什么是死锁?
什么是死锁?
看一看普通人
和高手是如何回答这个问题的
普通人
线程 A 占用对象锁 1,线程 B 占用对象锁 2
线程 A 需要继续获得对象锁 2 才能继续执行,所以线程 A 需要等待线程 B 释放对象锁 2 线程 B 需要获得对象锁 1,才能继续执行
同样也需要等待线程 A 释放对象锁 2
由于这两个线程都不释放自己已经占有的锁,导致两个线程处于无限等待状态这个就是死锁。
高手
关于这个问题
我会从几个个方面来回答
什么是死锁
**死锁(Deadlock):**是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。称此时系统处于死锁状态或系统产生了死锁。称这些永远在互相等待的进程为死锁进程。
这句话的核心点有三处:(1)“两个或两个以上的进程”:也就是说死锁必定是在并发“进程”(这里的进程可以看作是一个泛指,具体要看这个系统是什么)间产生,单个进程不会产生死锁。(2)“资源争夺”:这些并发的进程必须互相争夺资源,如果一个系统存在并发的进程,但是大家都井水不犯河水,那么也不会产生死锁。(3)造成的结果是这些进程进入一种状态,各个进程都无法继续推进,如果没有外力,这些进程无法跳出这个状态。
用通俗的话来说就是这些并发的进程在占有资源的同时又去申请对方持有的资源,但是大家又都不愿意放弃自己已经抢到的资源,所以都只能死等了。比如下面的这个场景,路口的四辆车都想从自己的路口开到对面,对面路口又都被对方占主了,大家也都不愿意倒车让路,所以都开不动了,所以这里的交通就陷入瘫痪。这就是死锁。

死锁的出现,就说明多个并发进程相互依赖形成的等待图中存在环。在此,我们主要讨论数据库事务的死锁及其处理,引用《数据库系统概念》中对等待图的精确描述:
死锁可以用称为等待图(wait-for graph)的有向图精确描述。该图由*G=(V,E)*对组成,其中V是顶点集,E是边集。顶点集由系统中的所有事务组成,边集E的每一元素是一个有序对Ti——>Tj。如果Ti——>Tj属于E,则存在从事务Ti到Tj的一条有向边,表示事务Ti在等待事务Tj释放所需数据项。
当事务Ti申请的数据项当前被事务Tj持有时,边Ti——>Tj被插入到等待图中。只有当事务Tj不再持有事务Ti所需要的数据项时,这条边才从等待图中删除。
当且仅当等待图中存在环时,系统中存在死锁。
比如下面这个场景:
#背景
create table t (a int primary key, b int);
insert into t values(1,1),(2,2),(3,3);
#用例
#session1, txn1 #session2, txn2 #session3, txn3
begin;
update t
set b = 11
where a = 1;
begin;
update t
set b = 22
where a = 2;
begin;
update t
set b = 33
where a = 3;
update t
set b = -2
where a = 2;
#waiting update t
set b = -3
where a = 3;
#waiting update t
set b = -1
where a = 1;
#deadlock
三个并发事务txn1、txn2和txn3分别持有a=1、2和3这三行数据的排他锁,然后txn1继续申请a=2这行数据的排他锁,因为已经被txn2持有,所以阻塞。同样,当txn2申请a=3这行数据的排他锁时会被txn3阻塞。这时如果txn3再去申请a=1这行数据的排他锁,等待图就会形成环,导致死锁发生。

根据EDGAR KNAPP 在《Deadlock Detection in Distributed Databases》中的总结,根据对并发系统(在此我们只讨论数据库)中请求的限制程度的不同,死锁共有以下几种模型:
1:One-Resource Model
这是最简单的死锁模型,它假设每个事务每次最多发出一个资源请求,也就是说它的等待图的中每个节点的出度最大为1,比如上面的图2。事务阻塞直到它发出的请求得到响应。因此,这种模型的死锁检测就是查找等待图中否有环存在。
2:AND Model
