【项目实战】自主实现 HTTP 项目(四)——处理请求和构建相应

目录
回应报文的了解
深入理解两个方法
URL传参
建立回应
路径问题
web根的目录问题
自定义根目录的添加
编辑
目标路径下文件的存在性问题
stat接口引入
目标路径下文件的属性问题
路径下是目录
路径下是可执行程序
初识CGI
方法的大写转换
回应报文的了解
在前面的章程之中,我们学习到了如何来进行读取向客户端发来的请求以及提取这些请求当中的有效信息进行分析,而本篇我们将介绍的是如何来对请求的客户端构建相应的响应。这里我们可以看一下一般网站是如何对我们的客户端发来相应的,我们这里以百度为例。

在这里我们用我们用Xshell来去链接一下百度的官网,我们看到的一下的情况

我们看到的是,和我们的请求报文的结构类似,分别是回应行,回应报头,以及空行之后的回应正文,而整文部分的代码就是我们看到的百度页面的前端代码,这就是百度给我们发来的一个相对标准的一个回应。
深入理解两个方法
在互联网刚刚开始的时候,我们最开始是让客户端去服务器上获取资源,而随着时代的发展,我们渐渐的可以把客户端的相关的信息发送到服务端上,真正的实现“人机交互” 。
所以,我们现在所有的上网行为,宏观上分为两种情况:
1.浏览器想从服务器拿下某种资源(打开网页、下载等)
2.浏览器想把自己的数据上传到服务器(上传视频,登录,注册等)
而浏览器拿下资源的方法,为GET方法,而上传数据到服务器的方法分为两个 分别是POST、和GET。

上传数据就需要传参,而这两种方法传参的方式一样吗?
不一样,POST是通过正文传参的,而GET是通过URL传参的。
URL传参
那么什么是url传参呢,我们以我们平时访问搜索来举一个例子,比如我们在搜索框中搜索NBA,当点击搜索以后,我们看到的是如下的情况。

我们没有对网址做出任何的改变,只是在框中输入了 NBA 然后搜索,结果自动给我们匹配了这么一个长串网址,我们可以把网址复习下来分析一下。

我们可以看到,前面是百度的网址,而在 ?之后就是我们要进行的传参,通俗理解就是我们要输入NBA搜索的这个请求提交给客户端所要传入的资源。那么我们又知道了一件事,关于GTE方法的请求传参是在网址之后,以?作为分隔符,其后面的内容就是用户提交的请求参。
那么这里我们其实又有了一个疑问,就是我们平时在上传自己的资料的时候,也需要等待一段时间,这段时间是用来做什么的呢?
是让http或者其他程序对提交上来的参数进行读取和分析以及数据处理!
建立回应
void BuildHttpResponse()
{
std::string _path;
auto &code = http_response.status_code;
if(http_request.method !="GET" && http_request.method !="POST"){
//非法请求
LOG(WARNING,"method is not right");
code = NOT_FOUND;
goto END;
}
if(http_request.method == "GET"){
size_t pos = http_request.uri.find('?');
if(pos !=std::string::npos){
Util::CutString(http_request.uri,http_request.path,http_request.query_string,"?");
}
else {
http_request.path = http_request.uri;
}
}
class HttpRequest{
//....
//以下为新增
std::string path;
std::string query_string;
};
说明:我们想在主要处理的只处理GET和POST的两个方法,如果不是这两个方法,那么这个时候我们就把它看作非法请求,让错误码等于404,然后接下来就是分析方法了,如果是POST方法,因为POST是正文传参,在报头请求资源中暂时没有我们需要提取的参数,如果是GET方法,这里我们就要注意了,我们需要在请求资源uri中分离其路径和资源队列,我们刚刚已经讲到了,其两者之间的分隔符,是以?来分离,所以我们就调用之前我们写过的分离字符串的函数来进行分割。
//之前写过的分割字符串的函数
static bool CutString(const std::string &target, std::string &sub1_out, std::string &sub2_out, std::string sep)
{
size_t pos = target.find(sep);
if(pos != std::string::npos){
sub1_out = target.substr(0, pos);
sub2_out = target.substr(pos+sep.size());
return true;
}
return false;
}这里我们调用Find函数来进行查找,如果找到了,说明这个GET方法的报文是有参数要传的,如果没有找到,这么这个报文就是一个普通的报文,其请求资源就是一个单纯的路径,这个时候我们就把整个请求资源当作路径就可以了

