从前端视角看浏览器隐身模式工作原理
大家好,我是 漫步,平常为了不让别人知道你浏览过哪些网页,一般会打开隐身模式,你知道这个原理吗?一起来看下文。喜欢记得关注我并设为星标方便及时收到更新。
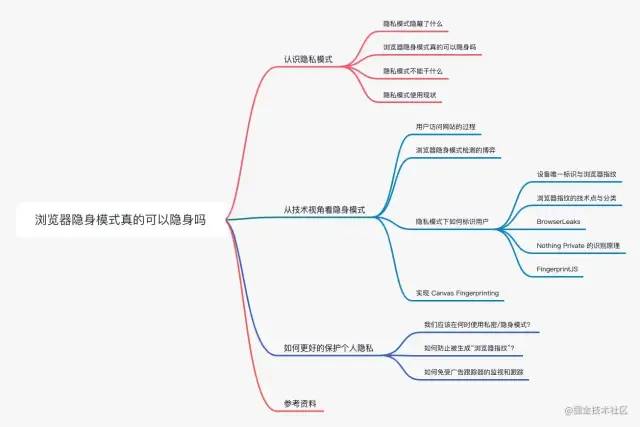
本文从科普和技术视角对浏览器隐身模式进行介绍,全文脉络如下,读者可根据兴趣选择对应章节阅读。
 IncognitoMode
IncognitoMode
认识隐私模式
隐私模式隐藏了什么
现代网络浏览器,大多数都增加了隐私浏览模式来浏览网页,旨在保护用户隐私。Chrome 称之为隐身模式;Opera、Safari 和 Firefox 中一般称为隐私浏览。这些模式以深色主题和蒙面人物图标为特征,可以给用户一种匿名浏览的印象。芝加哥大学和汉诺威莱布尼茨大学的研究人员发现,人们对隐私浏览或隐身模式存在很多误解,许多用户认为隐私浏览可以保护他们免受恶意软件、广告、跟踪脚本和互联网服务提供商 (ISP) 的监控。
其实,隐私浏览旨在避免在计算机上保留浏览会话的痕迹。因此,当你打开隐私窗口时,主浏览窗口中的 cookie、浏览历史不会被保留。当你关闭隐私浏览窗口时,你的浏览历史记录、保存的密码以及你在该窗口的文本字段中键入的内容(用户名、电话号码等)都将被擦除。这意味着使用你的计算机并启动浏览器的下一个人将无法找出你在私人浏览会话期间访问了哪些网站,即便是你自己,当下次使用这些网站未登录帐户时,你也将以新用户的身份出现。
隐私浏览是一种非常有用且方便的工具,可用于快速浏览会话,不会在你的计算机上留下痕迹。它将保护你的隐私免受使用你计算机的其他人的侵害,并减少你在访问网站时透露的一些有关你自己的信息。但是隐私浏览不会让你匿名,也不会保护你免受监视和大型技术窥探。
说到泄露隐私,很多人认为只要自己不登录、不使用 cookie,使用浏览器的无痕模式,自己的数据信息就是安全的、自己浏览了什么就只有自己知道了,那么,我们不妨直接看看浏览器官方自己的定义吧。
无痕模式(Incognito mode)是 Chrome 浏览器的一种设置,在 Chrome 浏览器里,它是这样描述的:
 incognito_mode
incognito_mode
简单来说,Chrome 无痕模式只是帮你删除了你存在本地的搜索和浏览记录,只是看起来“无痕”而已。要在 Chrome 中以隐身模式打开页面,请单击右上角的三点图标,从出现的下拉菜单中选择打开新的无痕窗口,或按 Ctrl+Shift+N。一个带有深色主题的新窗口弹出,并显示一条通知:“您已进入无痕模式”, 细则解释了隐身模式的优缺点。默认情况下,第三方 cookie(用于跨不同站点跟踪你)被禁用。
至于如何开启隐身模式,相信大多数人都是知道的,如果不知道,或者不知道某一款特定的浏览器如何开启隐身模式,可以参考下面这个链接。
How do I set my browser to Incognito or private mode?[1]
在实践中,即使在隐私模式下,网站仍然可以通过关联其他信息来发现你的身份,例如你的 IP 地址、设备类型和浏览习惯(一天中的时间、访问的页面等),隐私浏览不会隐藏任何数据。Facebook 和 Google 等大型科技公司拥有大量关于用户的信息,通过连接这些点,即使你尚未登录帐户,它们也可以识别你的身份。
浏览器隐身模式真的可以隐身吗?
