("插入条目: "+result);
}
}从打印结果上看到,我们确实插入成功了.

注意看预编译的SQL语句, 因为我们并没有对article的authorId等成员变量进行设置,所以动态生成的SQL语句中也没有出现这些字段.
但是这段代码有个Bug,童鞋们可以仔细思考一下,如果我没有设置插入文章的updateTime值会产生什么后果?
不妨来试试.
@Test
void insertArticle() {
Article article=new Article();
article.setTitle("白猫不喜欢黑猫");
article.setContent("从前有一只白猫...");
article.setCreateTime(new Date());
int result= mapper.insertArticle(article);
log.info("插入条目: "+result);
}
可以看到,程序抛出了异常,因为()中多了两个','
肯定有聪明的小朋友会说,如果将','放在字段前面是不是就不会产生这种情况了?(见下图)

如果这样编写SQL语句,当用户没有输入title字段时,同样会产生多余的','
那么该如何去掉这个顽固的','呢?既然一个标签不够,我们就使用两个标签来解决~
2.3 标签
先来讲解一下
标签的用法---- 标签有四个属性:
- prefix: 表示前缀,如果trim标签内有内容,编译的SQL语句就会自动加上这个前缀
- suffix: 表示后缀,如果trim标签内有内容,编译的SQL语句就会自动加上这个后缀
- prefixOverrides: 如果整个语句块的前缀为该属性的值,则将这个前缀去除
- suffixOverrides: 如果整个语句块的后缀为该属性的值,则将这个后缀去除
结合代码,更好理解~
现在我们重新写一下insertArticle方法.
insert into article
title
content,
author_id,
create_time,
update_time,
values
#{title},
#{content},
#{authorId},
#{createTime},
#{updateTime}
再来运行一下刚才的测试方法.
@Test
void insertArticle() {
Article article=new Article();
article.setTitle("白猫不喜欢黑猫");
article.setContent("从前有一只白猫...");
article.setCreateTime(new Date());
int result= mapper.insertArticle(article);
log.info("插入条目: "+result);
}

可以看到,这次即使没有给updateTime变量赋值,我们也成功插入了.
下面来仔细对比一下xml文件和动态生成的SQL语句.

可以发现,即使我们没有设置updateTime的变量值,但是设置了createTime的值,createTime字段后面的 ',' 却被删除了,这就是suffixOverrides的功劳.
同样,每个trim语句块的前后都有(),这是因为我们设置了suffix和prefix.
那么,如果trim语句块中没有内容会怎样呢?我们来测试一下.
![]()
可以从打印的SQL语句中看到,trim标签中的prefix和suffix并没有添加.
2.4 标签
标签有如下特性:
- 如果
标签中没有内容,where也不会在SQL语句中存在 - 如果
标签中有内容,会自动在该语句块的最前面加上where 内语句块会自动去掉最前面的and
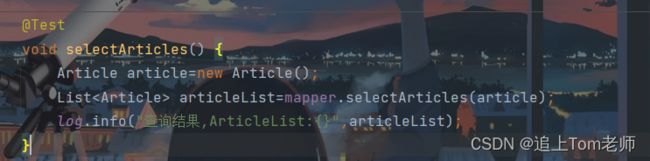
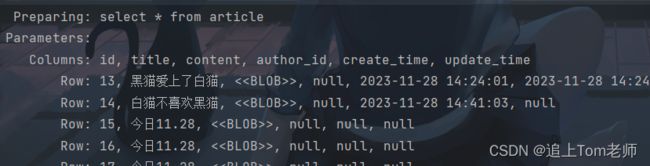
现在在ArticleMapper中编写selectArticle方法.
List selectArticles(Article article); 重点来了~来看看where标签是怎么使用的吧!
先来看看如果不使用动态SQL该怎么编写.(为了简便,这里的查询只设置了三个条件)
现在我们根据原始的SQL语句编写带有
生成对应的测试方法并运行
@Test
void selectArticles() {
Article article=new Article();
article.setContent("昨日11.27");
List articleList=mapper.selectArticles(article);
log.info("查询结果,ArticleList:{}",articleList);
} 
来对比一下xml中方法的实现和实际运行时编译的SQL语句.
 可以看到,where语句块自动删除了最前面的and.
可以看到,where语句块自动删除了最前面的and.
同学们想一想,如果我们输入的参数中所有字段均为Null,是不是就相当于查询article表的全部内容?
来实践一下~
 可以看到,当
可以看到,当
实际上,根据where标签的特性,我们可以使用

测试方法请读者自行编写.
2.5 标签
标签用在uodate语句中,具有以下特性:
- 当
标签中没有内容时,set也不会存在于SQL语句中 - 如果
标签中有内容,会自动在该语句块的前面加上set - set后面的语句块会自动去掉末尾的','
结合代码更好地理解一下~
现在ArticleMapper中定义一个updateArticle方法
int updateArticleById(Article article);在xml文件中实现这个方法,下面是不使用标签时的update语句.