与One-Resource 不同的是,这种模型假设每个事务可能同时发出多个请求,这个事务阻塞直到它一次发出的多个请求都得到响应。也就是说,它允许等待图的每个节点的出度为[0, n]。比如分布式数据库中,一个事务发出的一个请求,可能需要访问多个站点才能获取全部的数据。这种模型的死锁检测和One-Resource一样也是确认等待图中是否有环存在,但不同的是,因为允许一个节点的出度大于1,所以一个事务可能同时参与到了多个环中,它要等到所有的环都被破坏才能解除死锁。
3:OR Model
它是在AND Model上进一步放宽条件,也就是说一个事务可能同时发出一个或多个请求,但是只要有一个请求得到响应,事务即可继续推进。因此,这种模型的死锁检测又和上面一种不同,在等待图中,一个节点还是允许有[0, n]个出度,也就是说,这个事务可能参与到了多个环中,只有当这个节点的所有出度所在的路径都在环中时,这个事务才进入死锁,只要有一条路径存在终点,那么这个事务就没有被死锁。
4:AND—OR Model
这是AND Model和OR Model的一种组合模型,它允许一个事务发出[0, n]个请求,这些请求中即包括AND模型请求,也包括OR模型请求。这样死锁检测更加复杂,甚至没有一个熟悉的图论模型与之对应。对这个模型来说,最容易想到的死锁检测方式,就是反复应用OR 模型的死锁检测方式进行死锁检测。因为死锁具有稳定性,虽然AND—OR进入死锁之前的状态检查十分复杂,但是只要它进入死锁,那么它的状态就不会改变。也就是说,当它形成死锁后,它的检测结果和OR模型是一样的,即各个出度都处与环中。EDGAR KNAPP还提到了一种AND—OR模型的推广模型,但是它们的表达最终结果都是一样的,而且由于在知乎中实在没有办法打出哪个符号,在此就不做介绍了,推荐大家直接阅读论文。
4:Unrestricted Model
这种模型是最通用的模型,它不限制事务的资源请求规则,由于十分复杂,在此也不做介绍。
在下文中提到的死锁,都是以AND Model为基础。
常用的死锁处理方式
现在我们已经知道,死锁就是并发事务的等待图中出现了环。那么自然而然就会有两种处理思索的思路:(1)避免在等待图中形成环(2)主动发现并破环掉等待图中的环。我们称第一种思路为死锁预防,第二种思路为死锁检测和恢复。
死锁预防
死锁预防的思路是通过特定的加解锁方式,让事务的等待图始终保持为有向无环图。实现可以从两个方面入手,一方面以数据为中心,另一方面以事务为中心。
1:以数据为中心
这种思路的一种实现是对所有的数据项强加一个次序,形成一个有向无环图(称之为数据库图),同时要求所有的事务只能按照这个次序规定的顺序给数据项加锁。这也就是《数据库系统概念》中介绍的树形协议的实现方式。
在树形协议中,只存在排他锁这一种类型的锁。每个事务Ti对一个数据项只能加一次锁。加锁规则如下:
1:Ti首次加锁可以对任何数据项进行。
2:此后,Ti对数据项Q加锁的前提是Ti当前持有Q的父项上的锁。
3:对数据项解锁可以随时进行。
4:数据项被Ti加锁并解锁后,Ti不能再对该数据项加锁。

这个协议的优点是永远不会形成死锁(因为任何事务都是在有向无环图上加锁,并且都是按顺序加锁),同时也可以在任何时候解锁(不考虑级联问题和可恢复问题的话)。但是它的局限在于在加锁之前需要知道事务访问的数据集,然后按照这个数据集的数据项的顺序加锁。但是在事务运行过程中往往是很难确定这个事务要访问的数据集的,因为不确定它后面会进行什么操作,在不能确定数据集的情况下,事务Ti只能给树根A加锁,。同时这种加锁方式会导致对不必要的数据项加锁,比如事务Ti要更新的数据集是{A,J},那么它就比需要给A、B、D、H、J都加锁,其中的B、D、H本来是不需要访问的,对它们加锁都是额外的开销。因此这种并发控制协议虽然不会产生死锁,但是会大大系统的并发度。
另一种以数据为中心的预防死锁的方式和上面这种一样还是需要获取事务需要加锁的所有数据的这个数据集,然后事务原子性地对这个数据集中的所有数据进行加锁。也就是说事务要加锁的数据,要么全部同时加锁成功,要么全都不加锁。这样,就不会出现事务Ti在占有一部分资源的情况下去申请另外的资源,也就破坏了死锁形成的条件,等待图中也不会出现环。但它的问题在上面已经提到过了,即在事务开始前很难预知事务需要对那些数据项加锁。某些比较乐观的并发控制协议,比如快照隔离,在事务提交之前,所有的写操作都缓存在事务自己的私有空间,在事务提交时,可能会用先更新者提交规则原子性地处理所有的写操作。这种先更新者提交的处理规则,根据我的理解,也可以算作是这种死锁预防思路的一种运用吧。