通过前面的介绍,想必你的答案是确定的:不能。
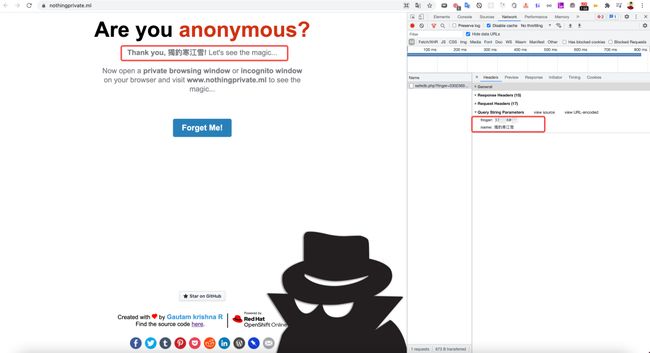
我们可以通过一个展示隐私浏览跟踪的示例网站 —— Nothing Private[2]来证明这一点。这个网站的测试方式是让你先提交一个你的标识信息,之后让你使用浏览器的无痕模式访问网站,猜猜网站会不会认出你。
这里,我先填入了“獨釣寒江雪”,很明显的,当我提交信息时,浏览器除了发送了我填写的“獨釣寒江雪”,还有一个finger字段。
 nothingprivate1
nothingprivate1
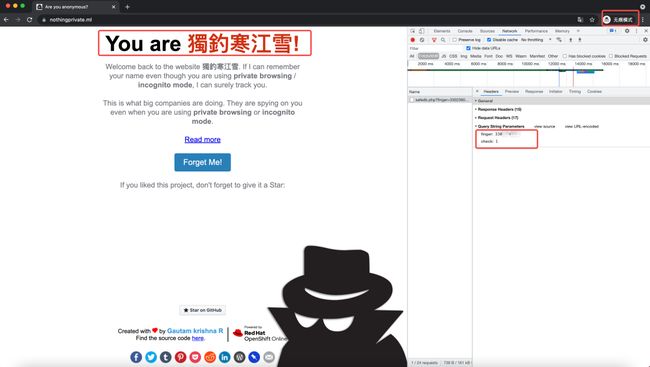
当我使用无痕模式再次打开这个网站时,浏览器又携带了相同的finger字段去服务器查询相关信息,于是,我被识别出来了。
 nothingprivate2
nothingprivate2
综上:浏览器无痕模式并不能保护你的数据信息不被网站的服务器所获取。准确的说,无痕模式就是掩耳盗铃而已。有兴趣的话,您不妨亲自去Nothing Private[3]体验一下,关于它的原理,后续章节会继续介绍。
隐私模式不能干什么
它不会保护你免受病毒或恶意软件的侵害;
它不会让你的 Internet 服务提供商 (ISP) 无法看到你上网的位置(事实上,无论你做什么,你的 ISP 几乎都可以访问你的所有浏览活动);
它不会阻止网站查看你的实际位置;
当你关闭网页时,你在隐私浏览或隐身模式下保存的任何书签都不会消失,它会被添加到你的正常浏览网页的书签中;
关闭窗口时不会删除你在私密浏览时下载到计算机的文件。
隐私模式使用现状
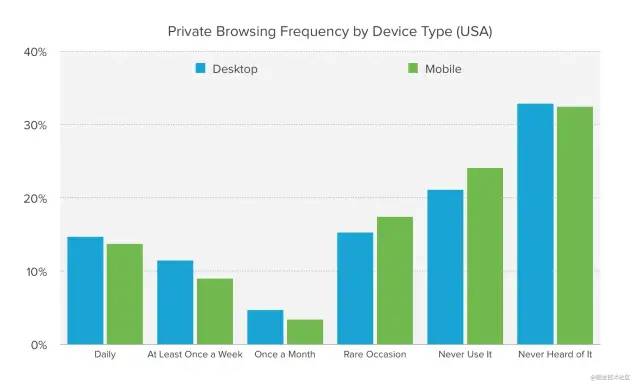
2017 年,DuckDuckGo[4]对 5,710 名美国人进行了浏览器隐私模式调查,以了解人们对隐私模式的认识以及他们如何使用这一常见的隐私功能,完整报告可参考:A Study on Private Browsing: Consumer Usage, Knowledge, and Thoughts[5]。
简单总结如下:
46% 的美国人使用过隐私浏览;
 private-browsing1
private-browsing1 人们使用隐私浏览的第一个原因是“令人尴尬的搜索”;
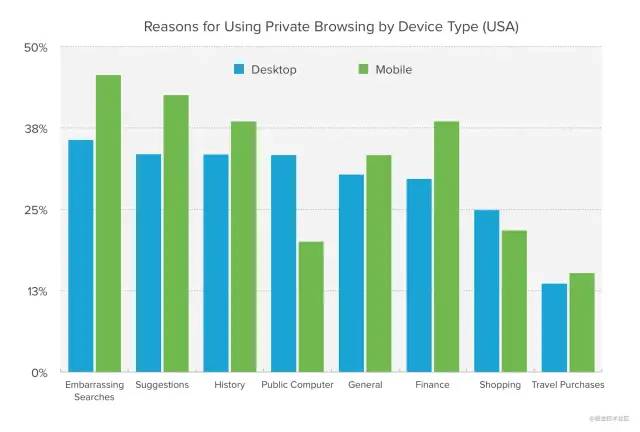 private-browsing2
private-browsing2 76% 使用隐私浏览的美国人无法准确识别其提供的隐私优势;
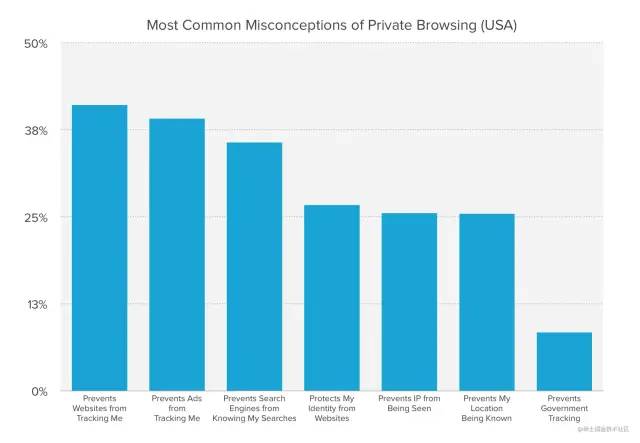 private-browsing3
private-browsing3 65% 的受访者表示,在了解隐私浏览的局限性后(隐私浏览模式只会阻止你的浏览器历史记录被记录在你的计算机上,并不会提供任何额外的保护),他们感到“惊讶”、“误导”、“困惑”或“受到伤害”;
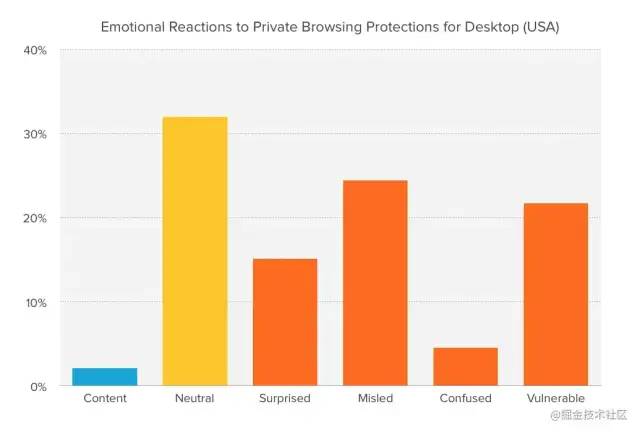 private-browsing4
private-browsing4 84% 的美国人会考虑尝试使用另一个主要的网络浏览器,如果它能提供更多功能来帮助保护他们的隐私的话。