这个时候我们做一个简单的测试,我们看看是否请求资源中的路径和资源队列实现了分离,测试的代码如下(测试后代码删除):
std::cout<<"debug: uri:"<我们启动程序:

我们用浏览器对服务器进行一下访问
我们可以看到的是,?前后的路径和资源队列实现了分离,证明了我们的程序没有什么问题。
路径问题
web根的目录问题
这个地方疑问又来了,在我们之前的博客里也提到过这个问题,就是说 /a/b/c 这路径,其中a前面的/是表示从根目录下寻找a吗?换一种说法,这里的路径,表明了是从根目录吗?我们当时给出的答案不一定。
那么为什么说是不一定呢,实际上web的根目录是需要我们自己指明的,在我们没有指明的情况下,访问的就是我们的根目录,如果我们在想要自定义web的根目录是我们指定的某一路径下, 这个时候就不再是从真正的根目录开始了。
自定义根目录的添加

在这里我们自己定义一个根目录,把它作为web的根目录,当我们想要访问任何资源的时候,前面都要添加上这一路径。
这个地方又忽略了一个点,我问大家一个问题,如果我要访问的是不是一个具体的资源,而是一个目录,这个时候你应该给我返回什么,是这个目录下全部的内容吗?显然不是的,返回的是这个目录下的目录主页,大家需要注意的是,其实每一个目录下面其实都有一个目录主页,我们每次打开目录看到的内容,其实都是目录“index.html”文件。

也就是说,当我们最终访问的是一个目录而不是一个文件的时候,我们需要自动添加上其访问的是目录主页。
#define HOME_PAGE "index.html"
void BuildHttpResponse()
{
_path = http_request.path;
http_request.path = WEB_ROOT;
http_request.path +=_path;
if(http_request.path[http_request.path.size()-1] =='/'){
http_request.path +=HOME_PAGE;
}目标路径下文件的存在性问题
这个时候还有一个问题,那就是我们如何保证我们访问路径下文件一定存在呢,如果不存在我们将如何处理?
这个问题我们需要分情况讨论:
1.目标路径下是一个目录(特征路径结尾后是‘/’的,如上加主页进行处理)
2.目标路径下不存在文件
3.目标路径下有一个可执行性的文件
这里我们想要查看的是目标路径下是否有文件,若有是什么类型的文件,这个时候我们就需要调用系统的接口,来帮我进行检测。
stat接口引入
这个接口,可以帮我们探测这个资源是否存在,如果资源存在,那么就返回零,下图是对这个stat接口内容的介绍。

path:表示你要访问的这个路径
buf:表示定义的stat定义的的对象
返回值:在资源存在的情况下返回0。

大家可以看到,stat定义的很多变量,包括文件的权限,文件的编号、文件的连接数等等,这个地方我们需要注意,只有文件的权限我们得到了,才能说明这个是一个有效的文件,否则就相当于我们在这个路径下找不到任何文件,那么这个就是一个不合法路径。
目标路径下文件的属性问题
路径下是目录
这里我们又有疑问了,我们单单知道是否有资源是不够的,我们还需要进行对资源的判断,如果是目录、可执行程序文件的话, 我们需要进行其他操作,这个时候我们还需要引入一个东西来进行文件属性的判断。