2:以事务为中心
这种死锁预防的思路的核心是给全局的所有的事务进行排序,在发生加锁冲突时,在给定的规则下根据事务的先后顺序做出处理。比较常见的事务排序方式是给每个事务分配一个唯一的时间戳。根据回滚事务的不同,有下面两种机制:
**wait-die机制:**这种机制基于非抢占技术。当事务Ti申请的数据项当前被事务Tj持有,仅当事务Ti的时间戳小于Tj的时间戳(即Ti比Tj老),事务Ti阻塞(即wait),否则事务Ti回滚(即die)。比如上图2中的场景,当txn1申请a=2行数据的排他锁时,因为txn1的时间戳小于txn2的时间戳,所以txn1阻塞,同理txn2也被txn3阻塞,但是当txn3申请a=1行数据的排他锁时,由于txn3的时间戳大于txn1的时间戳,所以txn3回滚,由于txn3的回滚,txn2的阻塞也结束了,最终没有产生死锁。
**wound-wait机制:**这种机制是基于抢占技术,它的处理规则和wait-die相反。当事务Ti申请的数据项当前被事务Tj持有,仅当Ti的时间戳比Tj的时间戳大(即Ti比Tj年轻),Ti才被阻塞(即wait),否则Tj回滚(即wound)。还是上图二中的场景,当txn1申请a=2行数据的排他锁时,由于txn1的时间戳小于txn2的时间戳,所以txn2被动回滚,释放掉它持有的a=2行数据的排他锁,这样txn1顺利获取到a=2行的排他锁。接着txn3申请a=1行数据的排他锁时,由于txn3的时间戳大于txn1的时间戳,所以txn3被txn1阻塞,直到txn1提交或回滚之后,txn3才能继续执行。谷歌的Spanner的死锁处理机制就是wound-wait。
这两种机制存在的问题是可能会造成不必要的回滚。比如下面的两个用例,在wait-die机制下,用例2中的txn2会自动回滚,但是这种场景并不是死锁场景。同样在wound-wait机制下,用例3中的txn2会被txn1 abort掉,尽管这个场景也不是死锁。其原因在于,这种以事务为中心的死锁预防思路,都是通过将事务排序后防止出现环形依赖,在一个有序序列中出现“环”的必要条件是出现至少一个违反这种“有序”的依赖。比如,如果规定的有序序列是升序,那么必然至少有一个降序才能构成环,比如1->2->3->1这个环种,3->1这种依赖关系就是违反规定的升序依赖的,因此要解决这种规则下的死锁,只需要避免出现这样的3->1依赖即可,如果出现,那么“1”自动abort,这就是wait-die。但是这种机制下就不能出现4->3->2->1这样的依赖关系了,虽然它不是环。同理,wound-wait机制只允许出现3->2->1这样的依赖,当出现1->3这样的依赖时,因为违反了降序,所以3会被1被动abort掉。因此它也不允许出现1->2->3这样的依赖,尽管它们也不构成死锁(即环)。
#背景
create table t (a int primary key, b int);
insert into t values(1,1),(2,2),(3,3);
#用例2
#session1, txn1 #session2, txn2
begin;
update t
set b = 11
where a = 1;
begin;
update t
set b = 11
where a = 1;
#abort self;
commit;
#用例3
#session1, txn1 #session2, txn2
begin;
begin;
update t
set b = 22
where a = 2;
update t
set b = -2
where a = 2;
#abort txn2 #commit;
commit;
死锁检测和恢复
死锁检测与恢复和死锁预防的思路不同,死锁预防是在事务执行阶段就避免形成环形依赖,而死锁检测与预防则允许事务的等待图中形成环,但是要能及时地发现等待图中的环并主动采取一些措施破坏掉这个环,从而让系统从死锁中恢复过来。很明显,这种死锁处理方式有两个关键点:死锁检测和死锁恢复。
1:死锁检测
为了检查多个事务是否构成了死锁,就需要系统维护事务之间的依赖关系,以此来构建等待图,还需要实现一个死锁探测算法来周期性地检查等待图中是否构成了环。在单机系统中,因为所有的依赖关系都在一起,因此死锁检测算法比较容易实现,但是在一个分布式系统中(比如CockroachDB),任何一个节点都无法及时获知整个等待图全貌,但看自己节点的信息,它可能不会发现环,但是就全局视角来看死锁已经产生(如下图)。