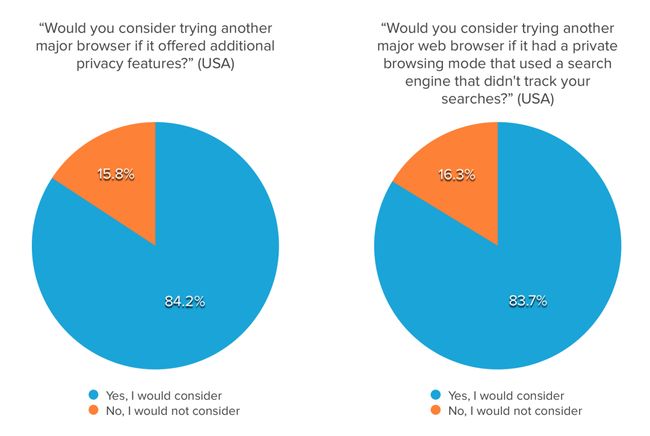 private-browsing5
private-browsing5
参考资料:Is Private Browsing Really Private?[6]
从技术视角看隐身模式
用户访问网站的过程
一般情况下,用户访问网站的过程如下图所示:
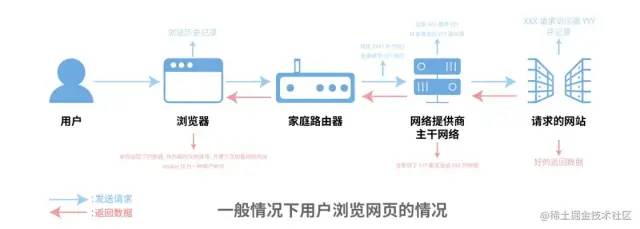 browsing_process1
browsing_process1
当一位用户浏览网页时,一般会进行以下操作:
打开浏览器,输入网址。这时候浏览器就会默默将此过程保留在历史记录中;
连接请求通过用户家中的网线,层层递进,到达互联网供应商的主干网络,再接着连接到用户请求的网站地址,这个时候就网站就能拿到用户的 IP 地址了;
网站返回数据给用户,网页大部分的内容作为临时文件被暂存在用户电脑中;
用户如果进行注册/登录,则会将用户信息保存/更新在服务器端。将 Cookie 保留在本地作为验证用户的一种方式,避免用户多次反复的登录。当然进行注册时填写的手机号、邮箱、家庭住址也会被浏览器记录,方便用户下次调用。
可以看到整个过程一般而言有 3 种数据是保存在用户的电脑上的,那就是浏览记录、临时文件与 Cookie 和表单填写的内容。而有 1 或 2 种的数据被保留在了网站那边,就是 IP 地址和用户填写的注册信息。
现在非常多的公司和学校建立了专有的网络环境,对外只显示 1 个 IP,数据返回的时候再发送到相应的内网 IP 上。雇主和学校有心想看的话还是能够知道内网的某个人浏览了什么。对于 HTTP 网站链接,雇主和学校能够完整的了解用户浏览了哪些网站,用户看了哪些内容,停留了多久,针对哪些网站进行了点击跳转等等;对于 HTTPS 网站链接,由于证书的存在和相应的验证机制,一般而言 HTTPS 解密(中间人攻击)很难发动,所以只能够了解到用户浏览了哪些网站而已。同时不恰当的网络环境也会将自己的浏览记录暴露在他人的视野中,比如免费公用的 Wi-Fi。
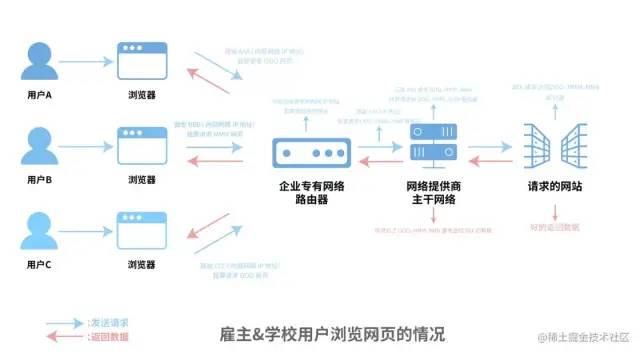 browsing_process2
browsing_process2
浏览器隐身模式检测的博弈
在 Chrome 76 之前,存在一个漏洞,许多网站利用该漏洞来检测用户是否在 Chrome 的隐身模式下访问网站。这些网站只需要尝试使用 FileSystem API 用于存储临时或永久文件的 。此 API 在隐身模式下被禁用,但在非隐身模式下存在,因此产生了差异,该差异被利用来检测用户是否正在使用隐身模式浏览网站并阻止这些用户查看网站的内容。
const fs = window.RequestFileSystem || window.webkitRequestFileSystem;
if (!fs) {
console.log('check failed?');
} else {
fs(
window.TEMPORARY,
100,
console.log.bind(console, 'not in incognito mode'),
console.log.bind(console, 'incognito mode')
);