顺着刚才的介绍往下翻,这个地方给我们提供了类似于宏的东西,我们就用这个接口来判断是否是一个目录。
if(stat(http_request.path.c_str(),&st) == 0)
{
//说明资源是存在的
if(S_ISDIR(st.st_mode)){
//说明请求的资源是一个目录,不被允许的,需要做一下相关处理
//虽然是一个目录,但是绝对不会以/结尾!
http_request.path += "/";
http_request.path += HOME_PAGE;
}
if( (st.st_mode&S_IXUSR) || (st.st_mode&S_IXGRP) || (st.st_mode&S_IXOTH) ){
//特殊处理
}
}
else{
//说明资源不存在的
std::string info = http_request.path;
info +="Not Found!";
LOG(WARNING,info);
code = NOT_FOUND;
goto END;
}确认是目录之后,我们就在其后面添加/,并且添加其文件主页
路径下是可执行程序
第二个问题,如果该路径下面是一个可执行程序,那么这个时候我们应该如何来做呢,还是看一下我们刚才看过的那几个系统函数接口。
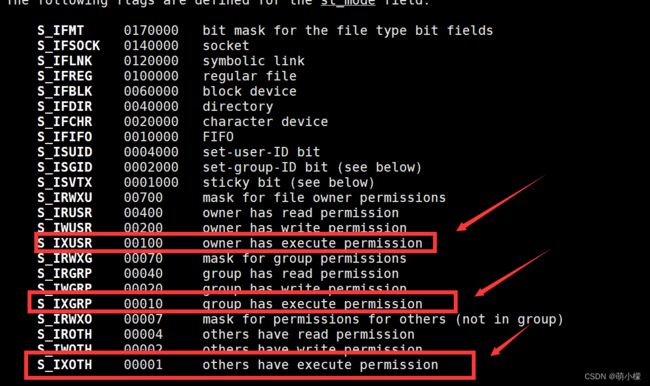
我们可以看到,三组可执行程序权限,如果其中有一个判定为可执行性文件,那么这个文件就是可执行的文件,我们这个时候就应该去做一下特殊的处理。
大家可以发现的是,这三个的值都是后三位中有1的值,我们只需要mode去与这三个进行按位与的操作,直接可以获得这三个值是否存在为可执行文件的执行权限。
if(stat(http_request.path.c_str(),&st) == 0)
{
//说明资源是存在的
if(S_ISDIR(st.st_mode)){
//说明请求的资源是一个目录,不被允许的,需要做一下相关处理
//虽然是一个目录,但是绝对不会以/结尾!
http_request.path += "/";
http_request.path += HOME_PAGE;
stat(http_request.path.c_str(), &st);
}
if( (st.st_mode&S_IXUSR) || (st.st_mode&S_IXGRP) || (st.st_mode&S_IXOTH) ){
//特殊处理
}
}
else{
//说明资源不存在的
std::string info = http_request.path;
info +="Not Found!";
LOG(WARNING,info);
code = NOT_FOUND;
goto END;
}初识CGI
什么是CGI呢,我们在刚刚说过,在最开始我们只能从服务端上下载数据,而不能提交数据给服务端,而现在慢慢的我们逐渐实现了这一点,但是很多时候http只能实现最简单的请求分析,而真正要去完成的事是由http来调用可执行程序完成,调用完成之后返回结果,http再把结果发送给客户端,在这个过程中http几乎不进行任何的处理,这个机制就叫做CGI。

简而言之,我们的CGI机制就是 调用目标程序,传递目标数据,拿到目标结果。
class HttpRequest{
//...
bool cgi;
//...
};
void BuildHttpResponse()
{
std::string _path;
struct stat st;
auto &code = http_response.status_code;
if(http_request.method !="GET" && http_request.method !="POST"){
//非法请求
LOG(WARNING,"method is not right");
code = NOT_FOUND;
goto END;
}
if(http_request.method == "GET"){
size_t pos = http_request.uri.find('?');
if(pos !=std::string::npos){
Util::CutString(http_request.uri,http_request.path,http_request.query_string,"?");
}
else {
http_request.path = http_request.uri;
}
}
else if(http_request.method == "POST"){
//POST
http_request.cgi = true;
}
else {
//Do Nothing
}
_path = http_request.path;
http_request.path = WEB_ROOT;
http_request.path +=_path;
if(http_request.path[http_request.path.size()-1] =='/'){
http_request.path +=HOME_PAGE;
}
std::cout<<"debug: uri:"<说明:
1.关于CGI的具体实现,我们会在后面单独拿出来进行详细的讲解。
2.如果执行到最后我们不需要启动CGI,那么我们就返回静态网页即可,关于返回静态网页,我们在下一篇博客中会专门来讲。
方法的大写转换
在各种传参调用的过程中,我们难免可能把调用方法的字母大小写弄得不一致,而我们在判断方法的时候又是以大写统一的一个标准,这个时候我们就需要把接收到的方法进行大小写的转化。

这里我们用transform函数来进行转化,我们先做一个简单的实验。
#include
#include
#include
int main()
{
std::string method = "Get";
std::transform(method.begin(),method.end(),method.begin(),::toupper);
std::cout<<"method: "<< method < 我们编译链接,发现输出内容正好是我们大写的方法。

我们按照格式,直接应用到方法文件中即可。
#include
void ParseHttpRequestLine()
{ auto &line = http_request.request_line;
std::stringstream ss(line);
ss >> http_request.method >> http_request.uri >>http_request.version ;
auto &method =http_request.method;
std::transform(method.begin(),method.end(),method.begin(),::toupper);
LOG(INFO,http_request.method);
LOG(INFO,http_request.uri);
LOG(INFO,http_request.version);
}