如果换成
update article
title=#{title},
content=#{content},
author_id=#{authorId}
where id=#{id}
生成对应的测试方法并运行.
@Test
void updateArticleById() {
Article article=new Article();
article.setContent("今天开始努力敲代码");
article.setId(15);
log.info("更新条目: "+mapper.updateArticleById(article));
}
对比一下生成的SQL语句和xml文件中方法的实现.
 可以看到,set标签自动删除了语句块中末尾的","
可以看到,set标签自动删除了语句块中末尾的","
如果语句块为空,
@Test
void updateArticleById() {
Article article=new Article();
// article.setContent("今天开始努力敲代码");
article.setId(15);
log.info("更新条目: "+mapper.updateArticleById(article));
}![]()
从打印的语句中看到,set也不存在,但实际上,这种情况是不可能发生的,如果我们要更新某个字段,就必然输入该字段更新后的值.
2.6 标签
标签通常用于批量操作,我们可以使用这个标签遍历java中的某个数据集合,进行指定操作. 下面列举该标签的四个属性:
- collection: 该属性的值为传入的参数(类型可以是List,Set,Map或者数组等)
- item: 给传入集合的每个元素进行统一命名,命名的值是item的值(相当于Java语法中的for-each,要给每个从集合中取出的元素命名才能拿到该对象)
- open: 标签内语句块要添加的前缀
- close: 标签内语句块要添加的后缀
- separator: 各个元素之间要添加的分隔符
下面使用一个SQL语句来说明一下:
target: 查询id为13,14,15,16的article
可以看到,上图中的查询语句中,我们传入的数据集合是13,14,15,16,每个元素之间用","分割,in后面的语句块中,需要在数据集合前后加上().

下面来演示一下批量删除操作,先在ArticleMapper中定义一个方法
int deleteArticle(List ids); 在xml文件中写具体实现,下面先来写如果没有使用

下面是使用
delete from article where id in
#{id}
生成对应的测试方法并进行测试.
@Test
void deleteArticle() {
List ids=new ArrayList<>();
ids.add(14);
ids.add(16);
ids.add(18);
int result= mapper.deleteArticle(ids);
log.info("删除条目: "+result);
} 来看一下动态生成的SQL语句.

我们不妨猜一下,如果传入的集合中没有值,

结果是抛出了异常,因为我们的SQL语句有误.当然
2.7 标签
回顾一下我们已经编写的动态SQL语句,同学们不难发现有很多代码是十分冗余的,比如下面这个insertArticle方法
insert into article
title,
content,
author_id,
create_time,
update_time,
values
#{title},
#{content},
#{authorId},
#{createTime},
#{updateTime}
于是乎,我们就可以使用
: 定义可重用的代码片段,里面的内容可以是语句,也可以是字段.
: 通过属性refid,指定要包含的sql片段
下面我们就来修改一下这个insertArticle方法.可以看到,重复的语句是

title,
content,
author_id,
create_time,
update_time,
接下来直接在需要使用该代码片段的地方添加一个
insert into article
运行我们之前写过的测试方法.
@Test
void insertArticle() {
Article article=new Article();
for(int i=0;i<6;i++){
article.setTitle("今日11.28");
article.setContent("昨日11.27");
int result= mapper.insertArticle(article);
log.info("插入条目: "+result);
}
}会发现没有任何不同~

2.8 使用注解进行动态SQL
在上一篇博文中,我们分别使用注解和XML的方式实现了Mapper层接口的方法,但是很容易发现,使用注解的方式会更简单,只需要在定义的方法上面编写SQL语句即可.
实际上,我们往往使用XML的方式编写动态SQL,使用注解编写简单的SQL.
因为使用注解来编写动态SQL比较麻烦.
下面简单演示一下
@Select("")
List selectArticles(Article article); 可以看到,需要在SQL语句的开头添加