}后来谷歌修复了一个漏洞,不幸的是,他们的修复导致了另外两种方法,仍然可以用来检测访问者何时进行私密浏览。
基于文件系统大小检测隐身模式:该方法基于为浏览器使用的内部文件系统预留的存储量。安全研究人员 Vikas Mishra发现[7],Chrome 隐身模式和非隐身模式之间存储配额存在区别,如果临时存储配额<= 120MB,那么可以肯定地说它是一个隐身窗口。这个方法主要通过
navigator.storage.estimateAPI 来进行获取和判断。
if ('storage' in navigator && 'estimate' in navigator.storage) {
const { usage, quota } = await navigator.storage.estimate();
console.log(`Using ${usage} out of ${quota} bytes.`);
if (quota < 120000000) {
console.log('Incognito');
} else {
console.log('Not Incognito');
}
} else {
console.log('Can not detect');
}通过访问时间检测隐身模式:在读取和写入数据时,内存文件系统总是比磁盘文件系统快。在隐身模式下,Chrome 会将写入 API 的数据存储在内存中,而不是像在正常模式下那样将数据持久化到磁盘。这种新的检测方法是由研究员Jesse Li[8] 发现的,它测量对浏览器文件系统的一系列写入。根据这些写入的速度,网站理论上可以确定浏览器是否使用隐身模式。防止这种检测方法的唯一方法是让隐身模式和普通模式使用相同的存储介质,以便 API 无论如何都以相同的速度运行。
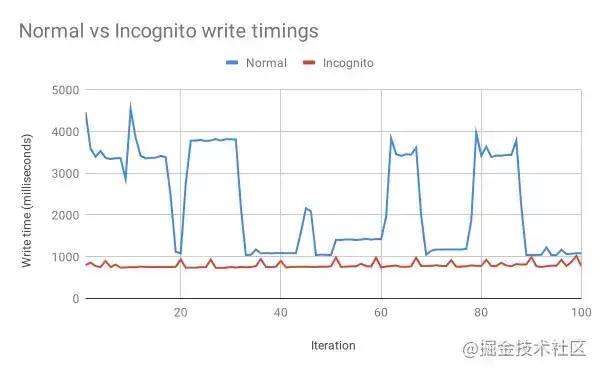 timings
timings
Chrome 开发人员看到了这两点:在 2018 年 3 月的设计文档中,他们确定了基于时间和文件系统大小检测隐私模式的风险,并进行了替代实现:只将元数据保存在内存中,并加密磁盘上的文件。这将解决网站使用时间来区分内存和磁盘存储的风险,并消除基于文件系统大小和文件系统类型(临时与持久)的差异。
然而,这样的解决方案有其自身的权衡。虽然它可以抵御隐私模式检测,但它会留下元数据:即使数据本身无法解密,它的存在也提供了隐身使用的证据。
如果我们考虑隐身模式的威胁模型,其主要目的是保护同一设备的其他用户的隐私,而不是您访问的网站的隐私,这种权衡可能是不值得的。
隐私模式下如何标识用户
设备唯一标识与浏览器指纹
我们都知道,浏览器隐身模式可以让别人无法知道你都访问了什么网站和做了什么操作,在隐身模式下,打开的网页和加载的文件不会记录到你的浏览历史记录以及加载历史记录中。在你关闭打开的全部隐身窗口后,系统会删除所有新 Cookie。但是,做为程序猿的我们,如果有类似以下场景:
当产品和数据分析师需要更精准的数据时;
当无需登陆的页面(如社区文章)需要杜绝隐身模式刷 UV 访问量时;
当无需登陆的投票站点需要杜绝隐身模式反复投票点赞时;
当无需登陆的问卷类网站,需要限制用户只能进行一次问卷提交或者第二次打开,需要展示前次提交的结果时;
...