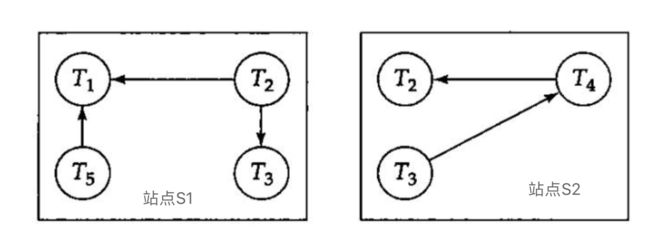

在分布式系统中,死锁检测又有以下两种思路:
(1)集中式死锁检测
集中式死锁检测的核心思想和单机系统的死锁检测是十分类似的,它要求每个节点都维护在本节点发生的依赖关系,也就是局部的等待图。同时在系统中存在一个全局节点(死锁检测协调器),其它节点都将自己的等待图发送到这个节点,这个全局节点会把所有局部节点的等待图拼接成一个完成的等待图,然后检查这个等待图中是否存在环形依赖。
局部站点什么时候把自己的局部等待图发给死锁检测协调器呢?通常有三种做法:
a:本节点的等待图发生变化是就立刻发送,比如图4中站点s1的T5 abort了,就立刻将删除T5->T1的消息发给死锁检测协调器来更新全局等待图。
b:周期性地,每当局部节点的等待图发生大量更新时在一起发送给协调器。
c:每当协调器的死锁检测算法进行死锁检测时各个局部节点在把局部等待图发送给协调器。
不管选择那种方式,避免不了的一个问题是由于依赖信息进行网络交互引起的依赖信息过时或不准确。这时可能导致不必要的回滚。比如在下面的场景中,由于某种原因,T2释放了S1节点的对T1申请资源的占有,同时去S2节点申请T3持有的资源。这时本来S1应该给协调器发送删除T1->T2的依赖、同时S2应该给协调器发送增加T2->T3的依赖。但是由于网络问题,S2发送的信息先与S1的信息到达协调器,这时在协调器便出现了T1->T2->T3->T1的环,如果触发死锁恢复,可能会导致这三个中的某几个事务被回滚。但是真正的等待图是T2->T3->T1,并没有环产生。

集中式死锁检测的其它缺点还包括:死锁检测协调器形成的单点在造成系统可用性下降;局部站点和死锁检测协调器之间的大量网络交互容易成为系统的性能瓶颈…。
(2)分布式死锁检测
EDGAR KNAPP把分布式死锁检测算法分为了四类:
a:Path-Pushing Algorithms(路径推动算法)
路径推动算法的核心思想是在每个站点都维护一个简化的全局等待图(global WFG),每次执行死锁计算之前,每个站点都将自己本地的WFG发送到许多邻接站点来更新它们的WFG,每个站点在更新过的WFG中进行死锁检测。这个动作周期性地重复,直到某些站点在自己的WFG中发现了死锁并进行解除。
b:Edge-Chasing Algorithms(边追踪算法)
这种算法的思路是WFG中的每个节点都会沿着它的依赖路径发送一个不同于资源请求和授予的特殊消息Probe,探针),这样,当某个时候,某个站点发现它收到了自己发出的这个特殊消息(Probe,探针)时,就说明自己处于一个依赖环中。
c:Diffusing Computations(扩散计算)
当一个WFG中的某个节点怀疑自己处与死锁状态时,便触发扩散。扩散沿着WFG的方向给所有的孩子发送扩散请求,孩子接收到扩散请求后也给它的孩子递归发送扩散请求,当它们接收到孩子的响应后,它们再给它们的父亲节点回复响应。一个节点发送请求后处与active状态,接收响应后恢复nature状态。当触发扩散的节点恢复到nature后扩散结束。
d:Global State Detection(全局状态检测)
在此具体不做介绍了。
2:死锁恢复
当死锁检测算法发现等待图中存在环时,就需要启动恢复程序来打破死锁,常用的做法是选择这个依赖环中的一个或几个事务进行回滚,但前提是要让回滚的代价尽可能的小,当然这个要求是很难实现的,因为事务的回滚代价受到许多因素的影响,比如事务执行到此花费了多少计算资源,还剩下多少计算事务即可完成(当然最优选择是回滚目前耗费最少计算、存储资源以及对其它事务影响最小的事务…),事务需要回滚多少才能解除死锁,最简单常用的做法是全部回滚。
一种特殊的死锁处理机制
还有一种特殊的死锁处理机制,那就是超时。在这种机制种,申请锁的事务等待锁时至多等待给定的时间t,如果时间到了还没有申请到锁,那么自己就回滚重启。这种机制的优点是实现简单。但是其缺点是这个最长等待时间t不好确定。如果t设置地过短,那么可能并没有发生死锁,只是正常的等待锁,但是由于时间到了,一个或几个事务都被回滚了,造成不必要的资源浪费;但是如果t设置的时间过长,那么可能死锁早已经发生了,但是由于还没有到t,所以这些事务都还在阻塞,导致系统的并发度降低。
喜欢的朋友记得点赞、收藏、关注哦!