这对我们来说,无疑是一个巨大的困扰,我们或许都知道设备唯一标识的概念,但在浏览器端,在隐身模式下,在无需用户额外授权时,我们该如何拿到设备唯一标识呢?
在开发场景下,唯一的标识一个设备是一个基本功能,可以拥有很多应用场景,比如软件授权(如何保证你的软件在授权后才能在特定机器上使用)、软件 License,设备标识,设备身份识别等。
如果说要获取设备唯一标识,也许你会想到类似 IMEI、Android ID、MAC 地址等思路,但是Android 10 中官方文档[9] 中有以下两个表述:
从 Android 10 开始,应用必须具有
READ_PRIVILEGED_PHONE_STATE特许权限才能访问设备的不可重置标识符(包含 IMEI 和序列号)。默认情况下,在搭载 Android 10 或更高版本的设备上,系统会传输随机分配的 MAC 地址。
一个电脑可能存在多个网卡,多个 MAC 地址,MAC 地址另外一个更加致命的弱点是,MAC 地址很容易手动更改。
至于 Android ID,则不具有真正的唯一性,ROOT、刷机、恢复出厂设置、不同签名的应用等都会导致获取的 Android ID 发生改变,并且不同厂商定制的系统的 BUG 会导致不同的设备可能会产生相同的 Android ID。
其他一些获取设备唯一标识的方法,这篇文章有比较全面的论述:
获取设备唯一标识(Unique Identifier):Windows 系统[10]
广告商是如何追踪我们?日常使用手机该怎样保护隐私[11]这篇文章有一张图则是一个更好的汇总:
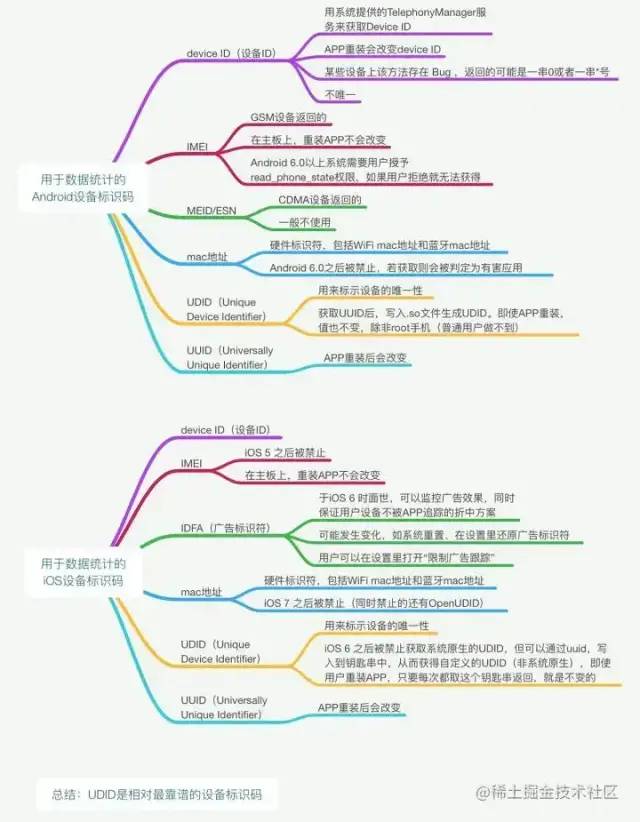 identifying
identifying
而如果回到我们前端场景下,以上这些方法又多了很多局限性,比如有的需要特许权限,有的需要依赖于原生开发的配合,那么,有没有一种只需要前端参与,也可以获得不错的准确率的唯一标识方案呢? —— 此时就到了浏览器指纹登场的时候了。
FingerPrint 即我们常说的指纹识别,使用手指和拇指前端的纹理按下的纹印来鉴定身份。指纹是鉴别身份的一种可靠的方法,具有唯一性,因为每个人的每个指头上的纹理排列各不相同而且不因发育或年龄而改变。而浏览器指纹是指仅通过浏览器的各种信息,如 CPU 核心数、显卡信息、系统字体、屏幕分辨率、浏览器插件等组合成的一个字符串,就能近乎绝对定位一个用户,就算使用浏览器的隐私窗口模式,也无法避免。
这是一个被动的识别方式。也就是说,理论上你访问了某一个网站,那么这个网站就能识别到你,虽然不知道你是谁,但你有一个唯一的指纹,将来无论是广告投放、精准推送、安全防范,还是其他一些关于隐私的事情,都非常方便。
浏览器指纹的技术点与分类
基本指纹:浏览器基本指纹是任何浏览器都具有的特征标识,比如 UserAgent、屏幕分辨率、CPU 核心数、内存大小、浏览器插件及扩展、浏览器设置、语言、硬件类型、操作系统、时区、地理位置、DNS、SSL 证书等众多信息,这些指纹信息“类似”人类的身高、年龄等,有很大的冲突概率,只能作为辅助识别。可以在这个网址[12]进行查看本地浏览器的基本特征。
高级指纹:浏览器高级指纹与基本指纹的区别是:基本指纹就像是人的外貌特征,外貌可以用男女、身高、体重区分,然而这些特征不能对某个人进行唯一性标识,仅使用基本指纹也无法对客户端进行唯一性判定,基于 HTML5 的诸多高级功能就能生成高级指纹了。高级指纹包括 Canvas 指纹、Webgl 指纹、AudioContext 指纹、WebRTC 指纹、字体指纹等;
综合指纹:零散的指纹信息并不能真正的定位到唯一用户,并不能用来代表一个用户的唯一身份(用户指纹)。综合指纹是指将所有的用户浏览器信息组合起来,就可以近乎 99%以上的准确率定位标识用户。将基本指纹和高级指纹组合起来就可以生成综合指纹(用户指纹),这样就可以达到接近 99%以上定位唯一用户了。
更多关于高级指纹的细节和原理,可以通过探讨浏览器指纹[13]这篇文章进行了解。
BrowserLeaks
长期以来,人们一直认为 IP 地址和 Cookie 是用于在线跟踪人员的唯一可靠数字指纹。但过了一段时间,当现代网络技术允许感兴趣的组织在他们不知情且无法避免的情况下使用新方法来识别和跟踪用户时,事情就失控了。
BrowserLeaks[14]就是关于浏览隐私和网络浏览器指纹的。在这里,你将找到一个 Web 技术安全测试工具库,这些工具将向你展示哪些类型的个人身份数据可能会被泄露,以及如何保护自己免受此类泄露。这个网站提供了包括 IP 地址、地理位置、Canvas、WebGL、WebRTC、字体等多种类型指纹的查看及其基本原理概述。
 fingerPrint
fingerPrint
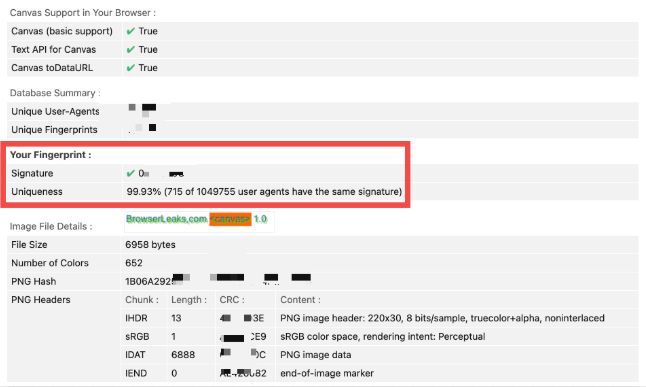
如果你对其中的技术原理很感兴趣,可以进入BrowserLeaks[15],点击对应卡片标题进行查看和了解,比如 HTML5 Canvas Fingerprinting[16]页面,会给出你的 Canvas 指纹及其唯一性率等信息。
Nothing Private 的识别原理
前面的章节「浏览器隐身模式真的可以隐身吗?」中介绍了Nothing Private[17]这个站点的测试结果,我们也看到,在提交信息和校验的时候,请求会携带一个finger字段,这个字段就可以被认为是“浏览器指纹”。
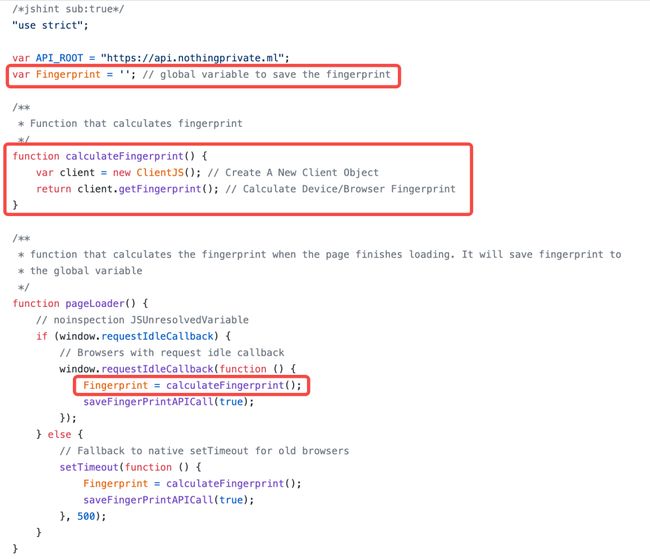
查看 GitHub 上Nothing Private 的源码[18]可以发现,Nothing Private 实现“浏览器指纹”的核心逻辑如下:
 fingerprint1
fingerprint1
显而易见,Nothing Private 使用 ClientJS[19](用纯 JavaScript 编写的设备信息和数字指纹)的浏览器指纹识别功能来获取你的 Web 浏览器的指纹,核心方法在于getFingerprint。当你提交表单时,此指纹与你填写的标识一起保存在使用 PHP 作为后端的 MySQL 数据库中。下次你访问该网站时,你的浏览器指纹将与数据库中的列匹配,并返回你填写的标识。
ClientJS 当前用于生成指纹的数据点包括:
user agent, screen print, color depth, current resolution, available resolution, device XDPI, device YDPI, plugin list,
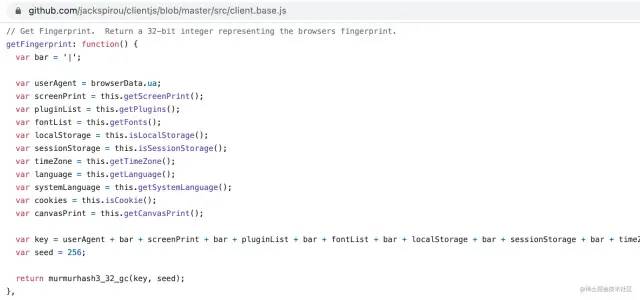
font list, local storage, session storage, timezone, language, system language, cookies, canvas print我们还是浏览一下 ClientJS 的`getFingerprint`基本逻辑[20]:
 fingerprint2
fingerprint2
我们发现,getFingerprint会获取 UA、cookie、本地存储、canvas 指纹等信息,再经过Murmur Hash 算法加密,最终返回一个可以唯一标识浏览器设备的“浏览器指纹”。
MurmurHash 是一种非加密型哈希函数,适用于一般的哈希检索操作。 由 Austin Appleby 在 2008 年发明, 并出现了多个变种,都已经发布到了公有领域(public domain)。与其它流行的哈希函数相比,对于规律性较强的 key,MurmurHash 的随机分布特征表现更良好。
ClientJS 官网地址[21]
FingerprintJS
FingerprintJS 是一个快速的浏览器指纹库,纯 JavaScript 实现,没有任何依赖。默认情况下,使用 Murmur Hash 算法返回一个 32 位整数,Hash 函数可以很容易地更换。同时,他也很轻量:开启 gzipped 后只有 843 bytes,匿名识别网络浏览器的准确率高达 94%。
FingerprintJS 的使用也比较简单:
import FingerprintJS from '@fingerprintjs/fingerprintjs';
// 应用启动时初始化:Initialize an agent at application startup.
const fpPromise = FingerprintJS.load();
(async () => {
// Get the visitor identifier when you need it.
const fp = await fpPromise;
const result = await fp.get();
// This is the visitor identifier:
const visitorId = result.visitorId;
console.log(visitorId);
})();更多关于 fingerprintJS 的信息,可以参考:
fingerprintJS 介绍与使用[22]
fingerprintJS - GitHub[23]
fingerprintJS - 官方文档[24]
上面这些方法,能获得九成以上意义的唯一浏览器指纹,也许并不能完全真的唯一,因为比如重写相关 canvas 方法、使用类似猫头鹰浏览器[25]等特殊浏览器还是会使得相关方法失效,但是技术手段更多时候只是一个通用意义上的解决方案,增加破解的壁垒和成本,我认为支持常用场景下的开发是足够的了。
有了唯一的浏览器指纹,我们就可以在类似统计 UV、点赞、投票的时候,带上相关指纹,自然就可以在极大程度上辨别用户是否存在刷票、刷访问量的行为了,不过,浏览器指纹技术终归是把双刃剑,在解决以上问题的同时,难免会给用户带来更多的信息泄漏困扰。
实现 Canvas Fingerprinting
**Canvas Fingerprinting(Canvas 指纹)基于 Canvas 绘制特定内容的图片,使用 canvas.toDataURL()方法返回该图片内容的 base64 编码字符串。对于 PNG 文件格式,以块(chunk)划分,最后一块是一段 32 位的 CRC 校验,提取这段 CRC 校验码便可以用于用户的唯一标识。**Canvas 利用 HTML5 canvas API 和 JavaScript 来动态生成你想要的图像。和其它跟踪技术一样,这种方法已被成千上万的网站采用了,包括我们熟知的广告领域。
下面是 Canvas 指纹的一个简单实现,原理其实比较简单,不理解的地方可以参考注释:
// PHP 中,bin2hex() 函数把 ASCII 字符的字符串转换为十六进制值。字符串可通过使用 pack() 函数再转换回去
// 下面是PHP 的 bin2hex 的 JavaScript 实现
function bin2hex(s) {
let n,
o = '';
s += '';
for (let i = 0, l = s.length; i < l; i++) {
n = s.charCodeAt(i).toString(16);
o += n.length < 2 ? '0' + n : n;
}
return o;
}
// 获取指纹UUID
function getUUID(domain) {
// 创建 PHP bin2hex() 函数[26]
测试结果表明,同一浏览器访问该域时生成的 CRC 校验码总是不变。可以简单理解为同样的 HTML Canvas 元素绘制操作,在不同的操作系统不同的浏览器上,产生的图片内容其实是不完全相同的。出现这种情况可能是有几个原因:
在图片格式上,不同 web 浏览器使用了不同的图形处理引擎、不同的图片导出选项、不同的默认压缩级别等。
在像素级别来看,操作系统各自使用了不同的设置和算法来进行抗锯齿和子像素渲染操作。
即使是相同的绘图操作,最终产生的图片数据在 hash 层面上依然是不同的。
如何更好的保护个人隐私
我们应该在何时使用私密/隐身模式?
隐身模式就是能够在多人共用电脑的时候保护自己的浏览记录不被其他公用的人看到,以及保护自己的账户不被恶意登录。此外隐私模式还能保护我们不被恶意广告所困扰。
即使你使用的是隐私浏览模式,也并不意味着你可以做一些邪恶的事情;
也许你想将你的工作和个人生活分开;
你可能会共用一台计算机或设备,并且你不希望你的家人、朋友、同事窥探;
你可能正在购买礼物,但你不希望任何东西破坏可能的惊喜;
或者,也许你只是想限制公司收集有关你的数据量,并且你重视隐私;
使用公共场所的电脑设备时。
如何防止被生成“浏览器指纹”?
上一大节我们探讨了网站如何使用各种技术来生成“浏览器指纹”来标识唯一用户,那么下面我们来说说,如何避免被网站“生成”唯一用户指纹。
常用的手段是,通过浏览器的扩展插件,阻止网站获取各种信息,或者返回个假的数据,这种方式是在网页加载前就执行一段 JS 代码,更改、重写、HOOK 了 js 的各个函数来实现的,因为 JS 的灵活性给这种方式提供了可能。但是这种方式始终是表层的,使用 JS 修改是能防止大部分网站生成唯一指纹,但是是有手段可以检测出来是否“作弊”的。
更好的手段是从浏览器底层做处理,从浏览器底层修改 API 使得这些在 js 层获取的信息并不唯一,不管如何组合都不能生成一个唯一的代表用户的指纹。比如:猫头鹰浏览器[27]。
猫头鹰浏览器是基于 chromium 代码修改编译的浏览器,从底层对各种 API 做了修改,可以交给用户自定义返回各种数据,比如 Canvas、Webgl、AudioContext、WebRTC、字体、UserAgent、屏幕分辨率、CPU 核心数、内存大小、插件信息、语言等信息,这样就可以完全避免被“生成”唯一用户指纹了。因为在线公司、广告商和开发人员喜欢跟踪你的在线活动和操作,以便为你提供有针对性的广告,通常,大家认为这是侵犯用户隐私的。
如何免受广告跟踪器的监视和跟踪
禁用第三方 Cookie。Chrome 2020 年推了一个叫做 SameSite Cookie 的东西,目的是为了减少第三方 Cookie 的发送,但网站所有者仍然有能力关掉它(SameSite=None)。而 Chrome 的终极目标,是要在 2022 年完全消灭第三方 Cookie,像 Safari 和 Brave 已经做的那样,SameSite Cookie 就是第一步。
禁用 JavaScript 脚本,蒽,这个在现今,估计还是算了。在现在前后端分离的开发模式下,大多数网站在禁用 JavaScript 后,将什么也没有,得,烦恼没有了,网站内容也没有了,一了百了~
要隐藏你的互联网流量以免受监控和跟踪,你可以使用虚拟专用网络 (VPN)。你的 ISP 会知道你正在使用 VPN,但它无法确定你正在访问哪些网站。VPN 服务通过远程服务器路由流量,因此看起来你是从另一个位置或多个位置进行浏览。不过,VPN 提供商可以跟踪你上网的位置,因此最好找一家你可以信任的公司来删除或锁定你的浏览活动。VPN 不会阻止来自广告商的第三方 cookie,但这些 cookie 将无法准确识别你的位置,从而使广告跟踪器难以或不可能有效。
友情提示:VPN 是中立性的技术,使用由相关单位构建并且登记备案的 VPN 不属于违法行为,而私自搭建的则属于违法行为(即使用非法 VPN 是违法的);如果只是使用 VPN 连接国际网络进行必要的工作、查阅必要信息,是不属于违法行为的;如果使用 VPN 在国际互联网制作、复制、查阅和传播违法信息的,则需要依法追究违法责任。
Tor 浏览器可以真正掩盖你的在线活动。TorBrowser 是一款匿名访问网络的的软件,用户通过 Tor 可以在因特网上进行匿名交流。为了实现匿名目的,Tor 把分散在全球的计算机连起来形成一个加密回路。当你通过 Tor 网络访问互联网时,你的网络数据会通过多台电脑迂回发送,就像洋葱包裹其核心那样掩饰你的网络活动,使得跟踪流量变得困难,你访问的网站真的不知道你在哪里,只知道你的请求路由通过的最后一个服务器的大致位置;信息传输在每一步都被加密,无从得知你所处位置和信息传输目的地。因此 Tor Browser 也被称为洋葱浏览器,Tor 浏览器在关闭时会删除所有 cookie,但是即使 Tor 代理也不会阻止第三方广告商在你的浏览器中注入 cookie。
参考资料
探讨浏览器指纹[28]
浏览器的隐私模式,真的能完全保护我们的隐私吗?[29]
Google Chrome Incognito Mode Can Still Be Detected by These Methods[30]
Private Browsing Won't Protect You From Everything[31]
本文首发于个人博客[32],欢迎指正和star[33]。
关于本文
作者:獨釣寒江雪
https://juejin.cn/post/6994228279909548062
参考资料
[1]
https://www.computerhope.com/issues/ch001378.htm
[2]https://www.nothingprivate.ml/
[32]https://king-hcj.github.io/2021/08/08/Incognito-Mode/
[33]https://github.com/king-hcj/king-hcj.github.io
- EOF -
推荐阅读 点击标题可跳转
记一次高级前端开发工程师面经
一年半经验的前端面经总结
前端面经 - 看这篇就够了
觉得本文对你有帮助?请分享给更多人
推荐关注「前端开发博客」,提升前端技能
我是漫步,分享技术,不止前端,下期见~
文中如有错误,欢迎给我留言,如果这篇文章帮助到了你,欢迎点赞、在看和关注。你的点赞、在看和关注是对我最大的支持!
创作不易,你的每一个点赞、在看、分享都是对我最大的支持!❤️